"Palying Atari with Deep Reinforcement Learning"은 아타리 게임에서의 심층 강화학습을 적용한 논문이다.
- 해당 내용은 AI관련 논문에 대해서 학습을 하면서 요약해 서술한 내용입니다. 따라서 틀린 부분이나 수정할 부분에 대한 무한 피드백은 언제나 감사합니다.
기본개념
강화학습이란?
Agent가 보상을 최대화하는 최적의 행동을 스스로 찾는 것을 목표로 한다.
- Agent: 학습의 주체
- Environment: Agent가 움직이며 상호작용하는 공간(해당 논문에서는 Atari게임)
- State(S): 현재 Agent의 위치 또는 상황
- Action(A): Agent가 취할 수 있는 행동
- Reward(R): 행동의 결과로 주어지는 점수
Q-learning
강화학습의 알고리즘 중 하나로 에이전트가 최적의 행동을 학습하는 방법
Q-learning은 에이전트가 행동할 때마다 Q value를 업데이트하며 최적의 경로를 찾는다.
- Q-value?
- Q value는 특정 상태에서 특정 행동을 했을 때, 기대되는 보상 값을 의미- 에이전트는 학습을 반복하며 Q값을 점점 더 정확하게 업데이트하여 최적의 행동을 선택
- 동작원리(Q-Table)
- 상태, 행동 쌍에 대한 Q값을 지정하는 표를 만듦(like Game Theory)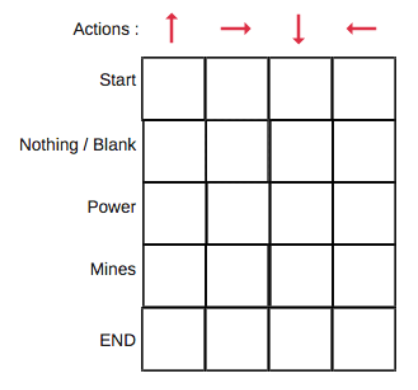
출처: 위키독스- 따라서 에이전트는 학습을 반복하면서, Q값을 점점 더 정확하게 업데이트하여 최적의 행동을 선택
- Q(s,a)←Q(s,a)+α(r+γ maxQ(s ′ ,a ′ )−Q(s,a))
- Q(s, a): 현재 상태 s에서 행동 a를 했을때의 기존의 Q값
- r: 행동을 수행한 후 받은 보상
- maxQ(s’, a’): 다음 상태 s’에서 가능한 최대 Q값
- α (learning rate): Q값을 업데이트 하는 비율(0~1)
- γ (discount rate): 미래 보상을 얼마나 중요하게 생각할지 결정(0~1)
1. 서론
-
강화 학습(RL)에서 고차원 감각 입력(예: 이미지, 음성)으로부터 직접 에이전트를 제어하는 것은 오랜 과제
-
기존 RL 방법들은 수작업으로 설계된 특징(feature)과 선형 가치 함수(value function) 또는 정책(policy) 표현에 의존
-
최근 딥러닝의 발전으로 인해 원본 감각 데이터(raw sensory data)에서 고수준 특징(high-level feature)을 추출하는 것이 가능
-
합성곱 신경망(convolutional networks), 다층 퍼셉트론(multilayer perceptrons), 제한된 볼츠만 머신(restricted Boltzmann machines), 순환 신경망(recurrent neural networks) 등의 다양한 신경망 아키텍처를 활용하며, 지도 학습(supervised learning)과 비지도 학습(unsupervised learning) 모두를 적용
Restricted Boltzmann machines?
제한된 볼츠만 머신은 데이터를 더 낮은 차원으로 변환하거나 숨겨진 구조를 학습하는데 사용된다. 볼츠만 머신과 달리 제한이 추가된 구조로 '제한'으로 인해 학습이 더 쉬워지고 효율적으로 동작
- 핵심특징
- 입력과 은닉층 간의 연결은 존재하지만, 은닉층 뉴런들 간에는 연결이 없음
- 자기 지도 학습 방식을 사용하여 특징을 추출, 추천 시스템 등에서 활용 多
하지만, Reinforcement Learning(RL)은 기존의 딥러닝과 다른 몇 가지 어려움이 존재
1. 대부분의 딥러닝 기법은 대량의 레이블링된 데이터를 필요로 하지만, RL은 희소하고 지연된(sparse & delayed) 보상 신호를 통해 학습해야 한다.
2. RL에서는 데이터 샘플 간의 상관관계가 높고 학습하면서 데이터 분포가 변하는 문제가 존재
- 해당 논문에서는 Q-러닝(Q-learning) 기반의 심층 신경망(Deep Q-Network, DQN)을 적용하여, 원시 픽셀 입력으로부터 학습 가능한 RL 모델을 제안
- Q 러닝은 RL에서 널리 사용되는 오프폴리시(Off-policy) 학습 방법으로, 최적 정책을 근사하기 위해 가치 함수(보상의 기대값)를 사용
- 원시 픽셀 데이터(이미지)를 직접 학습하는 것은 기존에 사용되던 수작업 특징 엔지니어링(feature engineering) 기법을 대체하는 방법On Policy & Off Policy?
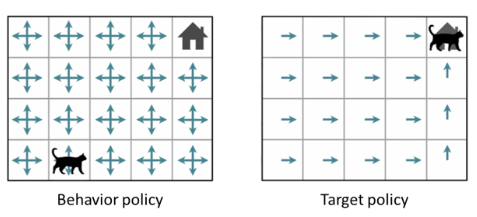
on policy: Behavior policy Target policy
off policy: Behavior policy Target policy - Behavior policy: action을 선택하고 데이터 샘플을 얻을 때 사용되는 정책
- Target policy: 평가하고 업데이트를 하고자 하는 정책
2. 배경
RL 목표: 행동을 선택하여 미래 보상의 기대값을 최대화하는 최적 정책을 학습하는 것.
논문에서는 RL 문제를 마르코프 결정 과정(MDP, Markov Decision Process) 으로 정의하고, 최적의 행동-가치 함수(Q*)를 찾기 위해 벨만 방정식(Bellman Equation)을 사용
3. 관련연구(생략)
4. DQN(심층 강화학습)
제안된 Deep Q-Network (DQN) 은 CNN(합성곱 신경망, Convolutional Neural Network)을 사용하여 고차원 픽셀 데이터를 처리하고, 경험 재현을 활용하여 학습을 안정화하는 방식
4.1 Q-learning과 심층신경망의 결합
강화학습에서 Q-learning은 대표적인 가치기반학습법으로 벨만의 방정식을 이용하여 최적의 행동-가치 함수를 학습
하지만 기존 Q-러닝 방식에는 몇 가지 문제가 존재
- 고차원 입력 데이터(예: 이미지, 비디오)를 직접 학습하기 어려움
- 테이블 기반 Q-러닝 방식은 상태 공간이 클 경우 확장성이 떨어짐
- 강한 데이터 상관관계로 인한 학습 불안정성
이를 해결하기 위해 DQN은 CNN을 사용하여 상태 값을 자동으로 특징(feature) 추출하는 방식을 도입하고 CNN은 원시 픽셀 데이터를 입력으로 받아 유의미한 상태 표현을 학습
4.2 DQN 주요기법
1. 경험재현
강화 학습에서는 현재 행동이 다음 상태에 영향을 미치므로, 데이터 샘플들이 높은 상관관계(correlation)를 가지게 됨.
이로 인해 학습이 불안정해지고, 네트워크가 특정 패턴에 과적합(overfitting)될 위험
이를 방지하기 위해 DQN은 에이전트의 경험을 저장하고 무작위로 샘플링하여 학습하는 경험 재현 기법을 사용
📌 경험 재현의 핵심 원리
- 에이전트의 경험을 저장하는 메모리 버퍼 𝐷를 유지하고 메모리에서 무작위로 샘플링하여 학습 데이터를 구성
- 이를 통해 상관관계를 낮추고 학습의 안정성을 높임
2. Target Network
Q-learning의 Loss Function
Q-값을 예측하는 신경망(가중치 𝜃)과 목표값을 계산하는 신경망이 동일하기 때문에 학습이 불안정해질 수 있음
학습 과정에서 Q값이 급격히 변화하면 발산(divergence)하는 문제가 발생 가능
이를 해결하기 위해 DQN은 타겟 네트워크()를 별도로 유지하여 안정적인 학습을 수행
3. Architecture
입력: 84×84×4크기의 흑백 영상 (마지막 4개의 프레임을 스택)
첫 번째 합성곱 층: 16개의 8×8 필터, 스트라이드 4
두 번째 합성곱 층: 32개의 4×4 필터, 스트라이드 2
완전 연결층: 256개의 뉴런, ReLU 활성화 함수 사용
출력층: 각 행동(action)에 대한 Q-값을 출력

5. Experiment
1. 학습 안정성
훈련과정에서 평균보상값과 예측된 Q값을 분석하여 학습 안정성을 검토하고 경험 재현 덕분에 학습이 안정적으로 진행됨을 확인
2. 가치함수 시각화
게임 'Seaquest'에서 학습된 Q값을 분석하여, 적 등장 → 공격 → 적 제거 등의 패턴을 학습하는 것을 확인
3. 평가 및 성능비교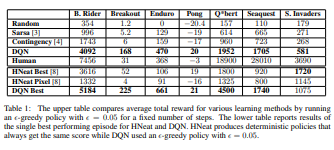
기존 선형 근사 기법보다 뛰어난 성능을 보였으며, 일부 게임에서는 인간 전문가보다 높은 성능을 기록
6. 결론
- 논문은 딥러닝과 강화 학습을 결합한 DQN 모델이 Atari 게임에서 높은 성능을 발휘함
- 기존 RL 방법과 달리 원시 픽셀 데이터만으로 학습 가능하며, 특정 게임에 특화된 특징을 설계할 필요가 없음
코드구현
https://github.com/rlaxodns/Implementation-of-thesis-code/blob/main/dqn.py
