Group Recommendations with Rank Aggregation and Collaborative Filtering
Linas Baltrunas, Tadas Makcinskas RecSys '10
0. Abstarct
- 대부분의 추천시스템은 개인에 맞게 연구되어 왔지만, 그룹에 의해 선택되는 상황도 존재한다. 예를 들면, DVD와 같이 여러 개인이 모여서 하나의 선택을 하는 경우다.
- 본 논문은 개인의 collaborative filtering 정보를 활용하여 그룹 추천의 effectiveness를 파악하고자 한다.
- 개인과 그룹 추천의 effectiveness 를 파악하기 위해서 normalized discounted cumulative gain을 사용한다.
1. Introduction
-
추천시스템은 개인의 다양한 의사 결정에 도움을 주며, Web-based e-commerce application에서 사용이 된다.
-
추천시스템은 주로 개인에게 집중이 되지만, 특정 상황(ex. DVD) 같은 경우에는 그룹에도 집중을 해야한다.
-
이러한 이유로 최근 연구들에서는 그룹의 개인들에게 'good for'을 추천하려고 한다.
-
그룹간의 추천을 살펴볼 수 있는 tourism, web/news page, music과 같은 도메인에서 주로 연구가 되었다.
-
개인과 그룹의 effectiveness를 비교하기 위해서 2가지 접근법이 사용이 된다.
- 개인의 평가를 진행 한 후에 이를 그룹에 맞게 통합하는 방법
- joint 평가를 통해 그룹의 추천 평가를 얻는 방법
-
해당 접근법들에는 '수집 방법에 따른 차이', '다른 개인에 의한 영향'이라는 문제점이 존재한다.
-
하지만 2번 접근법에는 그룹 평가를 재진행 해야한다는 큰 문제점이 있음으로 본 논문은 1번 접근법에 따라 진행된다. 순서는 다음과 같다.
- test data에 대해서 개인의 collaborative filtering rating prediction을 진행한다
- rating prediction을 기준으로 개인의 ranking prediction을 생성한다.
- size/member similarity/rank aggregation 3가지 기준으로 그룹 ranking prediction을 생성한다.
-
실제 상황에서 일어나는 경우를 test함으로 추천시스템의 성능이 좋지 않아 그룹추천의 성능이 안좋게 나올 수 있으며, 그룹 멤버들간의 유사도가 높으면 그룹추천의 성능이 좋을 수 도 있다.
-
본 논문은 rating을 잘 예측하는 것보다 ranking을 예측하는데 더 초점을 둔다(이는 최근에 많이 진행되는 추천 성능 평가 방법이다).
2. Related Work
3. Rank Aggregation for group recommendations
3.1 user rating ranking transpose to group ranking
- 개인의 Collaborative filtering을 통해 predition된 test rating들을 사용하여 그룹의 test rating의 ranking을 정해야한다.
- 순위 집계 방법을 사용하여 그룹의 순위을 작성하면 여러 개인의 개별 순위 선호도가 주어졌을 때 대안 간의 "합의된" 순위를 찾는 문제가 해결된다.
Approach 1. 각 item의 user rating을 사용하여 joint group rating을 예측한다. 이는 group 전체의 item ranking을 알 수 있다.
Approach 2. user의 rating ranking을 통해서 group item ranking을 예측한다.
3.2 Method of aggregate
- 적절한 순위 aggregate 방법은 일반적으로 최적화하는 ranking distance 및 item list의 속성에 따라 달라진다.
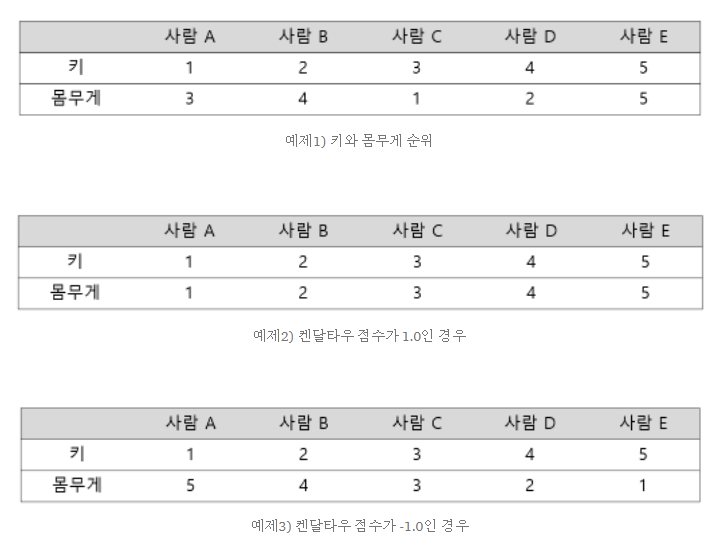
- 순위 집계 방법 중 평균 Kendall tau distance를 최소화하는 Kemeny optimal aggregate을 사용한다. kendall tau distance는 두 리스트(user-user, group-group) pair의 불일치 수를 카운트 한다.
- 두 리스트를 비교를 할때 feature들의 ranking의 상하관계로 영향을 받는다.
- model에 사용되는 permutation은 다음과 같다.
- g = {σ1,...,σ|g|}; group의 멤버를 의미
- σu => I = {1,...,n}; 멤버 u에 대한 item rating ranking
- σu(j) => 멤버 u에 item j의 ranking
- model에서 사용되는 user rating aggregate 방법은 크게 4가지가 존재한다.
- 1. Spearman footrule
두개의 list (item ranking)의 거리의 합으로 rank absolute position의 차이를 의미한다. 즉, 같은 위치에 있는 item의 ranking간의 차이를 의미한다. 식은 다음과 같이 나타난다.이를 통해서 group user들의 item rating ranking을 가장 잘 반영해주는 group item rating ranking을 만들게 된다.
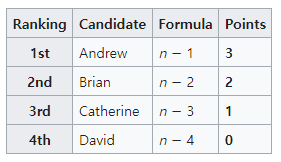
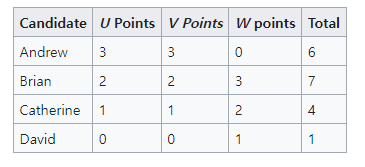
2. Borda count
특정 user의 item에 대한 score는 다음과 같이 표현 할 수 있다.
해당 item에 대한 ranking이 낮게 된다면 score_u(i)에 대한 점수도 낮게 나온다.
이를 user가 아닌 group에 대해 item rating ranking을 파악하기 위해 다음과 같이 나타낼 수 있다.
3. Average
group의 rating ranking을 표현하기 위해서 user의 rating의 평균을 통해서 해당 group의 item rating ranking을 재정의하는 방법이다.
4.Least Misery
group에 속해있는 user들의 rating 중에서 가장 최소의 rating을 group의 대표 rating으로 고려하여 item rating ranking을 만든다.
5. Random
마지막으로 user들의 rating 중 random으로 추출하여 group의 item rating ranking을 만드는 경우가 있다.
4. Experimental setup
- 실험평가 과정에서 user가 속한 group의 item rating ranking과 user의 item rating ranking을 비교를 통해서 group recommendation의 효과를 비교한다. 해당 효과는 Normalized discounted cumulative gain(nDCG) measure로 계산이 된다.
- 실험 과정을 위해서 임의적으로 group을 형성한다. 이후 train set(60%)와 test set(40%)를 각각 나눈다.
4.1 dataset an group generation
- 본 연구에서 사용된 dataset은 movie lens dataset을 사용하고 100k rating과 1682movies, 983의 user를 가지고 있다.
- group의 수는 user를 2,3,4,8으로 나누는데 random하게 grouping하는 방법과 high inner group similarity grouping 2가지 approach가 존재하며 최소 5개 이상의 item에rating한 user를 대상으로 한다.
- high inner group similarity에 대한 기준은 similarity가 0.27이상인 user-to-user간의 group으로 이루어진다. 이는 pearson correlation coefficient(PCC)를 통해서 계산된다.
- 그림을 보면 약 33%의 user들만 0.27이상인것을 확인 할 수 있다.
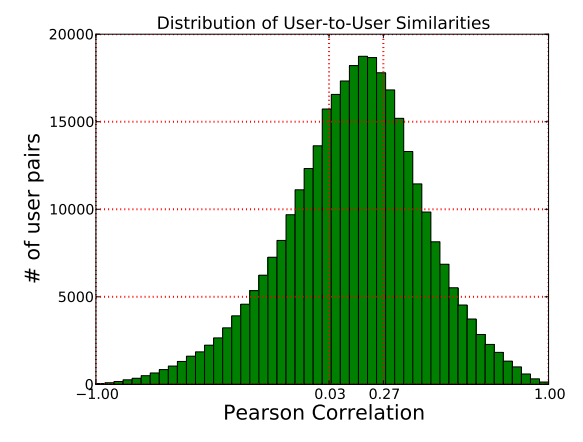
- 다른 방법으로는 user들을 random하게 grouping하는 방법이 있는데, 이 group들 간의 average inner similarity는 0.132로 낮은 반면, high inner로 grouping 한 경우에 0.456으로 점수가 나타나게 된다.
4.2 recommendataion lists for a group
- 기존의 user recommedation 연구들에서는 gradient descent method, singular value decomposition(SVD) latent factor 방법을 통해서 user rating을 예측했다.
- 본 연구에서도 SVD를 사용하여 training set에 존재하지 않는 data까지 학습을 진행하고자 한다.
4.3 Effective of a rankes list of recommendations
-
각 effective of aggreagte를 평가하기 위해 normalized discounted cumilative gain을 통해 IR measure를 구한다.
-
u: user, : user의 item 에 대한 rating, k: ranking
-
IDCG: the maximum possible gain value for user u
-
nDCG를 통해서 우리는 실제 user가 item rating을 알아야 하기 때문에 모든 item rating에 대한 DCG를 계산한다.
-
계산 방법은 prediction한 rating을 기준으로 item을 배열을 한다.
-
이때, 해당 item들의 true rating을 으로 판단한다.
-
따라서 ranking의 순서가 rating을 기준으로 되어있지 않다면(잘못 predition), 아래의 ranking의 rating에 대해 낮은 가중치가 부여된다.
-
이를 DCG가 가장 높은 경우의 IDCG보다 낮아지게 때문에 nDCG값이 줄어든다
5. Experimental results
5.1 Effectiveness of group recommendation
- group recommendation의 effectiveness를 판단하기 위해서 다양한 aggregate method와 group size에 대한 실험이 필요하다.
- 실험은 random group과 high similarity group으로 구분되어 진행이 되며, 본 연구의 가정은 group size가 커질수록 effectiveness는 감소한다.
- 실제로 많은 사람들이 해당 group에 존재하면 여러 사람의 의견을 통합해서 결정해야하기 때문에 어려운 점이라고 생각한다. 즉, 모두 만족시키는 선택을 하기는 어렵다.
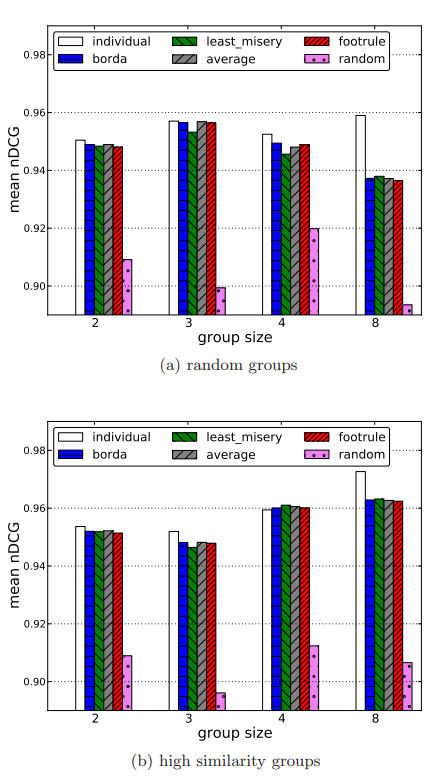
- (a)의 경우 random 하게 group을 정한 후 indivisual, least_misery, footrule, borda, average, random 6가지 aggregate 방법을 통해 1000개의 sample을 추출해서 mean nDCG를 구한다. (b)의 경우 high sumilarity group을 기준으로 진행한다.
group size
- group size가 2,3,4인 경우 random을 제외한 4가지 aggreagte method는 individual과 큰 차이를 보이지 않는다.
- high similarity group의 경우 individual과의 차이는 증가하지만 전반적으로 4가지 aggreagte method들이 증가함을 알 수 있다.
- 애초에 group size가 증가하면 nDCG가 감소할 것으로 가정하였지만 random group의 경우 size 3에서 증가함을 보인다.
- individual의 경우 가장 큰 nDCG를 가진다. 하지만 group size가 2,3,4의 경우에는 차이가 크지 않으나 group size가 클 수록 그 차이가 커진다.
- 이것의 의미는 group의 사람들이 많이질수록 그 의견을 좁히는게 쉽지 않음을 보여준다.
- 하지만, individual과의 차이는 증가하지만 다른 group size보다 8인 경우에 제일 높은 nDCG를 보여주고 있어 individual prediction이 좋지 않을 때, 사용이 가능한 장점이 있다.
worse random aggregation
- random aggregation의 경우 전반적으로 0.9이상의 score를 보여주고 있지만, 실제로 nDCG의 3~6%차이는 매우 큼을 의미한다.
- 완벽하게 ranking을 예측했을 때, nDCG가 1.0이 나오지만 모델의 오류로 인해서 잘못 예측을 했을 때에도 0.97이라는 score가 나온다. 이를 통해 잘못된 모델이 3%차이가 발생함으로 3~6%차이는 매우 큰 variance가 됨을 알 수 있다.
- random을 제외한 aggregation의 영향을 작음을 알 수 있다.
- group size와 group similarity를 확인한 결과 확연하게 뛰어난 부분을 찾지 못했다.
- 본 연구는 4 group size에 초점을 맞추고 진행한다.
5.2 Relationship between group and indivisual recommedation
- 해당 실험의 경우 group recommedation이 언제 좋고 나쁜지에 대해 측정을 하게 된다.
- 이때, 사용되는 측정 기준은 gain으로 group recommedation과 user individual recommendation의 차이로 나타난다.
- positive gain은 group recommedation이 individual보다 성능이 높게 나온 경우를 의미한다.
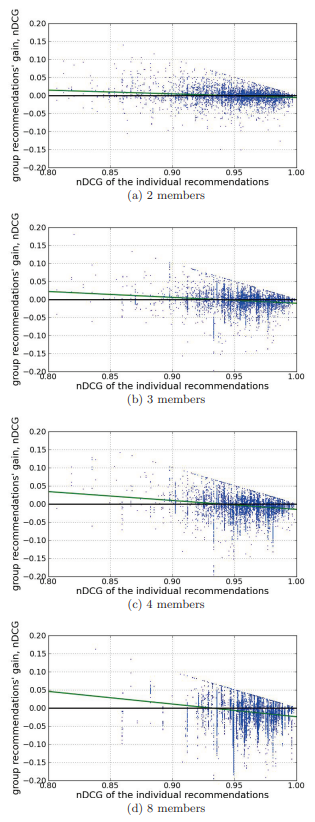
- 해당 그림의 x축은 individual recommendation의 nDCG를 나타내며 y축은 gain을 나타낸다.
- 이때 한 user는 서로 다른 group의 포함 될 수 있기 때문에 여러개의 point로 나타나게 된다. 또한, 총 3000개의 point를 sample로 추출해서 사용한다.
- individual recommendation이 증가할수록 gain의 차이는 줄어드는 모습을 볼 수 있다.
- 이것의 의미는 낮은 individual recommendation의 경우 group recommendation을 사용하는게 더욱 좋다는 것을 의미한다.
- 각 점의 correlation은 size 2:-0.17, size 3:-0.19, size 4: -0.19, size 8: -0.18로 나타나며 individual이 커질수록 gain이 낮아짐을 의미한다.
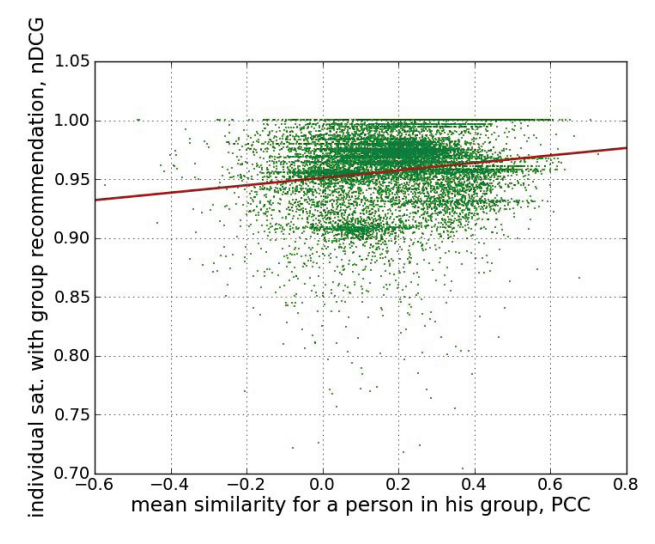
- 해당 그림은 각 그룹의 개인 간 유사도를 x축으로 하는 그래프이다. 이를 보면 group내의 개인간의 유사도가 높아질 수록 전반적인 group recommandation 성능이 높아짐을 알 수 있다.
6. Discussion and conclusions
- 전반적으로 낮은 group size의 recommedation는 individual에 비해 성능이 차이가 적은데 반해, group size가 커지면 성능의 차이가 커짐을 알 수 있다.
- group size가 커짐에 따라서 무조건 성능이 좋아지거나 낮아짐은 아닌것을 group 2->3 , 3->4를 보면 확인이 가능하다.
- individual의 성능이 안좋은 경우 group recommendation으로 대체가 가능함을 보여준다.
