MLP (Multi Layer Perceptron)
MLP 란 여러 개의 퍼셉트론 뉴런을 여러 층으로 쌓은 다층신경망 구조
입력층과 출력층 사이에 하나 이상의 은닉층을 가지고 있는 신경망이다.
처음엔 퍼셉트론이라는 이진 분류기가 시작이었다.
근데 이 퍼셉트론은 선형분류 밖에 하지 못했다.
하지만 선형 분류로는 정확한 분류를 할 수 없기 때문에 퍼셉트론 내부에
은닉층을 추가해서 xor 까지 분류할 수 있게 되었고
현재에는 두개 이상의 은닉층들을 추가해서 이용한다.
따라서 Multi Layer Perceptron이라는 MLP가 생겨나게 되었다고 한다.
MLP 진행과정
깊숙하게 말고 개념만 이해가도록 설명하면
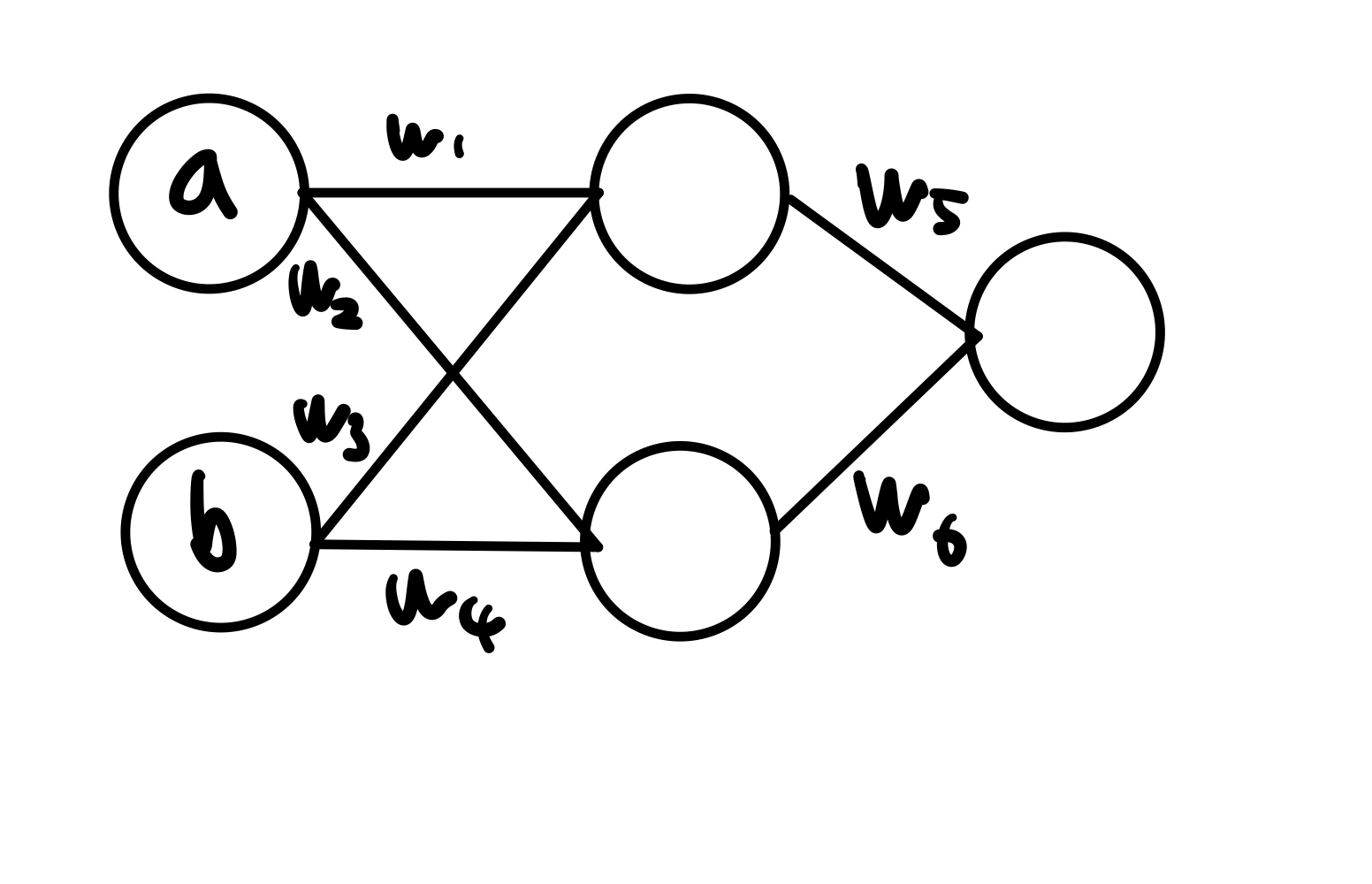
위와 같은 MLP가 있다고 하면 결과는 w5(aw1 + bw3) + w6(aw2 + bw4)가 된다.
이처럼 가중치들을 노드와 곱해가면서 결과를 도출해 내는 것이다.
❓ 근데 이렇게만 하면 항상 비슷한 결과만 나오기 때문에 계산만 복잡한 선형 분류기 일것이다.
❗️ 따라서 노드에서 활성화 함수(activation function)를 이용해서 값을 바꿔줘야 한다.
활성화 함수(Activation function)
활성화 함수에는 sigmoid, relu, softmax 등 여러가지가 있고.
이 활성화 함수를 이용해서 노드마다 값을 변환시켜 준다.
거의 relu를 많이 사용한다고 한다.
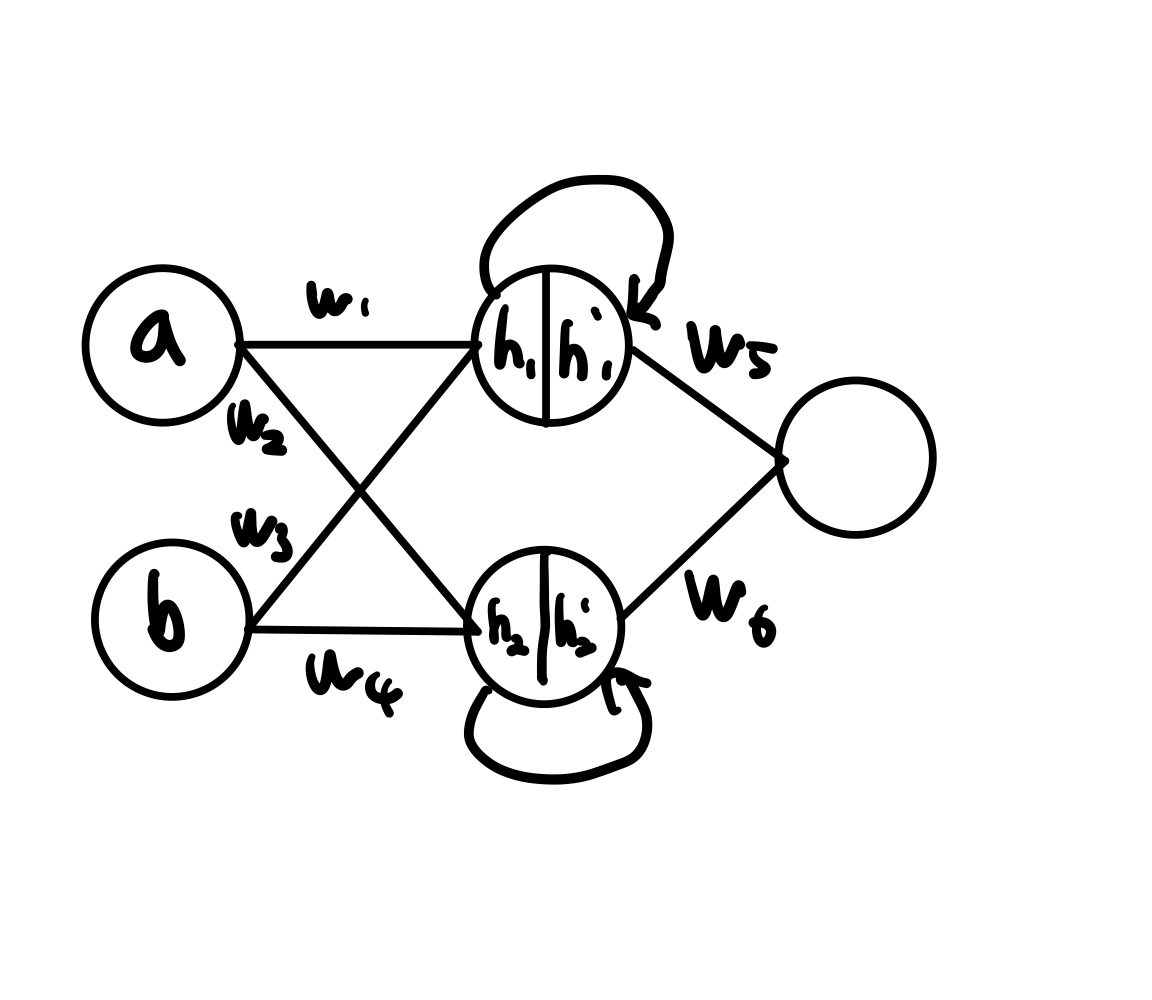
이 활성화 함수를 이용해서 결과는 도출해 낼 수 가 있게 되었다.
❓ 근데 이 결과값을 실제값에 더 정확하게 도달시키기 위해서는 어떻게 하는 걸까
❗️ w 값을 계속 변환시키면서 더 정확한 값을 찾아내는데 이 w값을 찾는데 사용되는게 경사하강법이다
경사 하강법
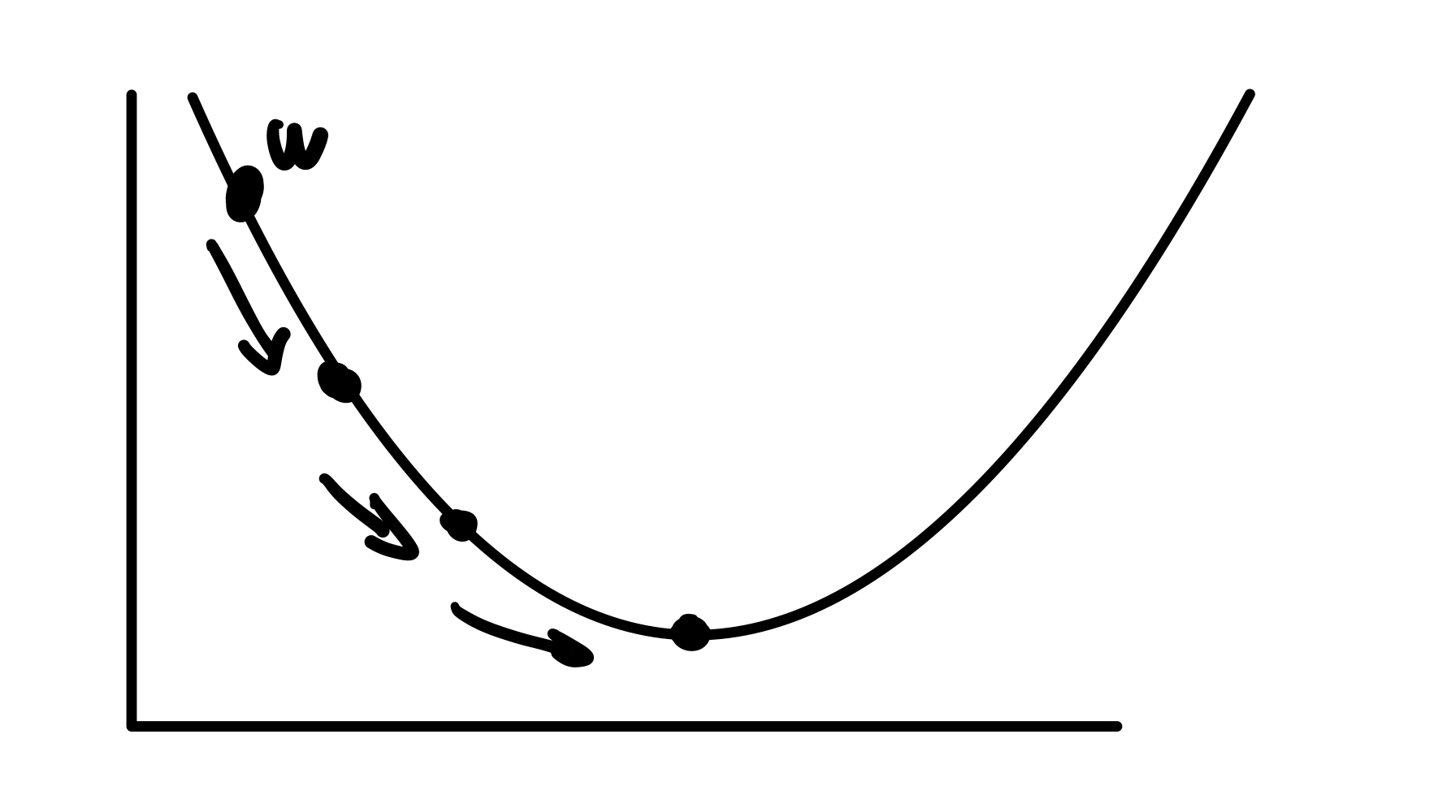
이 그래프는 w에 따른 총 손실 에러 값이다.
위 그림처럼 경사면을 따라서 내려가면서 최소 값을 찾는 과정인데
첫번째 w를 보면 기울기가 음수이다 따라서 그 기울기 값을 뺀 위치로 이동시키는 것이다.
이렇게 w를 이동시켜 가면서 총 손실 에러 값이 작은 w값을 찾는 것이다.
📌 가장 아래 꼭지점은 기울기가 0 이기 때문에 더이상 안움직임
식은 w = w - learning rage * 기울기 이다
learning rate
위의 식에서 learning rate라고 되어있는데 이게 필요한 이유는

위와 같은 그래프 에서는 w가 진짜 최소 값을 찾지 못하고 끝난다
따라서 기울기에 learning rate 값을 곱해줘서 진짜 최소 값을 구하도록 해줘야 한다.
아래처럼 learning rate를 전보다 크게 해주면 아래와 같이 제대로 w 값을 찾을 수 있다.

❓ 여기서 또 문제는 이 learning rate를 계산할 때마다 내가 정해줘야 하는가
❗️ 이건 optimizer를 이용하면 된다
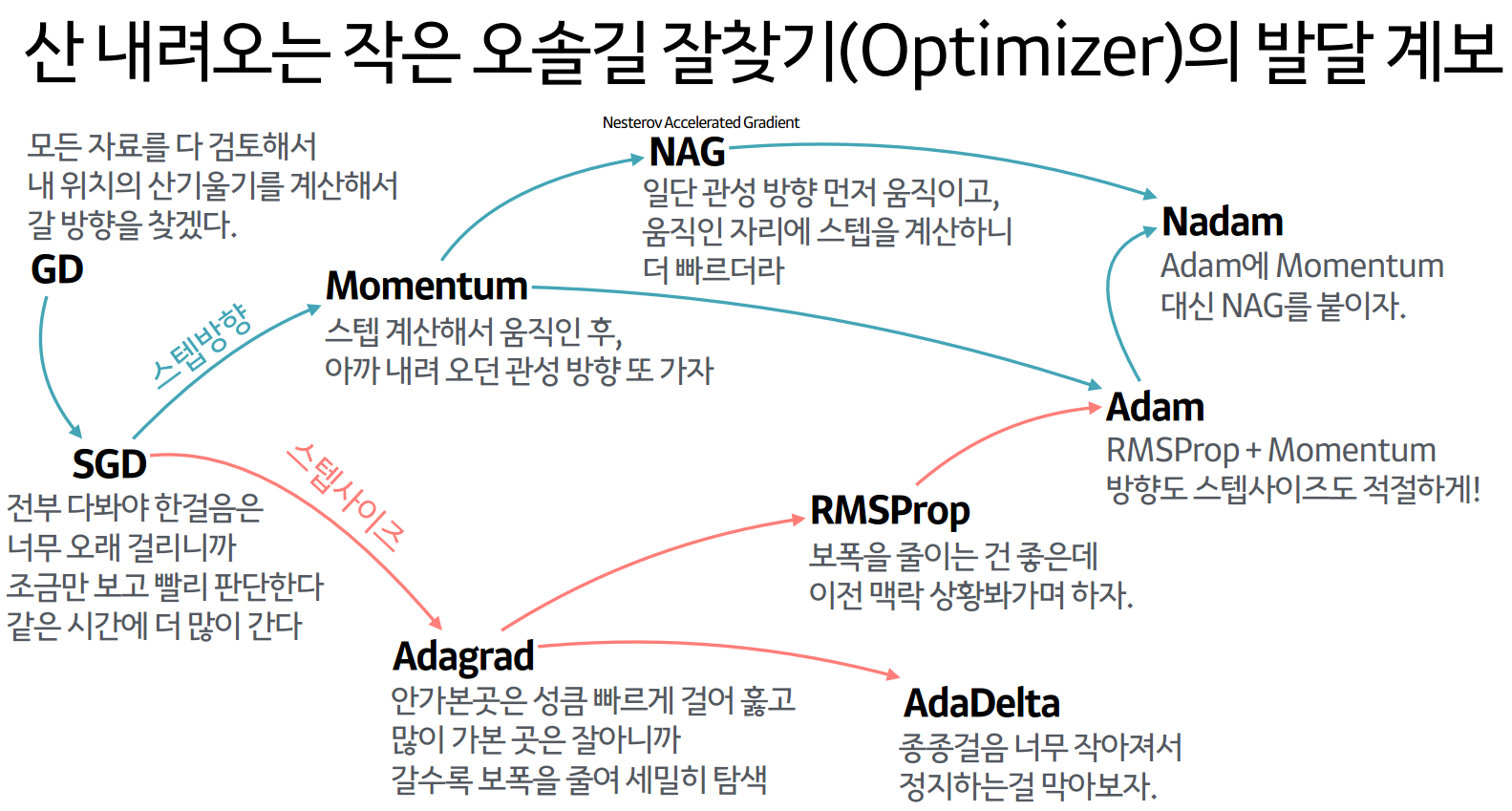
optimizer
옵티마이저는 learning rate를 특정 알고리즘을 이용해서 조절해 주는 것인데.
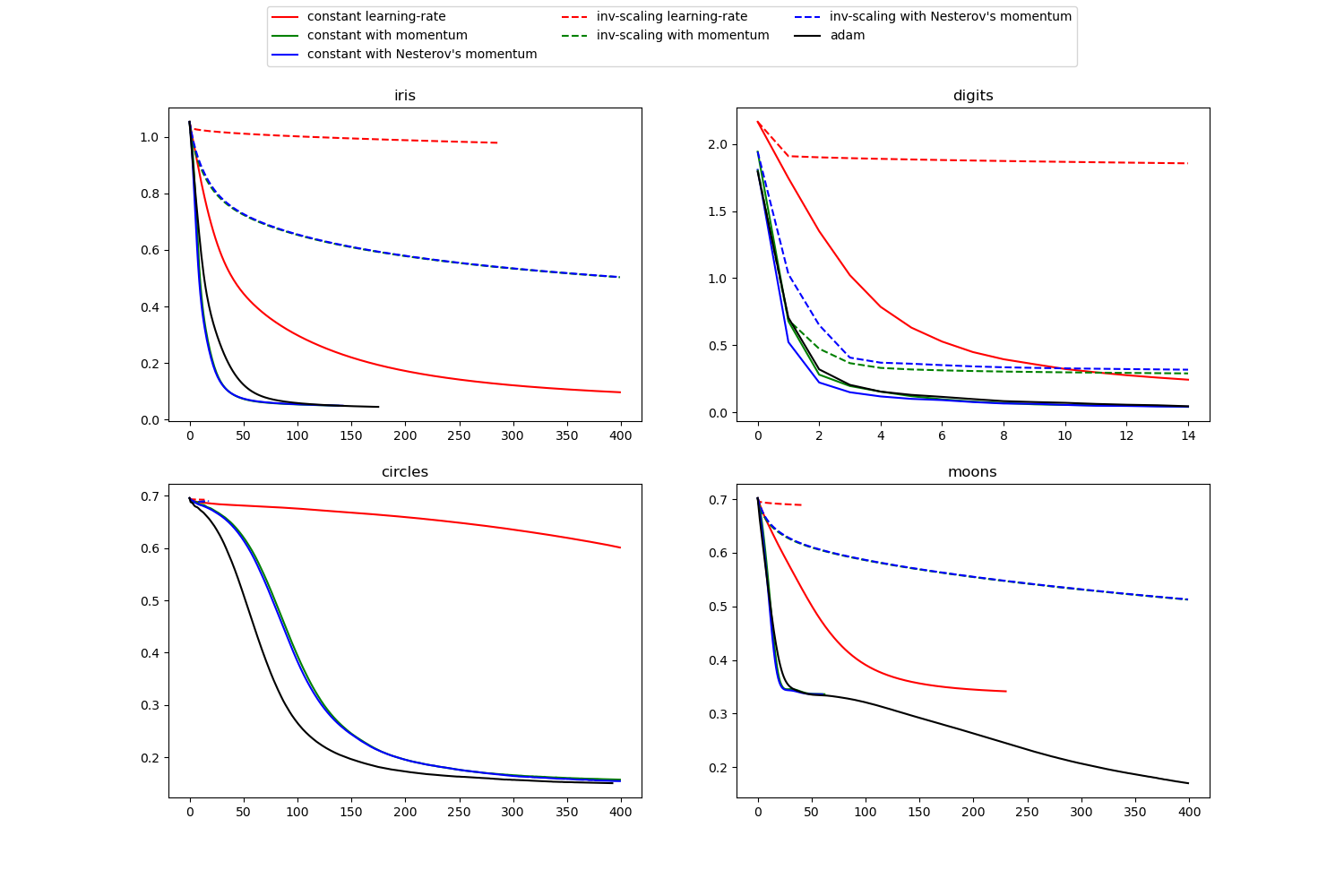
아래 그림처럼 다양한 종류가 있고 잘되어 있기 때문에 이중 하나를 이용하면 되는데
기본적으로 adam을 많이 사용한다.
파라미터
머신러닝에 대해 공부하다 보면 파라미터, 하이퍼파라미터 라는 말이 자주 나온다.
그냥 간단하게 둘다 모델의 훈련에 사용되는 변수라고 할 수 있는데
파라미터는 우리가 직접 설정해줄 필요 없는거
하이퍼파라미터는 우리가 직접 설정해줘야 하는 것이라고 생각하면 된다.
ex
http://scikit-learn.org/stable/auto_examples/neural_networks/plot_mlp_training_curves.html#sphx-glr-auto-examples-neural-networks-plot-mlp-training-curves-py
위의 사이트의 코드를 실행시키면
파라미터에 따른 loss 값 그래프를 볼 수 있다.