모델 기반 추천 알고리즘
모델 기반 추천 알고리즘 (model-based RS)
메모리 기반 추천 알고리즘(memory-based RS)
: CF(Collaborative Filtering)로 대표되며, 추천이 필요 할 때 마다 데이터로 계산하여 추천하는 방식입니다. 개별 사용자 데이터에 집중할 수 있지만, 모든 데이터가 매번 메모리에 올라와 있어야 하기 때문에 계산시간이 오래 걸린다는 특징이 있습니다.
모델 기반 추천 알고리즘 (model-based RS)
: 데이터로 한 번 모델을 생성해 놓고, 이 모델을 통해 추천을 제공하는 방식입니다. 모델 생성 때는 많은 계산이 요구되지만 매번 더 빠른 추천을 제공 할 수 있으며, 메모리 기반 RS와 달리 사용자의 평가 패턴으로 모델을 구상하기 때문에 잘 드러나지 않는 weak-signal을 더 잘 잡아 낼 수 있습니다.
: MF(Matrix Factorization) 방식과 deep-learning을 활용한 방식이 여기 속합니다.
SVD vs MF
: 추천시스템 분야에서 흔히 SVD와 MF가 같은 의미로 사용되고는 합니다.
결론부터 말하자면 명백히 둘은 다른 기법이고, 실제로 SVD기법은 추천시스템에서 거의 사용되지 않습니다.
추천시스템의 데이터셋에는 사용자가 평가하지 않은 많은 null값이 존재하게 되는데,
- (3개의 행렬로 분해되는) SVD방식에서는 null을 대체한 0값이 하나의 값으로 적용돼서 학습 후에도 0에 근사한 예측값이 도출됩니다.
즉, null에 대한 예측이 제대로 이루어지지 못합니다.
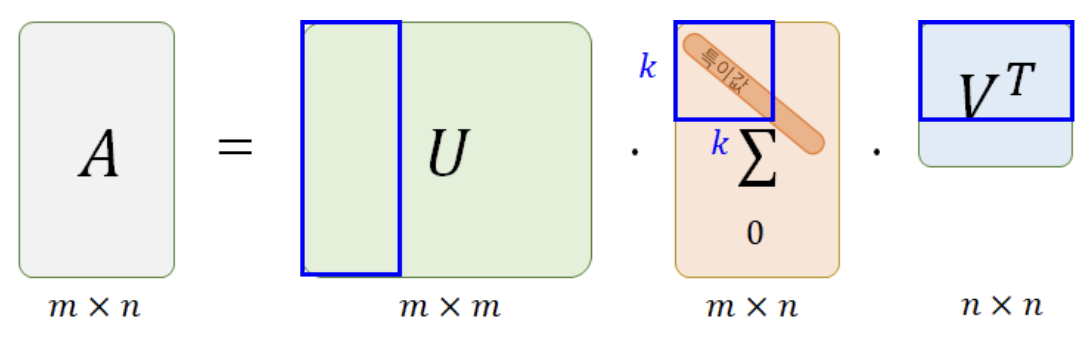
- (2개의 행렬로 분해되는) MF방식은 모델을 학습하는 과정(SGD)에서 null(0)값을 제외하고 계산하는 구조이며, 이렇게 학습된 행렬 P,Q를 통해 null에 대한 예측도 정확하게 할 수 있습니다.
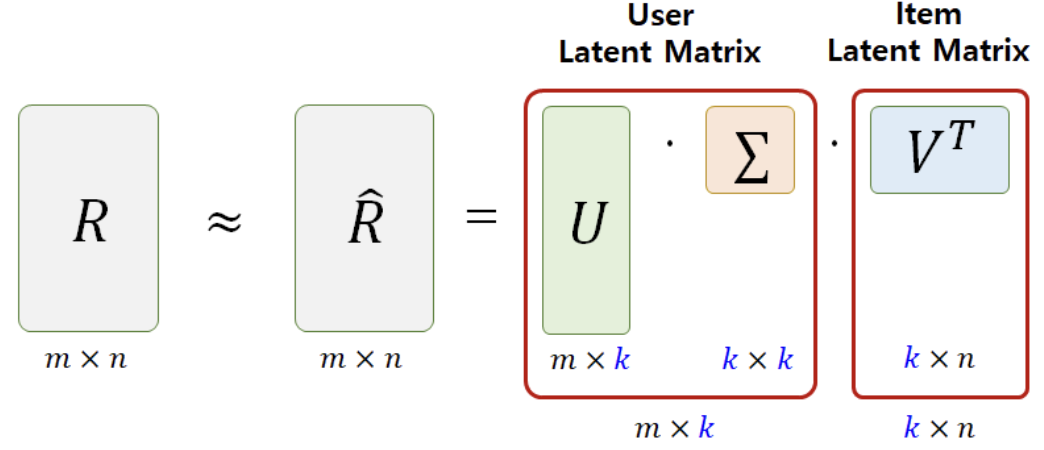
Matrix Factorization(MF) 알고리즘의 원리
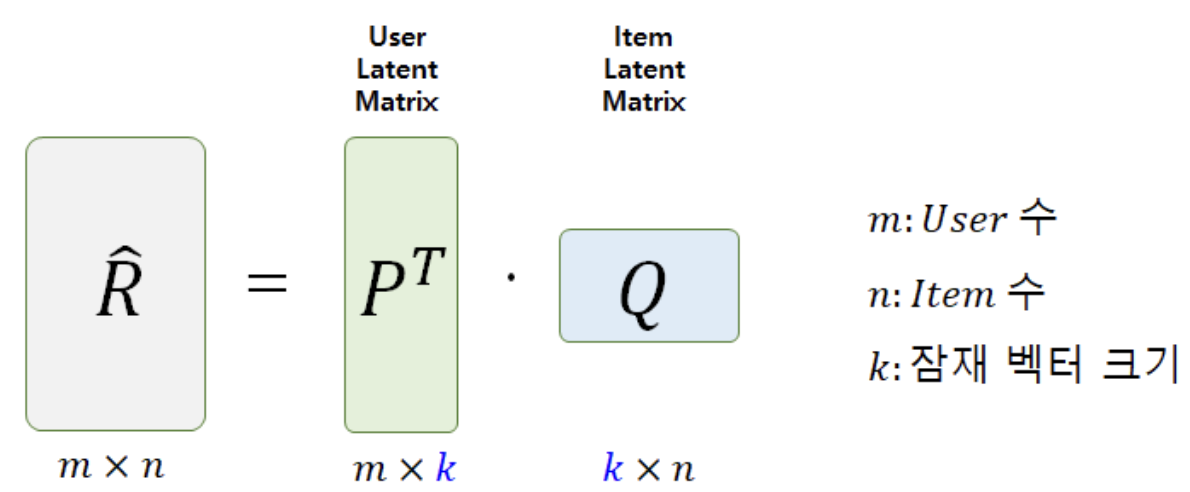
- MF 알고리즘은 R : [ user x item ] 형태의 full-matrix(평가데이터)를
- P : [ user x feature ]
- Q : [ item x feature ]
두 개의 행렬로 쪼개서 분석하는 방식입니다.
- 여기서 k개의 feature은 latent factor(잠재요인)로, user와 item이 공유하고 있는 특성입니다. 이 k개의 특성을 매개로 user와 item의 관계성이 형성됩니다.
- MF 알고리즘을 통해 우리가 궁극적으로 얻으려는 모델의 핵심은, user와 item의 특성이 가장 잘 적용된 각각의 latent factor value를 찾는 것 입니다.
- P, Q기반으로 예측값을 구하는 기본 식
MF 기반 추천 알고리즘의 과정
- 잠재요인의 개수 K를 정합니다.
- 임의의 값으로 채워진 두 행렬 P(m x k), Q(n x k)를 생성합니다.
- 실제 평점과 예측 평점 오차를 줄여가며 P, Q를 수정합니다. (SGD)
- 기준에 도달 할 때 까지 3.과정을 반복 합니다.
-
기본 오차
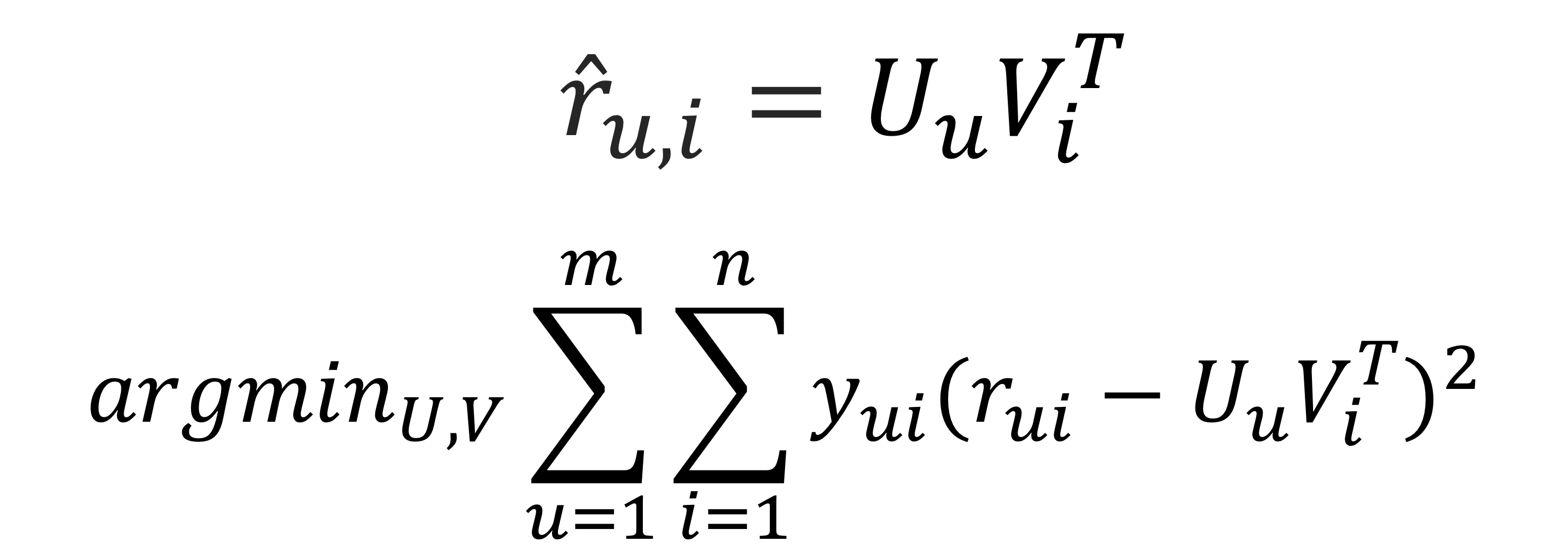
-
과적합 방지 위한 정규화 적용
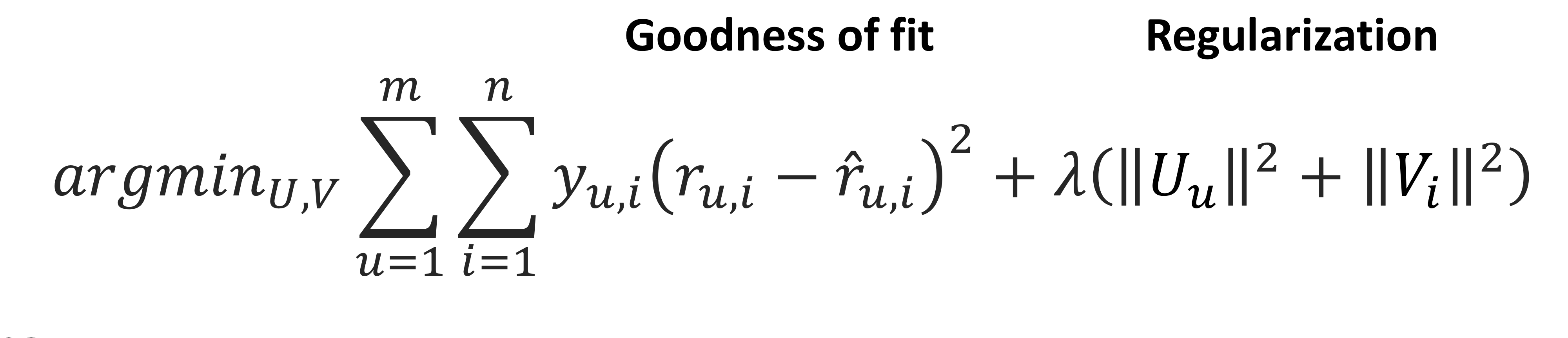
-
각 user와 item의 bias 고려
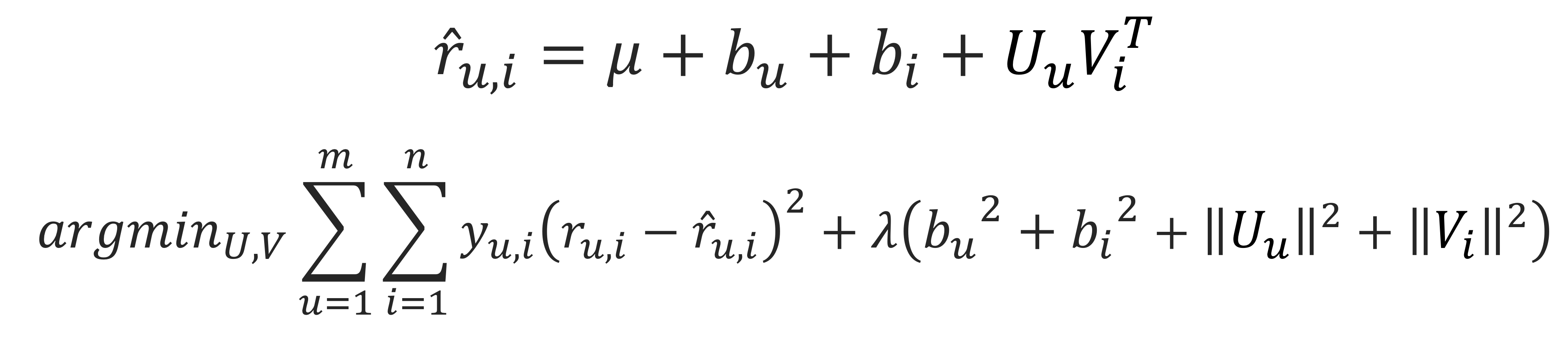
SGD 외 Optimization
- ALS (Alternating Least Squares)
: SGD의 목적함수(objective function)는 non-convex function이기 때문에 gredient descent를 사용할 때 속도가 느리고 cost가 많이 들게 됩니다.
이러한 점을 극복하기 위해 도입된 방법이 ALS입니다. 두 행렬을 동시에 최적화 하는 대신, 하나의 행렬을 고정시켜서 다른 행렬을 최적화 한 후 반대의 최적화를 진행하는 과정을 반복함으로써 최적을 찾아가는 방법입니다. 이러한 방법을 이용하면 목적함수가 convex function의 수렴된 형태를 가짐으로써 더 빠른 Optimization이 가능하게 됩니다.

K와 iterations의 최적값 찾기
- iterations로 춘분히 큰 숫자를 준 채로, K를 50~260까지 넓은 범위에서 10간격으로 RMSE를 계산해 최적값을 찾습니다.
- 찾은 최적값 K를 기준으로 더 작은 1의 간격으로 다시 RMSE값을 계산해 K의 최적값을 찾습니다.
- K를 찾은 최적값으로 고정 후 iterations의 1~300 범위에서 설정, 반복하여 iterations 최적값을 찾습니다.
- 학습률과 정규화 정도도 같은 방법으로 최적값을 찾아줍니다.
- train/test set 분리와, SGD 실행 시 적용되는 난수에 따라 계산값이 달라질 수 있으므로 코드를 여러번 반복 실행 후 평균값으로 최적값을 설정합니다.
- 각 파라미터의 최적값이 다른 파라미터 값의 변화에 영향을 받을 수 있다는 것입니다. 때문에 특정 파라미터부터 최적값을 찾아 고정 후, 차례로 다음 파라미터 최적값을 찾아나가는 방식으로 진행합니다.
참고
- 이미지
https://sungkee-book.tistory.com/12
https://seamless.tistory.com/38
투빅스16-17기 세미나 RS_basic 발표자료 - ALS
https://yeo0.github.io/data/2019/02/23/Recommendation-System_Day8/

7개의 댓글

투빅스 17기 박나윤입니다.
1) 메모리 기반
추천을 위한 데이터를 모두 메모리에 갖고 추천이 필요할 때마다 이 데이터를 사용해서 계산 및 추천
Ex) Collaboratice Filtering
2) 모델 기반
데이터로부터 추천을 위한 모델 구성한 후에 이 모델만 저장하고, 실제 추천할 때에는 이 모델을 사용
Ex) Matrix Factorization(MF) : 행렬 요인화 방식, Deep Learning 방식
평가데이터 (사용자 * 아이템)으로 구성된 하나의 행렬을 2개의 행렬로 분해하는 방법!
3) SSG
1 잠재요인의 갯수 k를 정한다.
2 주어진 K에 따라 P(MxK)와 Q(NxK)의 임의의 수로 채워진 행렬을 만든다.
3 P, Q 행렬을 이용하여 예측평점 Rhat = PxQt 계산
4 실제 데이터와 R과 예측평점 Rhat을 비교하여, 오차를 구하고, 이 오차를 줄이기 위해 P,Q를 수정
5 반복(정해진 iteration 혹은 수렴할때까지)

투빅스 17기 이지수입니다.
메모리 기반 추천(ex. CF)는 모든 데이터를 메모리에 저장해야해서 대량의 데이터일 경우 계산시간이 너무 오래 걸린다는 단점이 있다. 하지만, 모델 기반 추천 방식은 일단 모델이 만들어지만 빠른 반응이 가능하다는 장점이 있다.
MF 방식은 사용자와 아이템으로 구성된 하나의 행렬을 2개의 행렬로 분해하는 방법이며, 분해된 행렬은 사용자 잠재요인행렬과 아이템 잠재요인행렬이라고 부른다.
P,Q 행렬은 SGD 방법을 통해서 최적화 할 수 있는데,이 때 정규화 항을 추가하고, 사용자와 아이템의 경향성을 고려해야한다.

투빅스 16기 이승주
모델 기반 추천 알고리즘은 모델을 통해 추천을 제공하는 방식입니다. 주로 MF(Matrix Factorization) 방식과 deep-learning을 활용한 방식이 여기 속합니다. 특잇값 분해를 기반으로 한 아이템-유저 행렬은 잠재행렬로 분해되고 학습을 통한 잠재 행렬의 업데이트를 통해 아이템-유저 행렬 내의 존재하지 않은 평점 또한 예측할 수 있게 됩니다. 학습의 방식은 대표적으로 SGD와 ALS가 있습니다.
최적의 잠재 행렬 크기 K를 찾기 위한 방식까지 정리해주셔서 인상깊었습니다. 감사합니다!

투빅스 16기 박한나입니다.
- CF는 대표적인 memory-based RS이고, MF와 딥러닝 방식은 대표적인 model-based RS이다.
- 추천시스템 분야에서 SVD와 MF는 같은 의미로 사용되지만 사실 둘은 명백히 다른 기법이다.
- MF방식은 User Latent Matrix와 Item Latent Matrix로 full matrix를 분해한 후 SGD로 학습시킨다.
- k는 하이퍼파라미터로 latent factor의 개수를 의미한다. 이 k개의 특성을 매개로 user와 item의 관계성이 형성된다.
- MF를 학습할 때 과적합 방지를 위한 정규화와 user와 item 각각의 bias를 고려한다.
(대댓글로 잘못 달아 다시 올립니다)
투빅스 16기 김종우
앞에서는 메모리 기반의 추천 알고리즘을 보았다면, 이번 강의에서는 모델 기반의 추천 알고리즘을 보았다. 모델 기반 추천 알고리즘은 MF 방식과 deep - learning방식이 있다. SVD와 MF는 행렬 분해라는 비슷한 목적을 가지고 있지만 MF는 SVD와 달리 2개의 latent feature를 추출한다. 2개의 latent feature으로 rating matrix를 구성한 후에 rating prediction을 진행한다.

투빅스 17기 염제윤입니다.
이전의 cf는 메모리기반 알고리즘이다.
모델 기반 알고리즘은 만들어진 모델을 이용하여 입력값에 따른 결과값을 내는 알고리즘이다.
MF 모델(svd라고 불리우고는 있지만 엄연히 실제 svd와는 다르다!) 의 경우 sgd 방식을 이용하여 초기화된 PQ의 행렬들을 반복적으로 갱신하는 방식으로 실제값의 데이터 매트릭스를 가장 잘 설명하는 행렬로 만드는 모델이다. 이를 통해 실제로 NAN값으로 비어져있던 값들의 칸이 수렴한 pq의 행렬을 통해 확인할 수 있다.
투빅스 17기 나다경입니다.
MF 방식은 (사용자 X 아이템)으로 구성된 하나의 행렬을 2개의 행렬로 분해하는 방법이다. R(평가 데이터) 행렬을 P(사용자 행렬)과 Q(아이템 행렬)로 쪼개어 분석하는 방식이다. K는 잠재요인이며, 사용자오 아이템의 특정을 K개의 잠재요인을 사용해서 분석하는 모델이다.
MF와 SVD의 개념은 혼동할 수 있으나 명백히 다른 기법이다. SVD는 데이터를 3개의 행렬로 분해해서 학습시키고 3개의 행렬로 원래의 행렬을 재현하는 기법이다. 그에 비해 MF에서는 원레 데이터를 P와 Q, 2개의 행렬로 분해한다는 점에서 차이가 있다.