1. 프롬프트 엔지니어링이 필요한 이유
- 프롬프트 설계는 웹에서 AI시대 개발을 준비하기 위해 필요한 밑거름이다. 프롬프트 설계 스킬은 프로그래밍 언어를 배우는 것과 같다.
2. LLM(Large Language Model)이란?
-> LLM은 인간과 유사한 텍스트를 처리하고 이해하며 생성하도록 설계된 인공지능 시스템이다. 방대한 양의 텍스트 데이터를 기반으로 학습했으며 다양한 자연어 처리 작업을 수행하는게 가능하다. -> 텍스트 생성, 번역, 요약, 질문-답변, 감성분석, 코드 생성 등
3. LLM의 작동 원리
파라미터와 실행 파일로 나뉘어져 있다. 빅 데이터를 학습하면 파라미터가 생성되며 LLM은 파라미터를 바탕으로 다음 단어를 예상할 수 있게 된다. 즉, 파라미터가 많을 수록 지식이 많아지며 이는 올바른 대답을 할 확률이 높아진다는 말과 같은 뜻이다. LLM의 기본 기능은 다음 단어 예상이므로 할루시네이션은 자연스럽게 따라오는 현상이다.
다만 ChatGPT같은 기능은 실제 사람과 대화하는 느낌을 주는데, 기존 모델에 미세 조정을 시켜서 그런 것이다.
4. LLM이 언어를 이해하는 방식
(1) Tokenization

토큰화 과정을 통해서 단어 사이즈를 크게 줄일 수 있다. 이 과정에서 사람이 이해하는 방식과 달라진다. LLM은 사람이 쓴 글을 이모지의 배열로 받아들인다고 이해하면 된다.
(2) Embedding
컴퓨터는 문자를 그대로 이해할 수 없기 때문에 문자를 숫자의 형태를 띄는 벡터로 변환해서 받아들인다. Embedding이란 한마디로 토큰의 의미와 관계를 포착하는 고차원 벡터 표현이다. 단어나 문장의 기본적인 뉘앙스를 이해할 수 있으며 유사한 의미를 가진 단어나 문장은 유사한 벡터 표현을 가진다.
(3) Attention Mechanism
LLM은 내부적으로 어텐션 메커니즘을 활용한다.
입력 값의 모든 단어들이 서로 직접적으로 연결되서 연관성을 파악할 수 있게 해주는 매커니즘이다. 이로 인해 각 단어는 다른 단어들에 비해 얼마나 주의를 기울일지 계산된다. 즉, 중요도를 평가해서 중요한 단어들 위주로 텍스트를 해석한다.
-> Attention Mechanism이 적용된 경우
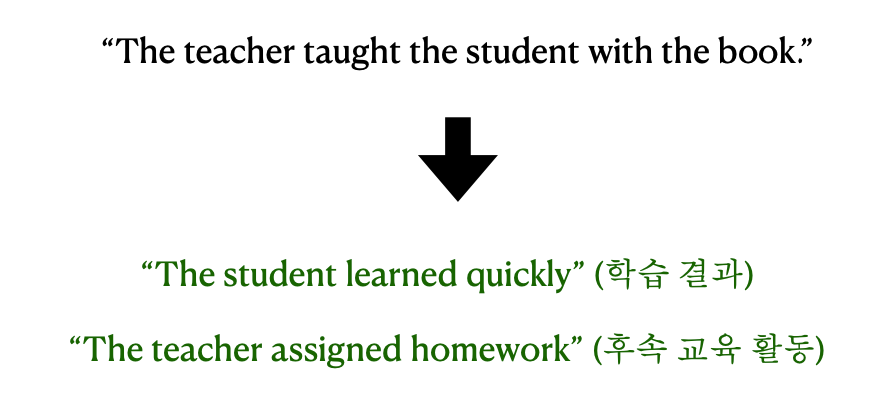
-> 적용되지 않은 경우

5. LLM의 특징
(0) LLM은 지식 저장소의 역할을 한다
(1) 성능은 모델의 크기와 학습 데이터의 크기에 비례한다(Scaling Laws)
(2) 처음 데이터와 마지막 데이터를 잘 기억한다(초두효과, 최신효과) -> 중요한 정보는 프롬프트 맨앞과 맨뒤에 넣자
(3) 인간에게 아첨하는 경향이 있다. -> 학습 데이터와 학습 방식이 인간이 만든 것이므로 자연스러운 현상
(4) Context Window를 가진다. 즉, 한번에 처리하고 기억할 수 있는 텍스트의 최대 길이를 가진다.
(5) 풍부한 맥락을 제공할수록 성능이 올라간다. -> 프롬프트에 자세히 적자
(6) LLM의 예측 기능으로 인해 할루시네이션 현상이 발생한다. -> 어떻게든 다음 단어를 내놓으려다 잘못된 정보를 제공하는 현상
(7) 역방향 추론 오류를 가지고 있다. -> 한 쪽 방향으로만 학습시키다보니 반대로 질문하면 답하지 못하는 경우가 있다. 예) 톰 크루즈의 엄마는? 메리 리파이퍼의 아들은?
=> LLM은 때때로 기이하게 행동하고 일차원 적으로 행동한다. 따라서 원하는 답을 이끌어내려면 특정 방향으로의 질문이 필요하다. 이는 특정 키워드 중심으로 검색을 하면 잘되는 검색 엔진을 쓰는 것과 유사하다.
6. LLM을 사용할때의 마음가짐
(1) LLM은 블랙 박스와 같이 어떻게 동작하는지 알기 어렵다
(2) 원하는 답을 한번에 얻어내지 못하는 것이 당연하다
(3) 실패로부터 반복적으로 개선해야 한다.
