0. Transformer Architecture 도입 배경
- 기존 RNN은 입력을 순차적으로 처리해야 하는 근본적인 구조의 한계가 있어 병렬 처리가 어렵다. 또한 긴 시퀀스를 처리할 때 메모리가 부족해지는 Long-Term Dependencies 문제가 발생한다. 따라서 Parallel Processing이 가능한 Transformer Architecture가 LLM 기본 아키텍쳐로 채택되었다.
1. Transformer Architecture란?

문장 내에서 모든 단어의 관련성과 중요도를 고려하여 텍스트를 해석하고 다음에 올 단어를 예측하는 아키텍쳐이다.
크게 인풋 -> 인코더 -> 디코더 -> 소프트맥스 -> 아웃풋의 순으로 이어진다.
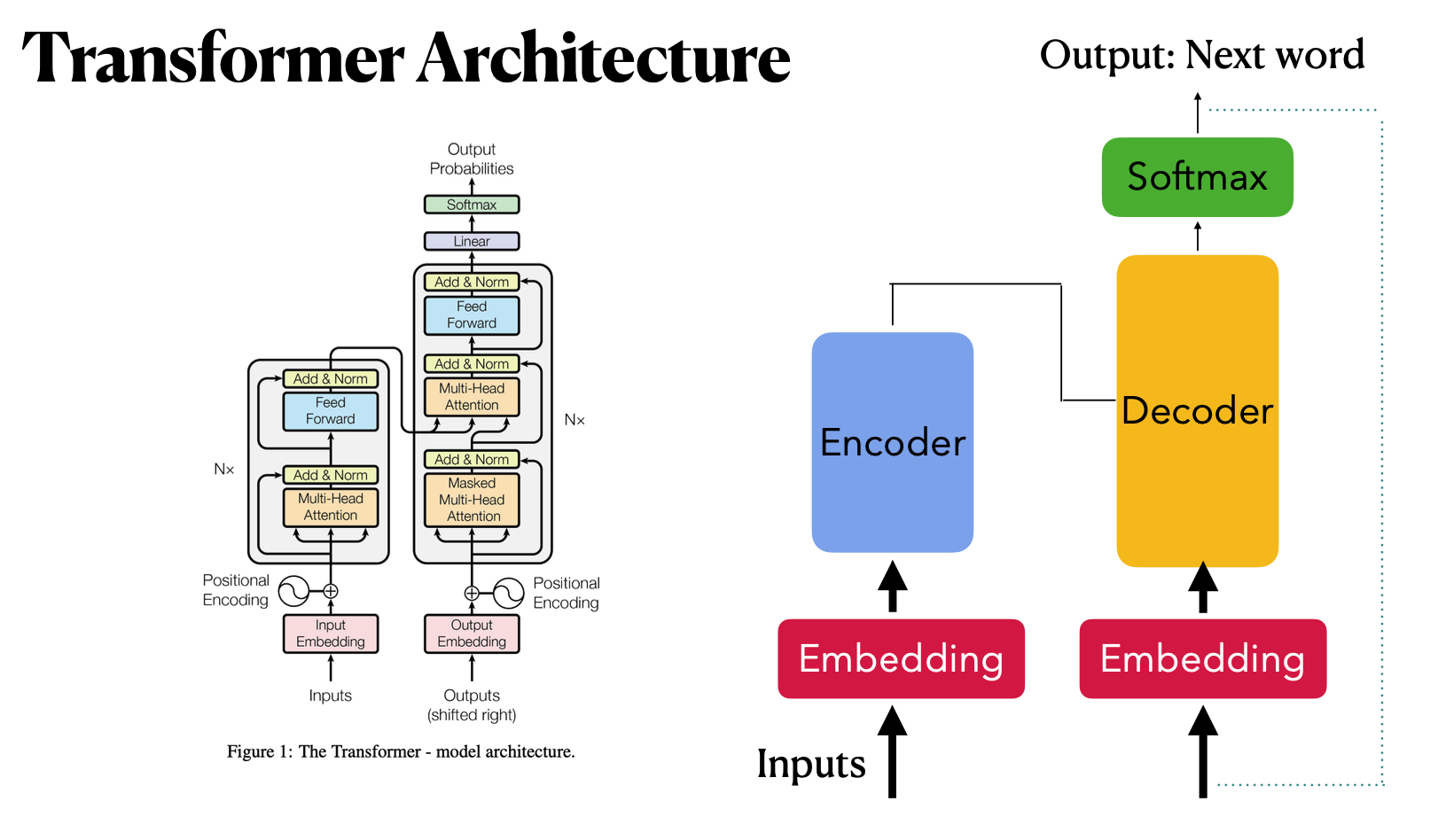
2. Transformer Architecture의 진행 과정
(1) Tokenization
입력이 들어오면 Tokenizer가 입력을 숫자로 바꾼다. 이때 유사한 단어는 유사한 값으로 바꾼다.
(2) Embedding
바뀐 숫자를 벡터로 표현한다.
(3) Positional Encoding
인코더에 들어가기 전에 벡터들의 순서에 따라 가중치를 부여한다. 텍스트는 순서에 따라 의미가 다르기 때문이다.
(4) Self-Attention in Encoder
Self-Attention 매커니즘을 활용해 인코딩을 한다. 3가지 구성 요소가 있다.
쿼리 - 현재 처리중인 단어
키 - 입력 시퀀스의 모든 단어
값 - 각 단어의 실제 의미를 나타내는 벡터
쿼리벡터와 키벡터 사이의 관련성을 측정 -> 각 단어가 쿼리에 얼마나 기여하는지에 따라 가중치 값을 생성 -> 값들을 바탕으로 새로운 값 벡터를 생성 -> 이 과정을 모든 단어에 적용 -> 최종 아웃풋 생성



(5) Masked Self-Attention in Decoder
디코더의 첫번째 어텐션 층에서 사용되며 현재까지 생성된 시퀀스 내에서 관계를 파악하는데 사용된다. 미래 정보를 볼 수 없도록 마스킹이 적용되며 인코더의 출력을 이용하지 않고 오로지 디코더의 이전 출력만 고려한다.
(6) Encoder-Decoder Attention
디코더의 두번째 어텐션 층에서 사용되며 입력 시퀀스(인코더의 출력)과 현재까지 생성된 출력 사이의 관계를 파악한다. 입력 텍스트의 이해와 현재까지 생성한 출력을 고려해서 다음 단어를 예상한다.
(7) SoftMax
다음 토큰의 확률을 예측한다. 확률이기 때문에 충분히 다양한 값이 나올 수 있음.
3. Multi-head Attention
위의 2번에서 설명한 진행과정에서 여러개의 헤드로 나눠서 독립적, 병렬적으로 처리한다. 헤드는 하나의 어텐션 매커니즘을 의미하며 입력 텍스트의 해석을 하나의 관점에서만 보는게 아니라 여러 관점에서 보기 위한 것이다.
문법적인 요소와 시제에 집중하는 헤드, 엔티티의 관계에 집중하는 헤드, 문장 내에서 일어나는 활동에 집중하는 헤드, 단어의 운율에 집중하는 헤드가 각각 진행되어 나온 결과를 종합한다.

