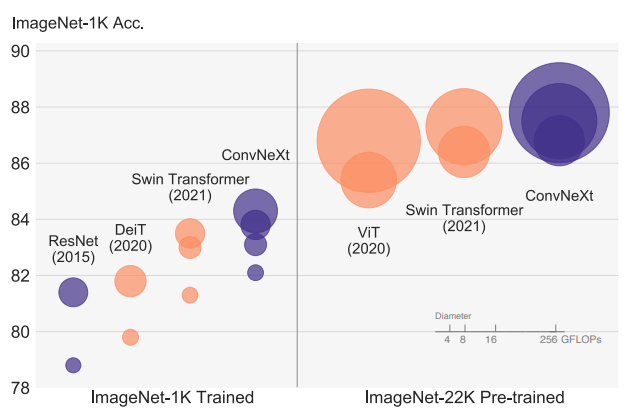
ViT모델의 등장과 함께 SOTA모델을 차지하게 되었습니다. 그러면서 주로 ViT모델과 비교되는 CNN모델은 ResNet 모델인데 해당 모델이 오래되었고, 이러한 모델을 최신화하여 성능을 끌어올릴 수 있다면 얼마나 더 좋은 성능을 낼 수 있을지에 대한 의문과 함께 연구가 시작되었다고 합니다.
Swin Transformer의 모델 구조를 차용하여서 CNN모델의 학습 성능을 향상 시켰고 Swin Transformer의 성능을 따라잡은 것을 확인할 수 있습니다.
1. 배경
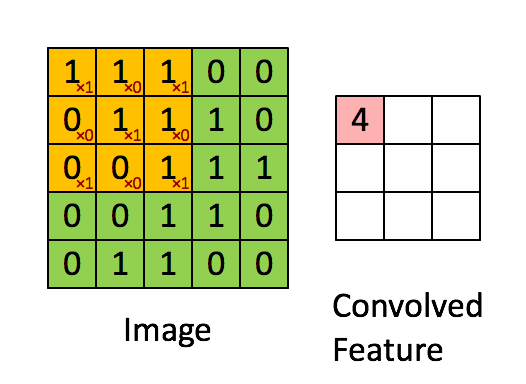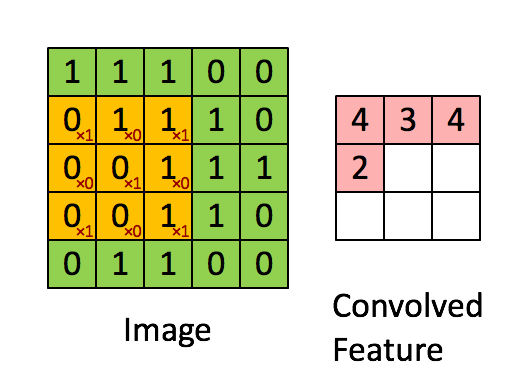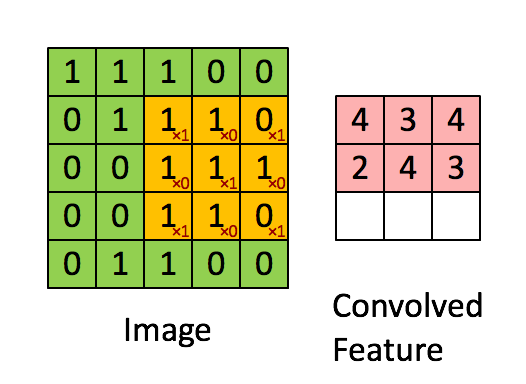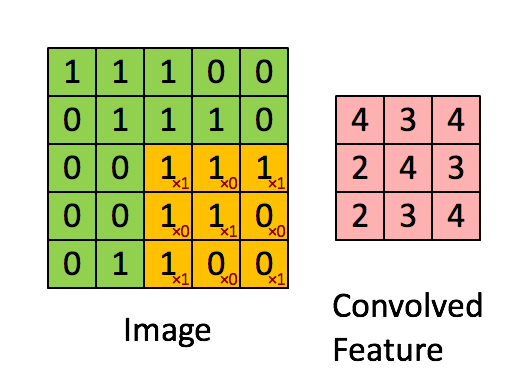
ConvNext모델은 기본적으로 CNN모델에 ViT의 아이디어를 적용한 모델이다. CNN연산은 다음과 같다.
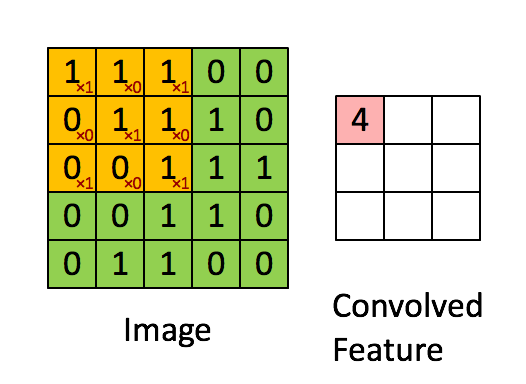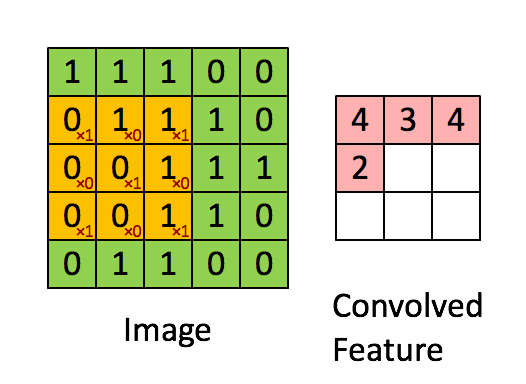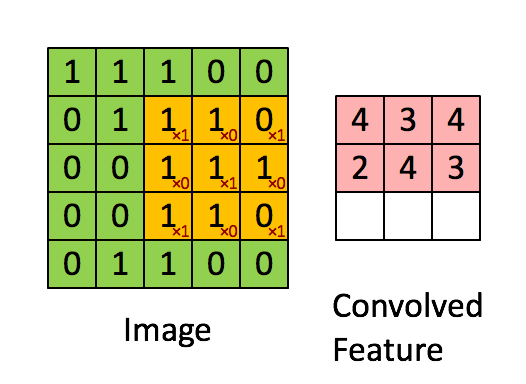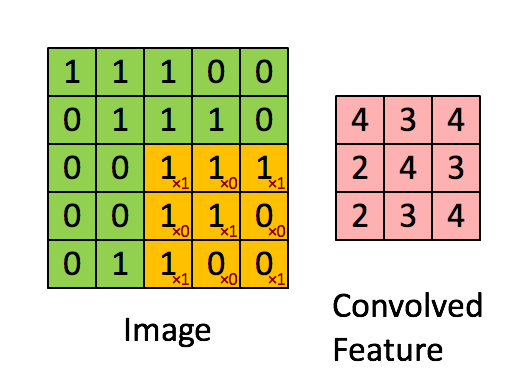
다음과 같이 입력 이미지의 3*3의 kernel_size의 필터를 통과하여 Feature map을 생성하게 된다. 이러한 특징 맵을 통해서 이미지의 특징을 추출하고 이를 Fully Connected Layer에 전달하여 Sigmoid 또는 Softmax함수를 통해서 어떤 이미지인지를 분류 작업 등을 수행할 수 있게 해준다.
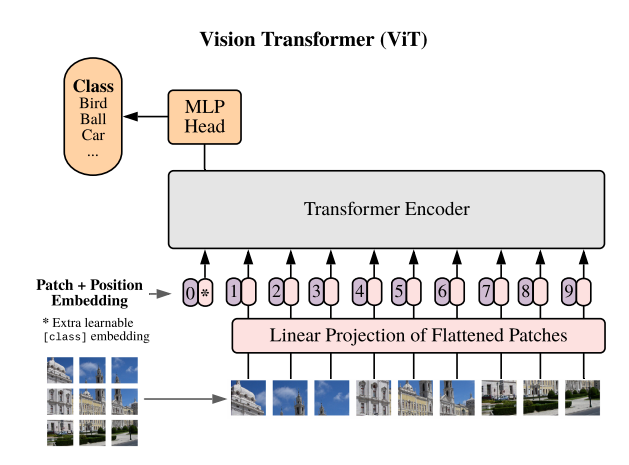
하지만, vision transformer 모델은 CNN의 모델과 달리 행렬곱 연산을 진행하지 않고 이미지를 Patch단위로 나누어서 이를 Patch & Position Embedding 해주어 Self-Attention 연산을 해준다. 이러한 어텐션 연산을 통해서 대용량의 이미지를 효율적으로 처리할 수 있는 모델을 만들어 낼 수 있게 되었다.
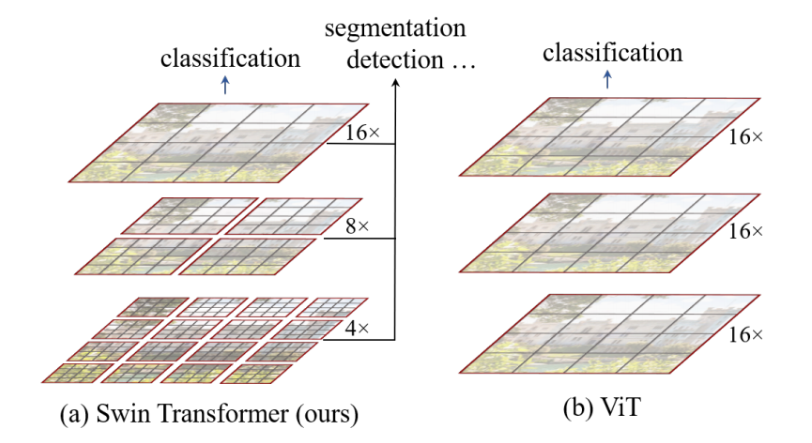
[Swin] Hierachical Architechure
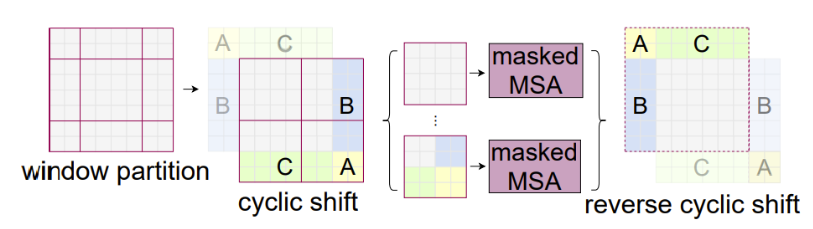
[Swin] Cyclic Shift
하지만, ViT모델도 한계점은 존재한다. 각 패치로 나누어 학습을 진행하기 때문에 이미지의 다양한 해상도 및 이미지 내의 다양한 크기의 객체에 대해서 학습하지 못하기 때문에 이미지 분류 작업 외에는 객체탐지, 객체분할과 같은 컴퓨터 비젼의 복잡한 작업을 수행하지 못하는 한계가 있었다. 이러한 점을 해결하기 위해서 [Swin] Hierachical Architechure을 통해서 이미지를 다양한 크기의 패치로 분할하고 이를 Local window 기법을 적용하여 묶어주는 작업을 통해서 다양한 크기의 이미지를 학습하지만 연산량을 크게 늘리지 않는 효율적인 방법을 채택하면서 복잡한 작업을 수행할 수 있게 해주었다.
이러한 기법의 핵심은 Shifted Window 기법으로 기존의 4분할 되었던 윈도우를 주대각 방향으로 이동하여 연결되지 않았던 패치들을 학습할 수 있게 해준다. 이를 통해서 다양한 부분의 학습을 진행하면서 ViT에서 보이던 약한 inductive bias문제를 해결할 수 있게 해주었다. 해당 이제 cyclic shift에서 Masked MSA를 진행하는 이유는 기존의 학습되었던 내용을 다시 학습을 제한하여서 연산이 늘어나는 것을 막아주고 또, NLP작업에서 Transformer모델에서 Masked MSA 작업과 유사하게 해당 이미지를 mask처리하여 학습을 제대로 할 수 있도록 학습 효용성을 증가시킨다.
2. ConvNext
2.1 AdamW
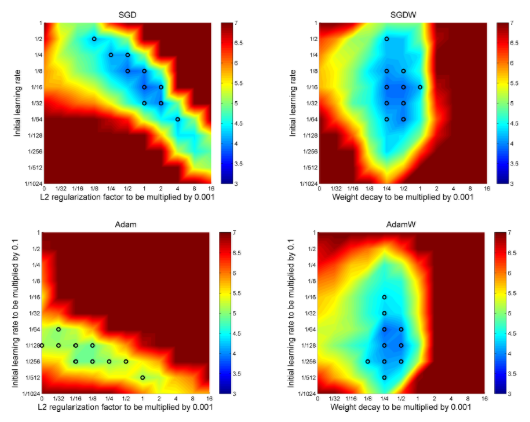
ConvNext모델에서는 AdamW 옵티마이저가 사용된 것을 확인할 수 있다. AdamW는 기존의 Adam 옵티마이저에 Weight Decay감소를 정규화 방식을 추가한 기법이다.
Weight Decay란?
- Weight Decay란, 가중치 폭발(Weight Explosion)을 방지하기 위해 가중치를 감소시키는 기법이다. 정규화 방법과 정규화 방식 등 여러 방법이 존재한다. 이러한 가중치 폭발이 생기는 이유와 이를 억제하는 이유는 데이터에 이상치가 존재할 경우 가중치는 이상치로 인해서 값이 너무 커지게 되고 과적합이 발생하는 문제가 발생하게 된다. 이러한 문제를 해결하기 위해서 가중치 값을 감소 시키는 것을 Weight Decay라 한다.
AdamW 옵티마이저가 SGD, Adam에 비해서 오차 값에 제대로 집중하는 것을 확인할 수 있다.
2.2 변화
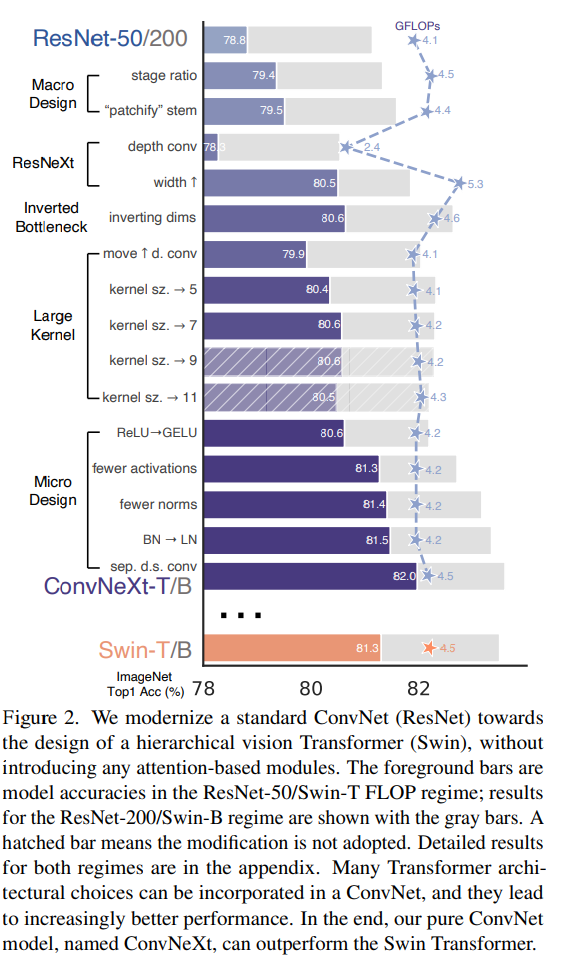
(1) Macro Design
- macro design에서 stage ratio에 괄목할만 하다. 기존의 ResNet-50모델의 stage구성인 3, 4, 6, 3의 비율에서 Swin-T모델을 차용하여서 1:1:3:1의 비율로 stage ratio를 구성하였다. 이러한 비율을 통해서 1% 성능을 향상시킬 수 있었다.

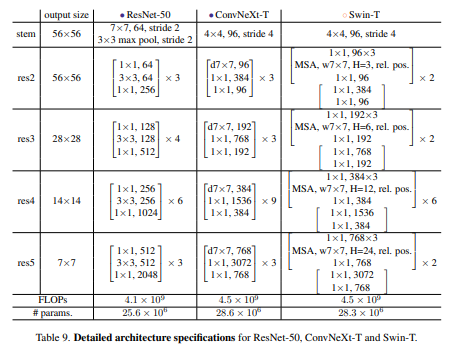
- Patchify Stem: 기존의 이미지를 다운 샘플링하는 과정에서 77에 stride2를 커지면서 이미지를 4배 줄일 수 있게 된다. Swin Transformer에서도 patch merging과정을 통해서 이미지를 다운샘플링을 진행하는데, 이를 기존의 ResNet의 77에 stride2와 달리 4*4에 stride 4를 주면서 Patchify Stem을 적용
(2) ResNeXt
- depth conv:
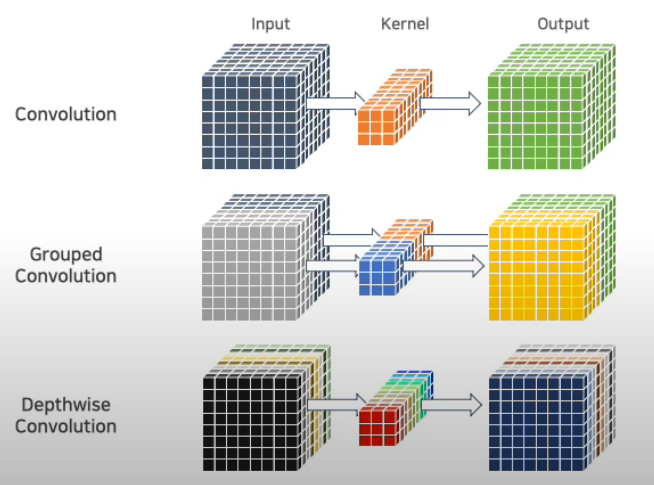
- 일반적인 Conv 연산
연산량 =
H = 넓이
W = 높이
= 입력 채널
= 커널 사이즈
= 출력 채널 - Grouped Conv 연산
연산량 =
그룹의 크기가 커질수록 연산량이 감소 - Depth-wise Separable Conv는 그룹 컨볼루션의 연장선
각각의 채널에 따라서 묶어서 연산을 진행하고 출력 시, Pointwise Conv를 진행하여 채널 간의 결합을 수행하여 각각의 채널 정보를 결합하여 최종 출력
입력 연산량 =
출력 연산량 =
최종연산량 =
- 일반적인 Conv 연산
(3) Inverted Bottleneck
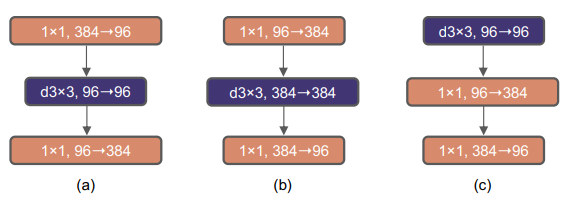
- 기존의 컨볼루션 네트워크 구성 시, 넓게 -> 좁게 ->넓게 형태를 많이 구성하였다. 왜냐하면 연산량을 늘리고 이후 연산량을 1*1 커널을 통해서 줄이는 방식으로 진행하였으나, MobileNet에서 제안된 역 병목구조를 활용하여 연산량이 적은 Depthwise Convolution을 사용하여 정보 학습을 수행
(4) Micro Design
-
ReLU에서 GELU로 대체
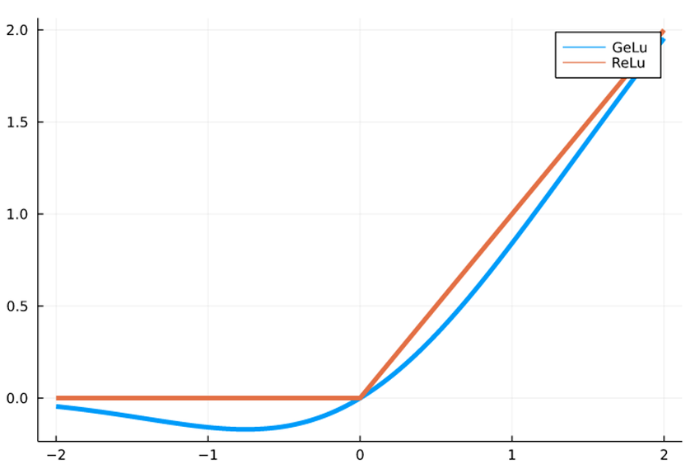
기존의 활성화 함수를 렐루에서 겔루로 변경하면서 더 자연스러운 부드러운 비선형성을 제공하게 된다. ReLU는 갑자기 0이 되는 부분(비선형성이 뚜렷한 점)이 존재하지만, GELU는 부드러운 비선형 함수이다. 이를 통해서 Gradient의 흐름이 원활하여 학습이 안정적으로 진행될 수 있게 해준다. -
활성화 함수와 Norm의 사용을 제한
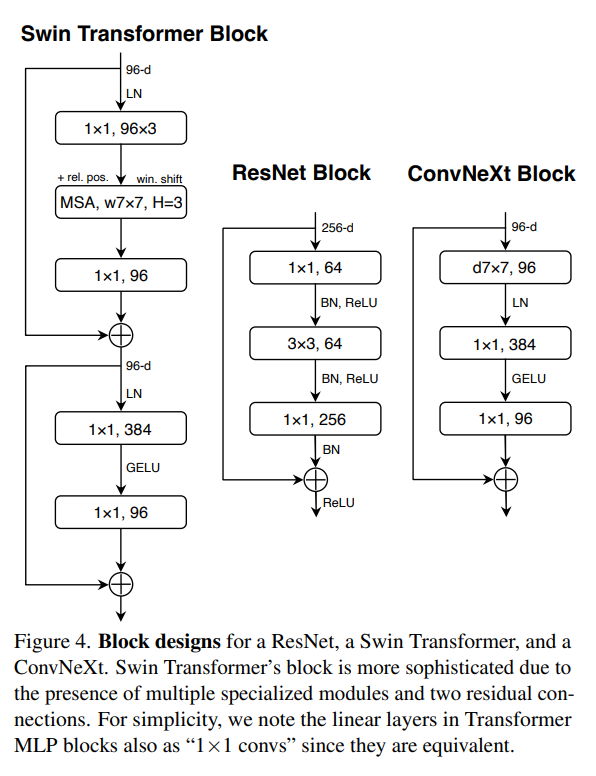
swin transformer나 resnet에서는 지속적으로 활성화 함수와 Normalization을 레이어 통과시에 반복적으로 사용하는 것을 확인할 수 있으나, ConvNext에서는 레이어 통과시에 각 한 번씩만 활용하는 방법을 사용하였음에도 성능 향상을 확인할 수 있었다. 또한, 일반적인 경우에 CNN에서는 주로 BatchNorm을 활용하였지만 LayerNorm을 활용하는 것을 확인할 수 있다. -
Patch merging을 차용하여 stage반복마다 다운샘플링을 진행
실험

다양한 버전이 존재
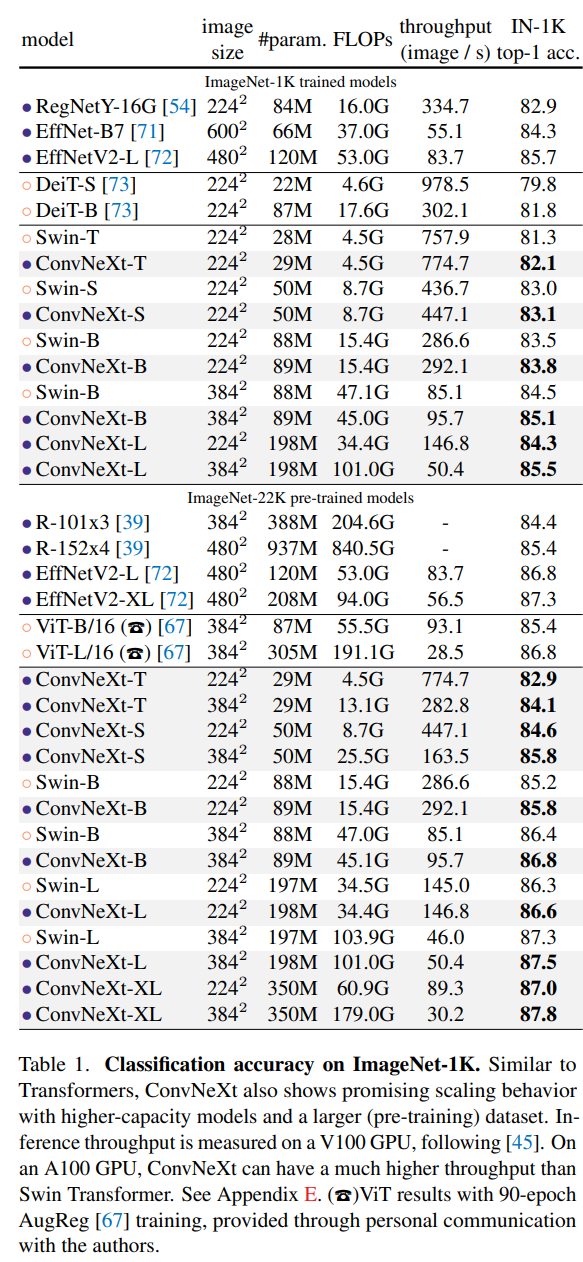
여러 성능 비교 상에서 비슷하거나 더 뛰어난 성능을 보여주는 것을 확인할 수 있다.
import torch
import torch.nn as nn
class ConvNeXtBlockBase(nn.Module):
def __init__(self, dim, conv_layer, drop_path=0., layer_scale_init_value=1e-6):
super().__init__()
self.dwconv = conv_layer(dim, dim, kernel_size=7, padding=3, groups=dim)
self.norm = nn.GroupNorm(num_groups=1, num_channels=dim)
self.pwconv1 = nn.Linear(dim, 4 * dim)
self.act = nn.GELU()
self.pwconv2 = nn.Linear(4 * dim, dim)
self.gamma = nn.Parameter(layer_scale_init_value * torch.ones((dim,)), requires_grad=True) \
if layer_scale_init_value > 0 else None
self.drop_path = nn.Identity()
def forward(self, x):
shortcut = x
x = self.dwconv(x)
x = self.norm(x)
# (B, C, D, H, W) -> (B, D, H, W, C) 형식으로 변환
x = x.permute(0, *range(2, x.ndim), 1)
x = self.pwconv1(x)
x = self.act(x)
x = self.pwconv2(x)
if self.gamma is not None:
x = self.gamma * x
# 다시 (B, C, D, H, W) 로 복귀
x = x.permute(0, -1, *range(1, x.ndim - 1))
x = shortcut + self.drop_path(x)
return x
class ConvNeXtBase(nn.Module):
def __init__(self, in_chans, num_classes, depths, dims, conv_layer, pool_layer):
super().__init__()
self.downsample_layers = nn.ModuleList()
stem = nn.Sequential(
conv_layer(in_chans, dims[0], kernel_size=4, stride=4),
nn.GroupNorm(num_groups=1, num_channels=dims[0])
)
self.downsample_layers.append(stem)
# 4개의 stage 중 나머지 3개의 downsample layer
for i in range(3):
downsample_layer = nn.Sequential(
nn.GroupNorm(num_groups=1, num_channels=dims[i]),
conv_layer(dims[i], dims[i + 1], kernel_size=2, stride=2),
)
self.downsample_layers.append(downsample_layer)
# 4개 stage
self.stages = nn.ModuleList()
for i in range(4):
stage = nn.Sequential(
*[ConvNeXtBlockBase(dim=dims[i], conv_layer=conv_layer) for _ in range(depths[i])]
)
self.stages.append(stage)
# 마지막 계층
self.norm = nn.GroupNorm(num_groups=1, num_channels=dims[-1])
self.head = nn.Linear(dims[-1], num_classes)
self.pool_layer = pool_layer
def forward(self, x):
# x: (B, C= in_chans, D, H, W)
for i in range(4):
x = self.downsample_layers[i](x) # DownSampling
x = self.stages[i](x) # ConvNeXt Block
# 예: pool_layer=[-1, -2, -3] => (B, C, D, H, W) 차원 기준으로 D,H,W 전부 평균
x = x.mean(dim=self.pool_layer) # Global Average Pooling 3D
x = self.norm(x)
x = self.head(x)
return x
class ConvNeXt3D(ConvNeXtBase):
"""
3D ConvNeXt
"""
def __init__(self, in_chans=1, num_classes=2,
depths=[3, 3, 9, 3], dims=[96, 192, 384, 768]):
super().__init__(
in_chans, num_classes, depths, dims,
conv_layer=nn.Conv3d,
pool_layer=[-1, -2, -3] # D, H, W 방향으로 평균
)
def convnext_3d(in_channels=1, out_channels=2,
depths=[3, 3, 9, 3], dims=[96, 192, 384, 768]):
"""
Cnn3dModel이 호출하는 factory 함수
base_model='convnext_3d'일 때 _load_attr_from_module()에서 이 함수를 호출하여 모델을 생성.
"""
return ConvNeXt3D(
in_chans=in_channels,
num_classes=out_channels,
depths=depths,
dims=dims
)해당 코드는 기존의 ConvNext모델을 2D에서 3D 데이터를 학습할 수 있게 변경된 모델입니다.
