Wide & Deep Learning for Recommender Systems
1. ABSTRACT & INTRODUCTION
- 본 논문에서는 추천시스템에 대한 memorization과 generalization의 장점을 결합한 Wide & Deep learning을 소개한다.
- Wide & Deep learning은 wide linear 모델과 deep neural networks를 함께 학습한 것이다.
- 구글 플레이에서 해당 모델을 평가했고, 실험 결과 Wide & Deep은 wide-only 또는 deep-only에 비해 앱 가입 수가 크게 증가하였다.
Memorization / Linear model
Linear model
-
선형 모델의 장점은 변수간 상호 작용을 기억(memorization)하는데 효과적이고 해석 가능하다는 것이다.
-
선형 모델의 단점은 일반화(generalization)에 많은 피처 엔지니어링이 필요하다는 것이다. 또한, 선형 모델의 경우 학습 데이터에 없는 것은 일반화할 수 없다.
Memorization
-
Memorization는 아이템이나 피처 간의 동시 발생을 학습하고, 과거 데이터를 사용하여 얻은 상관관계를 활용할 수 있다.
-
Memorization에 기반한 추천은 사용자가 이미 행동한 것과 보다 더 직접적으로 관련되어 있다.
Generalization / Deep neural networks
Deep neural networks
-
Deep neural networks는 적은 피처 엔지니어링을 사용하며, sparse한 입력 변수들을 저차원의 임베딩을 통해 변수 간의 새로운 feature 조합으로 더 잘 일반화(generalization)시킬 수 있다.
-
그러나 user-item interaction이 sparse하거나 high-rank일 때는 관련성이 낮은 항목을 과도하게 일반화하고 추천한다는 단점이 있다. 이런 경우 선형 모델이 더 낫다.
Generalization
-
Generalization는 드물게 발생했던 새로운 피처 조합을 찾아내고, 추천의 다양성을 향상시킨다.
-
FM이나 DNN과 같은 임베딩 기반 모델은 이전에 보지 못했던 item 또는 feature를 일반화(generalization)할 수 있다.
-
이 모델들은 각 feature를 저차원의 벡터로 임베딩하여 학습하며, 피처엔지니어링 부담이 적다.
참고로 Cross-product feature란 과거의 데이터를 사용하여 새로운 조합 feature를 만들어서 과거에 학습하지 않았던 feature를 생성하는 것.
2. RECOMMENDER SYSTEM OVERVIEW
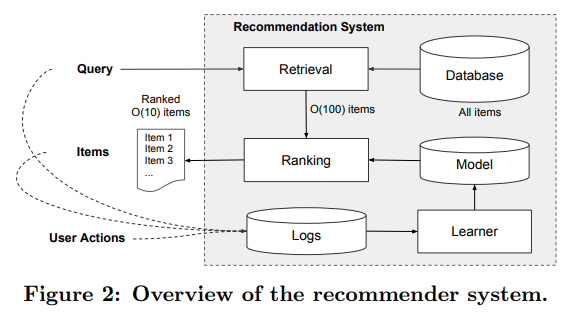
-
위의 그림은 앱 추천 시스템의 개요를 나타낸다.
추천시스템은 사용자가 클릭 또는 구매와 같은 특정 행동을 수행할 수 있는 여러 앱 리스트를 리턴한다. 유저가 검색을 하면 이에 따라 리턴된 앱 리스트들(검색 결과)와 유저의 행동 기록들이 모델 학습을 위한 로그 데이터로 쌓인다. -
첫 번째 스탭은 Retrieval로, user의 query에 가장 잘 일치하는 아이템의 짧은 목록을 반환한다. 후보 풀을 줄인 다음, 랭킹 모델은 모든 아이템에 점수를 매긴다. 점수는 P(y|x)로 계산되며, user의 정보 feature들인 x가 주어졌을 때 user가 y 앱에 action을 할 확률이다. x는 유저의 국적, 언어와 같은 user features, 디바이스, 시간, 요일과 같은 contextual features, 앱 age, 앱 통계와 같은 impression features를 포함한다.
-
이 논문에서는 Wide and deep learning을 사용한 ranking 모델을 제안하며, 이는 후보 앱들의 점수를 메기는데 사용된다.
3. WIDE & DEEP LEARNING
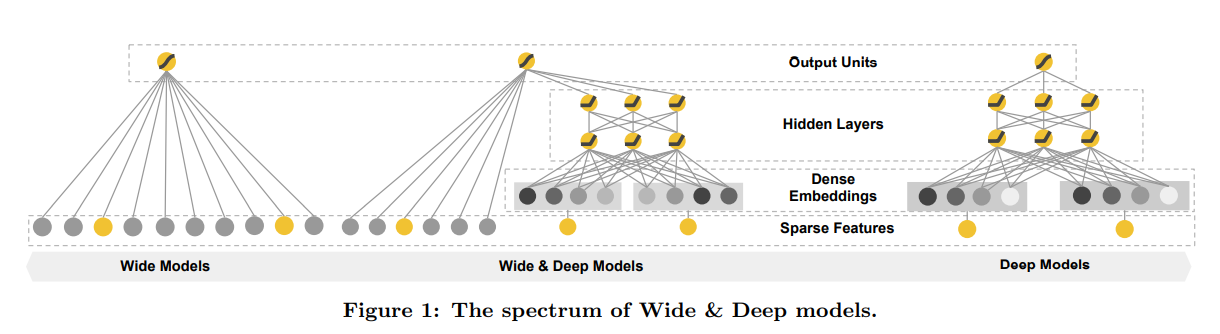
3.1 The Wide Component

- Wide component는 아래와 같은 일반적인 linear model이다.
-
는 예측값, 는 개의 변수 벡터, 는 모델의 파라미터, 는 bias를 의미한다.
-
Features는 raw input features와 변환시킨 features를 포함한다. 중요한 변수 변환 방법 중 하나는 cross-product transformation이며 다음과 같다. 이는 이진 변수간의 상호작용을 표현하고, 일반화된 선형 모델에 비선형성을 추가해준다.
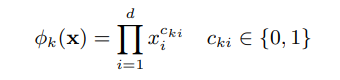
- 는 boolean 변수이며, -th feature가 -th transformation 의 일부분이면 1의 값을, 그렇지 않으면 0의 값을 갖는다.
3.2 The Deep Component
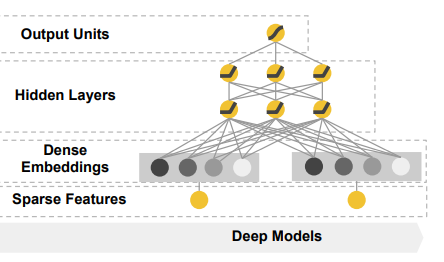
-
Deep component는 feed-forward neural network이며, Sparse하고 고차원인 categorical feature는 저차원의 임베딩 벡터로 변환한다.
-
Hidden layer에서는 다음과 같은 신경망 연산이 이루어진다.
-
은 layer number, 는 activation function (ReLUs), 는 activation, 는 bias, 는 model weights를 의미한다.
3.3 Joint Training of Wide & Deep Model

- Wide component와 deep component는 joint training을 위해 하나의 로지스틱 손실함수에 예측으로 output log odds의 가중치 합을 사용하여 결합된다.
Emsemble
- 앙상블의 경우, 모델이 독립적으로 학습되고 각각의 예측치가 training time이 아닌 inference time 때 결합된다.
- 모델의 학습을 독립적으로 하기 때문에 정확도를 어느정도 보장하기 위해선 각 모델의 사이즈가 클 수 밖에 없다. (feature도 많고 transformation도 많음)
Joint training
- 반대로, joint training은 학습 시 합계의 가중치 뿐만 아니라 wide와 deep의 모든 파라미터를 동시에 최적화한다.
- Wide가 deep의 약점만 보완하면 되기 때문에 많은 feature가 필요하지 않다.
-
Wide & Deep 모델의 joint training은 mini-batch stochastic optimization을 사용하여 wide와 deep 부분의 gradient를 동시에 backpropagation하며 수행한다.
-
본 논문에서는 FTRL(Follow-the-regularized-leader) 알고리즘을 사용하였고, wide part와 deep part는 각각 L1 정규화와 AdaGrad를 optimizer로 사용했다.
-
로지스틱 회귀의 Wide & Deep 모델은 다음과 같다.
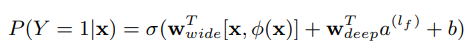
-
는 binary class label, 는 sigmoid 함수, 는 x의 cross product transformations, 는 bias이다. 는 wide 모델의 weights, 는 final activation 에 적용되는 weights이다.
4. SYSTEM IMPLEMENTATION
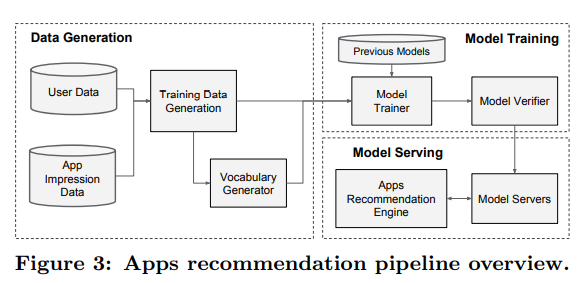
- 앱 추천 파이프라인의 구현은 위 그림처럼 데이터 생성, 모델 학습, 모델 서빙 총 3단계로 구성된다.
4.1 Data Generation
-
해당 단계에서는 특정 시간 동안 user와 app의 impression 데이터를 통해 학습 데이터를 생성한다. 라벨은 app acquisition이며, 앱을 설치했을 경우 1, 아닐 경우 0이다.
-
범주형 변수 문자열을 정수 ID로 매핑하는 테이블인 Vocabularies도 해당 단계에서 생성된다.
4.2 Model Training
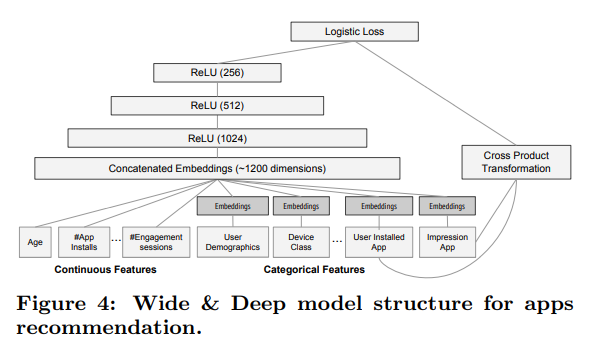
-
학습 과정에서 input layer는 학습 데이터와 vocabularies를 사용하여 label과 함께 sparse하고 dense한 feature를 생성한다.
-
Wide component는 설치된 앱과 impression 앱의 cross-product transformation로 구성된다.
-
Deep component는 각 범주형 변수에 대해 32차원의 임베딩 벡터가 학습된다.
-
모든 임베딩 벡터를 dense feature와 결합하여 약 1200차원의 dense vector를 생성한다. 결합된 벡터는 3개의 ReLU 레이어에 연결되고, 마지막으로 로지스틱 output unit으로 연결된다.
-
Wide & Deep 모델은 5000억개 이상의 데이터로 훈련되었다. 새로운 데이터가 생기면 모델은 재학습되어야 한다. 하지만 처음부터 재학습하는 것은 계산 비용이 많이 들고 시간이 오래 걸린다. 이를 해결하기 위해 warm-starting system을 사용하는데, 새로운 모델을 이전 모델의 임베딩과 선형 모델의 가중치로 초기화한다.
4.3 Model Serving
-
모델이 학습되고 검증이 되면 모델을 모델 서버에 로드한다.
-
각 요청에 대해 서버는 앱 검색 및 사용자 변수로부터 앱 후보셋을 받아 각 앱에 점수를 매긴다. 이 후, 앱들은 최고점부터 최저점까지 순위가 매겨지고 유저들에게 순위를 공개한다. 점수는 Wide & Deep 모델을 사용하여 계산된다.
-
각 요청을 10ms 단위로 처리하기 위해 단일 배치 추론 단계에서 모든 후보 앱의 점수를 매기는 대신 더 작은 배치를 병렬로 실행하여 멀티스레딩 병렬 처리를 사용하여 성능을 최적화한다.
5. EXPERIMENT RESULTS
5.1 App Acquisitions
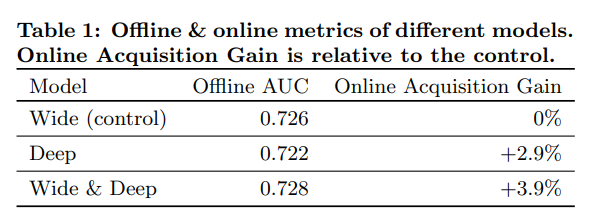
- Wide & Deep 모델은 대조군에 비해 app acquisition을 +3.9% 향상시켰다.
5.2 Serving Performance

- 멀티스레딩을 구현하고, 각 배치를 더 작은 크기로 분할하여 serving latency를 14ms로 단축했다.

5개의 댓글

투빅스 17기 염제윤 입니다.
Wide & Deep Learning for Recommender Systems
Linear model(변수간 상호 작용을 기억(memorization)하는데 효과적이고 해석 가능, 하지만 학습이 안되어 있는 것은 일반화 불가능하며, 많은 피처 엔지니어링이 요구된다.)과 Memorization(아이템이나 피처 간의 동시 발생을 학습)의 장점을 혼합한 모델이다.
Wide Component(Linear model)의 경우 raw input features와 변환시킨 features를 cross-product transformation을 사용하여 비선형성을 추가하여 사용한다. 이것은 마치 선형방정식에 xy와 같은 교호작용 항들을 추가하는 것과 비슷한 효과를 지니게 된다.
The Deep Component의 경우 categorical value들을 저차원의 임베딩 벡터로 만든 후 신경망을 거치게 한다.
이 두개의 component들에서 나온 값들을 하나의 로지스틱 손실함수의 값으로 만들기 위해 output log odds의 가중치 합을 사용하여 결합한다. 이를 이용하면, 만약 앙상블 학습을 진행할 경우, 보장된 모델을 (따라서 볼륨이 커진다) 써야하지만, 이렇게 가중치 합, joining training을 거칠 경우 wide와 deep모두를 최적화 할 수 있게 되며, Wide가 deep의 단점을 보완하는 것이 핵심이기에 충분한 방법이다. 매우 Big한 모델이기때문에 만약 새로운 데이터가 추가된다면, 현재 갖고있는 학습된 가중치를 초기값으로 해서 학습을 진행한다. (warm starting system)

투빅스 17기 나다경입니다.
흔히 regression이나 classification 문제를 풀때, linear 모델을 사용한다.
이때 feature간의 cross-product는 데이터의 특징을 기억하는데 효과적이다. 하지만 일반화를 위해서는 공수가 많이드는 엔지니어링 과정을 거쳐야한다.
반면 임베딩을 활용한 neural net 모델은 엔지니어링 노력이 덜 들고, feature간의 combination을 학습하기에도 탁월하다.
하지만 지나친 일반화로 인해 데이터의 특징을 자세히 기억하지 못하는 문제가 있다.
이런 문제에 주목해 본 논문은 memorization에 특화된 linear wide 모델과, generalization에 특화된 non-linear deep모델을 결합한 wide and deep 모델을 제안한다.
안녕하십니까 투빅스 17기 김상윤입니다.
wide (linear) 모델은 모든 item-feature 동시 발생을 학습하기에 관계 기억에 유용하지만 generalization이 어렵습니다. Deep neural networks 모델은 저차원 임베딩을 통해 generalization이 용이 하지만 , sparse하면 정확성이 떨어집니다.
wide and deep 모델 앞의 두 모델을 결합해 성능을 높이는 구조입니다.
두 모델을 결합 할 때 joint training을 활용하는데 이는 앙상블과 달리 두 모델의 parameter를 반영한 cost함수를 통해 동시에 최적화하기에 필요로 하는 feature 수가 적습니다.

투빅스 16기 이승주입니다.
본 논문은 memorization에 특화된 wide모델 (linear model)과, generalization에 특화된 deep모델을 결합한 것입니다. 두 ouput을 가중합하고 joint training을 위해 공통 로지스틱 손실함수에 입력됩니다. 공동훈련과 앙상블의 차이점은 앙상블은 개별 모델이 따로 훈련이 되지만, 공동 훈련은 모든 파라미터를 동시에 최적화합니다. 두 모델을 통해 sparse feature interaction을 효과적으로 기억할 수 있는 반면, 딥 모델은 저차원 임베딩을 통해 이전에 관찰되지 않은 feature interaction을 일반화할 수 있다는 특징의 모델입니다.
투빅스 17기 박나윤입니다.
본 논문은 memorization과 generalization의 장점을 결합한 Wide & Deep learning에 관한 내용이다.
추천시스템의 개요는 먼저 user의 query에 잘 일치하는 아이템의 목록을 반환하고 후보 풀을 줄인 다음 랭킹 모델은 모든 아이템에 점수를 매긴다.
점수는 user가 y앱에 action을 할 확률이다.
앙상블의 경우 모델이 독립적으로 학습되기 때문에 모델의 사이즈가 크지만 joint training은 학습 시 파라미터를 동시에 최적화하기 때문에 그렇지 않다.
앱 추천 파이프라인의 구현은 데이터생성, 모델학습, 모델 서빙으로 구성된다.
데이터 생성에서는 특정 시간동안 user와 app의 impression 데이터를 통해 학습 데이터를 생성한다.
모델 학습과정에서 input layer는 학습 데이터와 vocabularies를 사용하여 feature를 생성한다.
Wide component는 설치된 앱과 impression 앱의 cross-product transformation로 구성된다.
임베딩 벡터를 통해 dense vector를 생성하고 ReLU레이어와 로지스틱 output unit으로 넣는다.
모델 서버는 앱 검색 및 사용자 변수로부터 각 앱에 점수를 매긴다.