협업 필터링 추천 시스템 (Collaborative filtering recommendation system)
협업필터링이란?
- 어떤 아이템에 대해서 비슷한 취향을 가진 사람들이 다른 아이템에 대해서도 비슷한 취향을 가지고 있을 것이라고 가정하고 추천을 하는 알고리즘
- 추천의 대상이 되는 사람과 취향이 비슷한 사람들(neighbor)을 찾아 이 사람들이 공통적으로 좋아하는 제품 또는 서비스를 추천 대상인에게 추천하는 것
협업 필터링의 원리
아래의 표는 영화(M1~M5)에 대한 5명의 사용자(U1~U5)의 평가에 대한 자료이다. 각 사용자는 영화를 본 후에 점수(5점 만점)로 영화를 평가한다. 만일 U1에게 협업 필터링 방법으로 영화를 추천한다면 다음과 같다.
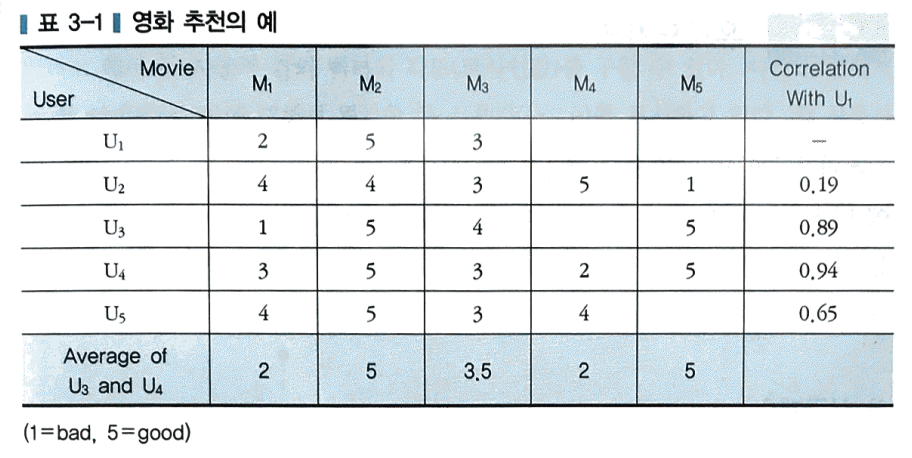
1) 우선 U1과 비슷한 영화 취향을 가진 사용자를 찾는다. 각 사용자의 유사성(similarity)을 계산하면 된다. 맨 오른쪽 열에 U1과 다른 사용자의 상관계수가 표시되어 있다. U3와 U4가 U1과 가장 높은 상관관계를 보이므로 이 둘을 neighbor로 분류한다.
2) 다음으로 U1이 보지 않은 영화 중 U3와 U4가 좋은 평점을 준 영화를 찾는다. M4,M5에 대해 U3와 U4의 평점의 평균을 내어보니 각각 2와 5이다. 따라서 평점 평균이 높은 M5를 U1에게 추천 영화로 제시한다.
유사도 지표
CF에서 사용자 간의 유사도를 구할 때 사용하는 지표이다.
(1) 상관계수
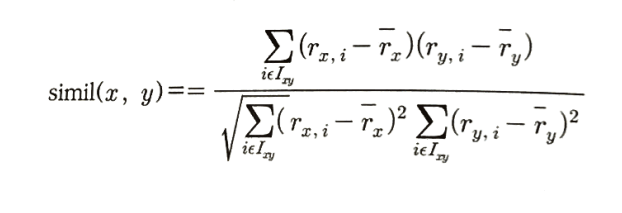
상관계수는 협업필터링에서 좋은 성능을 내지 못한다.
(2) 코사인 유사도
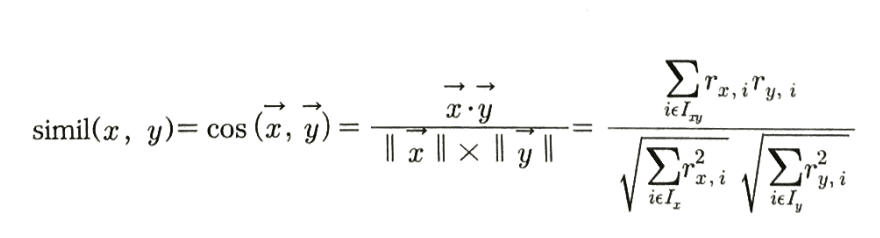
(3) 타니모토 계수

- 데이터가 이진값일 경우 사용
- 타니모토 계수의 변형으로 자카드 계수(Jaccard coefficient)가 있음
기본 CF 알고리즘
가장 기본적인 CF 알고리즘은 neighbor를 전체 사용자로 한다. 즉, 현재 사용자와 취향이 비슷한 사용자 그룹을 따로 선정하지 않고 모든 사용자의 평점을 가지고 예측을 한다. 방법은 다음과 같다.
1) 모든 사용자 간의 평가의 유사도를 계산한다.
2) 현재 추천 대상과 다른 사용자의 유사도를 추출한다.
3) 현재 사용자가 평가하지 않은 모든 아이템에 대해 현재 사용자의 예상 평가값을 구한다. 예상 평가값은 다른 사용자의 해당 아이템에 대한 평가를 현재 사용자와 그 사용자간의 유사도로 가중 평균해서 구한다.
4) 아이템 중에서 예상 평가값이 가장 높은 N개의 아이템을 추천한다.
# train set의 모든 가능한 사용자 pair의 Cosine similarities 계산
from sklearn.metrics.pairwise import cosine_similarity
matrix_dummy = rating_matrix.copy().fillna(0)
user_similarity = cosine_similarity(matrix_dummy, matrix_dummy)
user_similarity = pd.DataFrame(user_similarity, index=rating_matrix.index, columns=rating_matrix.index)
# 주어진 영화의 (movie_id) 가중평균 rating을 계산하는 함수,
# 가중치는 주어진 사용자와 다른 사용자 간의 유사도(user_similarity)
def CF_simple(user_id, movie_id):
if movie_id in rating_matrix:
# 현재 사용자와 다른 사용자 간의 similarity 가져오기
sim_scores = user_similarity[user_id].copy()
# 현재 영화에 대한 모든 사용자의 rating값 가져오기
movie_ratings = rating_matrix[movie_id].copy()
# 현재 영화를 평가하지 않은 사용자의 index 가져오기
none_rating_idx = movie_ratings[movie_ratings.isnull()].index
# 현재 영화를 평가하지 않은 사용자의 rating (null) 제거
movie_ratings = movie_ratings.dropna()
# 현재 영화를 평가하지 않은 사용자의 similarity값 제거
sim_scores = sim_scores.drop(none_rating_idx)
# 현재 영화를 평가한 모든 사용자의 가중평균값 구하기
mean_rating = np.dot(sim_scores, movie_ratings) / sim_scores.sum()
else:
mean_rating = 3.0
return mean_rating
위의 방법으로 CF 추천을 한 결과 RMSE가 약 1.017로 계산되었다.
이웃을 고려한 CF
- 이웃을 전체 사용자로 하는 대신에 유사도가 높은 사람만 이웃으로 선정해서 추천을 한다.
- 고려해야 할 사항은 이웃을 정하는 기준이다. 첫 번째 방법은 KNN 방법이고, 두 번째 방법은 유사도의 기준을 정해놓고 이 기준을 충족시키는 사용자를 이웃으로 정하는 Thresholding 방법이다.
- 일반적으로 Thresholding이 KNN보다 정확하지만 정해진 기준을 넘는 사용자가 없어서 추천을 하지 못하는 경우가 발생할 수 있기 때문에 KNN이 무난하게 많이 쓰인다.
# Neighbor size를 정해서 예측치를 계산하는 함수
def cf_knn(user_id, movie_id, neighbor_size=0):
if movie_id in rating_matrix:
# 현재 사용자와 다른 사용자 간의 similarity 가져오기
sim_scores = user_similarity[user_id].copy()
# 현재 영화에 대한 모든 사용자의 rating값 가져오기
movie_ratings = rating_matrix[movie_id].copy()
# 현재 영화를 평가하지 않은 사용자의 index 가져오기
none_rating_idx = movie_ratings[movie_ratings.isnull()].index
# 현재 영화를 평가하지 않은 사용자의 rating (null) 제거
movie_ratings = movie_ratings.drop(none_rating_idx)
# 현재 영화를 평가하지 않은 사용자의 similarity값 제거
sim_scores = sim_scores.drop(none_rating_idx)
##### (2) Neighbor size가 지정되지 않은 경우
if neighbor_size == 0:
# 현재 영화를 평가한 모든 사용자의 가중평균값 구하기
mean_rating = np.dot(sim_scores, movie_ratings) / sim_scores.sum()
##### (3) Neighbor size가 지정된 경우
else:
# 해당 영화를 평가한 사용자가 최소 2명이 되는 경우에만 계산
if len(sim_scores) > 1:
# 지정된 neighbor size 값과 해당 영화를 평가한 총사용자 수 중 작은 것으로 결정
neighbor_size = min(neighbor_size, len(sim_scores))
# array로 바꾸기 (argsort를 사용하기 위함)
sim_scores = np.array(sim_scores)
movie_ratings = np.array(movie_ratings)
# 유사도를 순서대로 정렬
user_idx = np.argsort(sim_scores)
# 유사도를 neighbor size만큼 받기
sim_scores = sim_scores[user_idx][-neighbor_size:]
# 영화 rating을 neighbor size만큼 받기
movie_ratings = movie_ratings[user_idx][-neighbor_size:]
# 최종 예측값 계산
mean_rating = np.dot(sim_scores, movie_ratings) / sim_scores.sum()
else:
mean_rating = 3.0
else:
mean_rating = 3.0
return mean_rating위의 방법으로 CF 추천을 한 결과 RMSE가 약 1.011로 이전보다 개선되었다.
다음은 실제 추천을 받는 기능을 구현한 코드이다. 추천을 받을 사용자 ID, 추천 아이템 수, 이웃 크기를 파라미터로 넘겨주면 이 사용자를 위한 추천 영화 리스트를 리턴한다.
##### (4) 주어진 사용자에 대해 추천을 받기
# 전체 데이터로 full matrix와 cosine similarity 구하기
rating_matrix = ratings.pivot_table(values='rating', index='user_id', columns='movie_id')
from sklearn.metrics.pairwise import cosine_similarity
matrix_dummy = rating_matrix.copy().fillna(0)
user_similarity = cosine_similarity(matrix_dummy, matrix_dummy)
user_similarity = pd.DataFrame(user_similarity, index=rating_matrix.index, columns=rating_matrix.index)
def recom_movie(user_id, n_items, neighbor_size=30):
# 현 사용자가 평가한 영화 가져오기
user_movie = rating_matrix.loc[user_id].copy()
for movie in rating_matrix:
# 현 사용자가 이미 평가한 영화는 제외 (평점을 0으로)
if pd.notnull(user_movie.loc[movie]):
user_movie.loc[movie] = 0
# 현 사용자가 평가하지 않은 영화의 예상 평점 계산
else:
user_movie.loc[movie] = cf_knn(user_id, movie, neighbor_size)
# 영화를 예상 평점에 따라 정렬해서 제목을 뽑아서 돌려 줌
movie_sort = user_movie.sort_values(ascending=False)[:n_items]
recom_movies = movies.loc[movie_sort.index]
recommendations = recom_movies['title']
return recommendations
recom_movie(user_id=2, n_items=5, neighbor_size=30)최적의 이웃 크기 결정
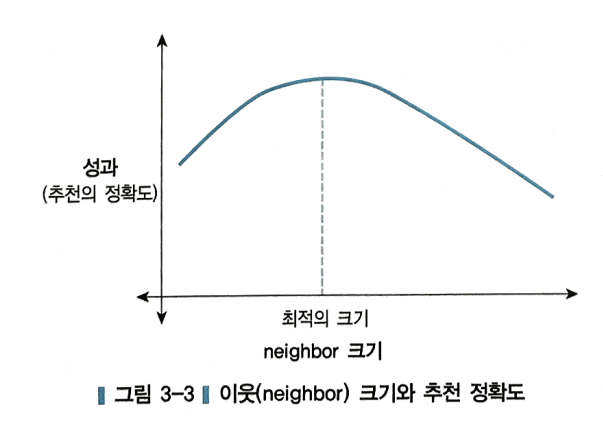
- 아래 그림처럼 일반적으로 이웃 크기가 증가하면서 추천의 정확도는 증가하다가 어느 시점 이후로 감소한다. 즉, 추천의 정확도를 최대로 하는 최적의 이웃의 크기를 사용하면 된다.
- 더불어 이웃의 크기를 고를 때는 추천을 하려는 분야와 도메인에 맞게 적절하게 정해야 한다.
사용자의 평가경향을 고려한 CF
- CF의 정확도를 더 개선시키는 방법은 사용자의 평가경향(user bias)를 고려하여 예측치를 조정하는 것이다. 사용자에 따라 평가를 전체적으로 높게 하는 사람이 있는 반면, 평가를 전체적으로 낮게 하는 사람이 있다.
- 다음은 사용자의 평가 경향을 고려하지 않고 예측한 평점이다.
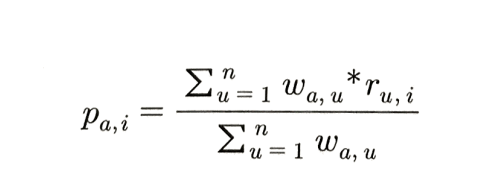
a: 사용자, u: 이웃 사용자, n: 이웃 사용자의 수
p(a,i): 아이템 i에 대한 사용자 a의 예상 평점
w(a,u): 사용자 a와 u의 유사도
r(u,i): 아이템 i에 대한 사용자 u의 평점
사용자의 평가 경향을 고려하여 평점을 구하는 방법은 다음과 같다.
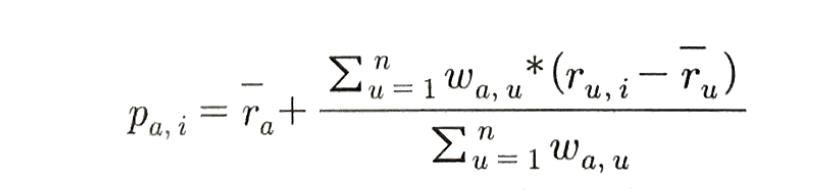
1) 각 사용자의 평점평균을 구한다.
2) 각 아이템의 평점을 각 사용자의 평균에서의 차이(평점-해당 사용자의 평점 평균)로 변환한다. 편의상 평점과 평균의 차이를 평점편차로 부르기로 한다.
3) 평점편차를 사용해서 해당 사용자의 해당 아이템의 편차 예측값을 구한다. 이 때, 해당 사용자의 이웃을 구하고 이들 이웃의 해당 아이템에 대한 평점편차와 유사도를 가중평균한다.
4) 이렇게 구한 편차 예측값은 평균에서의 차이를 의미하기 때문에 실제 예측값으로 변환하기 위해 현 사용자의 평균에 이 편차 예측값을 더해준다.
5) 예측값을 구할 수 없는 경우는 사용자의 평점평균으로 대체한다.
# train 데이터의 user의 rating 평균과 영화의 평점편차 계산
rating_mean = rating_matrix.mean(axis=1)
rating_bias = (rating_matrix.T - rating_mean).T
def CF_knn_bias(user_id, movie_id, neighbor_size=0):
if movie_id in rating_bias:
# 현 user와 다른 사용자 간의 유사도 가져오기
sim_scores = user_similarity[user_id].copy()
# 현 movie의 평점편차 가져오기
movie_ratings = rating_bias[movie_id].copy()
# 현 movie에 대한 rating이 없는 사용자 삭제
none_rating_idx = movie_ratings[movie_ratings.isnull()].index
movie_ratings = movie_ratings.drop(none_rating_idx)
sim_scores = sim_scores.drop(none_rating_idx)
##### (2) Neighbor size가 지정되지 않은 경우
if neighbor_size == 0:
# 편차로 예측값(편차 예측값) 계산
prediction = np.dot(sim_scores, movie_ratings) / sim_scores.sum()
# 편차 예측값에 현 사용자의 평균 더하기
prediction = prediction + rating_mean[user_id]
##### (3) Neighbor size가 지정된 경우
else:
# 해당 영화를 평가한 사용자가 최소 2명이 되는 경우에만 계산
if len(sim_scores) > 1:
# 지정된 neighbor size 값과 해당 영화를 평가한 총사용자 수 중 작은 것으로 결정
neighbor_size = min(neighbor_size, len(sim_scores))
# array로 바꾸기 (argsort를 사용하기 위함)
sim_scores = np.array(sim_scores)
movie_ratings = np.array(movie_ratings)
# 유사도를 순서대로 정렬
user_idx = np.argsort(sim_scores)
# 유사도와 rating을 neighbor size만큼 받기
sim_scores = sim_scores[user_idx][-neighbor_size:]
movie_ratings = movie_ratings[user_idx][-neighbor_size:]
# 편차로 예측치 계산
prediction = np.dot(sim_scores, movie_ratings) / sim_scores.sum()
# 예측값에 현 사용자의 평균 더하기
prediction = prediction + rating_mean[user_id]
else:
prediction = rating_mean[user_id]
else:
prediction = rating_mean[user_id]
return prediction위의 방법으로 CF 추천을 한 결과 RMSE가 약 0.9417로 이전보다 개선되었다.
CF 정확도 개선을 위한 신뢰도 가중 방법
- 공통 아이템이 많은 사용자와의 유사도에 공통 아이템이 적은 사용자와의 유사도보다 더 큰 가중치를 주는 방법이다.
- 예측값을 구하는 계산식을 수정하기보다 신뢰도가 일정 이상인 사용자만을 예측치 계산에 사용하는 것이 좋다. 즉, 신뢰도(공통으로 평가한 아이템의 수)가 기준값 이상인 사용자만 이웃 사용자로 활용하는 것이다.
- 비슷한 원리로 예측값을 계산하는 대상 아이템에 대해서도 평가한 사용자가 일정 수준 이상이 되는 아이템만 예측치를 계산하도록 하는 것도 가능하다.
# 사용자별 공통 평가 수 계산
rating_binary1 = np.array((rating_matrix > 0).astype(float))
rating_binary2 = rating_binary1.T
counts = np.dot(rating_binary1, rating_binary2)
counts = pd.DataFrame(counts, index=rating_matrix.index, columns=rating_matrix.index).fillna(0)
def CF_knn_bias_sig(user_id, movie_id, neighbor_size=0):
if movie_id in rating_bias:
# 현 user와 다른 사용자 간의 유사도 가져오기
sim_scores = user_similarity[user_id]
# 현 movie의 평점편차 가져오기
movie_ratings = rating_bias[movie_id]
# 현 movie에 대한 rating이 없는 사용자 표시
no_rating = movie_ratings.isnull()
# 현 사용자와 다른 사용자간 공통 평가 아이템 수 가져오기
common_counts = counts[user_id]
# 공통으로 평가한 영화의 수가 SIG_LEVEL보다 낮은 사용자 표시
low_significance = common_counts < SIG_LEVEL
# 평가를 안 하였거나, SIG_LEVEL이 기준 이하인 user 제거
none_rating_idx = movie_ratings[no_rating | low_significance].index
movie_ratings = movie_ratings.drop(none_rating_idx)
sim_scores = sim_scores.drop(none_rating_idx)
##### (2) Neighbor size가 지정되지 않은 경우
if neighbor_size == 0:
# 편차로 예측값(편차 예측값) 계산
prediction = np.dot(sim_scores, movie_ratings) / sim_scores.sum()
# 편차 예측값에 현 사용자의 평균 더하기
prediction = prediction + rating_mean[user_id]
##### (3) Neighbor size가 지정된 경우
else:
# 해당 영화를 평가한 사용자가 최소 MIN_RATINGS 이상인 경우에만 계산
if len(sim_scores) > MIN_RATINGS:
# 지정된 neighbor size 값과 해당 영화를 평가한 총사용자 수 중 작은 것으로 결정
neighbor_size = min(neighbor_size, len(sim_scores))
# array로 바꾸기 (argsort를 사용하기 위함)
sim_scores = np.array(sim_scores)
movie_ratings = np.array(movie_ratings)
# 유사도를 순서대로 정렬
user_idx = np.argsort(sim_scores)
# 유사도와 rating을 neighbor size만큼 받기
sim_scores = sim_scores[user_idx][-neighbor_size:]
movie_ratings = movie_ratings[user_idx][-neighbor_size:]
# 편차로 예측치 계산
prediction = np.dot(sim_scores, movie_ratings) / sim_scores.sum()
# 예측값에 현 사용자의 평균 더하기
prediction = prediction + rating_mean[user_id]
else:
prediction = rating_mean[user_id]
else:
prediction = rating_mean[user_id]
return prediction
SIG_LEVEL = 3
MIN_RATINGS = 2위의 방법으로 CF 추천을 한 결과 RMSE가 약 0.9413로 이전보다 개선되었다.
사용자 기반 CF와 아이템 기반 CF
- 지금까지 설명한 CF 알고리즘은 사용자를 기준으로 비슷한 취향의 이웃을 선정하는 방식을 사용하였다. 이런 방식을 사용자 기반 CF(User-Based CF: UBCF)라고 부른다.
- 반대로 아이템을 기준으로 하는 아이템 기반 CF(Item-Based CF: IBCF)도 가능하다. 이 둘 차이는 유사도를 계산하는 기준이 사용자인가 아이템인가 하는 것이다.
- UBCF는 취향이 비슷한 이웃 사용자를 알아내고, 이 그룹에 속한 사용자들이 공통적으로 좋게 평가한 아이템을 추천하는 방식이다.
- IBCF는 반대로 사용자들의 평가 패턴을 바탕으로 아이템 간의 유사도를 계산하여 사용자의 특정 아이템에 대한 예측 평점을 계산하는 방식이다. 즉, 예측 대상 사용자가 평가한 아이템의 평점과, 다른 각 아이템과의 유사도를 가중해서 평균한 값을 그 아이템에 대한 예측값으로 사용한다.
- 다음은 IBCF를 구현한 코드이다.
# train set의 모든 가능한 아이템 pair의 Cosine similarities 계산
from sklearn.metrics.pairwise import cosine_similarity
rating_matrix_t = np.transpose(rating_matrix)
matrix_dummy = rating_matrix_t.copy().fillna(0)
item_similarity = cosine_similarity(matrix_dummy, matrix_dummy)
item_similarity = pd.DataFrame(item_similarity, index=rating_matrix_t.index, columns=rating_matrix_t.index)
# 주어진 영화의 (movie_id) 가중평균 rating을 계산하는 함수,
# 가중치는 주어진 아이템과 다른 아이템 간의 유사도(item_similarity)
def CF_IBCF(user_id, movie_id):
if movie_id in item_similarity: # 현재 영화가 train set에 있는지 확인
# 현재 영화와 다른 영화의 similarity 값 가져오기
sim_scores = item_similarity[movie_id]
# 현 사용자의 모든 rating 값 가져오기
user_rating = rating_matrix_t[user_id]
# 사용자가 평가하지 않은 영화 index 가져오기
non_rating_idx = user_rating[user_rating.isnull()].index
# 사용자가 평가하지 않은 영화 제거
user_rating = user_rating.dropna()
# 사용자가 평가하지 않은 영화의 similarity 값 제거
sim_scores = sim_scores.drop(non_rating_idx)
# 현 영화에 대한 예상 rating 계산, 가중치는 현 영화와 사용자가 평가한 영화의 유사도
mean_rating = np.dot(sim_scores, user_rating) / sim_scores.sum()
else:
mean_rating = 3.0
return mean_ratingUBCF와 IBCF 장단점
-
UBCF의 장점은 각 사용자별로 맞춤형 추천을 하기 때문에 데이터가 풍부한 경우 정확한 추천이 가능하다.
-
IBCF의 장점은 정확도는 떨어지지만 사용자별로 따로따로 계산을 하지 않기 때문에 계산이 빠르다는 장점이 있다. 또한, UBCF는 정확할 때는 매우 정확하지만 터무니없는 추천을 하는 경우도 상당히 있는데 IBCF는 그럴 위험이 적다. 더불어 UBCF는 데이터가 조금 바뀔 때마다 업데이트를 해야 하지만 IBCF는 데이터가 조금 바뀌어도 추천 결과에는 영향이 크지 않기 때문에 업데이트를 자주 하지 않아도 된다.
-
정리하자면, 데이터 크기가 적고 각 사용자에 대한 충분한 정보(구매나 평가)가 있는 경우에는 UBCF, 데이터가 크거나 각 사용자에 대한 충분한 정보가 없는 경우에는 IBCF가 알맞다고 할 수 있다.
-
둘 중 어느 쪽이 정확한지는 분야마다 다르기 때문에 일률적으로 말하긴 어렵지만, 데이터가 충분하다면 UBCF가 IBCF보다 다소 정확하다고 알려져 있다. 대신, IBCF가 계산이 빠르기 때문에 아마존과 같은 대규모 데이터를 다뤄야 하는 상업용 사이트에서는 IBCF에 기반한 알고리즘이 사용된다.
추천 시스템의 성과 측정 지표
-
데이터를 train set, test set으로 나누어 정확도를 측정한다.
-
아래의 지표들은 예측값과 실제값의 차이가 적을수록, 즉 측정 지표가 작을수록 정확하다.
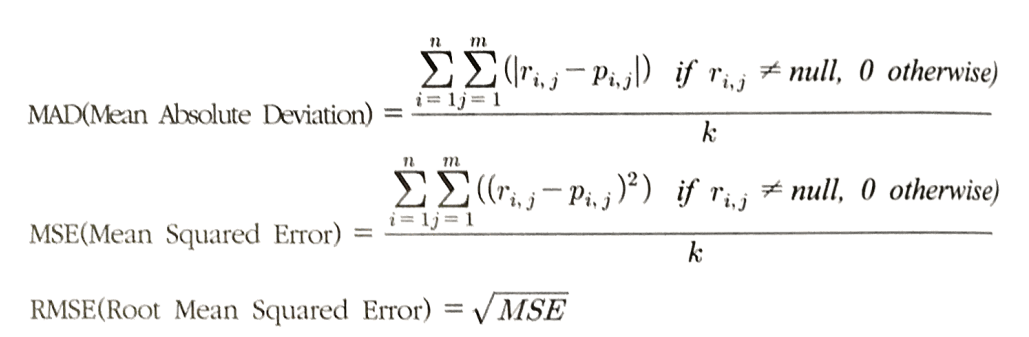
n: test set에 있는 사용자의 수
m: test set에 있는 아이템의 수
r(i,j): 사용자 i의 아이템 j에 대한 실제 평점
p(i,j): 사용자 i의 아이템 j에 대한 예상 평점
k: 정확도 계산에 포함된 총 아이템 수 (null이 아닌 평점의 개수) -
MSE와 RMSE가 많이 사용된다.
-
위의 지표는 모두 사용자의 평점이 연속값인 경우에 사용한다.
-
데이터가 이진값인 경우에는 정밀도(precision)과 재현율(recall) 등을 사용한다.
- 정확도 (accuracy) = 올바르게 예측된 아이템의 수 / 전체 아이템의 수
- 정밀도 (precision) = 올바르게 예측된 아이템의 수 / 전체 추천된 아이템의 수
- 재현율 (recall) = 올바르게 추천된 아이템의 수 / 사용자가 실제 선택한 전체 아이템 수
- 정밀도와 재현율의 조화평균(F1 score) = 2x정밀도x재현율/(정밀도+재현율)
- 범위(coverage) = 추천이 가능한 사용자의 수(혹은 아이템 수) / 전체 사용자의 수(혹은 아이템 수)
-
정밀도와 재현율은 trade-off 관계이다.
-
범위는 정밀도와 trade-off 관계이다.

- Accuracy = (TP+TN) / (TP+TN+FP+FN)
- Precision = TP / (TP+FP)
- TPR(True Positive Rate = Recall) = TP / (TP+FN)
- FPR(False Positive Rate) = FP / (FP+TN)
- 추천시스템에서 TN은 매우 큰 숫자가 되는 것이 보통이다. 그렇기 때문에 아이템이 많은 경우에는 현실적으로 TN을 사용하지 않는 측정 지표인 TPR(재현율)와 정밀도를 사용한다.
(해당 포스팅은 'Python을 이용한 개인화 추천시스템'을 바탕으로 정리하였습니다.)

7개의 댓글

투빅스 17기 박나윤입니다.
• User-based Filtering
- 특정 사용자(User)를 선택
- 예시 : SNS에서의 친구 추천 서비스
1. "평점 유사도"를 기반으로 나와 유사한 사용자(Users)들을 찾음
2. 유사한 사용자가 좋아한 Item을 추천
• Item-based Filtering
- 특정 아이템(Item)을 선택
- 예시 : 함께 구매한 경우가 많은 상품 - '사이다'와 '콜라'
1. 특정 Item을 좋아한 사용자들을 찾음
2. 그 사용자들이 공통적으로 좋아했던 다른 Item을 찾음

투빅스 17기 이지수입니다.
협업필터링은 비슷한 취향을 가진 사람들로 하여금 취향에 맞는 아이템을 추천할 수 있도록 만들어진 알고리즘이다. 유사도 지표로는 상관계수, 코사인유사도, 자카드 계수 등이 있고, 유사도를 추출하여 사용자가 평가하지 않은 모든 아이템에 대해서 예상 평가값을 구하게 되고, 예상 평가값이 높은 아이템을 추천하게 된다. 이웃을 고려한 CF는 KNN 방법과 Thresholding방법이 있다. Thresholding 방법이 정확하긴 하지만, 기준을 넘는 사용자가 많이 없을 수 있기 때문에 knn이 더 자주 사용되곤 한다. knn을 사용할 때, 최적의 이웃 크기를 결정하는 지점은 k를 늘려갈 때, 추천 정확도가 높아지다가 낮아지는 지점이다.

투빅스 16기 이승주
메모리 기반 CF 알고리즘은 모든 사용자 간의 평점의 유사도를 계산하고 유사도에 따라 타겟 사용자가 평가하지 않은 모든 아이템에 대해 예상 평점을 구한다. 예상 평점은 다른 유사 사용자의 해당 아이템에 대한 평점을 타겟 사용자와의 유사도로 가중 평균해서 구한다. 아이템 중에서 가장 높은 평점의 N개의 아이템을 추천한다. 메모리 기반 협업 필터링은 사용자 기반, 아이템 기반 협업필터링이 있고 데이터 크기가 적고 각 사용자에 대한 충분한 정보(구매나 평가)가 있는 경우에는 사용자 기반 협업 필터링, 데이터가 크거나 각 사용자에 대한 충분한 정보가 없는 경우에는 아이템 기반 협업 필터링이 사용된다.
코드까지 첨부한 자세한 설명이 많은 도움이 되었습니다. 감사합니다!

투빅스 17기 김상윤입니다.
- 협업 필터링은 비슷한 취향인 사람(neighbor)끼리 비슷한 아이템을 선택할 것이라는 가정하에 추천을 해주는 것이다.
- similarity를 통해 유사도를 구하고, CF에서 상관계수는 성능이좋지 못 해 코사인 유사도를 사용할 수 있으며 이진 데이터에는 타니모토 계수를 사용할 수 있다.
- 기본 CF 알고리즘 : sparse한 데이터의 예측 평가값은 대해 다른 사람들의 평가를 사용자간 유사도로 가중평균해서 구한다.
- 기본 알고리즘에 유사도가 높은 이웃을 고려하여 정확도를 높일 수 있다. (무난히 KNN이 많이 쓰인다.)
- 여기에 사용자의 평가경향(bias)를 반영하여 정확도를 더 높일 수 있다.
- 공통 아이템이 많은 사용자와의 유사도에 가중치를 줘 정확도를 높일 수있다. 간단하게 공통 아이템의 개수가 기준 이상인 사용자만 학습 대상으로 한다.
- 아이템 기반 CF은 같은 흐름이지만 유사도를 아이템 기반으로 계산하여 알고리즘이 진행된다.
- UBCF는 충분한 데이터가 있는 경우, IBCF는 빠른 계산을 요하거나 잦은 업데이트를 지양하고 무난히 정확한 결과를 필요로 할 때 사용한다.
투빅스 17기 염제윤입니다. 조금 늦게 작성하여 죄송합니다.
협업필터링 (일명 cf)
유저의 아이템에 대한 스코어링 데이터를 이용하여 유사도를 계산, 가장 유사한 집단을 선정하여 그에 기반해 추천을 하는 시스템이다.
유사도지표로는 상관계수, 코사인 유사도, 타니모토 계수가 있다.
이웃을 고려하는 경우 전체 사용자가 아닌 가장 유사한 집단만을 선별하므로 더 정확한 결과를 줄 수 있다. 또한 사용자의 평가경향을 고려하는 것이 좋은데, 그 이유는 사람마다의 기준이 다르기 때문이다.
cf에는 아이템 기반cf와 유저 기반 cf가 존재한다. 유저기반 cf는 정확하지만 가끔 치명적인 오답이 나오는 경우가 있고, 데이터가 업데이트 될때마다 새롭게 계산이 필요하다. 아이템 기반 cf는 매번 업데이트를 일일이 해줄 필요가 없고 계산이 빠른 장점이 있다.
성능지표로는 mse와 rmse 그리고 정확도기반의 정밀도와 재현율이 있다.
투빅스 17기 나다경입니다.
어떤 아이템에 대해서 비슷한 취향을 가진 사람들은 다른 아이템에 대해서도 비슷한 취향을 가지고 있을 것이라고 가정하는 추천 알고리즘은 협업 필터링이다. 사용자 기반 CF와 아이템 기반 CF가 있다. 유사도 지표는 코사인 유사도 등을 활용할 수 있으며, 이웃을 고려한 CF가 약간 RMSE가 개선된 결과를 보인다. 이웃의 크기는 너무 적거나 많아도 안되기에 최적의 이웃 크기는 for문으로 RMSE를 최소화하는 크기를 알 수 있다. 사용자의 평가경향을 고려한 CF는 평점편차와 가중평균의 개념이 들어가며 이는 이전 CF 알고리즘보다 크게 개선됨을 알 수 있다. 추천 시스템의 성과측정지표에는 RMSE, 재현율, F1 score 등이 있다.