아이티센 온라인 강의 - DATA 산업의 이해 (AI/ML)
데이터 기술 동향
AI/ML
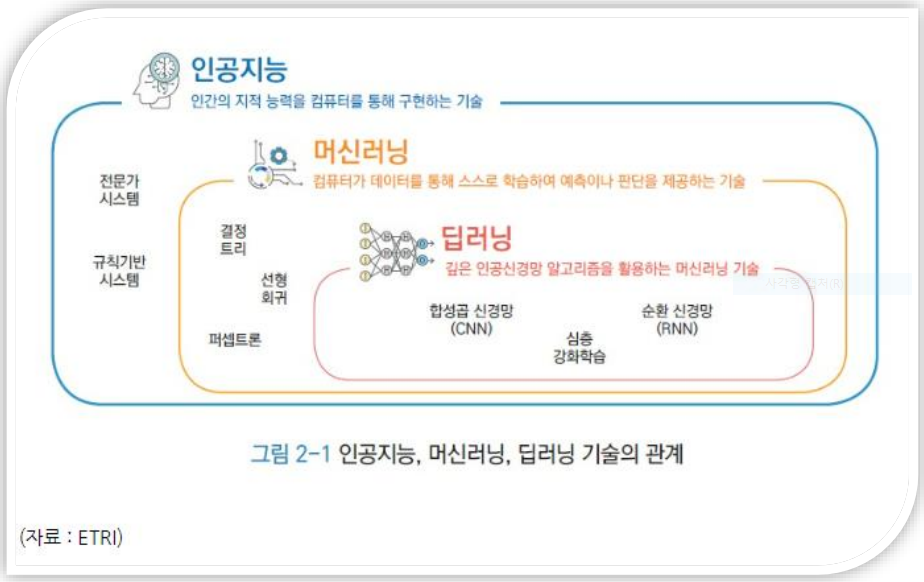
- 인공지능, 머신러인, 딥러닝 등이 활발하지 않았다.
머신러인, 딥러닝 등은 많은 데이터를 분석해서 인사이트를 얻음. 근데 데이터 양의 증가에 비해서 장비 발전 속도가 너무 느리다. 때문에 기술들을 발전시키기 쉽지 않은 환경이었음.
- 5~6년 전부터 클라우드 빅데이터 플랫폼을 구축하게 되면서 인공지능 기술들이 엄청 발전하게 되었음.
클라우드라는 플랫폼은 거의 무한에 가깝게 데이터를 확장할 수 있고, 컴퓨팅 파워도 필요시 빌려쓸 수 있다. 최근 몇 년동안 인공지능 기술이 급격하게 발전하게 되었다.
- 인공지능 : 사람처럼 생각하고 문제를 해결함.
- 머신러닝 : 데이터를 통해 스스로 학습. 예측이나 판단을 제공한다.
- 딥러닝 : 뉴럴 네트워크. 인공신경망 알고리즘을 활용하는 머신러닝 기술.
인공지능의 활용
- 알파고 vs 이세돌의 대국
- 생명공학분야의 활용 : AI로 단백질 비밀 해석, 구글 딥마인드, 알파폴드 2로 단백질 폴딩(접힘을) 예측해 단백질 구조를 파악했다.
- 범죄 예방 : AI 안면인식 기술.
- 공간 분석 : 주차장, 특정 공간 등을 인식하여 데이터 제공.
- 딥 페이크
기계 학습(Machine Learning)
- 인간의 능력 중 학습능력을 컴퓨터로 구현.
- 데이터를 제공하면 기계가 인사이트를 제공한다.
- 머신이 경험을 통해 작업을 개선할 수 있도록 하는 기술을 사용하는 AI의 하위 집합.
- 알고리즘에 데이터 피드 (기능 추출을 수행하는 등의 방법으로 모델에 추가 정보 제공할 수 있다.)
- 데이터를 사용해서 모델을 학습시킴
- 모델 테스트 후 배포
- 배포된 모델을 사용, 자동화된 예측 작업 수행 (배포된 모델을 호출 및 사용하여 모델에서 반환된 예측을 받음)
딥러닝 (Deep Learning)
- 인공신경망을 토대로 학습방식을 구현하는 기술
- 인공신경망 구조는 여러 입력, 출력 및 숨겨진 레이어로 구성되기 때문에 학습 프로세스가 깊어짐.
- 각 레이어에는 입력 데이터를 다음 레어이가 특정 예측 작업에 사용할 수 있는 정보로 변환하는 장치가 포함됨.
- 이 구조 덕분에 머신은 자체 데이터 처리를 통해 학습을 할 수 있음.
머신러닝 vs 딥러닝
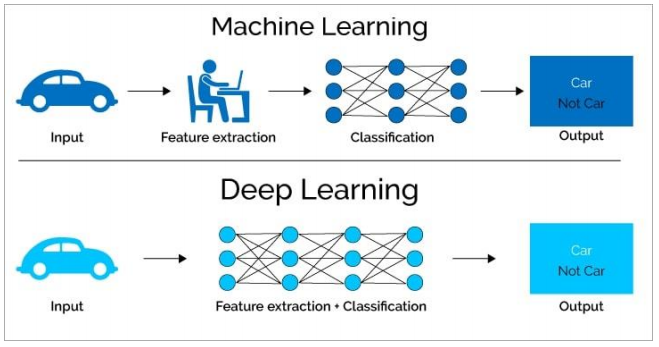
- 머신러닝
- 결과를 미리 알려줌
- 사람이 특징을 정의하여 입력하는 단계 필요
- 딥러닝
인공지능이란?
- 인간의 인지능력, 학습능력, 추론능력을 컴퓨터로 구현하는 모든 연구 분야.
기계 학습이 포함된다.
- 자율주행, 스마트 스피커, 챗봇, 인공지능 로봇, 이미지 인식, 개인화 추천, 기계 번역
데이터 레이크(Lake) vs 데이터 메쉬(Mesh)
데이터 웨어하우스
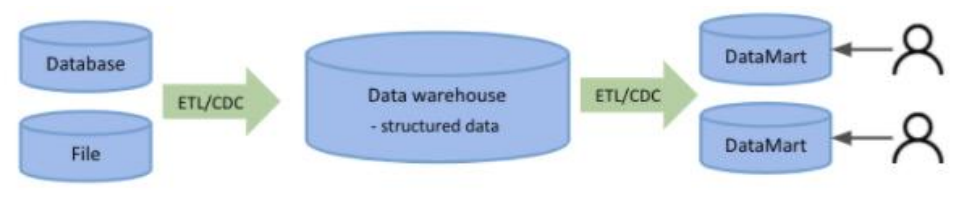
- 전통적인 데이터 저장방식. RDBMS 정형화된 데이터를 활용해서 데이터 웨어하우스에 쌓고, 데이터 마트에 전송.
데이터 웨어하우스는 물류창고, 데이터 마트는 도/소매 상점.
- 과거에는 데이터라고 하면 정형화된 데이터로 많이 표현했다.
데이터 레이크
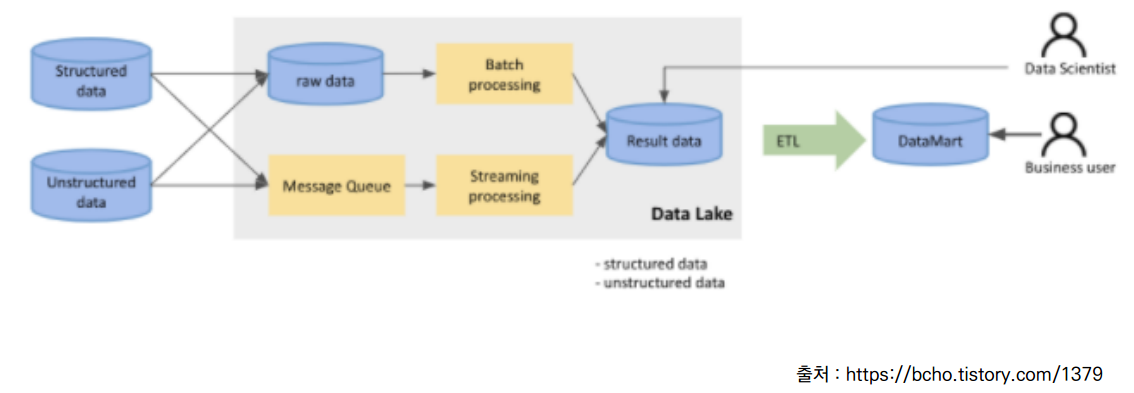
- 최근의 데이터 저장 형태.
온갖 데이터 형태들(구조화 되었든지, 그렇지 않든지)을 row data를 쌓거나 특정 포맷의 메시지 형태로 변경을 해서 실시간으로 데이터 저장소에 저장하게 됨.
비구조화 데이터도 처리를 거쳐서 정형화되고 분류된 데이터 형태로 재처리됨.
- 데이터 레이크는 데이터를 수집하고, 수집한 데이터를 처리하며, 그 데이터를 쌓게 된다.
- 이후 이 데이터를 직접 사용하거나 데이터 마트에 두기도 함.
데이터 메쉬
- 데이터 레이크의 문제점 : 모든 데이터가 중앙에, 한 곳에서 모이게 된다.
- 데이터 용량이 많고, 분류가 어려우며, 분석 역시 쉽지 않아진다. → 데이터를 한곳에 모으는 것이 항상 좋지만은 않다.
- 데이터 저장소의 볼륨이 매우 커지게 된다. 불필요한 데이터도 모아지고 필요로 하지 않은 데이터도 쌓이게 된다.
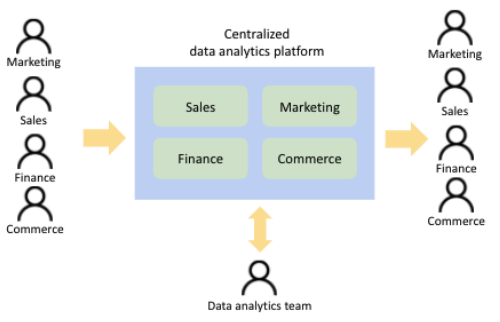
- 데이터 메쉬는 모노리틱 구조(단일 구조)라고 한다. 데이터는 각기 따로 저장되지만, 분석하는 것은 한 플랫폼으로 사용된다.
데이터는 각 비즈니스 별로 따로 묶이게 되고, 분석 플랫폼만 같이 사용.

- 업무 도메인 별로 데이터 저장과 분석을 따로 하는 경우.
데이터 분석 전문가들이 더 전문성을 갖을 수 있음.
- 분석에 많은 분야의 데이터가 필요하다면 단점이 될 수도 있다.
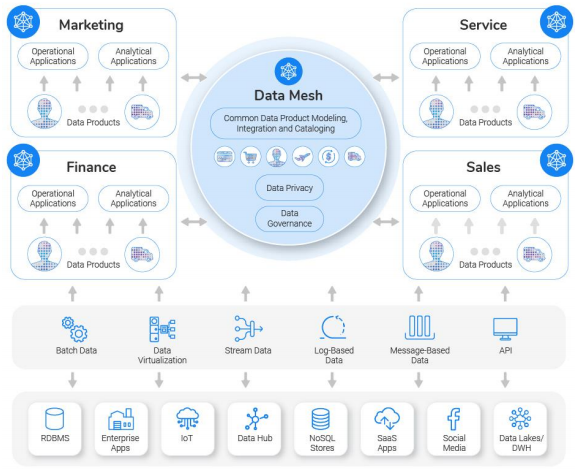

클라우드 데이터 기술
- 머신 러닝 서비스를 활용하기 위한 3가지 스택은 AI 서비스, ML서비스, ML인프라 및 프레임워크 제공 서비스를 활용할 수 있으며 기업 데이터의 형태 및 요구에 따라 변경 적용이 가능함.
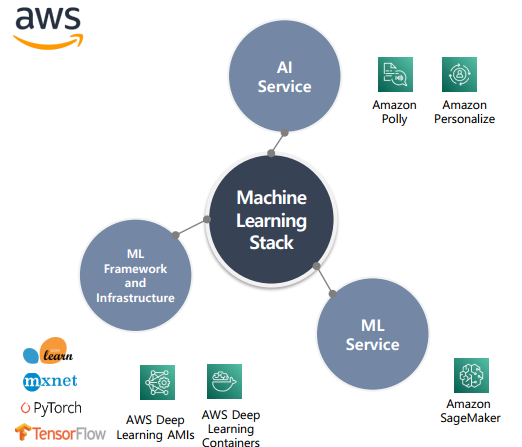
- 클라우드의 장점인 PaaS, SaaS등을 활용하면 금방 머신러닝 환경을 갖출 수 있다.
- AI 서비스
- API를 활용, ML 기능을 워크로드에 빠르게 추가할 수 있는 완전 관리형 서비스
- SaaS형태의 API, Compute vision, speech, natural language 등의 기능을 활용할 수 있음
- 사전 학습된 ML 모델을 활용하기에, 별도 ML 지식 필요 없음
- ML 서비스
- 개발자, 데이터 과학자 및 연구원에게 기계학습을 위한 관리형(PaaS)형 서비스 및 리소스 제공
- 데이터의 레이블, 모델을 구축, 교육, 배포 및 운영 가능.
- ML Framework and Infrastructure
- ML 전문가가 프레임워크와 인프라를 활용하여 모델을 구축, 교육, 조정 및 배포함.
데이터 관련 신기술
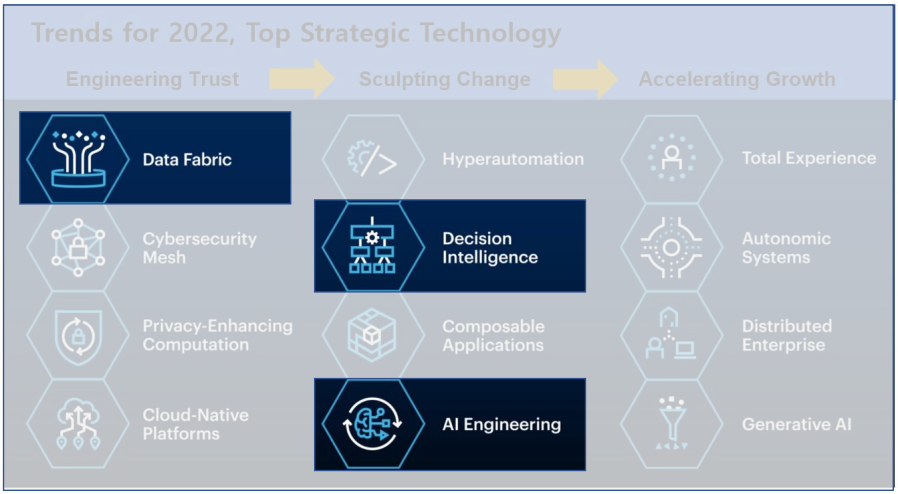
- 가트너에서 발표한 신기술 동향.
- 신뢰 강화 : 안전하게 데이터가 통합되고 처리되도록 함으로 보다 탄력적이고 효율적인 IT 토대 구축, IT 토대의 비용 효율적인 확장을 가능케 함.
- 변화 추진 : 빨라지는 변화 속도에 대응하여 비즈니스 활동을 자동화, 인공지는 최적화, 보다 빠르고 현명한 의사결정
- 성장가속화 : IT 전력 증강 요소를 활용할 수 있음. 가치 창출을 극대화하고 디지털 역량을 강화함.
- 데이터 분석은 전 산업에 걸쳐 필수불가결한 요소이며, 대부분 기업들이 Data Lake 구축을 위한 노력을 하고 있음.
- 데이터 활용 수요 증가
- 데이터 기술 발전
- 데이터를 의사결정에 활용
AI in Cloud Computing
- AI는 많은 데이터와 강력한 컴퓨팅 파워가 필요하고, 이것을 가장 잘 구현할 수 있는 것은 클라우드.
AI 활용의 7가지 패턴
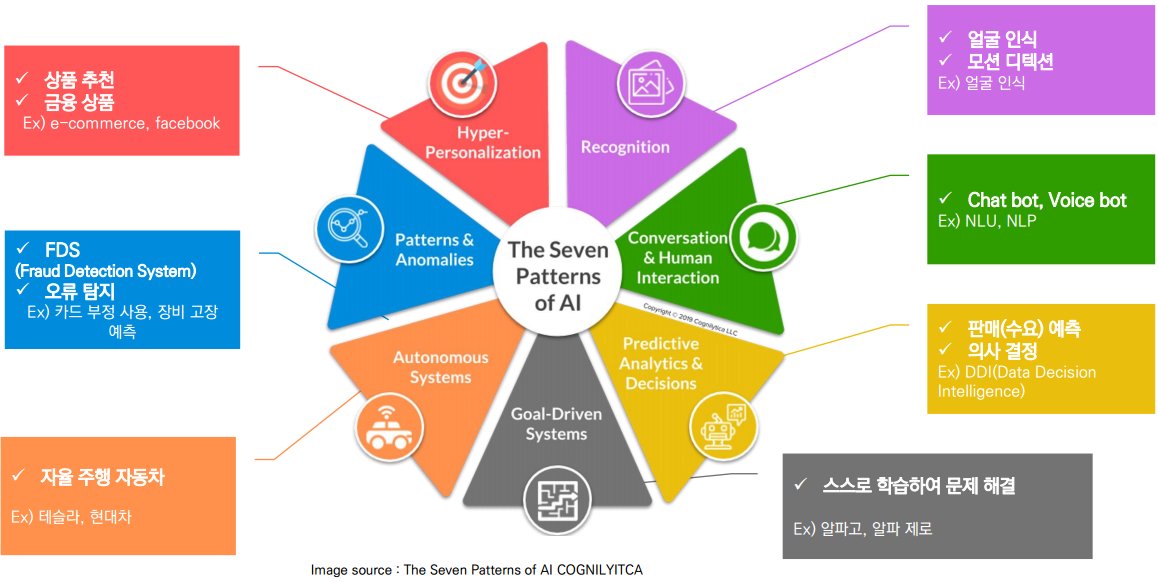
- Hyper-Personalization : 초 개인화. 상품 추천, 금융상품 추천.
- Patterns & Anomalies : 이상방지. 패턴을 분석해서 개인의 행동 예측
- Autonomous Systems : 자율 시스템. 자율 판단이 중요함.
- Recognition : 인식기술. 얼굴, 공간 인식. 모션 디텍션.
- Conversation & Human Interaction : 소통과 인간과의 교류.
NLU : 자연어 이해
- Predictive Analytics & Decisions : 예측 시스템.
- Goal-Driven Systems : 목표 달성을 위해 스스로 학습.
- 데이터를 어떻게 수집하고 저장, 가공, 분석하느냐에 따라 기업 경쟁력이 좌우될 수 있음. 데이터는 4차 산업에서의 원유.

- 학습데이터 : 로우데이터를 다양한 형태의 필터로 정제.
Data 직무 소개
- RDBMS 기술과 데이터 레이크를 구축하는 클라우드 PaaS 및 Open source sw에 대한 역량 준비 필요
