AI논문분석 및 구현
1.[논문]Playing Atari with Deep Reinforcement Learning(DQN)
"Palying Atari with Deep Reinforcement Learning"은 아타리 게임에서의 심층 강화학습을 적용한 논문이다.해당 내용은 AI관련 논문에 대해서 학습을 하면서 요약해 서술한 내용입니다. 따라서 틀린 부분이나 수정할 부분에 대한 무한 피드백
2.[논문]The effect of batch size on the generalizability of the convolutional neural networks on a histopathology dataset(CNN에서 Batch size & Learning rate가 학습에 미치는 영향)
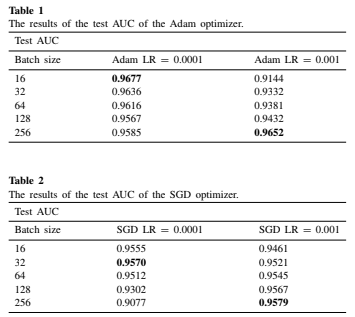
Batch size가 학습에 미치는 영향에 대해서 경험칙으로 1. Batch_Size가 클 경우 학습속도를 높일 수 있지만, 과소적합의 문제가 있다거나 2. 또는 작을 경우 학습속도는 느리지만, 과적합의 영향을 받을 수 있다고 판단해왔다. 이에 대해서 전문적인 내용을
3.[논문] Attention All You Need (Transformer)
현재 Transformer 모델은 Bert, GPT의 기본적인 Architecture로 활용되고 있으며, 대용량 데이터를 한번에 처리할 수 있는 강점을 가졌습니다. 시계열 분야에 국한되지 않고, Computer Vision분야에서도 SOTA를 차지하고 있는 모델의 대부
4.[논문]Vision Transformers
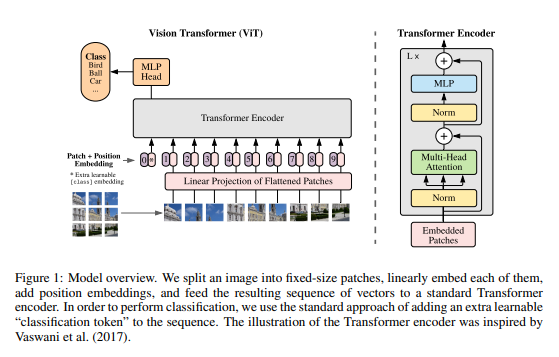
Transformers모델의 등장으로 자연어 처리 모델의 성능이 기하급수적으로 증가하였습니다. 이러한 Transformer모델의 성능을 컴퓨터 비젼 분야에도 적용할 수 있다면, 뛰어난 성능을 보일 것이라고 생각했기 때문에 Transformer모델을 컴퓨터 비젼분야에 적
5.[논문]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
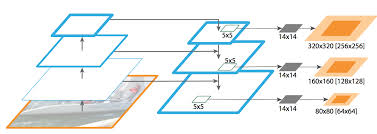
이미지 분류 작업에서 SOTA를 달성했던 ViT모델의 고유한 한계로 인해 Detection, Segmentation등과 같은 복잡한 작업에서 활용되지 못하는 문제를 해결하기 위해 Self-Attention메커니즘을 BackBone으로 활용하기 위해 등장한 모델이 Swi
6.[논문] ConvNext: A ConvNet for the 2020s
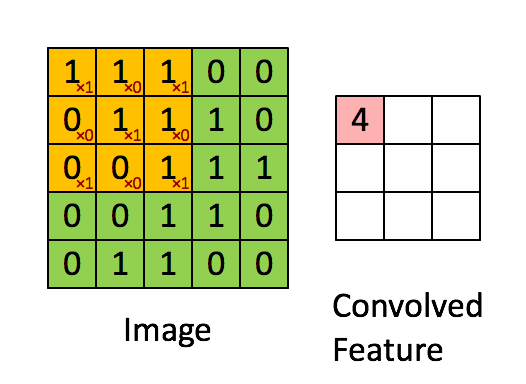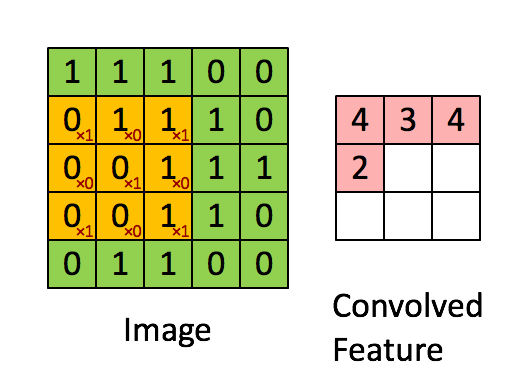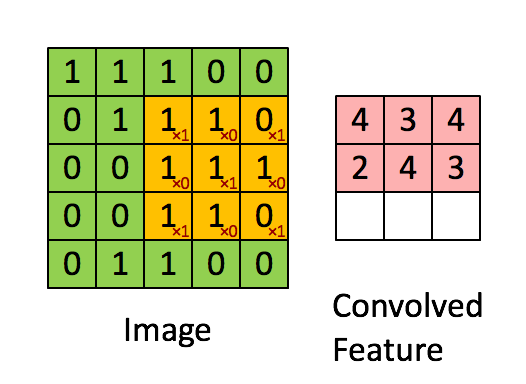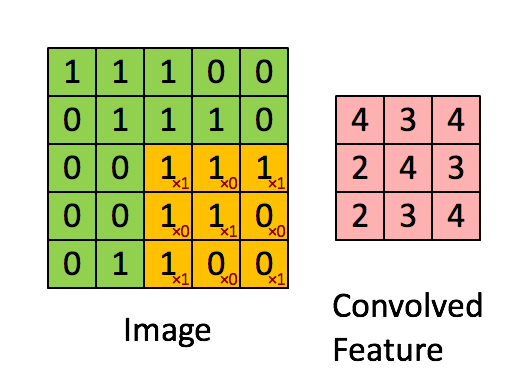
ViT모델의 등장과 함께 SOTA모델을 차지하게 되었습니다. 그러면서 주로 ViT모델과 비교되는 CNN모델은 ResNet 모델인데 해당 모델이 오래되었고, 이러한 모델을 최신화하여 성능을 끌어올릴 수 있다면 얼마나 더 좋은 성능을 낼 수 있을지에 대한 의문과 함께 연구