3. 데이터에 대한 이해
3-0. 소개

- 과학기술은 [그림 1-8]과 같이 데이터 수집, 모델 정립, 예측 과정을 순환하며 발전합니다.
- 기계 학습도 순환 과정을 따릅니다.
- 하지만 인식 문제와 같이 복잡한 문제를 해결하기 위해선 충분히 많은 양의 데이터를 수집한 후, 기계 학습 알고리즘에 입력하여 자동으로 모델을 찾아내게 해야합니다.
3-1. 데이터 생성 과정
- 기계 학습에서 데이터 생성 과정(data generating process)를 알 수 없습니다.
- 왜냐하면, 인위적으로 설정한 가정이 아닌 실제 세상의 데이터를 수집하기 때문입니다.
3-2. 데이터베이스의 중요성
- 기계 학습은 훈련집합을 이용해서 데이터 생성 과정으로 역추정하는 문제입니다.
- 따라서 데이터베이스의 품질이 무척 중요합니다.
- 기계 학습에서는 주어진 응용 환경을 자세히 살핀 다음 그에 맞는 데이터베이스를 확보하는 일이 무엇보다 중요합니다.
- 많은 응용 분야에서는 수집한 데이터베이스를 무료로 제공하는 벤치마크가 있습니다.
- List of datasets for machine learning research에서 다양한 데이터셋을 얻을 수 있습니다.
3-3. 데이터베이스 크기와 기계 학습 성능
- 실제 세상의 데이터는 무한히 많습니다.
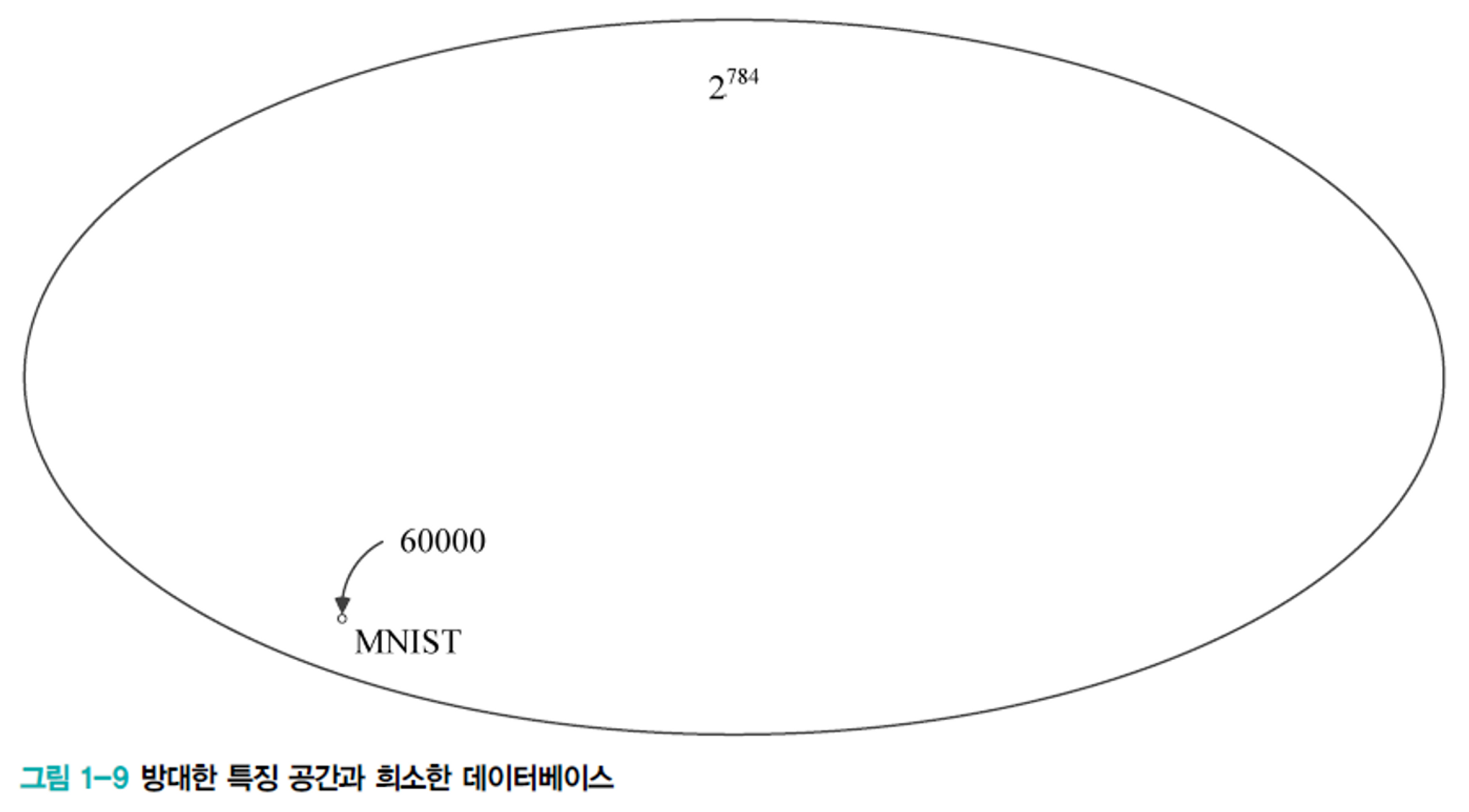
- [그림 1-9]는 MNIST 데이터베이스를 공간으로 대비하여 그린 것입니다.
- 기계 학습은 이처럼 방대한 공간 속 작은 데이터베이스인 MNIST 훈련집합을 사용해서 0.23%의 매우 낮은 오류율을 가진 프로그램을 만듭니다.
- 이 현상은 다음과 같은 이유로 설명됩니다.
- 방대한 공간에서 실제 데이터가 발생하는 곳은 훨씬 작은 부분공간입니다.
- 따라서 저 작은 공간에 대해서만 알면 우리는 0.23%의 낮은 오류율을 가진 인식 프로그램을 만들 수 있습니다.
- 발생하는 데이터는 심한 변화를 겪지만 일정한 규칙을 따라 매끄럽게 변화합니다.
- e.g. 숫자 '2' 데이터에 손상이 가더라도 '2'의 전체 형상이 '7'이 되진 않는 것과 같습니다.
- 방대한 공간에서 실제 데이터가 발생하는 곳은 훨씬 작은 부분공간입니다.
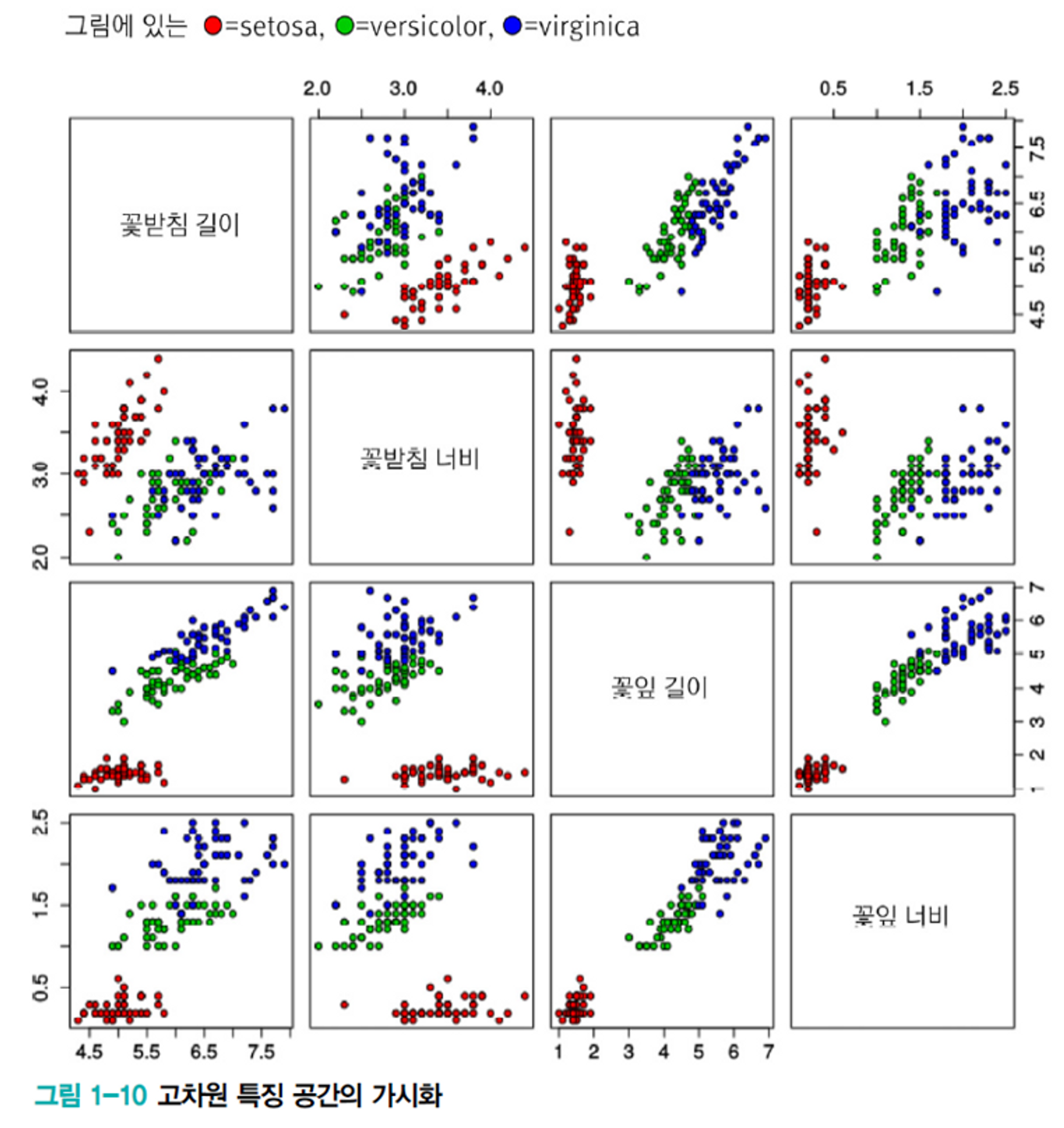
3-4. 데이터 가시화
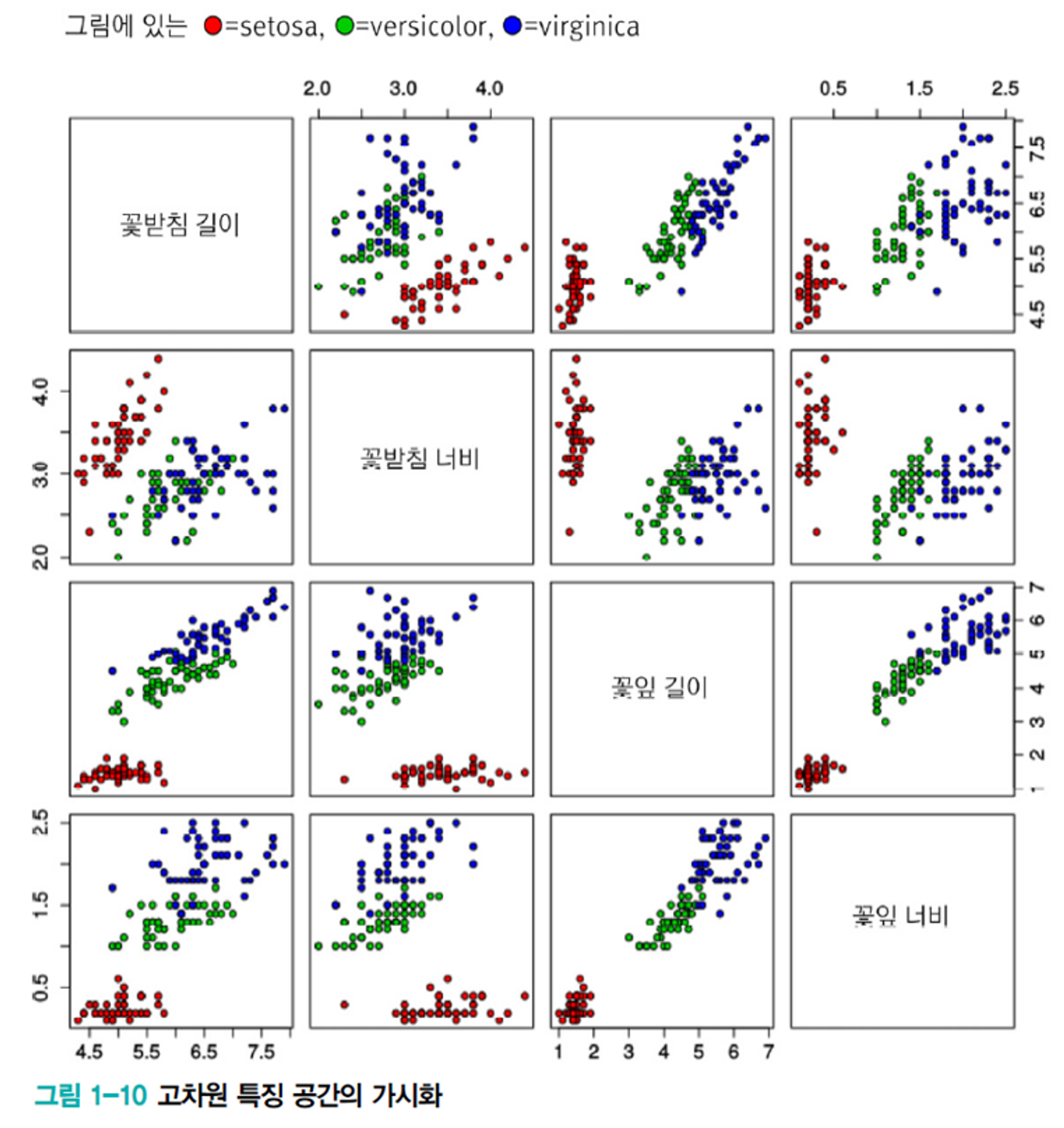
- 4차원 이상의 공간을 초공간(hyper space)이라고 한다.
- [그림 1-10]은 초공간에 분포하는 Iris 데이터를 가시화하는 한 가지 방법을 보여준다.
- 데이터를 가시화하면 데이터의 분포를 볼 수 있어 모델 선택, 한습 알고리즘 선택 등 중요한 의사결정에 큰 도움이 된다.

AI공의 폭풍은 정말 최고야!