1. Base LLM
- 학습된 데이터를 바탕으로 다음 단어를 예측하도록 설계된 언어 모델
- 질문에 답변하거나 대화를 하는 등의 특정 작업을 수행하도록 설계되지 않음
- 지시를 따르거나 작업을 수행하는 기능은 부족한 상태
- 추가적인 튜닝 없이는 주어진 프롬프트의 의도를 이해하지 못할 수 있음

2. Intruction tuned LLMs
- Base LLM에서 특정 작업을 수행하기 위해 추가적인 학습을 통해 개선된 모델
- 원하는 지시사항을 위해 결과 예시를 포함한 데이터 셋으로 추가 훈련을 한 것
- 단순한 다음 단어 예측을 넘어서 사용자의 지시를 이해하고 실행할 수 있다
- 학습을 위해서는 다양한 데이터, 데이터 퀄리티, 데이터의 양이 중요하다
- 임의로 만들어진 데이터 보다는 현실적인 데이터가 효과적이다

3. Instruction tuned LLM을 만드는 방식
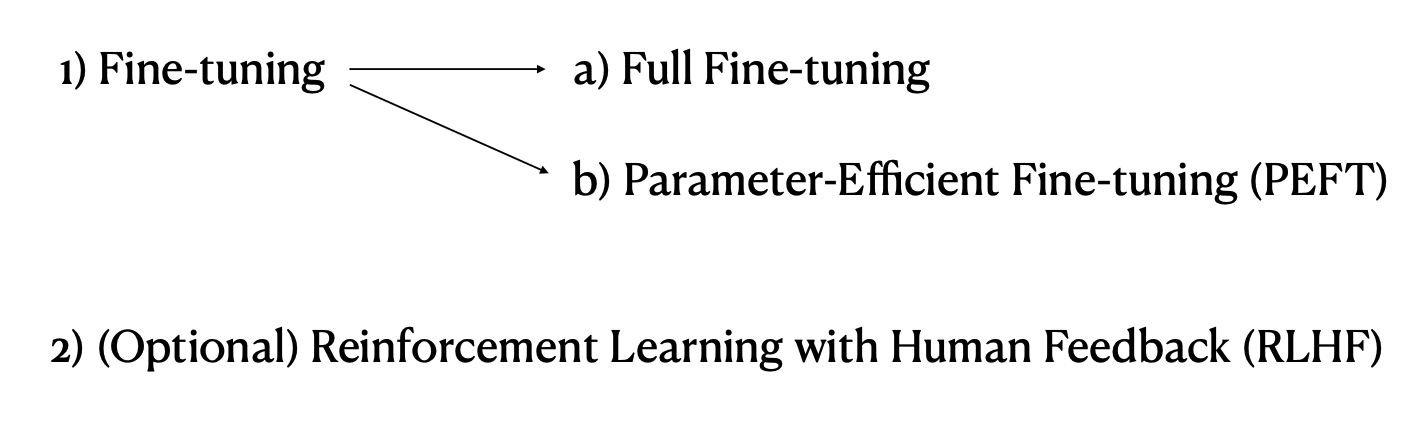
(1) Fine-tuning : Full Fine-tuning
완전한 파라미터 업데이트, 특정 작업을 위한 데이터셋, 많은 자원 소모, 높은 성능, 치명적인 망각의 특징이 있다.
(2) Fine-tuning : Parameter-Efficient Fine-tuning(PERT)
선택적 파라미터 업데이트, 사전 학습된 지식의 보존, 자원이 제한된 환경에서의 효율성, 더 빠른 적응의 특징이 있다.
(3) Reinforcement Learning with Human Feedback(RLHF)
유용성, 정직성, 무해함의 세가지 인간적 가치를 가지고 모델을 조정, 미세 조정을 통해 성능을 향상, 사용자 개인화된 LLM 생성의 특징이 있다.
4. Transformer variants
Transformer 기반 모델은 여러가지 아키텍쳐 변형이 있다. 각각의 특화된 작업이 존재한다.
Original Transformer : 인코더-디코더 구조로 되어 있음
- 인풋 텍스트 변환 능력에 뛰어남
- 번역과 요약과 같은 작업에 뛰어남
- 대표적인 모델은 T5가 있음
BERT(Bidirectional Encoder Representations from Transformers)
- 양방향 인코딩을 사용
- 양방향 텍스트 해석을 하다보니 텍스트 이해 능력이 뛰어남
- 감정 분석등에 사용됨
GPT(Generative Pre-trained Transformer)
- 디코더만 사용하는 모델
- 이전 출력만 사용해서 텍스트 출력을 하다보니 텍스트 생성 능력이 뛰어남
- 텍스트 생성과 같은 글쓰기 등에 사용됨
5. LLM 모델을 둘러볼 수 있는 사이트
- Hugging face
6. 모델 선택시 고려해야하는 요소
- Task Specificity : 내가 원하는 작업과 관련된 모델을 선택
- Model Performance : 주어진 테스크와 관련된 높은 성능을 가진 모델을 선택
- Model Size : 모델의 크기 고려. 리소스 사용량 고려
- Pre-training and Fine-tuning : 모델이 사전학습만 되었는지 또는 파인튜닝(미세조정)까지 되었는지 확인
- Licensing : 상업적인 용도로 사용하려면 라이센스 확인
7. Model Performance Benchmark
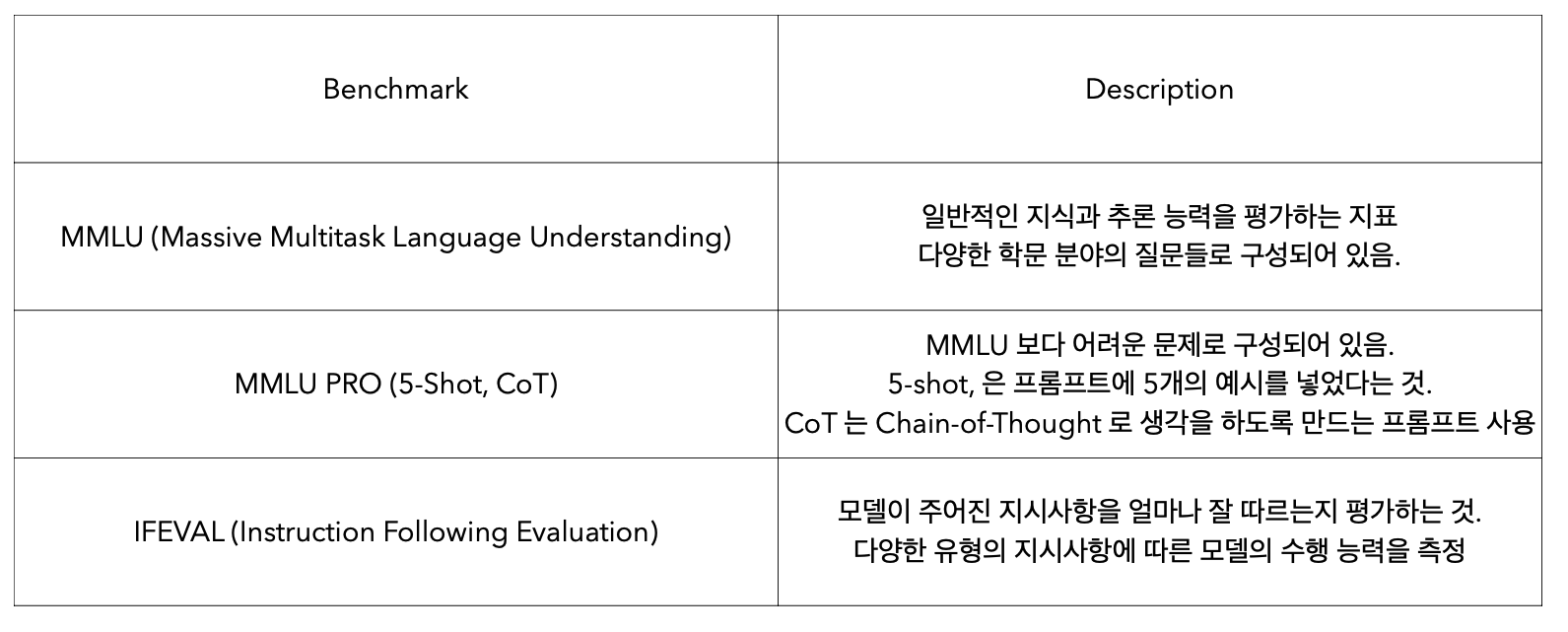
General Benchmark : LLM의 능력 중 일반적인 분야를 측정
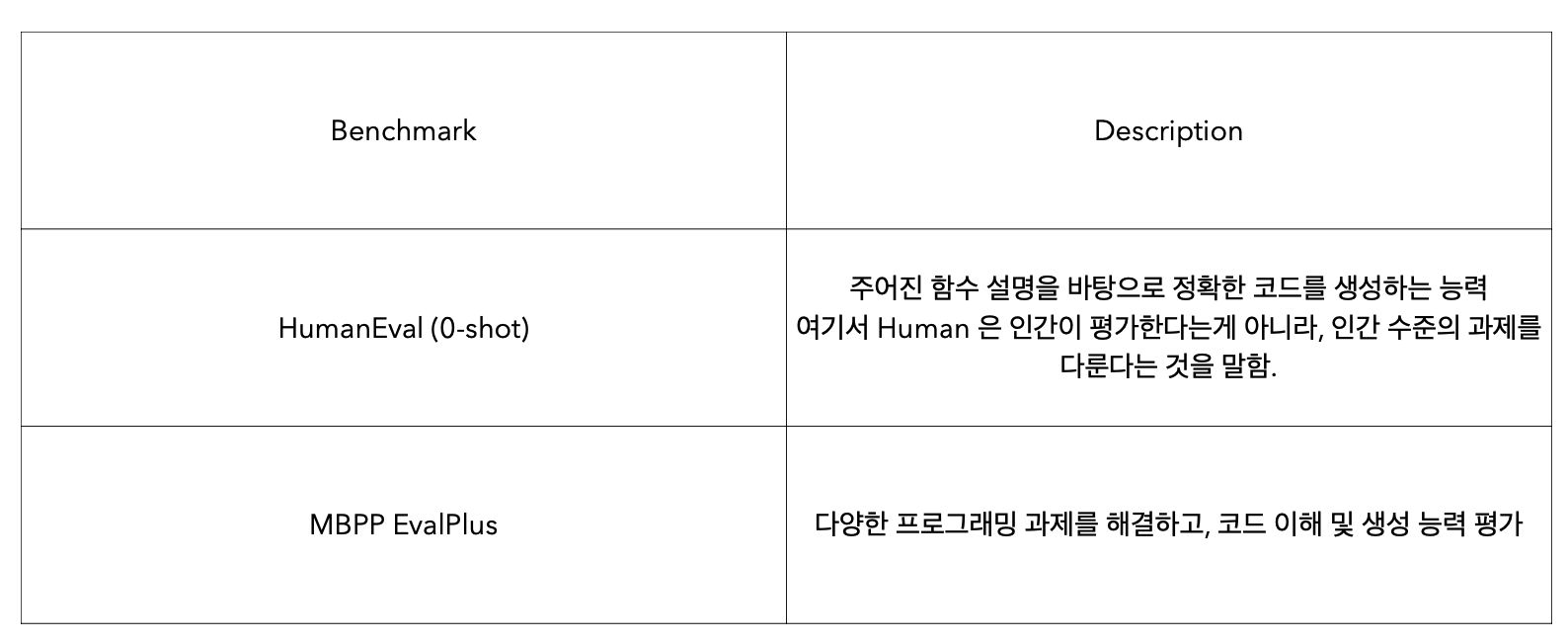
Code Benchmark : LLM의 능력 중 코드 생성과 프로그래밍 능력을 평가
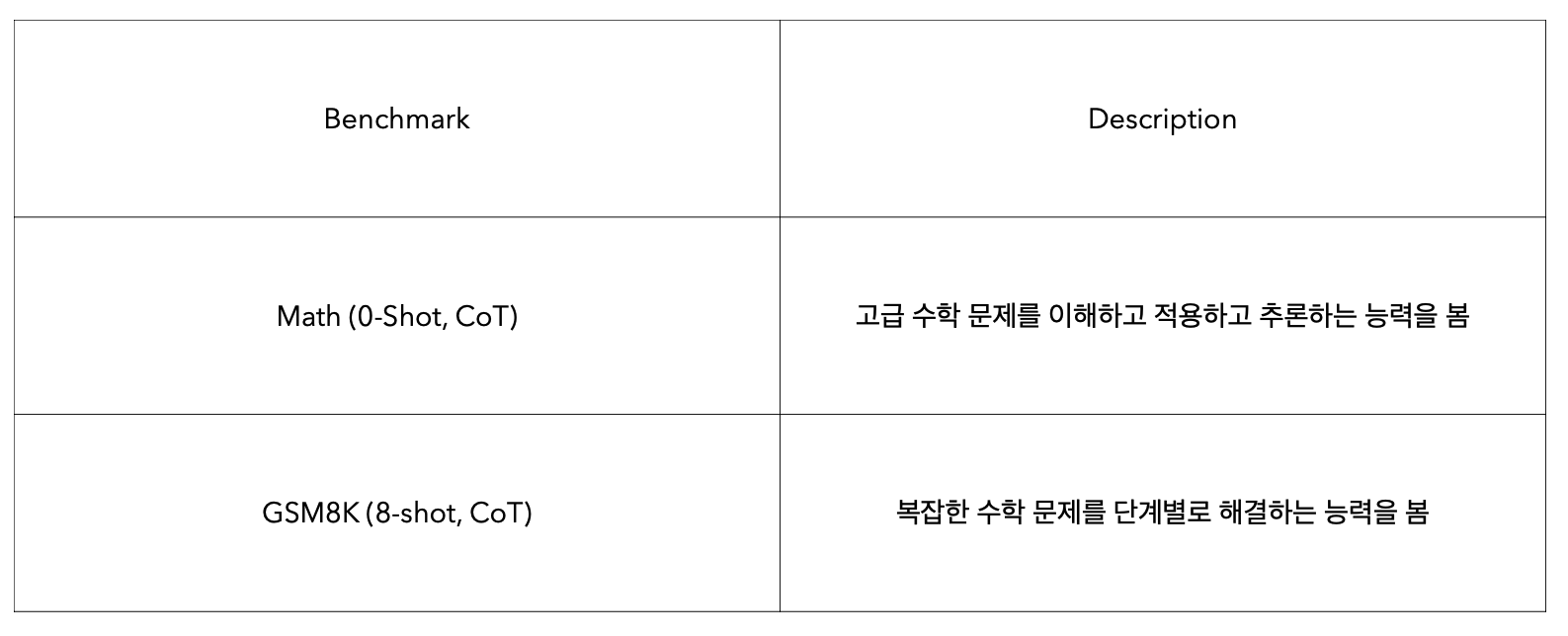
Math Benchmark : LLM의 능력 중 수학적 문제 해결 능력 평가
Reasoning Benchmark : LLM의 능력 중 추론 능력 평가
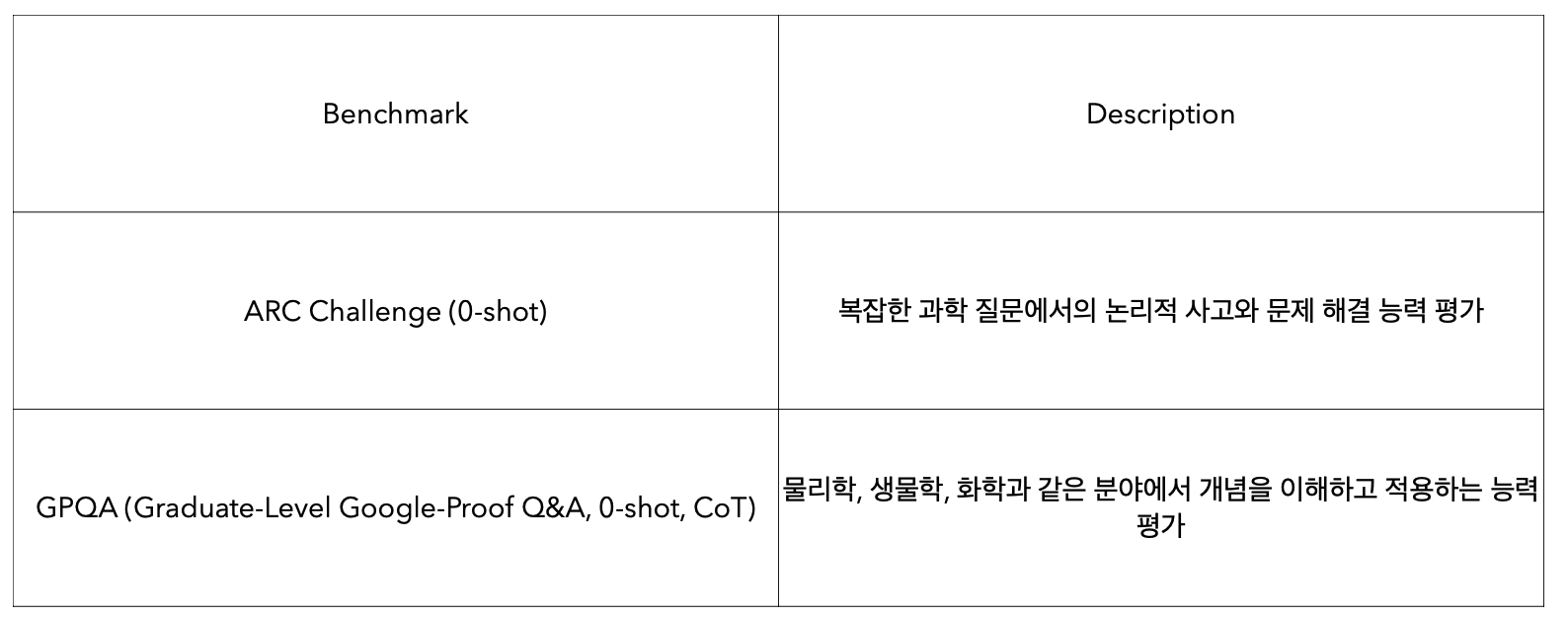
Tool-use Benchmark : LLM이 실제 도구나 API를 얼마나 잘 쓰는지 평가
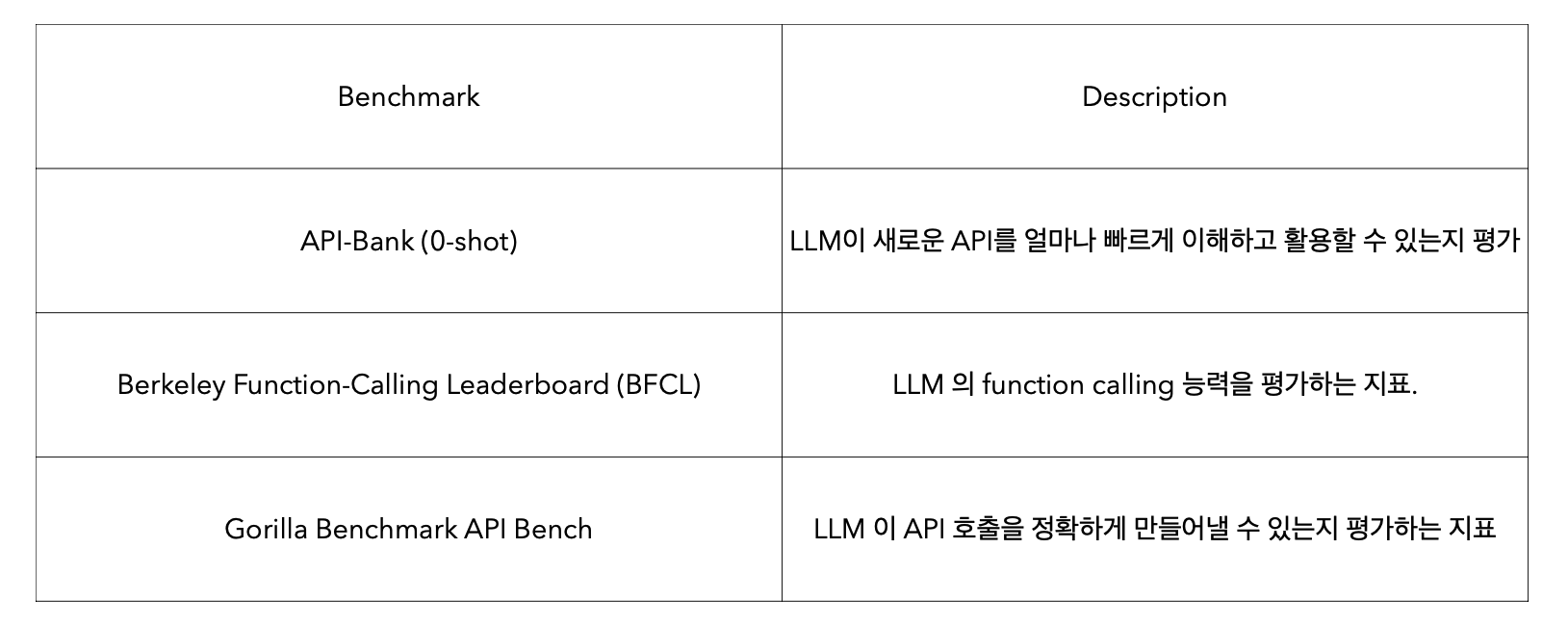
벤치마크는 실제 우리의 작업의 복잡성을 반영하지 못할 수 있다
