[번역] Swift Concurrency: Behind the Scenes 전사문
Swift Cocurrency

💬 본 전사문은 ChatGPT 4o에 의해 번역되었습니다.
♪ 베이스 음악 재생 중 ♪
로키니 프라부: 안녕하세요, “Swift Concurrency: Behind the Scenes” 세션에 오신 것을 환영합니다. 저는 로키니이며, Darwin 런타임 팀에서 일하고 있습니다. 오늘 저와 제 동료 바룬은 Swift 동시성과 관련된 몇 가지 세부 사항에 대해 이야기하게 되어 매우 기쁩니다. 이 세션은 이전 Swift 동시성 관련 세션들을 기반으로 하는 심화 내용입니다. 만약 async/await, 구조적 동시성과 액터(actor)에 익숙하지 않으시다면, 먼저 다른 세션들을 시청하실 것을 권장합니다.
이전에 진행된 Swift 동시성에 대한 세션에서는 올해 Swift에 새롭게 도입된 다양한 언어 기능과 그 사용법에 대해 배웠습니다. 이번 세션에서는 한 단계 더 깊이 들어가 이러한 기본 요소들이 왜 이런 방식으로 설계되었는지를 살펴볼 것입니다. 이는 단순히 언어의 안전성을 확보하기 위한 것뿐만 아니라 성능과 효율성을 고려한 설계이기도 합니다. 여러분이 Swift 동시성을 실험하고 직접 앱에 적용해 나가면서, 이번 세션이 Swift 동시성을 논리적으로 이해하는 데 도움을 줄 뿐만 아니라 Grand Central Dispatch(GCD)와 같은 기존의 스레딩 라이브러리와 어떻게 연계되는지도 파악할 수 있는 기회가 되길 바랍니다.
오늘은 몇 가지 중요한 주제를 다룰 것입니다. 먼저, Swift 동시성의 스레딩 모델을 살펴보고 GCD와 비교해 보겠습니다. 그런 다음, 동시성 언어 기능을 활용하여 Swift를 위한 새로운 스레드 풀을 구축함으로써 어떻게 성능과 효율성을 향상시켰는지 설명하겠습니다. 마지막으로, 기존 코드를 Swift 동시성으로 전환할 때 고려해야 할 사항들을 짚어보겠습니다. 이후에는 바룬이 Swift 동시성에서의 동기화 개념을 액터로 설명할 것입니다. 여기에서는 액터가 내부적으로 어떻게 동작하는지, 그리고 기존의 동기화 방식인 직렬 디스패치 큐와 비교했을 때 어떤 차이가 있는지를 알아볼 것입니다. 또한 액터를 사용할 때 유의해야 할 점들도 함께 논의할 것입니다.
오늘 다룰 내용이 많으니 바로 시작하겠습니다. 스레딩 모델에 대한 논의에서는 먼저, 현재 사용 가능한 기술인 GCD를 활용해 작성된 예제 앱을 살펴보겠습니다. 그런 다음, 동일한 애플리케이션을 Swift 동시성을 사용하여 다시 작성했을 때 어떤 차이가 있는지 비교해 보겠습니다.
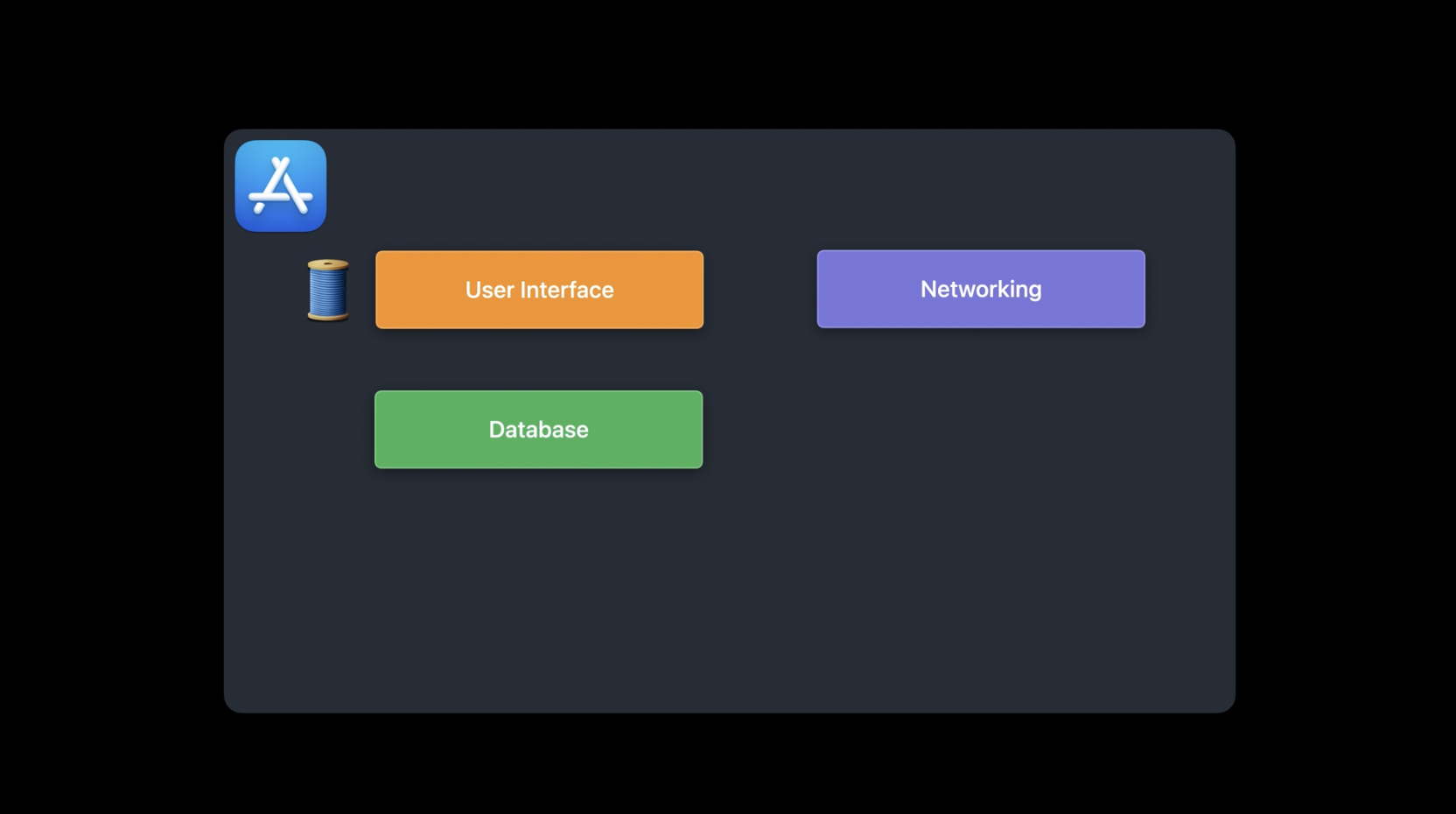
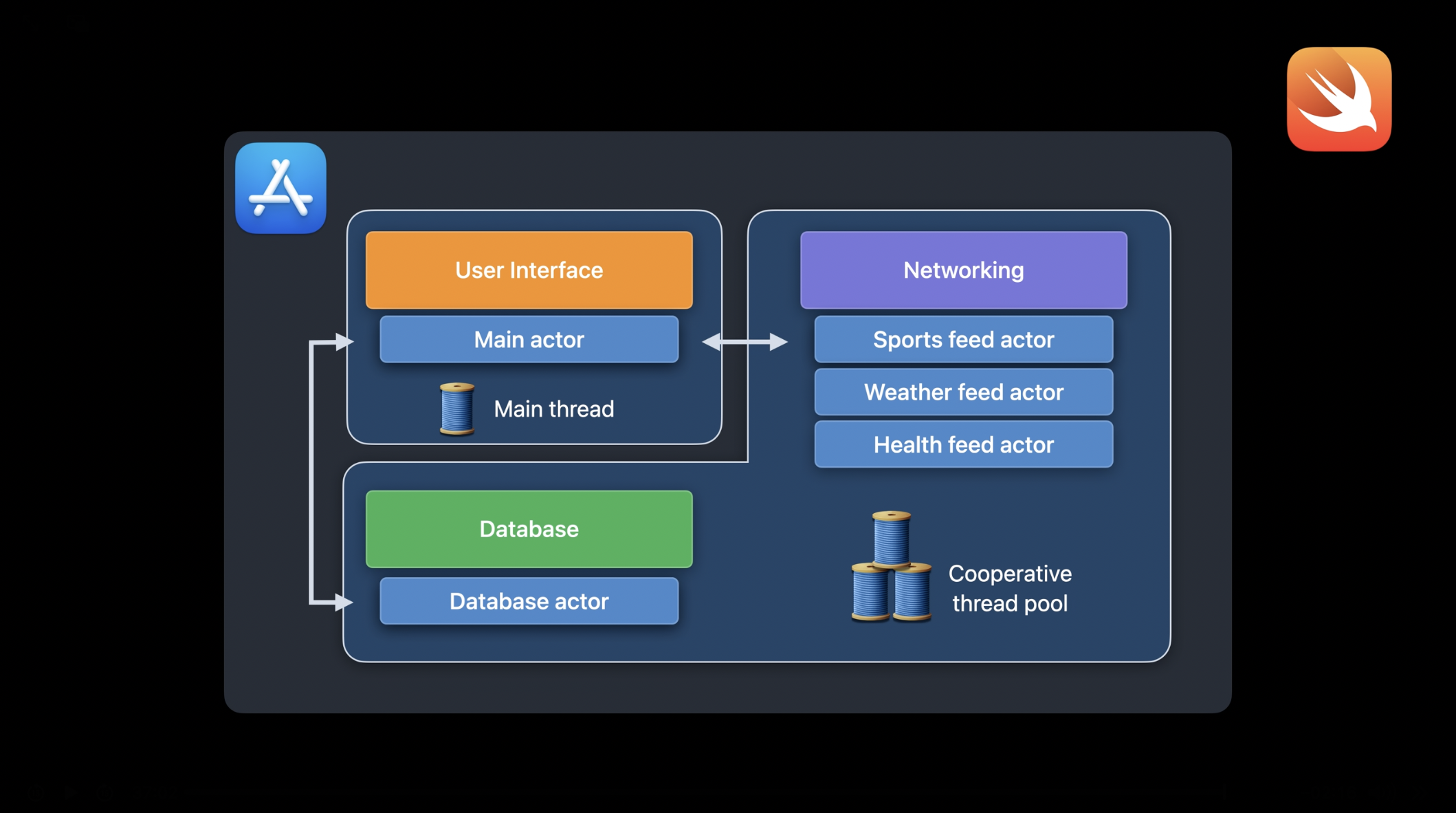
제가 직접 뉴스 피드 리더 앱을 만든다고 가정해 보겠습니다. 먼저, 애플리케이션의 주요 구성 요소를 생각해 보겠습니다. 앱에는 사용자 인터페이스를 담당하는 메인 스레드가 있을 것이고, 사용자가 구독한 뉴스 피드를 관리하는 데이터베이스가 필요합니다. 그리고 마지막으로, 피드에서 최신 콘텐츠를 가져오는 네트워킹 로직을 처리하는 서브 시스템이 필요합니다.
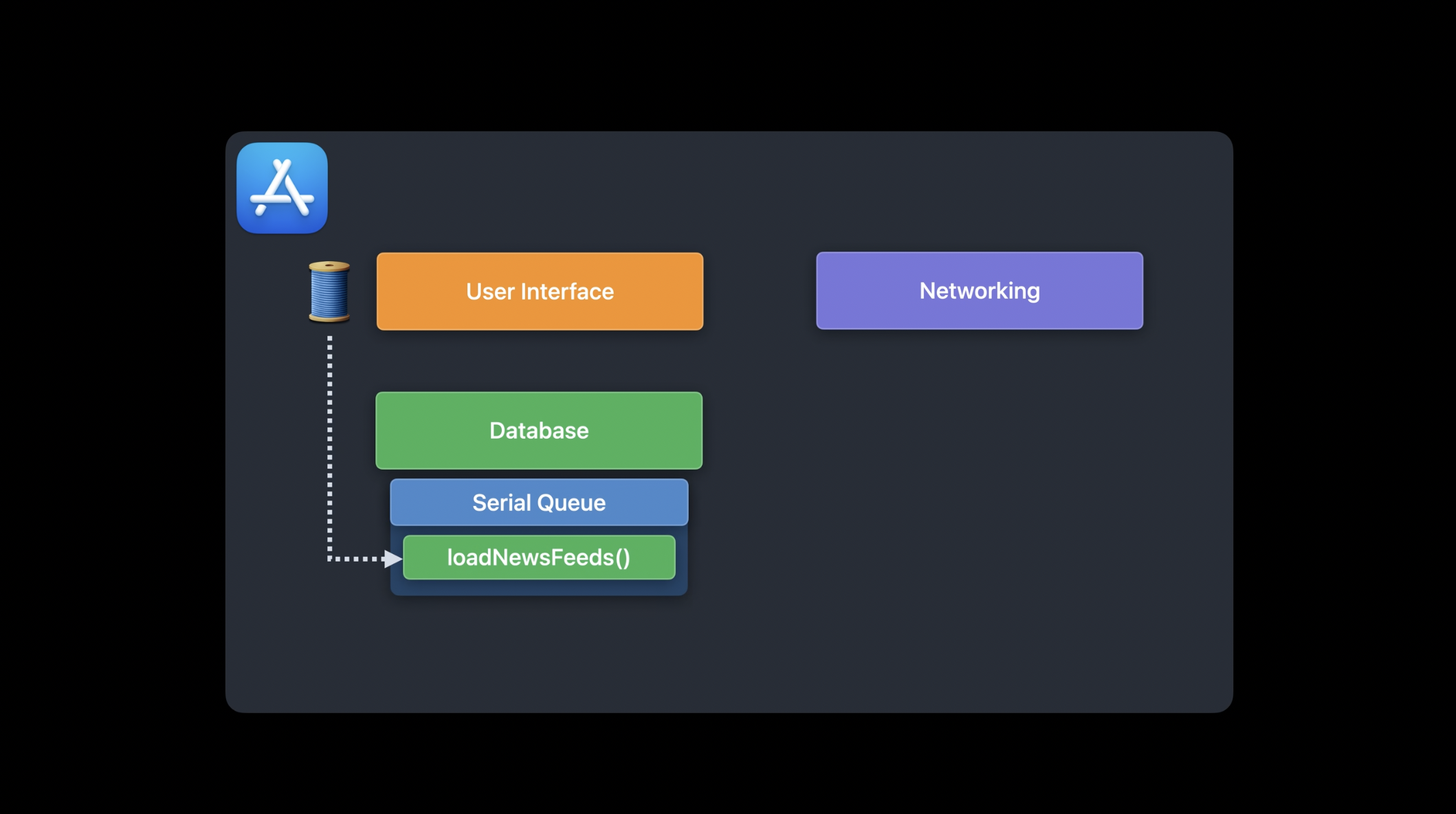
이제 이 앱을 GCD 큐를 사용하여 어떻게 구조화할 수 있을지 살펴보겠습니다. 사용자가 최신 뉴스를 보고 싶다고 요청했다고 가정해 보겠습니다. 이때, 메인 스레드에서 사용자 이벤트 제스처를 처리하게 됩니다. 이후, 데이터베이스 작업을 담당하는 직렬 큐로 비동기 디스패치하여 데이터베이스에서 필요한 정보를 가져오도록 합니다.
이렇게 하는 데는 두 가지 이유가 있습니다. 첫째, 작업을 다른 큐로 디스패치함으로써, 메인 스레드가 잠재적으로 많은 작업을 처리하는 동안에도 사용자 입력에 계속해서 응답할 수 있도록 보장할 수 있습니다. 둘째, 직렬 큐를 사용하면 동시 접근이 제한되므로, 데이터베이스에 대한 접근이 보호됩니다. 직렬 큐는 한 번에 하나의 작업만 실행하기 때문에, 여러 스레드에서 동시에 데이터베이스를 조작하는 문제를 방지할 수 있습니다.

데이터베이스 큐에서 실행되는 동안, 사용자가 구독한 뉴스 피드를 순회하며 각 피드에 대해 네트워킹 요청을 스케줄링하여 URLSession을 통해 해당 피드의 콘텐츠를 다운로드하도록 합니다. 네트워킹 요청의 결과가 도착하면, URLSession의 콜백이 동시 큐에서 실행됩니다. 각 요청의 완료 핸들러에서 최신 피드 데이터를 캐싱하기 위해 동기적으로 데이터베이스를 업데이트합니다. 마지막으로, UI를 새로고침하기 위해 메인 스레드를 깨워 화면을 업데이트합니다.
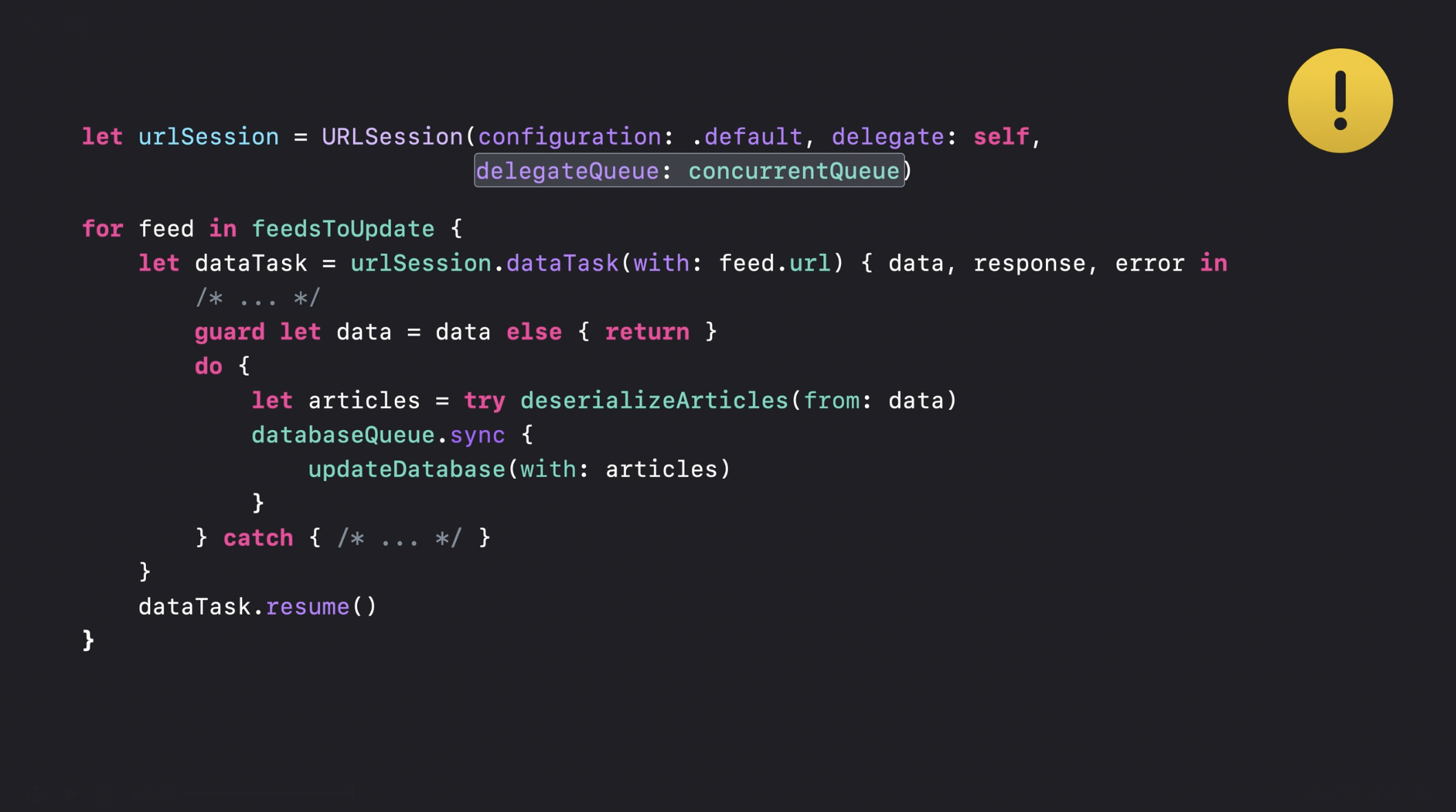
이러한 방식으로 애플리케이션을 구성하는 것은 매우 합리적으로 보입니다. 요청을 처리하는 동안 메인 스레드를 차단하지 않도록 했으며, 네트워크 요청을 동시에 처리함으로써 프로그램의 고유한 병렬성을 최대한 활용할 수 있도록 설계되었습니다. 이제, 네트워크 요청의 결과를 처리하는 코드를 좀 더 자세히 살펴보겠습니다. 먼저, 뉴스 피드에서 데이터를 다운로드하기 위해 URLSession을 생성했습니다. 여기에서 볼 수 있듯이, URLSession의 델리게이트 큐를 동시 큐로 설정했습니다. 그런 다음, 업데이트해야 하는 모든 뉴스 피드를 순회하며 각 피드에 대해 URLSession에서 데이터 작업을 스케줄링합니다. 데이터 작업의 완료 핸들러는 동시 큐에서 실행되며, 여기에서 다운로드한 결과를 역직렬화하고 기사 형식으로 변환합니다. 이후, 데이터베이스의 결과를 업데이트하기 전에 데이터베이스 큐에서 sync 호출을 수행하여 동기적으로 데이터를 저장합니다. 겉으로 보기에 이 코드는 단순한 직선 흐름으로 작성되어 있어 쉽게 이해할 수 있지만, 성능 측면에서 몇 가지 숨겨진 문제가 있습니다.

이러한 성능 문제를 더 잘 이해하려면, 먼저 GCD에서 스레드가 어떻게 생성되어 작업을 처리하는지 알아볼 필요가 있습니다. GCD에서 작업이 큐에 추가되면, 시스템은 해당 작업을 처리하기 위해 스레드를 생성합니다. 특히 동시 큐의 경우, 여러 작업을 동시에 실행할 수 있으므로 시스템은 CPU 코어가 포화 상태에 이를 때까지 여러 개의 스레드를 생성합니다. 그러나 만약 특정 스레드가 블로킹되는 경우, 동시에 실행할 수 있는 추가 작업이 있을 때 GCD는 더 많은 스레드를 생성하여 남은 작업을 처리하려 합니다. 이는 CPU 활용도를 최대로 끌어올리는 방식이지만, 잘못 관리될 경우 과도한 스레드 생성으로 인해 불필요한 컨텍스트 스위칭과 리소스 낭비가 발생할 수 있습니다.
이러한 동작이 이루어지는 데는 두 가지 이유가 있습니다. 첫째, 프로세스에 추가적인 스레드를 할당함으로써, 각 CPU 코어가 언제나 작업을 실행할 수 있도록 보장할 수 있습니다. 이를 통해 애플리케이션이 지속적으로 높은 수준의 동시성을 유지할 수 있습니다. 만약 모든 코어가 활성화된 스레드 없이 대기 상태에 있다면, 시스템 자원을 충분히 활용하지 못하게 됩니다. 둘째, 블로킹된 스레드는 세마포어와 같은 특정 리소스를 기다리고 있을 수 있으며, 이 리소스를 확보해야만 다음 단계로 진행할 수 있습니다. 이때, GCD가 새로운 스레드를 생성하여 동시 큐에서 작업을 계속 수행하게 하면, 이 새로운 스레드가 첫 번째 스레드가 기다리고 있는 리소스를 해제하는 역할을 할 수도 있습니다. 결과적으로, 전체적인 작업 진행 속도를 향상시키는 데 도움이 될 수 있습니다.
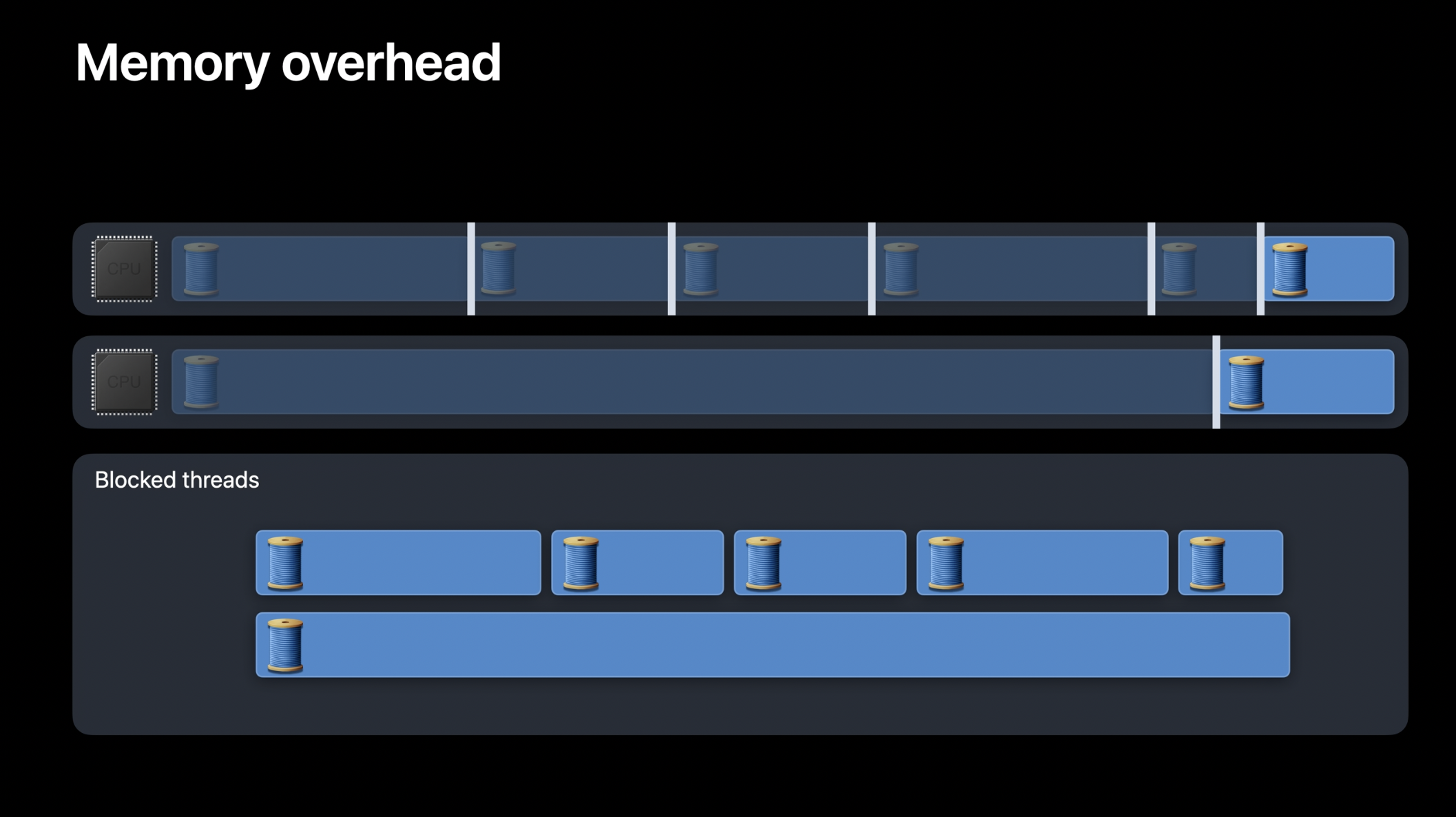
이제 GCD에서 스레드가 어떻게 생성되는지 이해했으므로, 다시 우리 뉴스 앱의 CPU 실행 흐름을 살펴보겠습니다. 예를 들어, Apple Watch와 같은 듀얼 코어 기기에서 GCD는 처음에 두 개의 스레드를 생성하여 피드 업데이트 결과를 처리합니다. 그러나 이 스레드들이 데이터베이스 큐에서 대기하게 되면, GCD는 네트워킹 큐에서 계속 작업을 수행할 수 있도록 추가적인 스레드를 생성합니다. 그 결과, CPU는 네트워크 요청 결과를 처리하는 여러 개의 스레드 사이에서 빈번하게 컨텍스트 스위칭을 수행하게 됩니다. 이는 스레드 간에 전환이 발생하는 지점으로 흰색 수직선으로 표시됩니다.
이러한 동작이 뉴스 앱에서 문제가 되는 이유는, 앱이 쉽게 매우 많은 수의 스레드를 생성할 수 있기 때문입니다. 예를 들어, 사용자가 100개의 뉴스 피드를 구독하고 있다면, 각 URL 데이터 작업이 네트워크 요청 완료 시 동시 큐에서 완료 블록을 실행해야 합니다. 이때, 각 콜백이 데이터베이스 큐에서 블로킹되면 GCD는 더 많은 스레드를 생성하여 남은 네트워크 작업을 처리하려 하므로, 결과적으로 애플리케이션 내에서 과도한 수의 스레드가 생성될 수 있습니다.

이제 이런 질문이 나올 수 있습니다. “애플리케이션에서 많은 스레드를 가지는 게 왜 문제가 될까?” 애플리케이션에서 너무 많은 스레드를 생성하면, 시스템은 CPU 코어 수보다 훨씬 많은 스레드를 실행하려고 시도하게 됩니다. 즉, 스레드가 과도하게 할당(overcommit)되는 상황이 발생합니다. 예를 들어, iPhone에 6개의 CPU 코어가 있다고 가정해 보겠습니다. 만약 우리 뉴스 앱이 100개의 피드 업데이트를 처리해야 한다면, iPhone은 CPU 코어보다 16배 더 많은 스레드를 처리해야 합니다. 이것이 바로 우리가 스레드 폭발(thread explosion)이라고 부르는 현상입니다.
과거 WWDC 세션에서도 이 문제를 다룬 바 있으며, 스레드 폭발이 애플리케이션에서 데드락(deadlock)과 같은 문제를 유발할 가능성이 있다는 점을 강조했습니다. 또한, 스레드 폭발은 단순히 실행 속도 저하만 초래하는 것이 아니라, 메모리 소비 증가와 스케줄링 오버헤드를 동반합니다. 이러한 문제들은 즉각적으로 눈에 띄지 않을 수 있지만, 애플리케이션의 성능에 큰 영향을 미칠 수 있습니다. 이제, 이러한 오버헤드가 실제로 어떻게 발생하는지 좀 더 깊이 살펴보겠습니다.
우리 뉴스 앱을 다시 살펴보면, 블로킹된 각 스레드는 실행을 재개할 때까지 메모리와 시스템 리소스를 점유하고 있습니다. 각 블로킹된 스레드는 스택과 커널에서 해당 스레드를 추적하는 데이터 구조를 유지하고 있어, 실행되지 않는 동안에도 중요한 시스템 자원을 소비합니다. 또한, 일부 스레드는 특정 락(lock)을 점유하고 있을 수 있으며, 이 락을 필요로 하는 다른 스레드들은 실행되지 못하고 대기하게 됩니다. 결과적으로, 진행되지 않는 스레드들이 불필요한 메모리와 리소스를 차지하게 됩니다.
스레드 폭발로 인해 스케줄링 오버헤드도 증가합니다. 새로운 스레드가 생성될 때마다, CPU는 이전 스레드에서 새로운 스레드로 전환하기 위해 전체 스레드 컨텍스트 스위칭을 수행해야 합니다. 또한, 블록된 스레드가 다시 실행 가능 상태가 되면, 스케줄러는 모든 스레드가 원활하게 진행될 수 있도록 CPU에서 시분할(time-sharing)을 수행해야 합니다. 스레드의 시분할 자체는 몇 번 발생하는 정도라면 문제가 되지 않습니다. 이것이 바로 동시성의 강점입니다. 하지만 스레드 폭발이 발생하면, 한정된 코어를 가진 기기에서 수백 개의 스레드를 시분할해야 하므로 과도한 컨텍스트 스위칭이 일어날 수 있습니다. 그 결과, 이러한 스레드들의 스케줄링 지연 시간이 실제 유용한 작업 수행 시간을 초과하게 되고, 이는 CPU의 비효율적인 실행을 초래하게 됩니다.
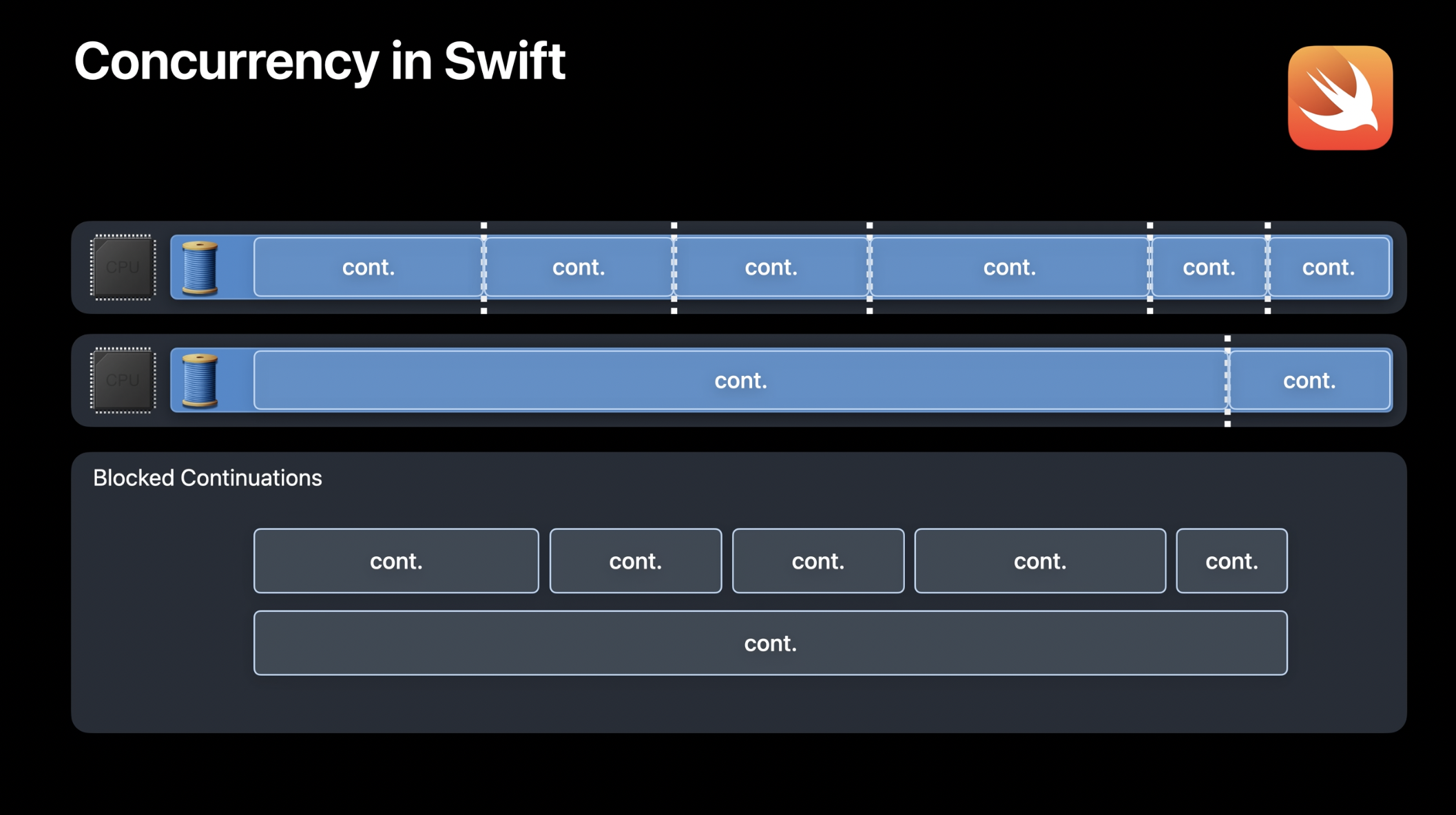
지금까지 살펴본 것처럼, GCD 큐를 사용할 때 스레드 관리에 대한 세부적인 부분을 놓치기 쉽습니다. 그 결과, 성능 저하와 불필요한 오버헤드가 발생할 수 있습니다. 이러한 문제를 해결하기 위해 Swift는 동시성을 설계할 때 기존과는 다른 접근 방식을 취했습니다. Swift 동시성은 성능과 효율성을 최우선으로 고려하여 설계되었으며, 이를 통해 애플리케이션이 보다 구조화되고 안전한 방식으로 동시성을 활용할 수 있도록 지원합니다. Swift에서는 기존의 실행 모델을 다음과 같이 변화시키고자 합니다. 기존 모델에서는 과도한 스레드와 컨텍스트 스위칭이 발생했습니다. 하지만 Swift 동시성을 적용하면, 두 개의 코어를 가진 시스템에서 단 두 개의 스레드만 실행되며, 컨텍스트 스위칭이 전혀 발생하지 않습니다. 또한, 블로킹된 스레드가 완전히 사라지고, 대신 경량 객체인 컨티뉴에이션(Continuation)이 사용됩니다. Swift 동시성에서는 스레드가 작업을 실행할 때, 전체적인 스레드 컨텍스트 스위칭을 수행하는 것이 아니라, 컨티뉴에이션 간 전환을 수행합니다. 이를 통해 스케줄링 오버헤드를 줄이고 CPU를 훨씬 더 효율적으로 활용할 수 있게 되었습니다.
Swift 동시성에서는 스레드가 작업을 실행할 때 전체적인 스레드 컨텍스트 스위칭을 수행하는 대신, 컨티뉴에이션 간 전환을 수행합니다. 이는 이제 함수 호출 비용만 지불하면 된다는 것을 의미합니다. 따라서 Swift 동시성이 목표로 하는 런타임 동작은 CPU 코어 수만큼의 스레드만 생성하고, 스레드가 블로킹될 때 비용이 거의 들지 않는 방식으로 작업 간 전환을 수행하는 것입니다. 이를 통해 직관적으로 이해할 수 있는 직선형 코드를 작성하면서도 안전하고 구조화된 동시성을 제공하는 것을 목표로 합니다.

이러한 동작을 실현하기 위해서는 운영 체제가 스레드를 블로킹하지 않을 것이라는 런타임 계약(runtime contract)을 필요로 하며, 이를 보장하려면 언어 차원에서 지원이 이루어져야 합니다. Swift의 동시성 모델과 그에 따른 의미론은 이러한 목표를 염두에 두고 설계되었습니다. 이를 위해 Swift는 런타임과의 계약을 유지할 수 있도록 두 가지 언어적 기능을 제공합니다. 첫 번째는 await의 의미론, 두 번째는 Swift 런타임에서의 태스크(task) 종속성 추적입니다. 이제 이러한 언어 기능이 어떻게 동작하는지, 그리고 우리 뉴스 앱의 예제 코드에서 어떻게 적용될 수 있는지 살펴보겠습니다.
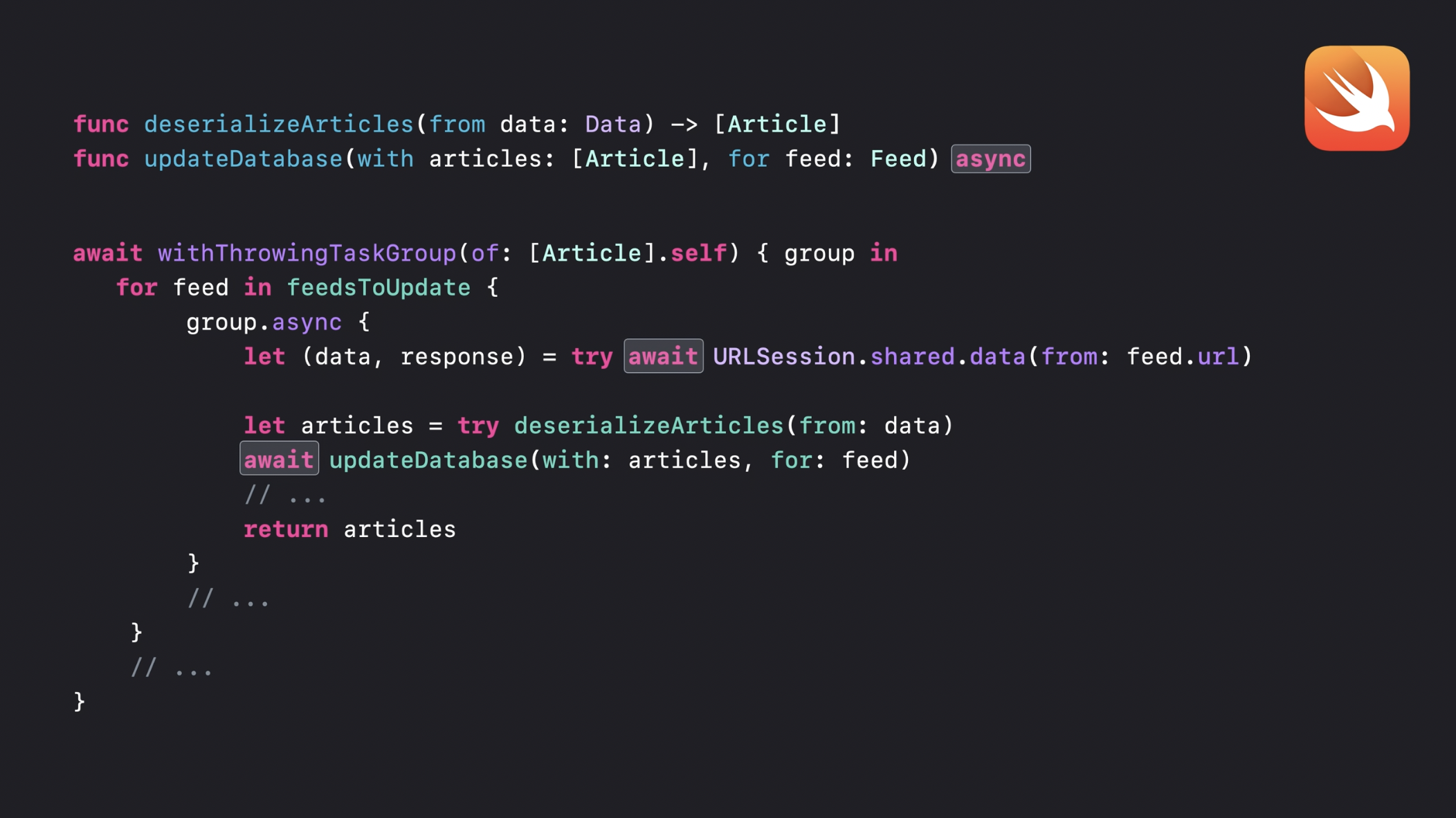
이제 동일한 로직을 Swift 동시성 기본 요소를 사용하여 작성하면 어떻게 달라지는지 살펴보겠습니다. 먼저, 도우미(helper) 함수의 비동기 버전을 구현하는 것으로 시작합니다. 그런 다음, 네트워크 요청 결과를 처리하기 위해 동시 디스패치 큐를 사용하는 대신, 태스크 그룹(task group)을 사용하여 동시성을 관리합니다. 태스크 그룹 내에서,업데이트해야 하는 각 피드에 대해 자식 태스크(child task)를 생성합니다. 각 자식 태스크는 공유된 URLSession을 사용하여 피드의 URL에서 데이터를 다운로드합니다. 이후, 다운로드한 데이터를 역직렬화하여 기사 형식으로 변환한 다음, 마지막으로 비동기 함수를 호출하여 데이터베이스를 업데이트합니다.
이 과정에서 모든 비동기 함수 호출에는 await 키워드를 사용합니다. “Meet async/await in Swift” 세션에서 배운 것처럼, await은 비동기 대기(asynchronous wait)를 수행합니다. 즉, async 함수의 결과를 기다리는 동안 현재 스레드를 블로킹하지 않습니다. 대신, 함수는 일시 중단(suspended)될 수 있으며, 해당 스레드는 다른 작업을 수행할 수 있도록 해제됩니다. 그렇다면, 이러한 동작이 어떻게 가능할까요? 스레드는 어떻게 해제될 수 있을까요? 이제 제 동료 바룬이 Swift 런타임 내부에서 어떤 처리가 이루어지는지 설명해 드리겠습니다.
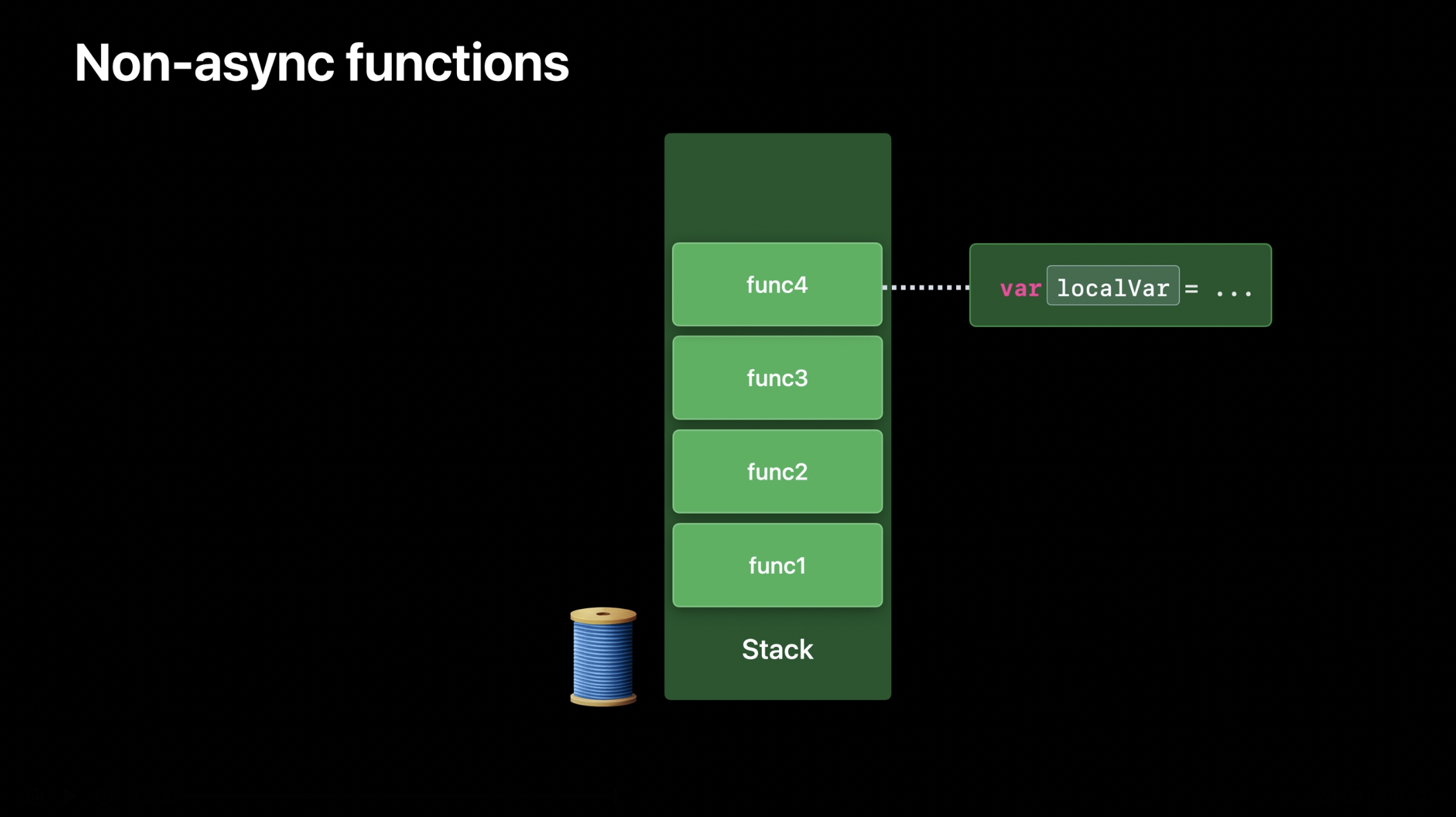
바룬 간디: 감사합니다, 로키니. 비동기 함수가 어떻게 구현되는지 살펴보기 전에, 먼저 일반적인 동기 함수가 어떻게 동작하는지 간단히 복습해 보겠습니다. 실행 중인 프로그램에서 각 스레드는 하나의 스택을 가지고 있으며, 이를 사용하여 함수 호출의 상태를 저장합니다. 지금은 하나의 스레드만 집중해서 살펴보겠습니다. 스레드가 함수를 호출하면, 새로운 스택 프레임(stack frame)이 해당 스레드의 스택에 푸시됩니다. 새롭게 생성된 스택 프레임은 해당 함수가 지역 변수, 반환 주소 그리고 실행을 위해 필요한 기타 정보를 저장하는 공간으로 사용됩니다. 함수가 실행을 마치고 반환되면, 해당 스택 프레임은 팝(pop)되어 제거됩니다.
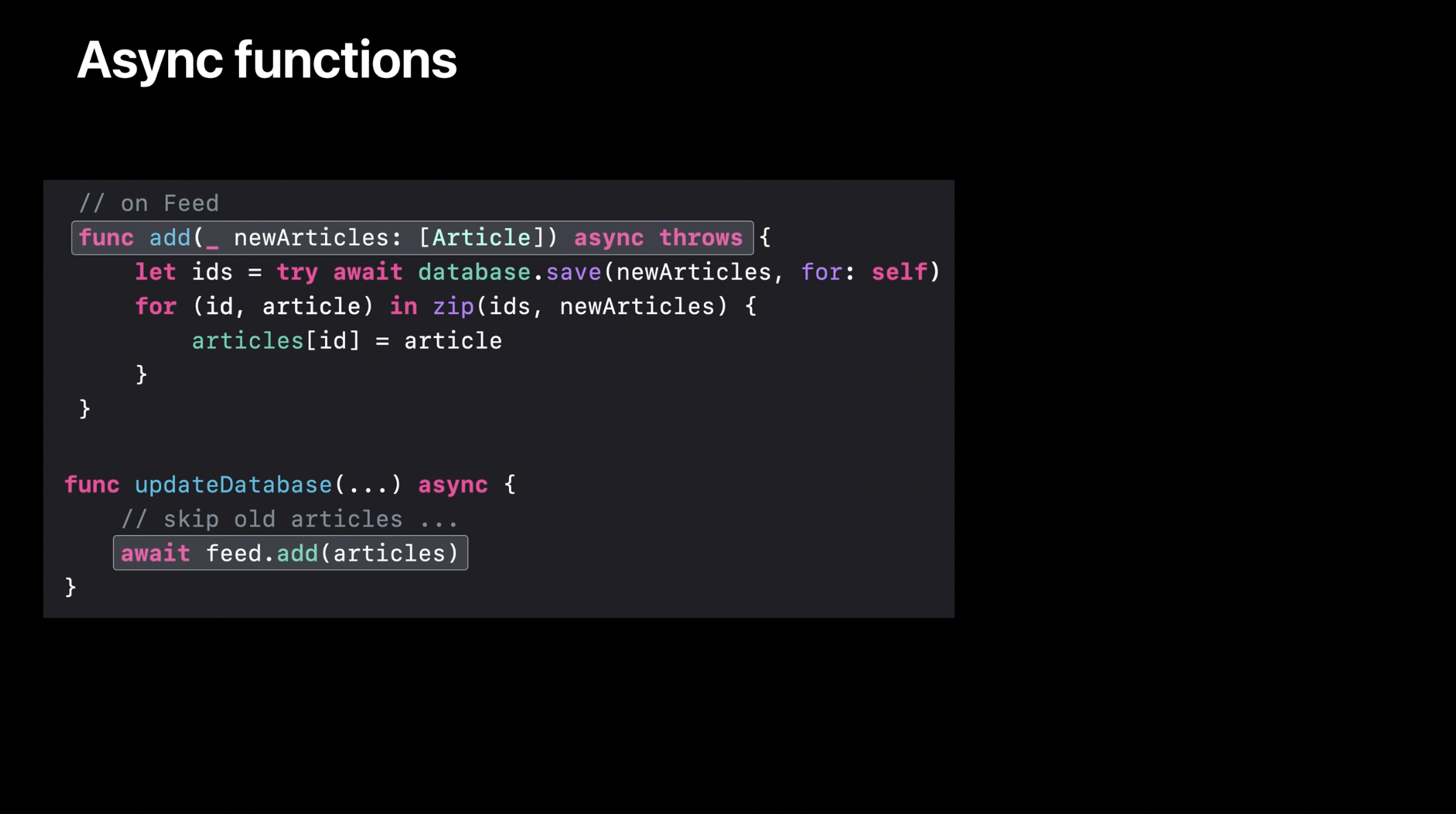
이제 비동기 함수의 동작을 살펴보겠습니다. 예를 들어, 스레드가 updateDatabase 함수 내에서 Feed의 add(_:) 메서드를 호출했다고 가정해 보겠습니다. 이 시점에서 최상단의 스택 프레임은 add(:) 함수가 됩니다. 스택 프레임은 일시 중단과 관련이 없는 지역 변수들을 저장합니다. _add(_:)의 본문을 보면, await 키워드로 표시된 하나의 일시 중단 지점이 있습니다. 이제 id와 article이라는 지역 변수를 살펴보겠습니다. 로컬 변수인 id와 article은 정의된 직후, 중간에 일시 중단 지점 없이 즉시 for 루프 본문에서 사용됩니다. 따라서 이 변수들은 기존의 스택 프레임에 저장됩니다.

또한, 힙에는 updateDatabase와 add를 위한 두 개의 비동기 프레임이 존재하게 됩니다. 비동기 프레임은 일시 중단 지점들을 넘어 계속 필요할 정보를 저장합니다. newArticles 인자가 await 이전에 정의되었지만 await 이후에도 필요하다는 점에 주목하세요. 이는 add의 비동기 프레임이 newArticles를 추적해야 함을 의미합니다.


이제 스레드가 실행을 계속한다고 가정해 보겠습니다. save 함수가 실행되기 시작하면, add의 스택 프레임은 save의 스택 프레임으로 대체됩니다. 새로운 스택 프레임이 추가되는 대신, 최상위 스택 프레임이 교체됩니다. 이는 앞으로 필요할 변수들이 이미 비동기 프레임 목록에 저장되어 있기 때문입니다.
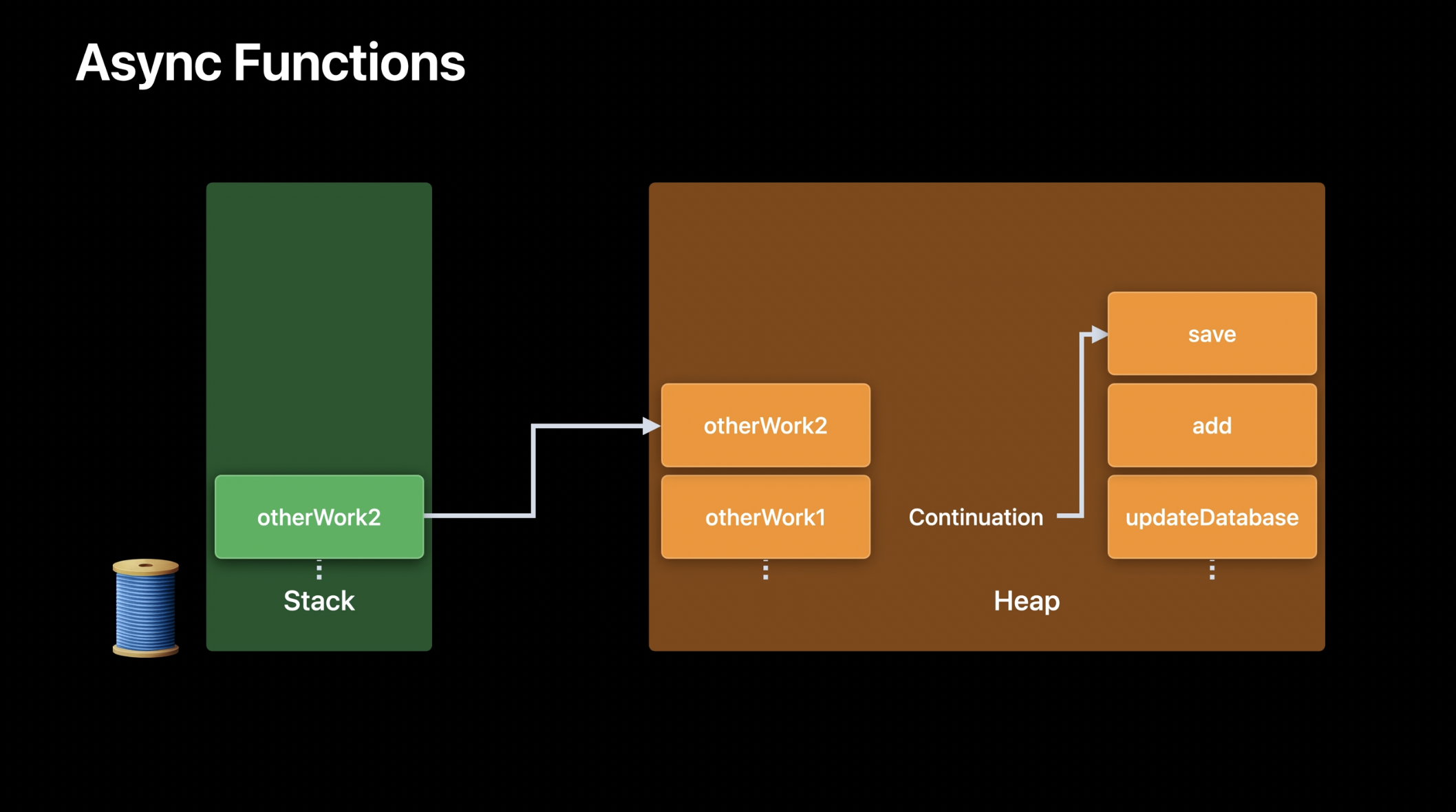
이제 save 함수가 데이터베이스에 기사를 저장하는 동안, 스레드가 블로킹되는 대신 유용한 다른 작업을 수행하는 것이 더 효율적입니다. 이를 위해, save 함수의 실행이 일시 중단(suspended)된다고 가정해 보겠습니다. 이 경우, 현재 스레드는 블로킹되지 않고 다른 작업을 수행하는 데 재사용될 수 있습니다. 그리고 일시 중단 지점 이후에도 유지되어야 하는 모든 정보는 힙에 저장되어 있기 때문에, 이후 실행을 재개할 때 사용할 수 있습니다. 이 비동기 프레임 목록은 실행 흐름을 저장하는 컨티뉴에이션의 런타임 표현입니다.



잠시 후 데이터베이스 요청이 완료되고, 사용 가능한 스레드가 하나 해제되었다고 가정해 보겠습니다. 이 스레드는 이전과 동일한 스레드일 수도 있고, 다른 스레드일 수도 있습니다. 이제 save 함수가 해당 스레드에서 다시 실행을 재개한다고 가정해 보겠습니다. save 함수가 실행을 마치고 일부 ID를 반환하면, 기존의 save 함수 스택 프레임은 제거되고, 다시 add(_:) 함수의 스택 프레임이 복원됩니다. 그 이후, 스레드는 zip 함수를 실행할 수 있습니다. 배열 두 개를 합치는 zip 연산은 비동기 함수가 아니므로, 새로운 스택 프레임이 생성됩니다.
Swift는 운영체제의 기존 스택을 그대로 활용하기 때문에, 비동기 코드와 일반 동기 코드가 원활하게 상호 호출될 수 있습니다. 따라서 Swift의 비동기 코드에서 C 및 Objective-C 함수를 효율적으로 호출할 수 있으며, 반대로 C 및 Objective-C 코드에서도 Swift의 동기 함수를 성능 저하 없이 호출할 수 있습니다. 마지막으로 zip 함수가 실행을 마치면, 해당 스택 프레임은 팝(pop)되고 실행이 계속 진행됩니다.
지금까지 await이 어떻게 설계되어 있는지 설명하면서, 효율적인 일시 중단과 재개를 보장하는 동시에, 스레드의 리소스를 해제하여 다른 작업을 수행할 수 있도록 하는 방식에 대해 알아보았습니다. 이제, 두 번째 언어 기능인 Swift 런타임에서의 태스크 간 종속성 추적에 대해 로키니가 설명해 드리겠습니다.
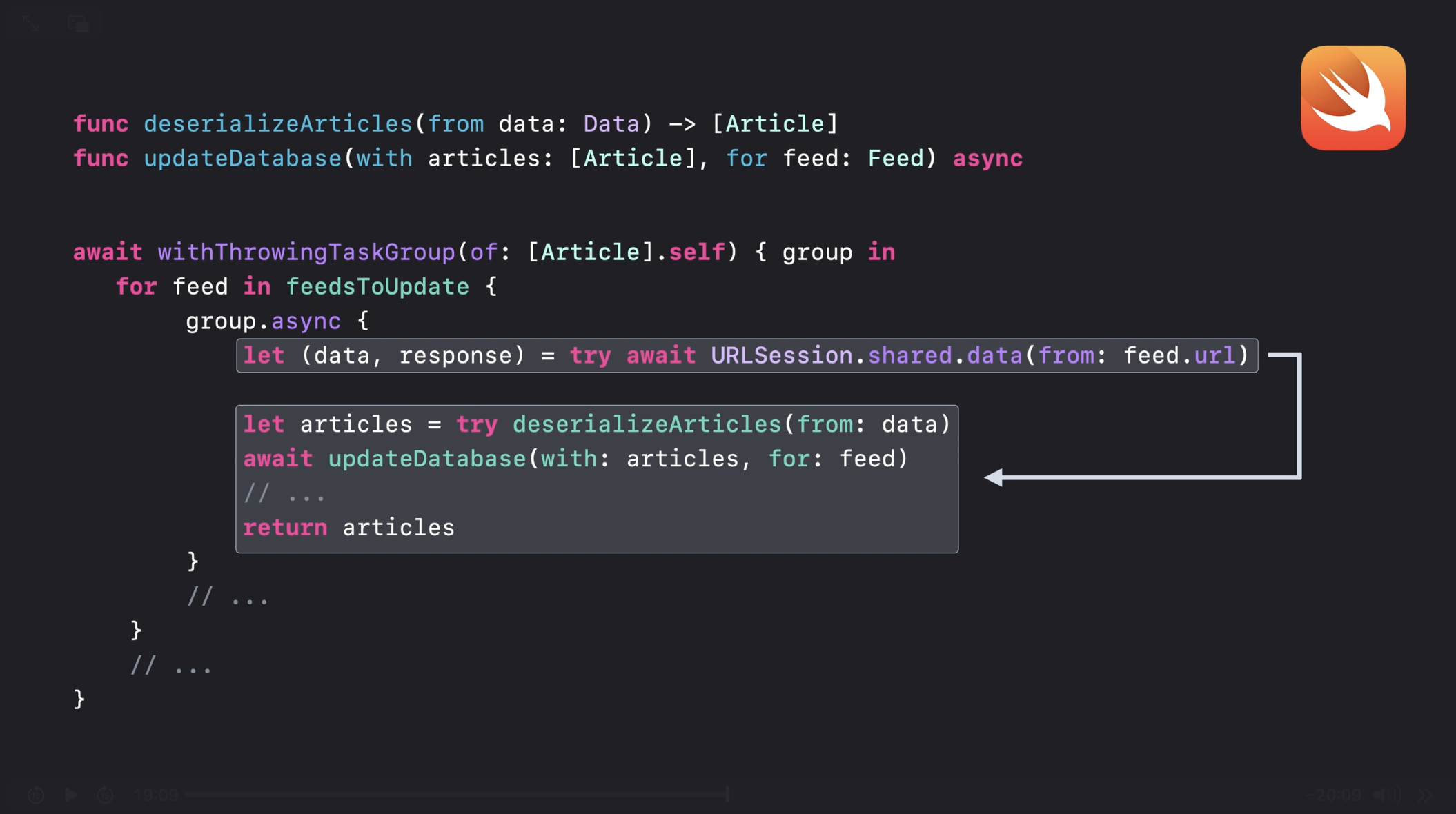
로키니 프라부: 감사합니다, 바룬. 앞서 설명한 것처럼, 함수는 await 지점을 기준으로 컨티뉴에이션 단위로 나뉠 수 있습니다. await은 일시 중단 지점을 의미하며, 이후 실행을 다시 이어가기 위한 경계를 형성합니다. 예를 들어, URLSession의 데이터 작업이 비동기 함수라고 가정하면, 이 함수가 실행된 후 이어지는 모든 작업이 컨티뉴에이션이 됩니다. 즉, URLSession의 데이터 작업이 완료된 후에만 이후 컨티뉴에이션이 실행될 수 있습니다. 이러한 실행 순서의 의존성은 Swift 동시성 런타임에서 자동으로 추적되며, 이를 통해 시스템이 작업 흐름을 효율적으로 조정할 수 있습니다.

마찬가지로, 태스크 그룹 내에서 부모 태스크가 여러 개의 자식 태스크를 생성할 수 있으며, 부모 태스크는 모든 자식 태스크가 완료된 후에만 실행을 계속할 수 있습니다. 이러한 종속성은 코드에서 태스크 그룹의 범위(scope)를 통해 표현되며, Swift 컴파일러와 런타임이 이를 명확하게 인식할 수 있도록 설계되었습니다. Swift에서는 오직 Swift 런타임이 인식할 수 있는 작업만 await할 수 있습니다. 즉, 컨티뉴에이션이든 자식 태스크든, Swift 런타임이 관리하는 작업들만 await을 사용할 수 있습니다. 따라서, Swift 동시성 기본 요소를 사용하여 코드를 구조화하면, 런타임이 태스크 간의 종속성 체인(dependency chain)을 명확하게 파악할 수 있으며, 이를 기반으로 실행 순서를 효율적으로 관리할 수 있습니다.

지금까지 Swift의 언어 기능을 통해 await 중에 작업이 일시 중단될 수 있다는 점을 배웠습니다. 대신 실행 중인 스레드는 작업 간의 의존성을 분석하고 다른 작업을 수행할 수 있습니다. 즉, Swift 동시성을 활용하여 작성된 코드는 지속적으로 실행 가능해야 한다는 런타임 계약을 유지합니다. 우리는 이 런타임 계약을 활용하여 Swift 동시성을 위한 통합된 운영체제 지원을 구축했습니다. 이는 Swift 동시성을 위한 새로운 협력형 스레드 풀(cooperative thread pool)의 형태로 제공되며, Swift 동시성의 기본 실행자(default executor)로 작동합니다.
새로운 스레드 풀은 CPU 코어 수만큼의 스레드만 생성하여 시스템에 과부하가 걸리지 않도록 합니다. GCD의 동시 큐는 작업이 블로킹될 때 더 많은 스레드를 생성하는 것과 달리, Swift에서는 스레드가 항상 진행할 수 있습니다. 따라서 기본 런타임은 생성되는 스레드의 수를 신중하게 제어할 수 있습니다. 이를 통해 애플리케이션에 필요한 동시성을 제공하면서도 과도한 동시성으로 인한 잘 알려진 문제를 방지할 수 있습니다.

이전 WWDC에서 GCD를 활용한 동시성에 대해 다룰 때, 우리는 애플리케이션을 명확한 서브 시스템으로 구조화하고, 각 서브 시스템당 하나의 직렬 디스패치 큐를 유지하여 동시 실행을 제어할 것을 권장했습니다. 이 접근 방식에서는 서브 시스템 내에서 동시 실행 수준을 1보다 높게 설정하기가 어려웠으며, 이를 무리하게 시도하면 스레드 폭발 위험이 발생할 수 있었습니다.
그러나 Swift에서는 언어 차원에서 강력한 불변성을 제공하며, 런타임은 이를 활용하여 기본 런타임 환경에서 보다 안정적으로 동시 실행을 제어할 수 있습니다. 이제 Swift 동시성의 스레딩 모델에 대해 조금 더 이해했으므로, 이러한 혁신적인 기능을 코드에 도입할 때 고려해야 할 몇 가지 사항을 살펴보겠습니다.

첫 번째로 고려해야 할 사항은 동기 코드를 비동기 코드로 변환할 때의 성능 비용입니다. 앞서 동시성과 관련된 비용으로 추가적인 메모리 할당과 Swift 런타임에서의 로직 처리 비용이 발생할 수 있다는 점을 설명드렸습니다. 따라서, 단순히 동시성을 도입하는 것 자체가 무조건적인 성능 향상을 보장하지 않으며, 동시성을 관리하는 비용이 그 도입으로 인한 이점보다 높아지는 경우도 있을 수 있습니다.
예를 들어, 여기 있는 코드 조각에서 단순히 UserDefaults에서 값을 읽기 위해 자식 태스크를 생성하는 것은 별다른 성능 향상을 가져오지 않습니다. 오히려, 자식 태스크를 생성하고 관리하는 비용이 실제로 수행되는 유용한 작업보다 커질 수 있습니다. 따라서, Swift 동시성을 도입할 때는 인스트루먼츠(Instruments)의 시스템 트레이스를 활용하여 코드의 성능을 프로파일링할 것을 권장합니다. 이를 통해, 동시성 도입이 실제로 성능 개선에 기여하는지 확인하고, 불필요한 태스크 생성을 방지할 수 있습니다.


두 번째로 주의해야 할 점은 await을 기준으로 한 원자성(atomicity) 개념입니다. Swift는 await 이전에 코드를 실행한 스레드가 이후의 처리를 이어받는 동일한 스레드일 것이라고 보장하지 않습니다. 사실상 await은 코드에서 원자성이 깨지는 명시적인 지점이며, 이 시점에서 태스크가 자발적으로 스케줄링에서 제외될 수 있습니다. 따라서 await을 넘어서는 동안 락을 유지하지 않도록 주의해야 합니다.
마찬가지로, 스레드별 데이터도 await을 넘어서 유지되지 않습니다. 따라서 코드에서 스레드 로컬(thread-local) 데이터에 의존하는 부분이 있다면, await의 일시 중단 동작을 고려하여 다시 검토해야 합니다.
마지막으로 고려해야 할 사항은 Swift의 효율적인 스레딩 모델의 기반이 되는 런타임 계약입니다. Swift에서는 스레드가 지속적으로 실행 가능해야 한다는 한다는 런타임 계약을 유지하도록 설계되어 있습니다. 이 계약을 바탕으로 우리는 협력형 스레드 풀을 기본 실행기로 구축했습니다. Swift 동시성을 도입할 때는 이 계약을 코드에서도 유지해야 하며, 그래야 협력형 스레드 풀이 최적의 성능을 발휘할 수 있습니다.

Swift의 await, actor, task group과 같은 동시성 기본 요소를 사용하면 이러한 의존성이 컴파일 시점에 명확해집니다. 따라서 Swift 컴파일러가 이를 강제하여 런타임 계약을 유지하도록 도와줍니다.
os_unfair_lock과 NSLock 같은 기본 동기화 요소도 안전하게 사용할 수 있지만, 주의가 필요합니다. 동기 코드에서 잘 정의된 작은 임계 구역(ciritical section) 내에서 데이터 동기화를 위해 락을 사용하는 것은 안전합니다. 이는 락을 보유한 스레드가 항상 락을 해제하는 방향으로 실행할 수 있기 때문입니다. 따라서 경쟁 상태(contention)에서 일시적으로 스레드가 블록될 수는 있지만, 스레드가 지속적으로 실행 가능해야 한다는 런타임 계약을 위반하지는 않습니다. 하지만, Swift 동시성 요소와 달리, 컴파일러가 락의 올바른 사용을 보장해 주지는 않습니다. 즉, 락을 올바르게 사용하는 것은 전적으로 개발자의 책임이라는 점을 기억해야 합니다.

반면, 세마포어(semaphore)나 조건 변수(condition variable)와 같은 기본 요소는 Swift 동시성과 함께 사용하기에 안전하지 않습니다. 이는 이러한 기법이 Swift 런타임에서 의존성 정보를 숨기지만, 실제 코드 실행에서는 의존성을 생성하기 때문입니다. 런타임이 이러한 의존성을 인식하지 못하면 적절한 스케줄링 결정을 내릴 수 없으며, 이를 해결할 수도 없습니다. 특히, 구조화되지 않은(unstructured) 태스크를 생성한 후, 세마포어나 안전하지 않은 기본 요소를 사용하여 태스크 경계를 넘나드는 의존성을 나중에 도입하는 패턴은 피해야 합니다. 이러한 방식의 코드는 한 스레드가 세마포어에서 무기한 블로킹될 수 있으며, 다른 스레드가 이를 해제할 때까지 실행되지 않을 수도 있습니다. 이는 스레드가 지속적으로 실행 가능해야 한다는 Swift 런타임의 런타임 계약을 위반하게 됩니다.
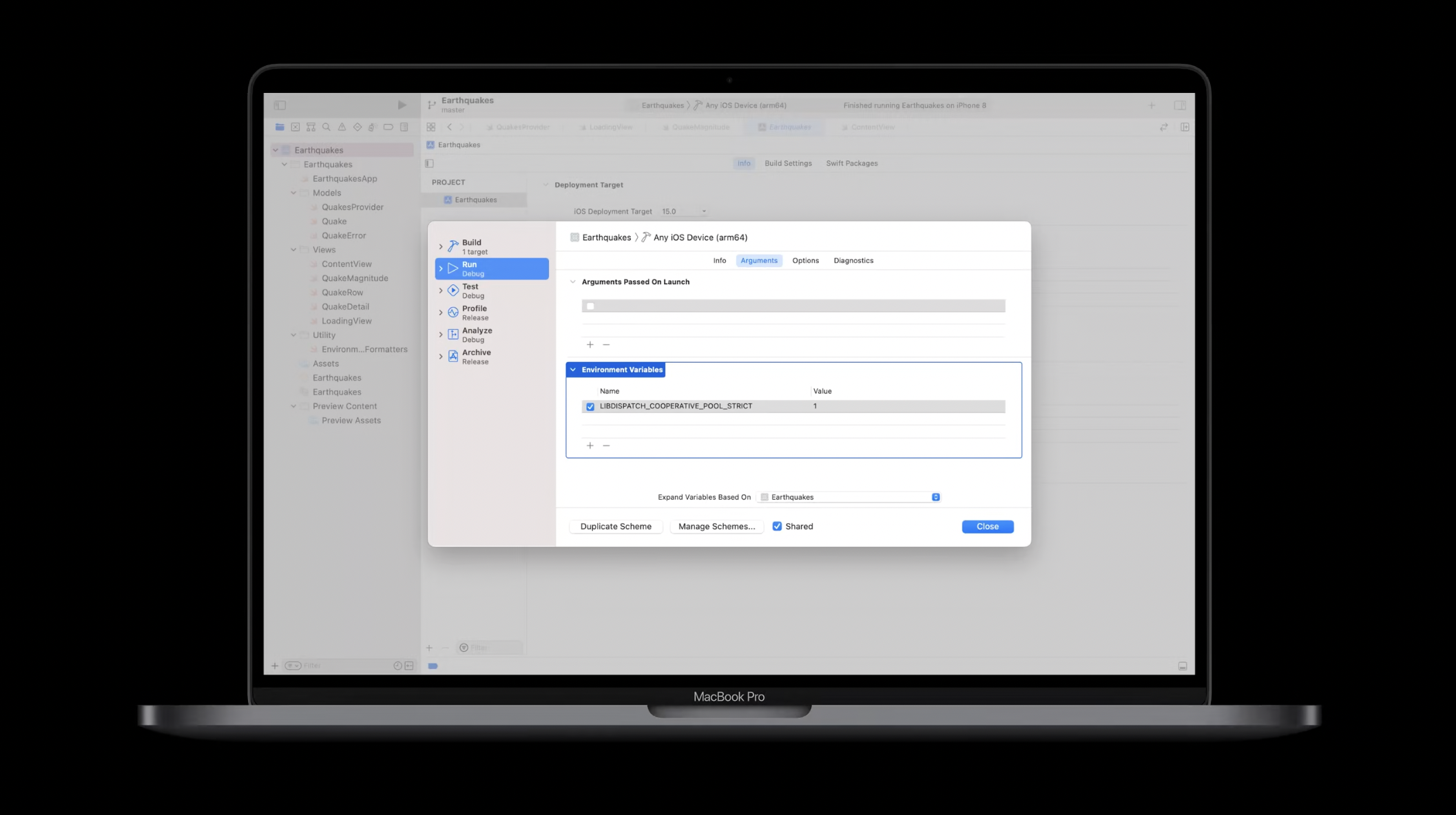
코드 베이스에서 이러한 안전하지 않은 요소의 사용을 식별하는 데 도움을 주기 위해, 다음 환경 변수를 사용하여 앱을 테스트할 것을 권장합니다. 이 환경 변수를 설정하면, 앱이 실행될 수 있어야 한다는 불변성을 강제하는 수정된 디버그 런타임에서 실행됩니다. 이 환경 변수는 Xcode에서 프로젝트 스킴의 “Run Arguments” 패널에서 설정할 수 있으며, 보이는 그림과 같이 구성할 수 있습니다. 이 설정으로 앱을 실행할 때, 협력형 스레드 풀 내의 스레드가 멈춘 것처럼 보인다면, 이는 안전하지 않은 블로킹 요소가 사용되었음을 의미합니다.
이제 Swift 동시성을 위한 스레딩 모델이 어떻게 설계되었는지 이해했으니, 이 새로운 환경에서 상태를 동기화하기 위해 사용할 수 있는 요소들을 더 자세히 살펴보겠습니다.
바룬 간디: Swift 동시성에서 액터는 변할 수 있는 상태를 동시 접근으로부터 보호하는 데 사용할 수 있습니다. 다시 말해, 액터는 강력한 새로운 동기화 기본 요소를 제공합니다. 액터는 상호 배제(mutual exclusion)를 보장합니다. 즉, 하나의 액터는 한 번에 오직 하나의 메서드 호출만 실행할 수 있습니다. 이러한 상호 배제는 액터의 상태가 동시에 접근되지 않도록 보장하며, 경쟁 상태(data race)를 방지하는 역할을 합니다. 따라서, 액터를 활용하면 기존의 락 기반 동기화보다 더 안전하고 직관적인 방식으로 상태를 관리할 수 있습니다.

이제 액터가 다른 형태의 상호 배제 방식과 어떻게 비교되는지 살펴보겠습니다. 앞서 예제로 들었던 직렬 큐를 사용하여 데이터베이스를 업데이트하는 방식을 다시 생각해 보겠습니다. 만약 큐가 현재 실행 중이 아니라면, 경쟁 상태(contention)가 없다고 말할 수 있습니다. 이 경우, 호출한 스레드는 컨텍스트 스위칭 없이 그대로 큐에서 새로운 작업 항목을 실행하는 데 재사용됩니다. 반면, 큐가 이미 실행 중이라면, 즉 직렬 큐가 경쟁 상태에 있다면, 새로운 작업은 큐에서 순서를 기다려야 하며, 기존 작업이 완료될 때까지 실행되지 않습니다. 이러한 상황에서는 호출한 스레드가 블로킹됩니다. 이러한 블로킹 동작이 바로 앞서 로키니가 설명한 스레드 폭발의 주요 원인입니다.
락도 같은 방식으로 동작합니다. 즉, 경쟁 상태가 발생하면 호출한 스레드가 블로킹되며, 다른 스레드가 해당 락을 해제할 때까지 대기해야 합니다. 이러한 블로킹 문제를 피하기 위해, 일반적으로 비동기 디스패치를 사용하는 것이 더 바람직한 방식이라고 권장해 왔습니다. 비동기 디스패치의 가장 큰 장점은 논-블로킹이라는 점입니다. 즉, 경쟁 상태가 발생해도 호출한 스레드를 블로킹하지 않으므로, 스레드 폭발로 이어지지 않습니다.
하지만 비동기 디스패치를 직렬 큐와 함께 사용할 때의 단점도 존재합니다. 경쟁 상태가 없는 경우에도 비동기 디스패치는 호출한 스레드와는 별도로 비동기 작업을 실행할 새로운 스레드를 요청합니다. 호출한 스레드는 다른 작업을 수행할 수 있지만, 그 과정에서 추가적인 스레드 활성화(thread wake-up)와 컨텍스트 스위칭이 발생할 수 있습니다. 따라서, 비동기 디스패치를 너무 자주 사용하면 불필요한 스레드 전환이 증가하여 성능이 저하될 가능성이 있습니다.
이제 액터에 대해 살펴보겠습니다. Swift의 액터는 협력형 스레드 풀을 활용하여 효율적인 스케줄링을 제공하며, 직렬 큐와 비동기 디스패치의 장점을 결합한 방식으로 동작합니다. 액터의 메서드를 호출할 때, 해당 액터가 현재 실행 중이지 않다면, 호출한 스레드는 그대로 재사용되어 해당 메서드를 실행할 수 있습니다. 반면, 해당 액터가 이미 실행 중인 경우, 호출한 스레드는 함수를 일시 중단하고, 다른 작업을 수행할 수 있도록 해제됩니다.
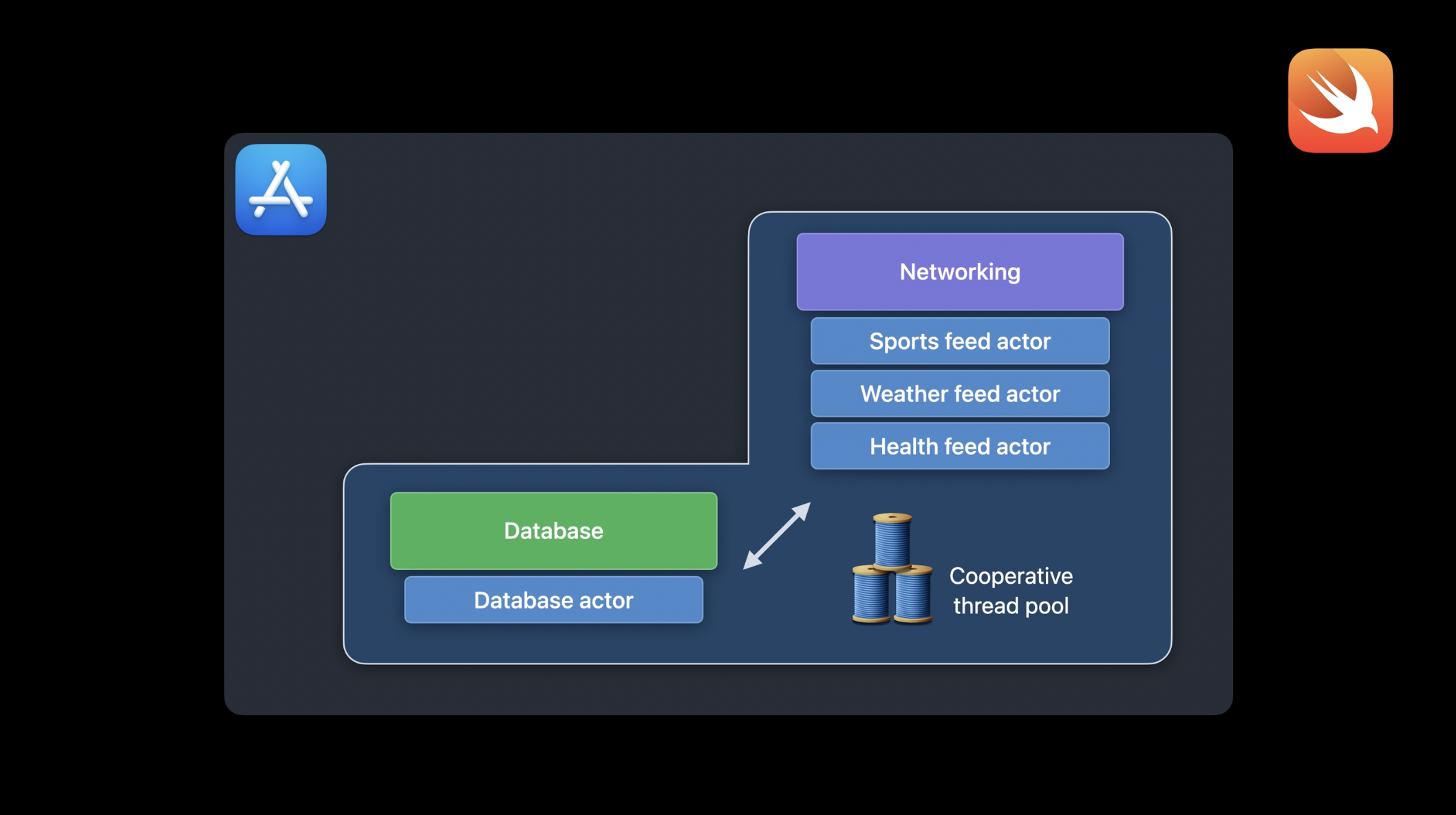
이제 이러한 두 가지 특성이 뉴스 앱 예제에서 어떻게 동작하는지 살펴보겠습니다. 데이터베이스와 네트워크 서브 시스템에 집중하여 설명하겠습니다. 애플리케이션을 Swift 동시성을 사용하도록 업데이트할 때, 데이터베이스를 위한 직렬 큐는 데이터베이스 액터로 대체될 수 있습니다. 네트워크를 위한 동시 큐는 각 뉴스 피드마다 하나의 액터를 두는 방식으로 변경할 수 있습니다. 간단한 예로, 여기에서는 스포츠, 날씨, 건강 피드에 대한 세 개의 피드 액터만 표시했지만, 실제로는 더 많은 액터가 존재할 수 있습니다. 이러한 액터들은 협력형 스레드 풀에서 실행되며, 피드 액터들은 데이터베이스와 상호작용하면서 기사를 저장하거나 기타 작업을 수행할 수 있습니다. 이 과정에서 한 액터에서 다른 액터로 실행이 전환되는 액터 홉핑(actor hopping) 현상이 발생합니다.
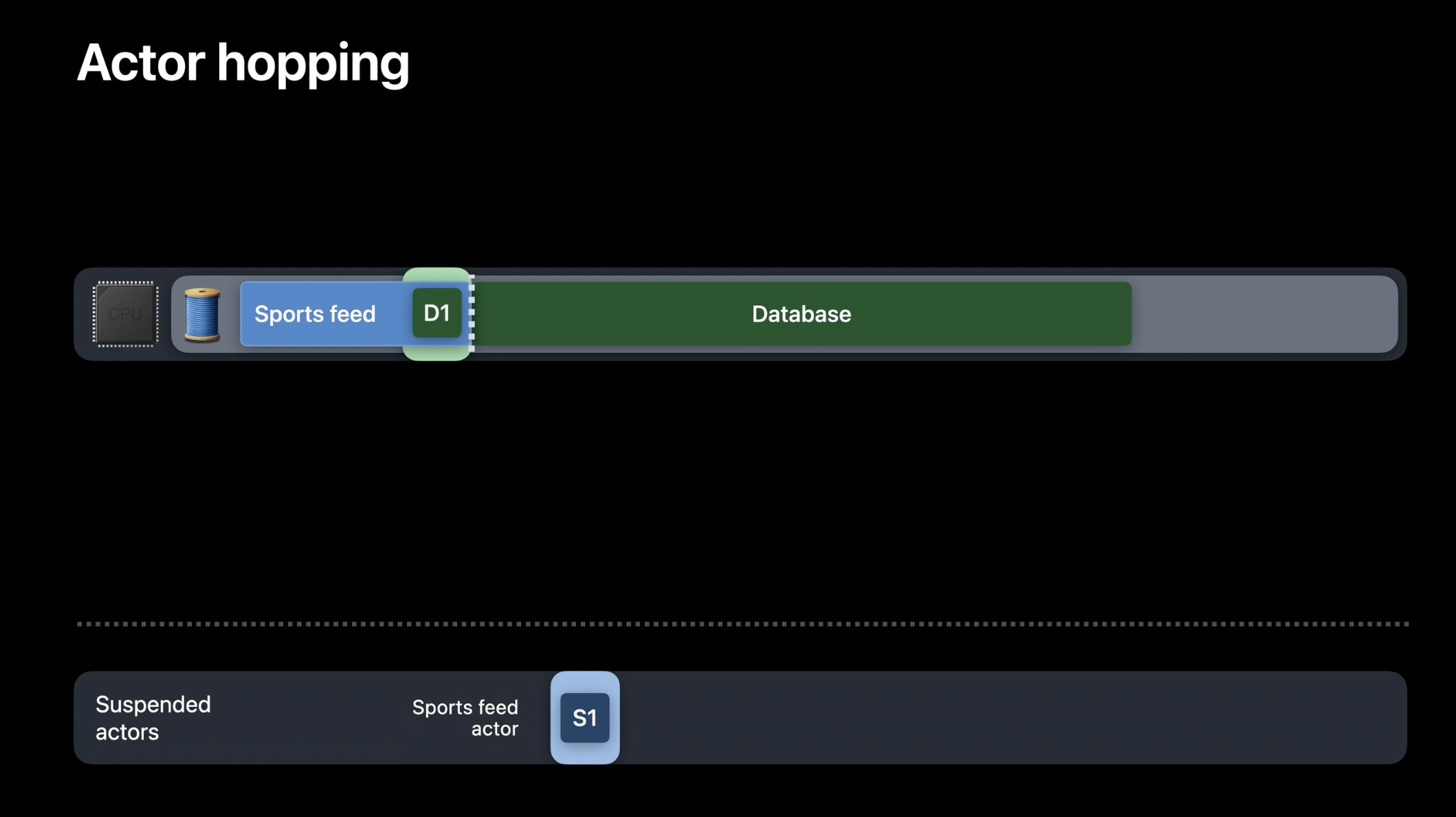
스포츠 피드 액터가 협력형 스레드 풀에서 실행 중이고, 일부 기사를 데이터베이스에 저장하려 한다고 가정하겠습니다. 현재 데이터베이스가 사용되지 않고 있는 경우, 이는 경쟁 상태가 없는 상황입니다. 이때, 스레드는 스포츠 피드 액터에서 데이터베이스 액터로 직접 전환될 수 있습니다. 여기에서 두 가지 중요한 점이 있습니다. 첫째, 액터 홉핑이 이루어지는 동안 스레드는 블로킹되지 않았습니다. 둘째, 홉핑을 위해 새로운 스레드를 생성할 필요 없이, 런타임이 스포츠 피드 액터의 작업을 일시 중단하고 데이터베이스 액터를 위한 새로운 작업을 생성하여 실행을 계속할 수 있습니다.
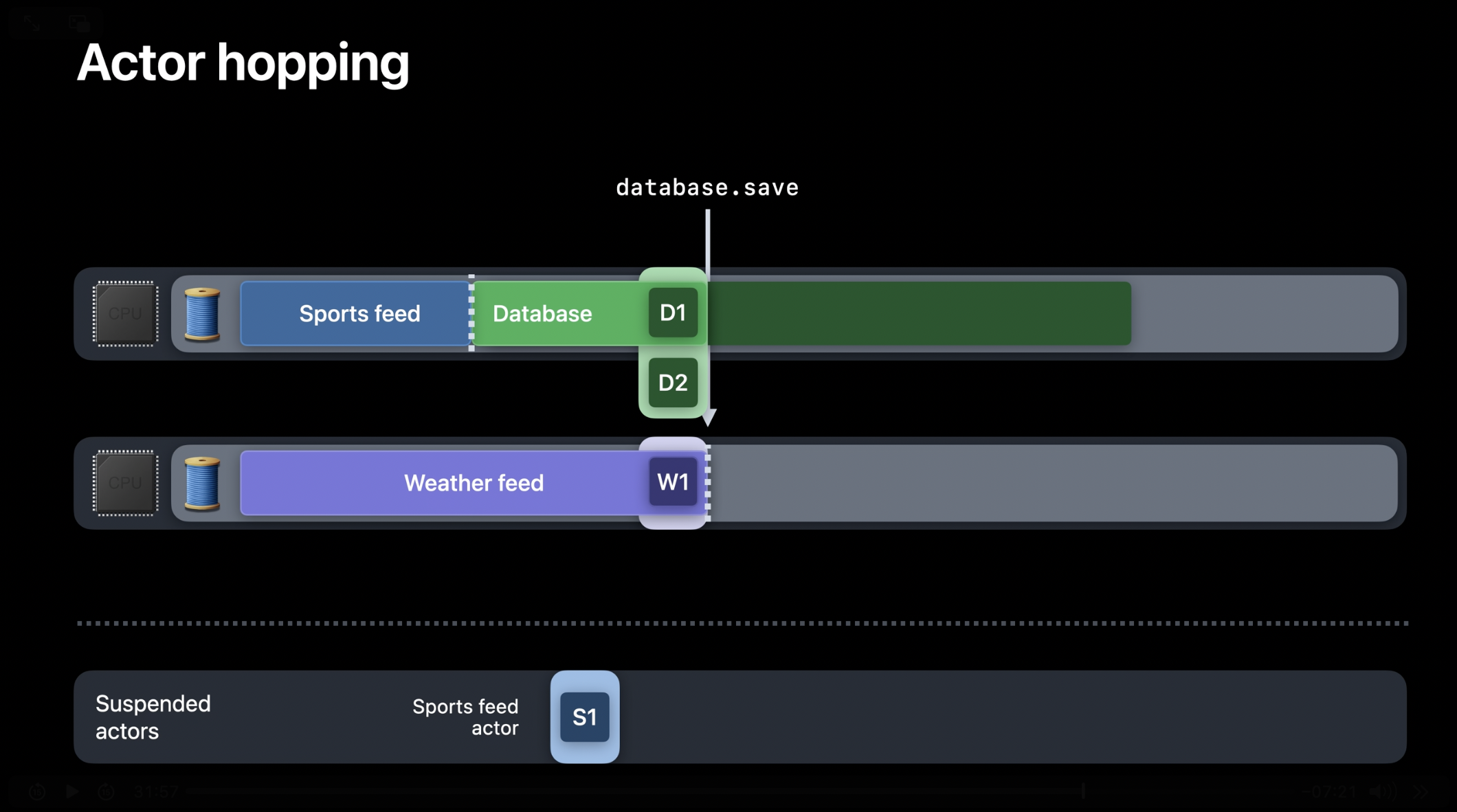
데이터베이스 액터가 일정 시간 동안 실행되었지만 첫 번째 작업을 아직 완료하지 않았다고 가정해 보겠습니다. 이때, 날씨 피드 액터가 데이터베이스에 몇 개의 기사를 저장하려고 합니다. 이는 데이터베이스 액터에 새로운 작업을 생성하게 됩니다. 액터는 상호 배제를 보장하여 안전성을 유지하는데, 즉, 한 번에 하나의 작업만 활성 상태일 수 있습니다. 현재 이미 활성화된 작업 D1이 있으므로, 새로 생성된 작업 D2는 대기 상태로 유지됩니다. 또한, 액터는 논-블로킹 방식으로 동작합니다. 따라서 이 상황에서 날씨 피드 액터는 일시 중단되며, 이를 실행하던 스레드는 다른 작업을 수행할 수 있도록 해제됩니다.
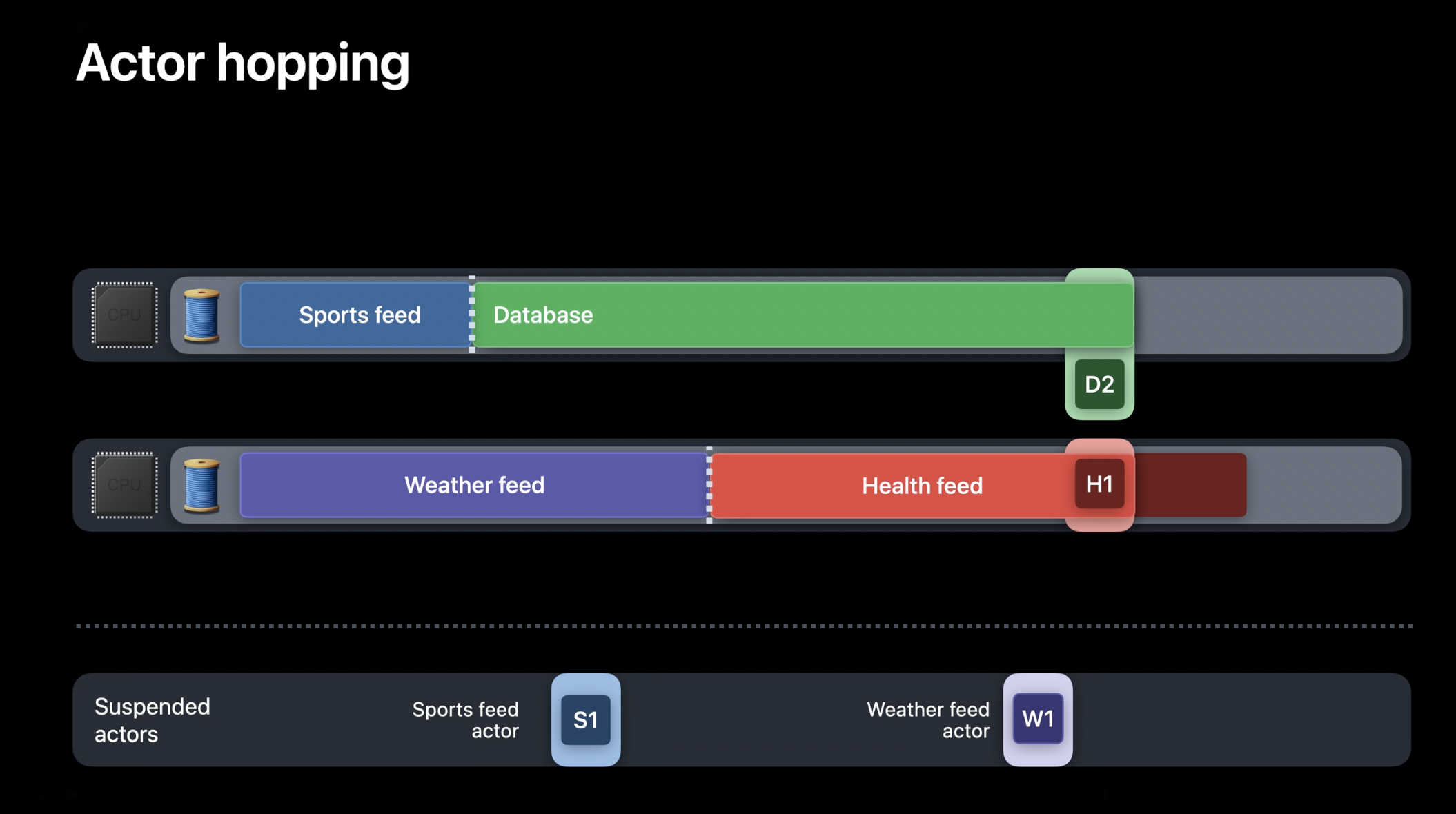
잠시 후, 최초의 데이터베이스 작업(D1)이 완료되면 데이터베이스 액터의 활성 작업이 제거됩니다. 이 시점에서 런타임은 대기 중이던 데이터베이스 액터의 다른 작업(D2)을 실행할 수도 있고, 피드 액터 중 하나를 다시 실행하거나 해제된 스레드를 사용해 다른 작업을 수행할 수도 있습니다. 비동기 작업이 많고 특히 경쟁 상태가 심한 경우, 시스템은 어떤 작업이 더 중요한지에 따라 적절한 트레이드-오프를 해야 합니다. 이상적으로는 사용자 상호작용과 관련된 고우선순위 작업이 백업 저장과 같은 백그라운드 작업보다 우선 처리되어야 합니다.
액터는 재진입성(reentrancy) 개념을 통해 시스템이 작업의 우선순위를 효과적으로 조정할 수 있도록 설계되었습니다. 하지만 여기서 재진입성이 왜 중요한지를 이해하려면, 먼저 GCD가 우선순위를 어떻게 처리하는지 살펴볼 필요가 있습니다.
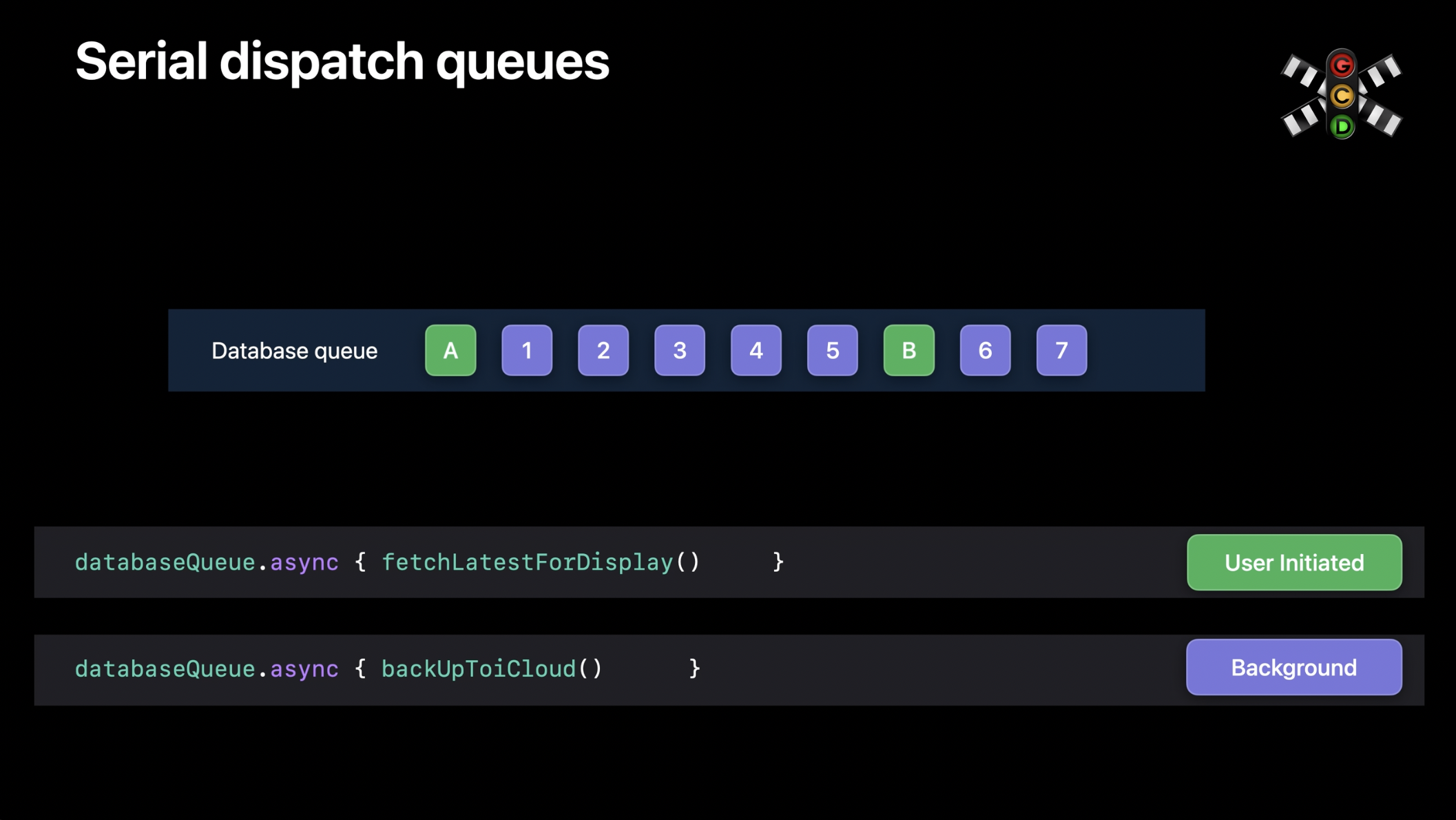
뉴스 앱에서 직렬 데이터베이스 큐를 사용하는 경우를 생각해 보겠습니다. 데이터베이스는 UI를 업데이트하기 위해 최신 데이터를 가져오는 작업과 같은 높은 우선순위 작업을 받을 수 있습니다. 또한, 데이터베이스를 iCloud에 백업하는 작업과 같은 낮은 우선순위 작업도 받을 수 있습니다. 이러한 작업은 결국 수행되어야 하지만, 즉시 실행될 필요는 없습니다. 코드가 실행되면서 새로운 작업들이 생성되어 데이터베이스 큐에 뒤섞인 순서로 추가됩니다. 디스패치 큐는 이러한 작업들을 엄격한 선입선출(FIFO) 방식으로 실행합니다. 문제는, 예를 들어 작업 A가 실행된 후, 5개의 낮은 우선순위 작업이 먼저 실행되어야만 다음 높은 선순위 작업이 실행될 수 있다는 점입니다. 이러한 현상을 우선순위 역전(priority inversion) 이라고 합니다.

직렬 큐는 우선순위 역전 문제를 해결하기 위해, 높은 우선순위 작업보다 앞서 있는 모든 작업의 우선순위를 일시적으로 높이는 방식으로 해결을 시도합니다. 이 방식은 큐에 있는 작업이 좀 더 빨리 처리되도록 하긴 하지만, 근본적인 문제는 해결되지 않습니다. 즉, 여전히 1번부터 5번까지의 작업이 완료되어야만 작업 B가 실행될 수 있습니다. 이 문제를 해결하려면 엄격한 선입선출 모델에서 벗어나야 합니다. 바로 여기서 액터의 재진입성 개념이 중요해집니다. 이제, 재진입성이 작업의 실행 순서와 어떻게 연결되는지 예제를 통해 살펴보겠습니다.
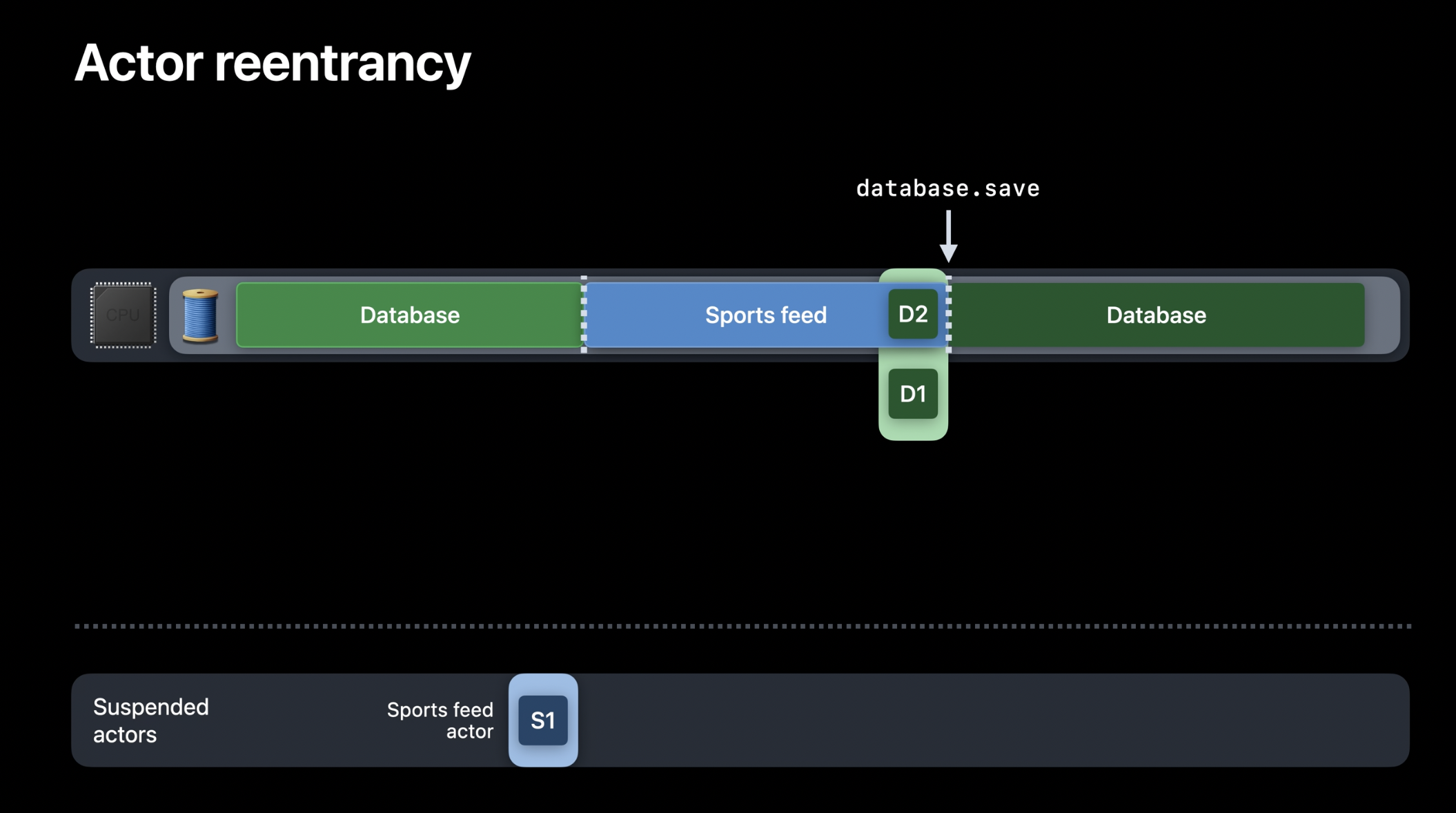
데이터베이스 액터가 한 스레드에서 실행되고 있다고 가정해 보겠습니다. 현재 데이터베이스 액터는 다른 작업을 기다리며 일시 중단된 상태이고, 그 스레드에서 스포츠 피드 액터가 실행되기 시작합니다. 잠시 후, 스포츠 피드 액터가 데이터베이스 액터를 호출하여 몇 개의 기사를 저장하려 한다고 가정해 보겠습니다. 현재 데이터베이스 액터는 다른 작업과 경쟁하고 있지 않으므로, 해당 스레드는 대기 중인 작업이 하나 있음에도 불구하고 데이터베이스 액터로 전환될 수 있습니다. 이 저장 작업을 수행하기 위해 데이터베이스 액터에 새로운 작업(D2)이 생성됩니다. 이처럼 하나 이상의 기존 작업이 일시 중단된 상태에서도 새로운 작업이 진행될 수 있는 것이 바로 액터의 재진입성입니다.
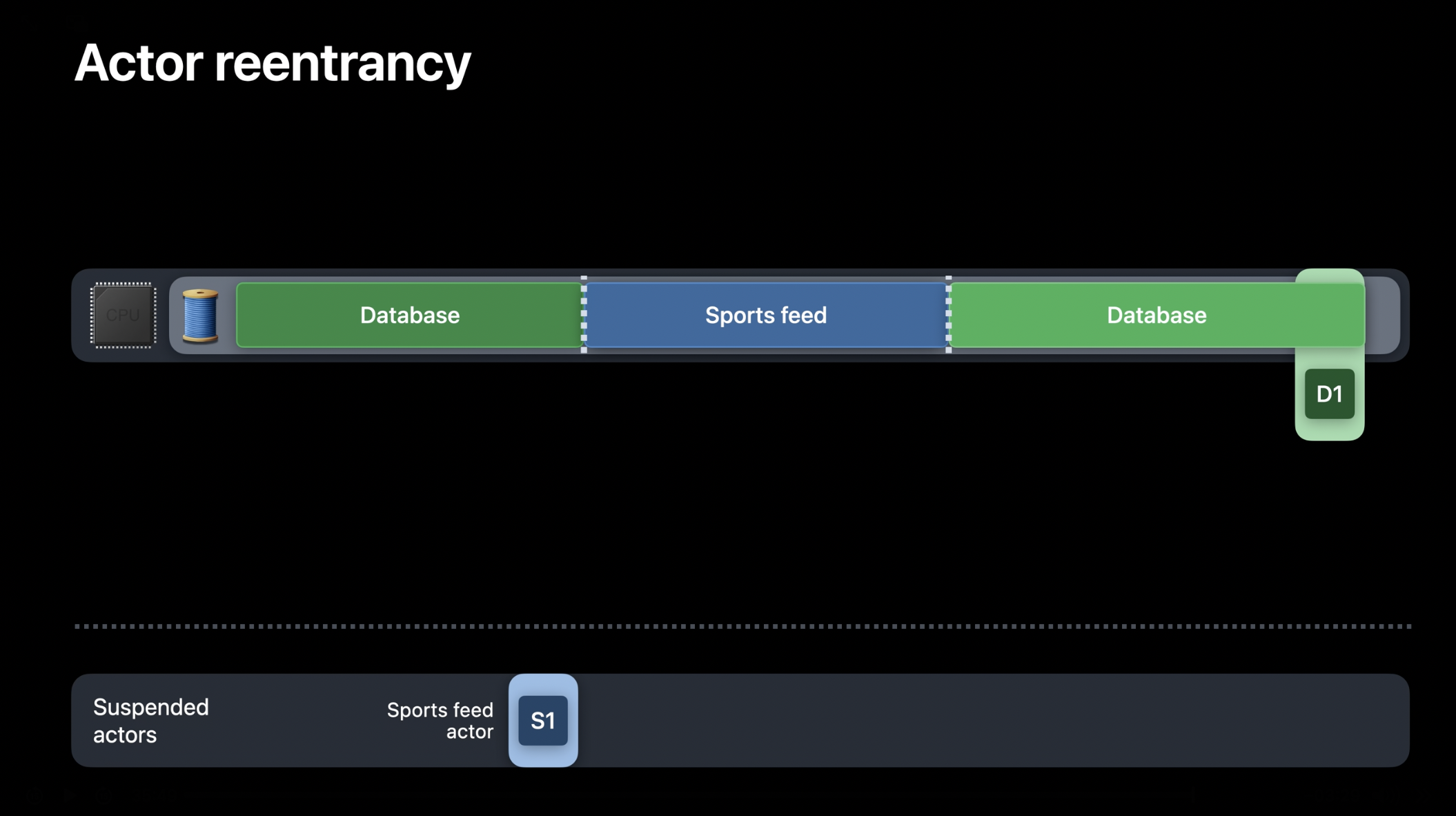
그러나 액터는 여전히 상호 배제를 유지합니다. 즉, 한 번에 하나의 작업만 실행될 수 있습니다. 어느 정도 시간이 흐른 후, 새로 생성된 작업 D2가 실행을 완료합니다. 여기서 중요한 점은, 작업 D2가 D1보다 나중에 생성되었음에도 불구하고 먼저 실행을 완료했다는 점입니다. 즉, 액터가 재진입성을 지원하면 작업 항목을 반드시 선입선출 순서대로 실행할 필요가 없게 됩니다.

앞서 살펴본 예제를 직렬 큐 대신 데이터베이스 액터를 사용하는 경우로 다시 생각해 보겠습니다. 먼저, 높은 우선순위 작업 A가 실행됩니다. 작업 A가 완료된 후, 이전과 동일한 우선순위 역전 문제가 발생할 수 있습니다. 그러나 액터는 재진입성을 지원하도록 설계되어 있기 때문에, 런타임은 높은 우선순위 작업 항목을 낮은 우선순위 작업들보다 앞쪽으로 이동시킬 수 있습니다. 즉, 높은 우선순위 작업이 먼저 실행되고, 낮은 우선순위 작업은 나중으로 밀려날 수 있습니다. 이 방식은 우선순위 역전 문제를 직접적으로 해결하며, 보다 효율적인 작업 스케줄링과 리소스 활용을 가능하게 합니다.
지금까지 협력형 스레드 풀을 사용하는 액터가 상호 배제를 유지하면서도 효율적인 작업 우선순위 처리를 지원하는 방식에 대해 이야기했습니다. 그런데 또 다른 유형의 액터가 있습니다. 바로 메인 액터(MainActor)입니다. 메인 액터는 시스템 내의 기존 개념인 메인 스레드를 추상화한 것이기 때문에, 일반적인 액터와는 몇 가지 차이점이 있습니다. 뉴스 애플리케이션에서 액터를 사용하는 예제를 다시 생각해 보겠습니다. UI를 업데이트할 때는 반드시 메인 액터를 통해 호출해야 합니다. 그러나 메인 스레드는 협력형 스레드 풀에 속한 스레드들과는 별개이므로, 이와 같은 호출이 발생할 때는 컨텍스트 스위칭이 필요합니다.
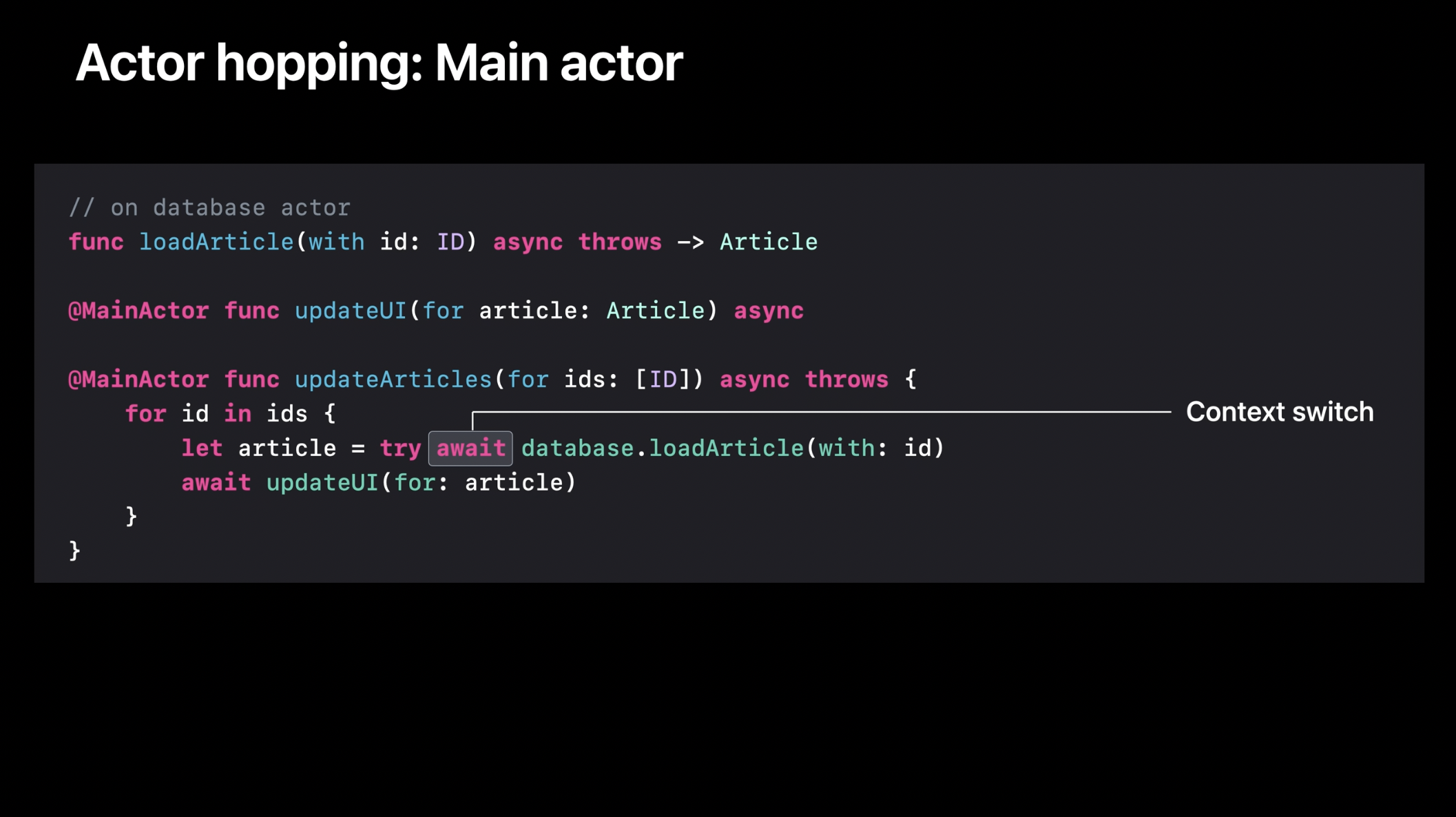

이와 관련된 성능 영향을 코드 예제를 통해 살펴보겠습니다. 다음 코드를 고려해 봅시다. 여기서는 메인 액터에서 실행되는 updateArticles 함수가 데이터베이스에서 기사를 불러오고, 각 기사의 UI를 업데이트합니다. 루프의 각 반복에서 최소 두 번의 컨텍스트 스위칭이 발생합니다. 하나는 메인 액터에서 데이터베이스 액터로 이동하는 것이고, 다른 하나는 다시 돌아오는 것입니다. 이러한 루프의 CPU 사용량을 살펴보겠습니다. 각 반복에서 두 번의 컨텍스트 스위칭이 필요하므로, 짧은 시간 동안 두 개의 스레드가 차례로 실행되는 패턴이 반복됩니다. 만약 루프 반복 횟수가 적고, 각 반복에서 수행하는 작업이 충분히 크다면 이는 문제가 되지 않을 수도 있습니다. 하지만 메인 액터에서 벗어났다 다시 돌아오는 작업이 자주 발생하면, 스레드 전환 비용이 누적될 수 있습니다.

애플리케이션이 컨텍스트 스위칭에 많은 시간을 소비하고 있다면, 코드를 재구성하여 메인 액터에서 처리할 작업을 묶어서 실행하는 것이 좋습니다. 이를 위해 for 루프를 loadArticles 및 updateUI 메서드 내부로 이동시켜, 개별 값이 아닌 배열을 한 번에 처리하도록 만들 수 있습니다. 작업을 묶어서 실행하면 컨텍스트 스위칭 횟수가 줄어듭니다. 협력적 스레드 풀 내에서 액터 간 이동은 빠르지만, 메인 액터와의 전환이 자주 발생하지 않도록 주의해야 합니다.
돌아보면, 이번 발표를 통해 시스템을 최대한 효율적으로 만들기 위해 우리가 어떤 작업을 해왔는지 살펴보았습니다. 협력적 스레드 풀의 설계에서부터 논-블로킹 중단 메커니즘 그리고 액터(actor)의 구현 방식까지 다양한 요소를 다루었습니다. 각 단계에서 우리는 런타임 계약의 일부를 활용하여 애플리케이션의 성능을 향상시키고자 했습니다. 이처럼 강력한 새로운 언어 기능을 활용하여 명확하고 효율적이며 매력적인 Swift 코드를 작성하는 모습을 기대하고 있습니다.
시청해 주셔서 감사하고, 멋진 WWDC 보내시기 바랍니다!
