A Deep Graph Neural Network Based Mechanism for Social Recommendations
0. Abstract
- 오늘 리뷰할 논문은 A Deep Graph Neural Network-Based Mechanism for Social Recommendations 이다.
- 본 논문에서 제안하는 GNN-SoR은 미래의 IoT 사용자들에게 보다 나은 정보를 제공하는 것을 목표로 한다.
1. Introduction
-
최근 IoT 기술의 발전으로, 사람들의 일상과 밀접하게 관련된 사이버 공간이 열려 다양한 사교 활동, 여가 활동, 업무 활동 등이 이루어지고 있다.
-
IoT 기술은 정보의 양을 폭발적으로 증가시키며, 사용자는 정보의 바다에 빠져들게 된다. 이에 따라 사용자에게 적절한 적합한 item을 추천해주는 추천 시스템이 중요해지고 있다.
-
본 논문에서는 IoT 사용자를 위한 SoR에 초점을 맞추어 연구를 진행하였다.
-
Social network는 그 관계의 정량화가 어렵기 때문에 쉽지 않은 task이다. 보통은 social relationship과 user의 선호도간의 관계를 파악하는게 일반적인 접근이다.
-
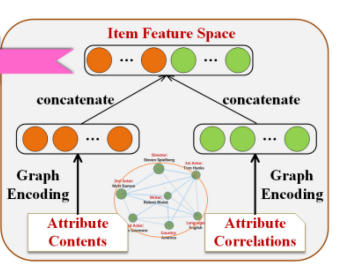
사용자는 사회적 관계가 더 높은 사람들에게 영향을 받을 가능성이 더 크기 때문이다. 하지만 item features간에도 상관관계가 존재한다.
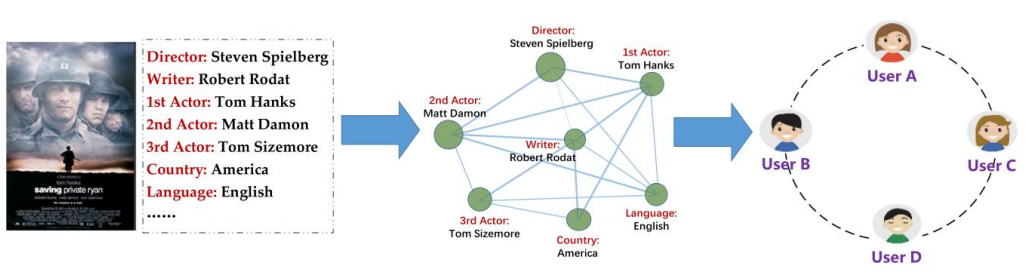
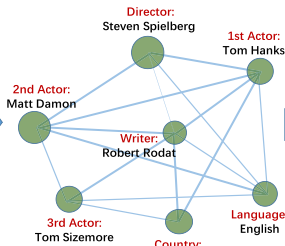
- 위 그림을 보면, 감독, 주연, 작가, 언어 등의 속성들은 모든 속성들 사이에 관계가 있음을 쉽게 알 수 있다. 그 예시로, 스티븐 스필버그가 톰 행크스와 협력한 적이 있다는 정보가 있을 때 많은 사회 집단에서 실제로 관심을 가지는 것은 두 사람 각자가 아니라 이 둘의 조합이다.
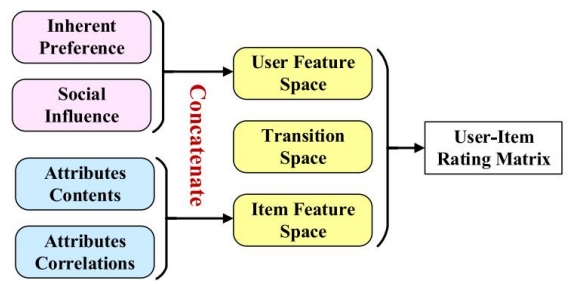
- 본 논문에서는 User feature를 ingerent preference와 social influence를 concat하여 구하고 item attributes를 사용한다는 점이 다른 논문들과의 구별되는 점이다.
- user feature space, item feature space을 두 개의 graph network로 만들어 encoding한다. 인코딩된 두 공간은 숨겨진 선호도 예측을 위한 MF 잠재 요소로 간주된다.
2.Problem Statement
1) user-item
- user i-> , item j-> 으로 표현할 수 있으며, user i와 item j의 rating은 로 표현한다.
- interaction이 없는 user와 item의 rating은 0으로 표현한다.
2) user-user
- user와 다른 user의 social relation을 표현한 부분이다. user-user matrix는 기본적으로 adjacency matrix형태를 가지며,으로 표현된다.
3) item-item
- item attribute와 item correlation을 표현한 부분이다. 는 attribute 간의 correlation 여부에 따라 0 or 1로 표현이 된다.
3.Methoholgy
A. User Feature Modeling
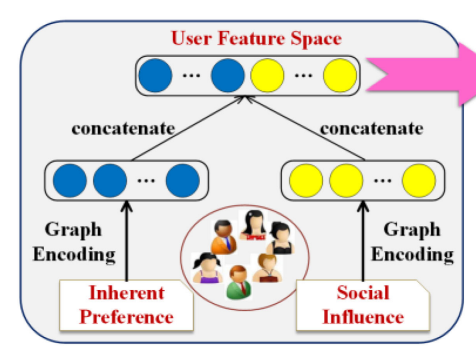
1)Inherence preference
-
Inherence preference는 user가 구매한 item에 대한 정보를 바탕으로 user의 preference feature를 의미한다. 이때, 에 대한 item rating은 으로 나타낼 수 있다. m은 user i가 구매한 item의 총 개수가 된다.
-
를 통해 inherent preference factor 를 구한다. 식은 다음과 같다. 는 ReLu를 사용한다.
-
를 이용해서 를 만들 수 있는데 이는 로 표현되며 총 개의 집합으로 이루어져있다.
-
에 포함된 funtion은 로 구성되며, 이를 통해 를 표현하면 다음과 같다..
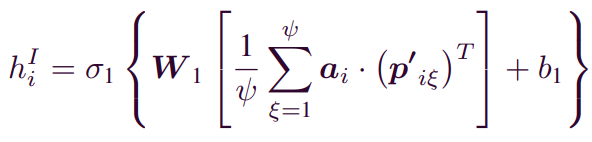
2) social influence
-
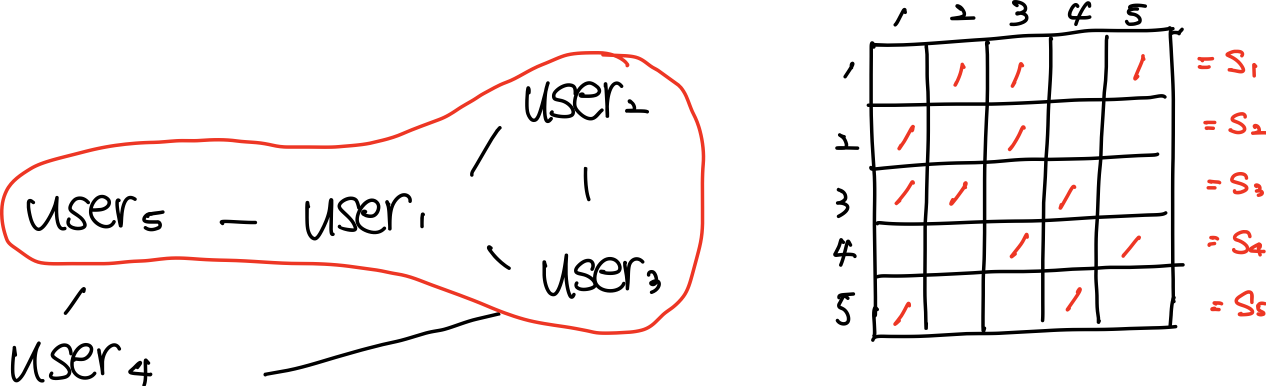
user i가 구성하고 있는 social network를 통해 social infulence를 알아본다.
-
의 social influence feature는 로 표현되며 다른 user과의 관계가 있음을 로 표시한다. 는 one-hot encoding으로 구성된다.
-
social influence factor는 이며, 로 표현된다.
-
에 포함된 는 로 표현된다. 는 feature transition vector이며, 이다. 이때, 는 user i의 latent vector이다.
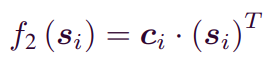
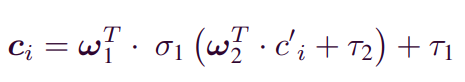
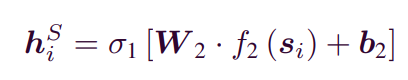
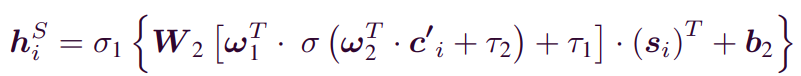
3) Concatenation
- first hidden layer 를 concatenation을 시켜 MLP model에 번 반복해서 user feature space를 생성합니다.
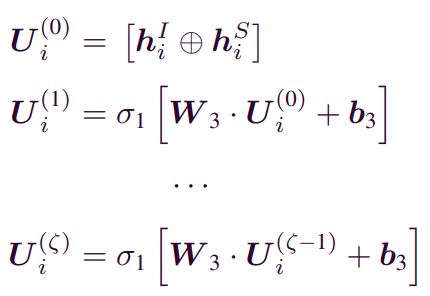
B. Item Feature Modeling
1) Attribute Contents
- 많은 item Attribute는 대부분 텍스트 형태로 되어있기 때문에 이를 vectorized 해주는 과정이 필요하다.
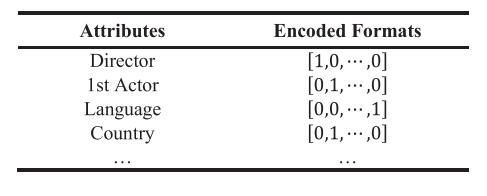
- item Attribute는 structured attribute와 unstructured attribute로 나눠진다. 아래와 같은 text로 이루어진 attribute는 fixed range of options을 가지기 때문에 structured attribute이다.
- structured attribute는 <Table 1>처럼 one-hot encoding으로 변환하여 사용한다.

- 본 논문은 text(영화 설명)에서 위와 같은 Attributes(Topic: Director,1st Actor..)를 추출하기 위해서 Twitter-LDA algoritm을 사용한다.
- 하지만 각 Attribute를 one-hot encoding을 진행하면 서로 다른 attribute 간의 dimension이 다른 문제점이 발생한다.
- zero padding을 통해서 서로 다른 attribute의 dimension을 맞춰준다.
- item j의 content(attribute) factor 는 다음과 같이 나타낼 수 있다. 는 item j의 1번째 attribute의 one-hot encoding이다.
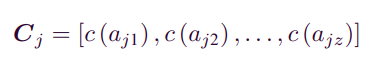
2) Attribute correlations
- item j에 포함된 Attribute 와 item j에 포함된 다른 Attribute의 관계를 파악하고자 한다. item j의 Attribute의 correlation은 다음과 같이 표현된다.
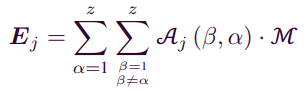
-
은 transformation function, 는 Attribute 의 관계(weight)를 표현한다.
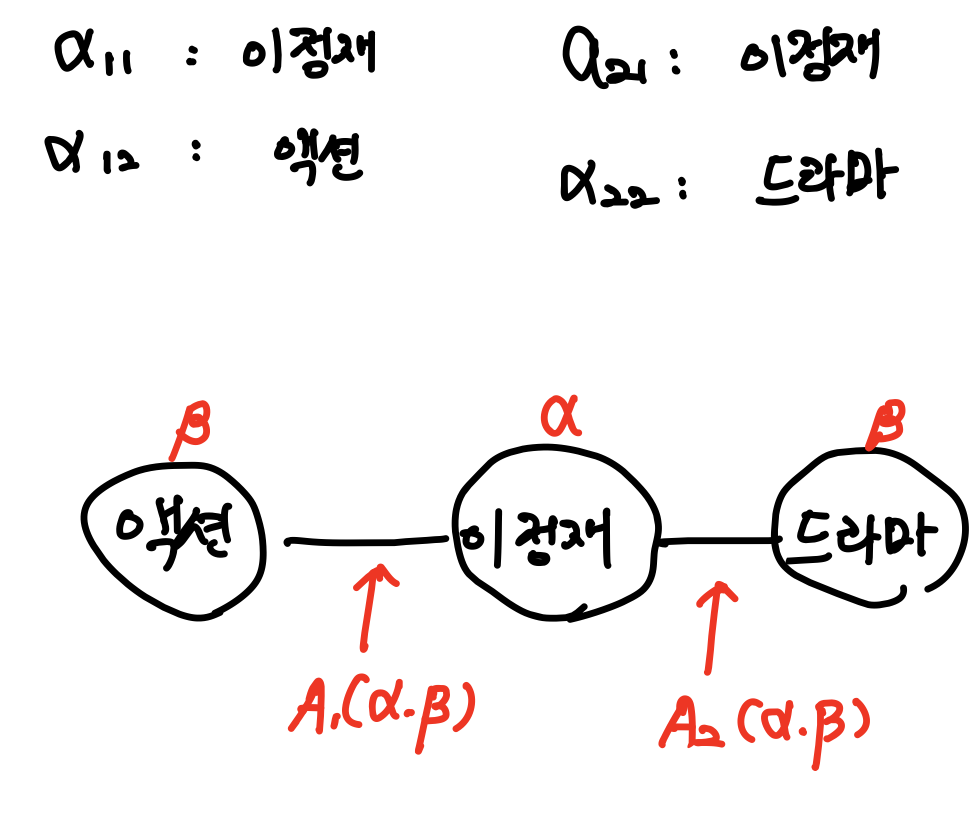
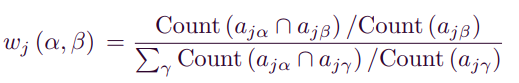
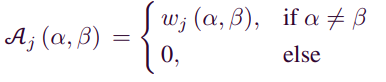
-
Count function이 나타내는 의미는 전체 item attribute network에서 와 를 함께 포함하는 item j의 수를 의미하며, Count()는 를 포함하는 item의 수를 의미한다.
-
은 transformation function으로 나타나는데 Attribute 간의 in/out의 정도를 표현하는데 사용이 된다. 즉 사이의 정보 전달을 의미하는 matrix이며 아래와 같이 표현된다.
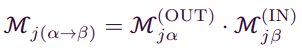
- 최종적으로 Atrribute correlation 수식을 확인하면 item j에 대한 correlation factor는
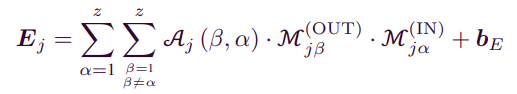
3) Concatenation
- 모든 item atrribute에 대해 계산하는 것은 많은 computational complexity를 가지고 있음으로 attribute correlation을 aggregate를 통해서 사용한다.
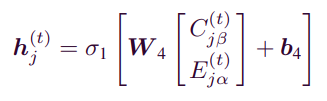
- 우선 앞에서 구한 의 attribute correlation과 를 제외한 item Attribute의 를 통해서 를 생성한다.
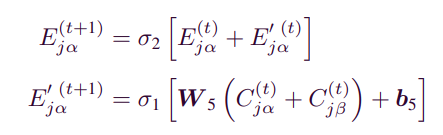
- 다음 step의 attribute correlation와 item Attribute를 다음과 같이 나타난다.
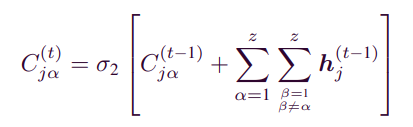
- 2개의 sigma를 통해서 하나의 attribute에 대한 내용을 더하고 추가로 다른 attribute에 대한 내용을 모두 구하여 item j의 attribute correlation와 item Attribute를 알 수 있다.
c. Rating Prediction
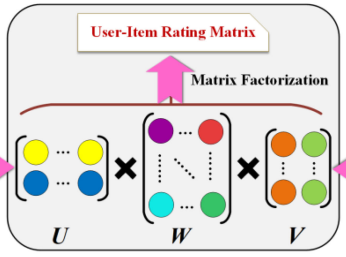
-
user latent space와 item laten space를 transition matrix 를 통해 rating matirx prediction한다.
-
해당 문제의 loss function은 rating의 차이를 최소화 시켜주는 method를 사용한다. 이때, 앞에서 등장한 feature들에 weight decay를 주어 regularization을 한다.
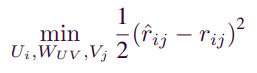
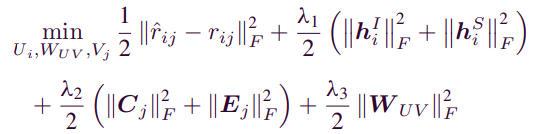
4. Experiments and analysis
4.1 Data sets
본 연구에 활용된 데이터셋은 SoR 분야에서 흔히 볼 수 있는 아래 세 가지 데이터이다.
- Epinions
- Yelp
- Flixster
Epinions
2003년, Paolo Messa et al.에서 인터넷 크롤링을 통해 유명한 온라인 쇼핑 웹사이트인 epinions에서 수집한 데이터이다. 이 웹사이트에서 사용자는 각 item에 1에서 5사이의 정수로 선호도 등급을 메기고, 다른 사람들과의 관계를 trust하게 설정했다.
본 논문에서는 4미만의 value를 걸러내고, 5개 미만의 평점을 게시한 사용자와 5개 이하의 item을 제거했다. 또한 original 데이터에는 contents에 대한 정보와 상관관계를 포함하고 있지 않았기 때문에 유명한 쇼핑 웹사이트인 아마존에서 epinions의 상품 정보에 따라 product attribute metadata를 크롤링했다.그 후 attribute pairs의 동시 발생 기록을 search하여 크롤링된 attribute의 상관 정보를 정량화한다. 상관 관계는 0 또는 1의 binary한 값으로 표현된다. 1일 때 상관 관계가 있음을, 0일 때 상관관계가 없음을 나타낸다.
Yelp
미국 샌프란시스코의 유명한 비즈니스 리뷰 웹사이트인 Yelp는 2004년에 설립되었는데, 이 웹사이트에서 사용자는 판매자 평가, 의견 제출, 쇼핑 경험 공유 등을 할 수 있다. 데이터에는 사용자 및 판매자에 대한 정보, 판매자에 대한 사용자의 선호도, 판매자에 대한 사용자 리뷰 등이 포함된다. 이 중 데이터셋의 판매자가 item으로 간주된다. 총 데이터의 양이 방대하기 때문에 평가 기록이 3개 미만인 사용자를 걸러낸다.
Flixster
Flixster는 사용자가 선호도를 공유하고, 다른 사람과 만날 수 있는 영화 관련 온라인 웹사이트이다. 이 데이터셋은 item과 user간의 풍부한 선호도와 상관관계를 담고 있다. item의 attrivute는 IMDb5라는 유명한 온라인 영화 데이터베이스에서 메타베이터를 크롤링하고 상관관계를 추출한다. Flixster의 등급은 0.5에서 5.0까지이며, 정수가 아닌 값은 정수로 추가 변환하는 과정을 거친다.
아래 표는 전처리된 데이터셋의 통계이다.
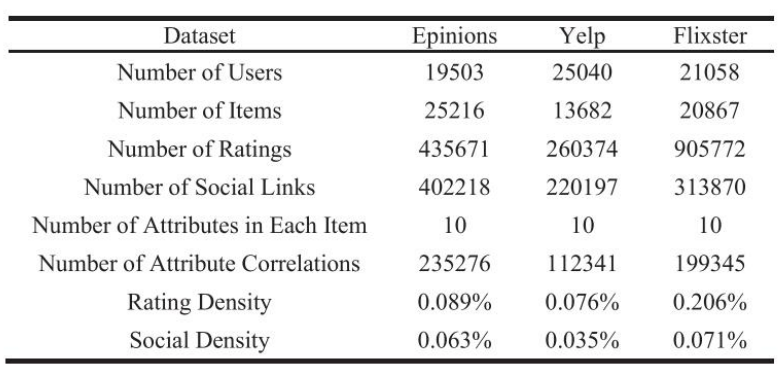
4.2 Experimental settings
-
본 논문에서는 평가 지표로 RMSE, MAE, NDCG를 사용한다. NDCG는 순위에 따른 중요도를 고려하여 평가하는 지표로 값이 높을 수록 더 나은 성능을 나타낸다.
-
GNN-SoR 모델과 비교하는 baseline으로는 TrustMF, SocialMF, TrustSVD, AutoRec의 4가지가 있다.
-
GNN-SoR은 tensorflow로 구현했다. (3)과 (11)의 반복 ψ, ζ는 각각 50이고, 배치사이즈는 2000이다. tradepff parameter τ1, τ2는 각각 0.5이며 SGD의 learning rate는 0.01이다. 그리고 penalty parameter인 λ1, λ2, λ3는 각각 0.35, 0.35, 0.3으로 설정했다.
4.3 Results and analysis
-
데이터의 training set 비율은 60%, 80% 두 값으로 설정한다.
-
Epinions
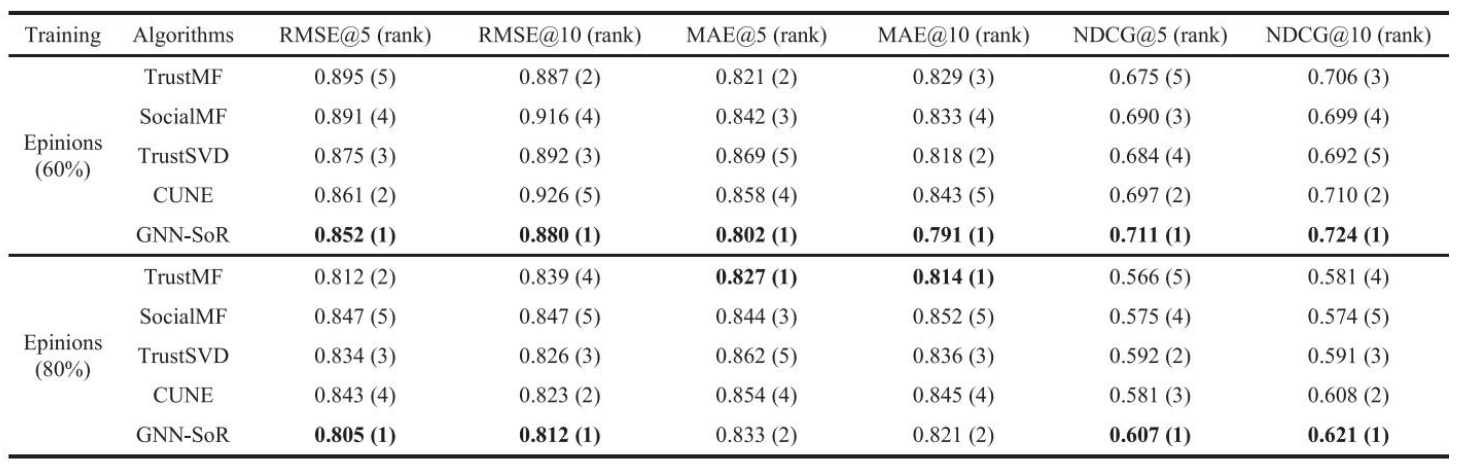
-
Yelp
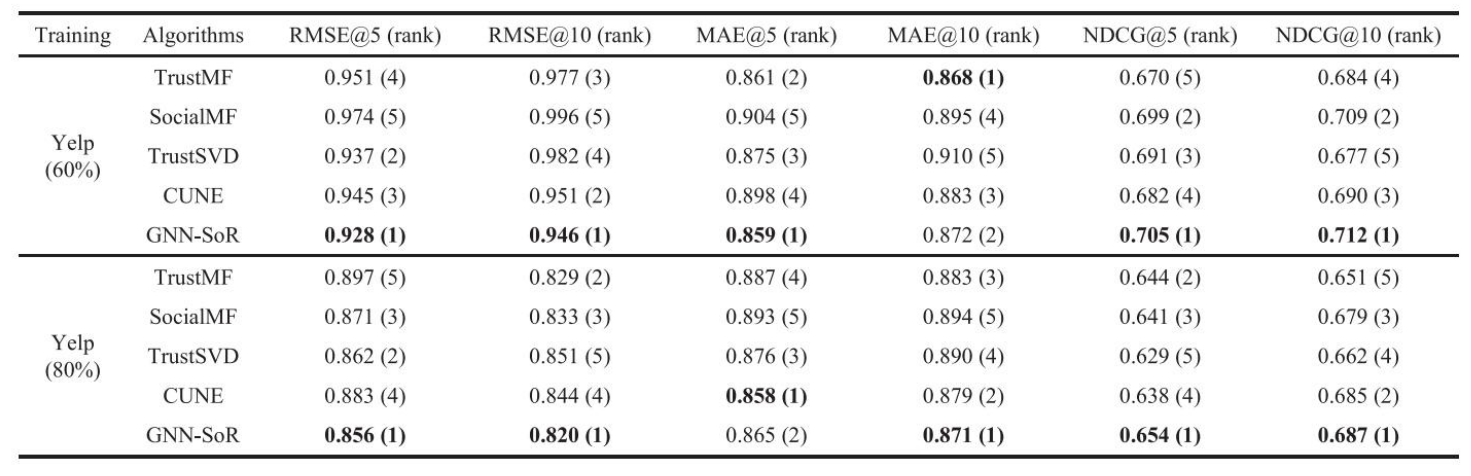
-
Flixster
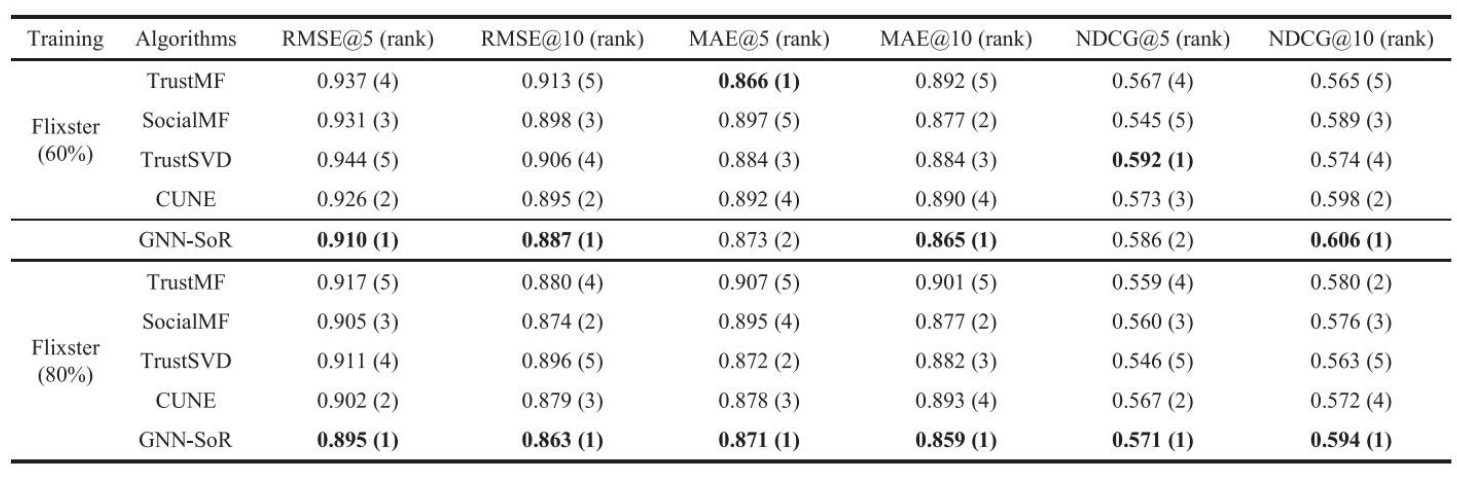
-
전반적으로 GNN-SoR이 좋은 성능을 보였다. 본 논문에서는 이에 대해 2가지 이유를 제시한다.
- 본 논문에서는 GNN을 사용하였기 때문에 다양하고 복잡한 관계를 더 잘 표현한다.
- item의 attribute 상관관계를 인코딩한 벡터를 사용함으로써 성능을 높였다.
-
그런 다음 배치사이즈를 1000, 2000, 2500, 3000, 3500, 4000으로 설정하고 권장 사이즈를 3, 5, 7, 8, 10으로 설정한다.
-
Epinions
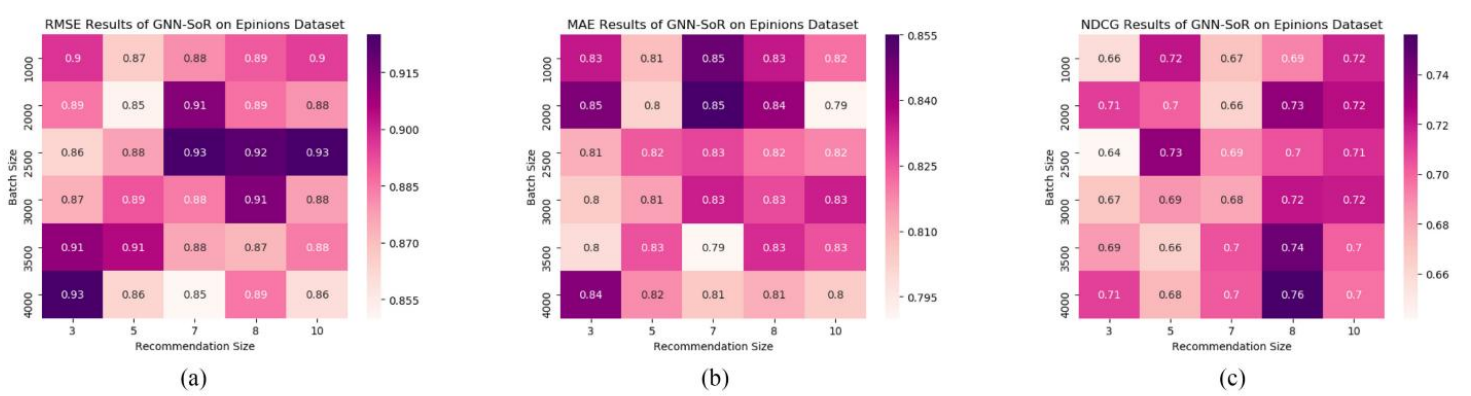
-
Yelp
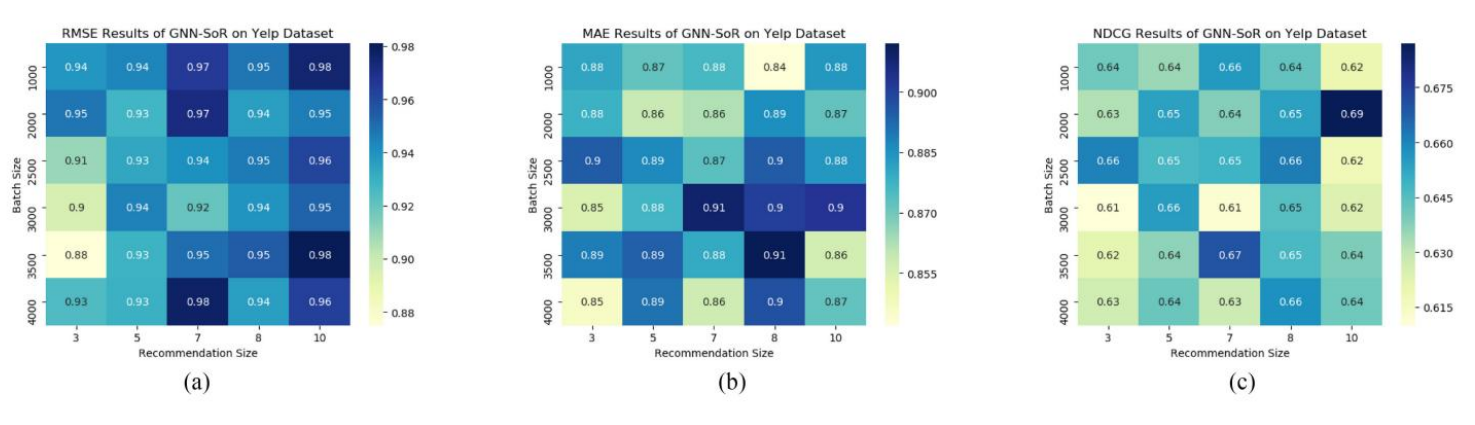
-
Flixster
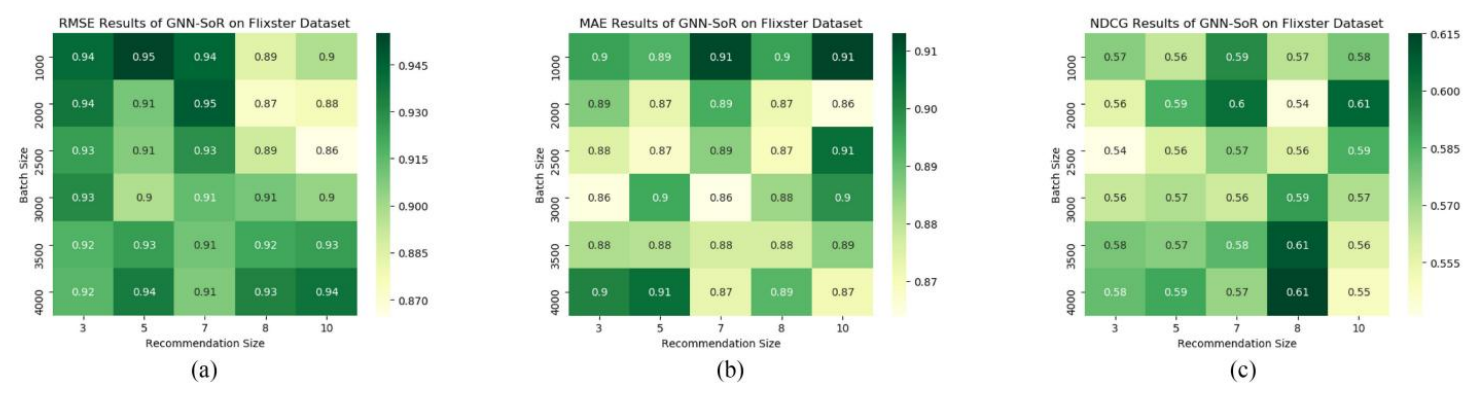
-
위 그림에서 각 그림 내부의 사각형 색 차이가 상대적으로 적기 때문에 GNN-SoR모델이 안정성 부분에서 우수함을 확인할 수 있다. 다양한 파라미터 설정에 대해 안정적으로 반응한다.
5. Conclusion
- 다가오는 5G 시대에 IoT가 중요한 부분으로 자리를 잡고 있다. 본 연구는 미래의 IoT 사용자를 위한 SoR 의 적용에 관한 내용이다.
- SoR에서 item의 attribute 상관관계를 활용함으로써 새로운 프레임워크인 GNN-SoR을 제안했다.
- 먼저 User feature space와 item feature space를 graph로 나타내고 각각을 graph networks를 통해 인코딩한다.
- 다음으로 인코딩된 두 공간이 숨겨진 선호도 예측을 위한 잠재 요소로 간주되어 missing rating values를 완성한다.
