
이번에 리뷰할 논문은 다양한 크기의 시각적 특징을 학습할 수 있는 방법을 제안한 Mugs: A Multi-Granular Self-Supervised Learning Framework(pdf) 논문이다.
0. Abstract
Self-supervised learning에서 다양한 downstream task는 다양한 크기의 feature를 요구하지만 다양한 크기의 feature를 반영하는 연구가 많지 않다. 저자들은 다양한 크기의 시각적 특징(multi-granular visual feature)을 명시적으로 학습하기 위해 MUlti-Granular Self-supervised learning(Mugs) 프레임워크를 제안한다.
Mugs는 3가지의 상호 보완적인 크기의 supervision을 제공한다:
1. Instance Discrimination Supervision(IDS) : IDS는 다른 인스턴스를 구별하여 인스턴스 수준의 fine-grained 특징을 학습한다.
2. Local Group Discrimination Supervision(LGDS) : LGDS는 이미지와 이웃의 특징을 local group 특징으로 aggregate하고, 동일한 이미지에서 crop된 다른 이미지의 local group 특징을 함께 끌어당기고 다른 것들에 대해서는 밀어낸다. LGDS는 지역 이웃에 대한 extra alignment를 통해 IDS에 상호 보완적인 instance supervision을 제공하고, 다른 지역 그룹을 밀어냄으로써 구별 능력을 높인다. 따라서 LGDS는 local group 수준에서 high-level fine-grained 특징을 학습하는 데 도움이 된다.
3. Group Discrimination Supervision(GDS) : GDS는 유사한 local group끼리 멀리 흩어지지 않도록 유사한 샘플끼리 가깝게 하고 유사한 local group도 함께 끌어당긴다. 그렇게 함으로써 semantic group 수준에서 coarse-grained 특징을 포착한다.
Mugs는 multi-granular feature를 포착함으로써 single-granular feature(ex : contrastive learning에서의 instance level fine-grained feature)보다 다양한 downstream task에서 더 높은 generality 가질 수 있다. Mugs는 ImageNet-1K에서 pretraining을 하였을 때 linear probing accuracy에서 82.1%를 달성하여 이전 SoTA보다 1.1% 향상되었다. 또한 transfer learinig, detection, segmentation에서도 SoTA를 능가하였다.
1. Introduction
Self-supervised learning(SSL) 접근법은 대규모 라벨이 없는 데이터셋에 deep model을 학습시켜 다양한 downstream task을 위해 transfer 가능한 unsupervised representation을 학습하는 것을 목표로 한다. 이를 위해 다양한 pretext task(ex : jigsaw puzzle, orientation)를 정교하게 설계하여 pseudo label을 생성할 수 있다. SSL은 최근 시각 표현 학습을 위해 매우 널리 채택되고 있으며, supervised 방식보다 highly-qualified and well-transferable representation을 학습하는데 더 큰 잠재력을 보이고 있다.
1.1 Motivation
SSL 분야의 다양한 downstream task는 다양한 크기의 특징을 필요로 한다. 예를 들어, 일반적으로 classification task는 카테고리 간의 구분을 위해 일반적으로 coarse-grained 특징을 필요로 한다. 반면 fine-grained classification은 subordinate 카테고리를 구별하기 위해 더 fine-grained한 특징을 필요로 한다. ImageNet-1K classification task에서 강아지, 새, 차를 구분하기 위해서는 coarse-grained 특징이 필요하고, 강아지 내에서 래브라도나 푸들과 같이 subordinate 카테고리를 구분하기 위해서는 fine-grained 특징이 필요하다.
그런데 최근에 연구되고 있는 contrastive learning 방식과 clustering learning 방식은 이렇게 multi-granular feature를 반영하고 있지 않다. Contrastive learning의 경우 개별 인스턴스를 구별하여 인스턴스 수준의 fine-grained 특징을 학습하기 때문에 coarse-grained 특징을 고려하지 않는다. 이러한 방식은 의미론적으로 유사한 인스턴스를 가깝게 끌어당기지 못하기 때문에 classification downstram task에 대한 성능을 해치게 된다. Clustering learning 방식은 유사한 인스턴스를 같은 클러스터로 묶어서 클러스터 수준의 coarse-grained 특징을 학습한다. 이 방식은 contrastive learning 방식과 반대로 fine-grained 특징을 필요로 하는 downstream task를 잘 처리할 수 없다. 따라서 downstream task에서 사전에 선호하는 특징이 없는 경우 가능한 많은 donwstream task를 잘 처리하기 위해 multi-granular representation을 학습할 수 있는 SSL 프레임워크를 구축해야 한다.
1.2 Contribution
저자들은 시각 데이터에 대한 다양한 크기의 특징을 명시적으로 학습하기 위한 MUlti-Granular Self-supervised learning(Mugs) 프레임워크를 제안한다. 구체적으로 Mugs는 세 가지 상호 보완적인 크기(IDS, LGDS, GDS)의 supervision을 반영한다.
Contrastive leanring에 영감을 받아 IDS는 인스턴스를 구별하기 위해 다양한 인스턴스 특징을 개별적으로 분산시키고 인스턴스 수준의 fine-grained 특징을 학습한다.
그리고 저자들은 local group 특징인 higher-level fine-grained 특징을 포착하기 위해 Mugs의 LGDS를 제안한다. LGDS는 작은 트랜스포머를 통해 인스턴스와 몇몇의 매우 유사한 이웃의 특징을 local group 특징으로 aggregate한다. 그 후 동일 이미지의 다른 crop의 local group 특징을 모으고 다른 것들에 대해서는 멀리 밀어낸다. 이 supervision은 Mugs를 두 가지 측면에서 향상시킨다. 첫 번째로 동일한 이미지의 다른 crop이 매우 유사한 이웃을 가지도록 정렬하기 때문에 IDS에 상호 보완적인 인스턴스 supervision을 제공하며 local group의 semantic 정렬을 향상시킨다. 두 번째로 매우 유사한 인스턴스가 작은 local group을 구성하도록 하고 이 그룹들을 개별적으로 분산시켜 더 구별력 있는 의미론적 학습을 촉진한다.
GDS는 유사한 local group이 멀리 분산되는 경우를 피하기 위해 설계되었다. 이를 위해 유사한 샘플을 함께 끌어 당기김으로써 유사한 로컬 그룹을 가까이 끌어당긴다. 이를 통해 그룹 수준에서 coarse-grained의 특징을 포착한다.
이러한 상호 보완적인 세 가지의 supervision을 통해 Mugs는 다양한 크기의 특징을 정확하게 포착할 수 있으며, 다양한 downstream task에서 single-granular 특징보다 generality와 transferability가 더 좋다. Figure 6을 보면 attention score를 보았을 때 다양한 크기의 특징을 포착하고 있는 것을 알 수 있다.
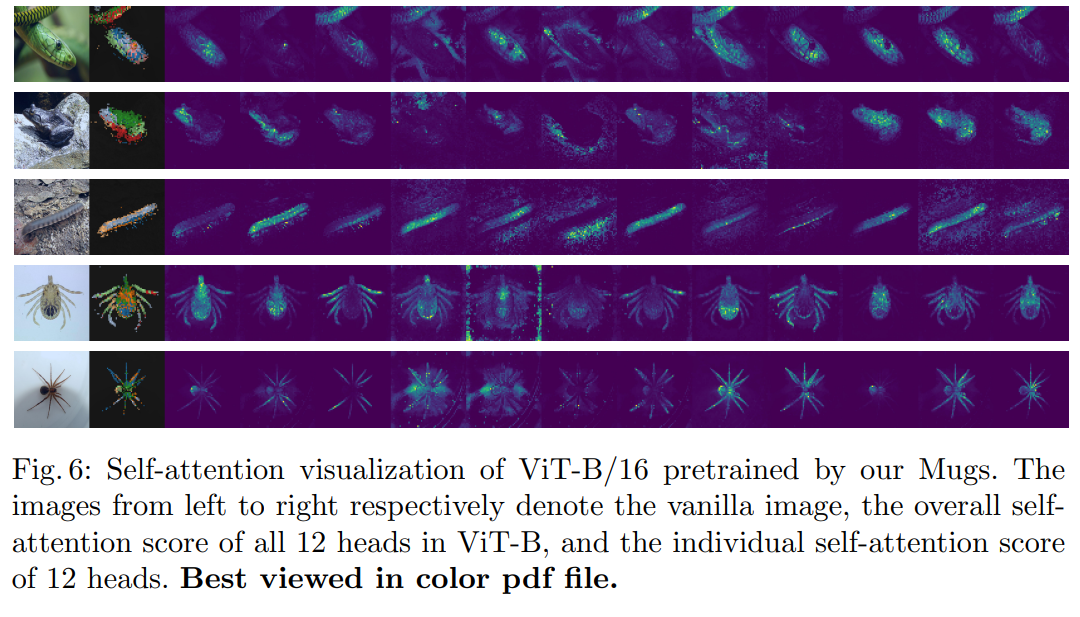
2. Related Work
SSL 분야에서 contrastive learning은 최근에 많은 주목을 받았다. contrastive learning의 핵심은 instance discrimination task로 같은 이미지에서 생성된 positive pair는 가깝게, 다른 이미지에서 생성된 negative pair는 멀게 학습한다. BYOL, Simsiam은 negative pair를 사용하지 않고 feature space에서 positive pair를 가까이 당기기만 하며 네트워크를 학습한다. 하지만 이러한 방법들은 fine-grained 특징을 학습하기 위해 개별 인스턴스만 구별하기 때문에 의미론적으로 유사한 인스턴스를 가까이 모으지 못해 성능이 저하된다.
다른 SSL의 방향성으로는 clustering learning이 있다. Clustering learning은 각 샘플에 대해 pseudo cluster label을 할당한 다음 네트워크를 훈련시켜 unsupervised representation을 학습한다. 예를 들어 deepcluster(Deep clustering for unsupervised learning of visual features)는 모든 데이터 특징을 클러스터링하기 위해 k-means를 사용하고, pseudo cluster label을 생성하여 네트워크를 학습한다. PCL(Prototypical contrastive learning of unsupervised representations)과 SwAV(Unsupervised learning of visual features by contrasting cluster assignments)은 query에 대한 positive와 negative 인스턴스로 클러스터 prototype을 학습하는 방식으로 contrastive learning과 온라인 클러스터링 접근법을 사용해 뛰어난 성능을 달성하였다. DINO(Emerging properties in self-supervised vision transformers)와 MST(Mst: Masked self-supervised transformer for visual representation)는 momentum teacher를 통해 pseudo label을 생성하여 간단한 온라인 labeling 프레임워크를 제안했다. 하지만 이 클러스터링 방식은 대체로 클러스터 수준의 coarse-grained 특징을 학습하며, fine-grained 특징을 원하는 downstream task를 잘 처리하지 못한다.
Masked auto-encoder(MAE)는 랜덤하게 이미지 패치를 마스킹하고 autoencoder를 통해 누락된 픽셀이나 의미론적 특징을 재구성하는 reconstruction 방식이다. MAE는 local region reconstruction에 중점을 두기 때문에 의미론적 구별 능력이 부족하다. 그래서 downstream task에 적용하기 위해 pretraining된 backbone의 head만 fine-tuning하는 것만으로는 contrastive learning 및 clustering learning보다 나쁜 성능을 보인다. 높은 성능을 달성하기 위해서는 MAE 방식은 downstream task에서 global semantic을 학습하기 위해 pretraining된 네트워크 전체를 fine-tuning해야 한다. 이러면 훨씬 더 많은 훈련 비용이 필요하며 여러 downstream task에 대해 매우 다른 모델을 생성하게 되어 모델 compatibility를 악화시키고 실질적으로 많은 비용을 요구한다.
3. Multi-granular self-supervised learning
MUlti-Granular Self-supervised learning(Mugs)의 전반적인 프레임워크와 세 가지의 granular supervision들에 대해 알아보자. ViT는 비슷한 모델 크기에서 CNN보다 더 나은 성능을 보이고 비전과 언어 모델을 통합하는 데 큰 잠재력을 보이기 때문에 저자들은 ViT를 통해 Mugs의 효과를 평가하였다.
3.1 Overall Framework
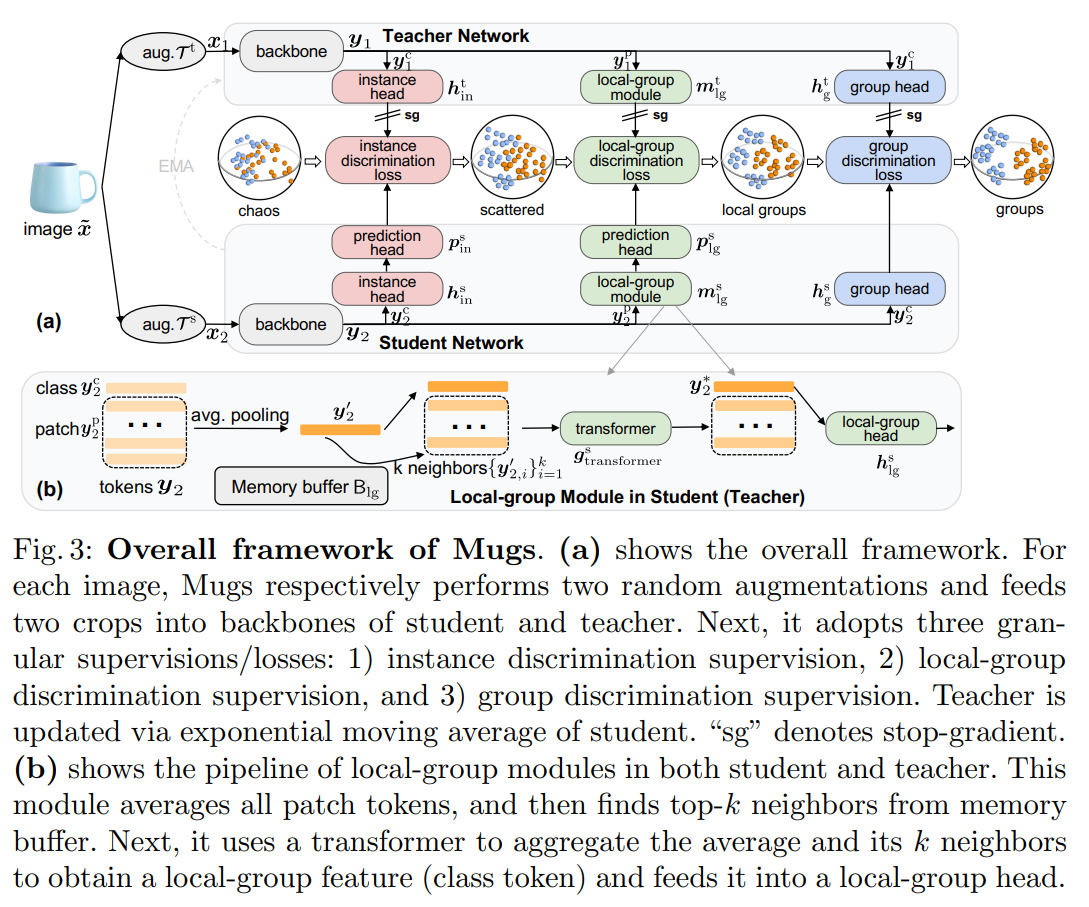
앞서 논의한 것처럼 다양한 downstream task을 위해서는 multi-granular 특징을 필요로 한다. 이를 위해 저자들은 single-granular 특징보다 더 높은 generality와 transferability를 가질 수 있는 간단하면서도 효과적인 Mugs 프레임워크를 제안한다. Figure 3(a)에서 이미지 가 주어지면, Mugs는 독립적으로 증강 와 를 수행하여 두 개의 crop 과 를 얻는다. 각각 과 teacher와 student의 backbone에 넣고 representation 과 를 얻는다. 이 representation들은 class token과 patch token을 포함한다. Mugs는 세 가지 granular supervision을 구축한다.
1) Instance discrimination supervision for instance-level fine-grained features
2) Local-group discrimination supervision for high-level fine-grained features at a local-group level
3) Group discrimination supervision for coarse-grained semantic features at a (semantic) group level
3.2 Multi-granular supervisions
3.2.1 Instance discrimination supervision
IDS를 통해 Mugs는 각 인스턴스를 자체적으로 고유한 클래스로 간주하며 가장 세분화된 수준의 granularity을 학습할 수 있다. 같은 이미지에서 생성된 crop을 feature space에서 모으고, 다른 이미지에서 생성된 crop은 멀리 밀어낸다. Figure 3(a)에서 볼 수 있듯이 IDS를 통해 인스턴스 특징을 sphere 표면에 있는 chaos distribution에서 대략적으로 흩뿌린다. IDS를 인스턴스 에 적용하기 위해 Mugs는 각각 두 특징 과 내의 두 class token 과 를 Figure 3(a)에서 보여지는 것처럼 각각의 인스턴스 헤드 과 에 넣는다. 그 후 Mugs는 추가적으로 를 prediction head 으로 전달하는데, 이것은 student나 teacher backbone에 의해 학습된 특징의 generality에 미치는 feature alignment의 부작용을 완화하기 위함이다. 마지막으로, MoCo 방식처럼 Mugs는 인스턴스 구별을 위해 InfoNCE loss를 사용한다.
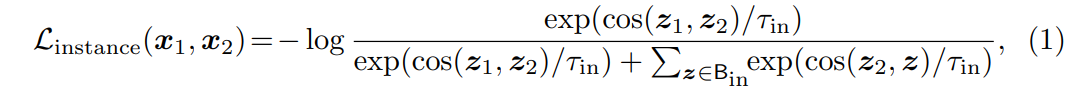
여기서 , 이고, 은 temperature parameter이다. 버퍼 은 의 negative sample을 저장하고 first-in and first-out order로 teacher에 의해 생성되었던 미니배치 특징 에 의해 업데이트된다. 이런 방식으로 Mugs는 버퍼 에서 negative sample로부터 crop 를 멀리 밀면서 positive sample인 crop 는 가까이 당긴다. 따라서 모델이 fine-grained 특징을 학습하도록 하고 인스턴스 수준의 특징 다양성을 증가시킨다.
3.2.2 Local-group discrimination supervision
fine-grained 특징들은 충분한 high-level semantic이 부족하기 때문에 다양한 downstream task에는 부족하다. Higher-level fine-grained 특징을 의미하는 local-group feature를 학습하기 위해 Mugs는 local-group supervision를 제안한다. 직관적으로 Figure 3(a)의 세 번째 sphere에서 보여지는 것처럼 이 supervision은 별도로 흩어진 작은 지역 local group을 가지도록 한다. 즉, 매우 유사/유사하지 않은 샘플들 사이에 작은/큰 거리를 둔다. 이를 통해 데이터에 있는 약간 더 높은 수준의 의미론을 포착하는 데 도움을 줄 수 있다.
Figure 3(a)을 보면, 이미지 의 crop 이 주어지면, teacher backbone은 class token 과 patch token 을 포함하는 을 출력한다. 마찬가지로 의 또 다른 crop 를 student backnone에 넣어 class token 와 patch token 를 포함하는 를 얻는다. 다음으로 Mugs는 각각 patch token 와 의 평균을 내어 Figure 3(b)에서 설명된 것처럼 두 개의 average token 과 를 얻는다. class token 대신 average of patch token이 더 많은 정보를 포함하고 더 정확한 이웃을 찾을 수 있기 때문에 average of patch token을 사용한다. CNN backbone의 경우 마지막 feature map의 평균을 내어 과 를 얻을 수 있다. Mugs는 선입 선출 순서로 이전 미니배치 average token 과 를 저장하기 위해 메모리 버퍼 를 사용한다. 그 다음 Figure 3(b)에서 보여지는 것처럼 과 각각에 대해 Mugs는 버퍼 에서 그들의 상응하는 top- 이웃 과 을 각각 찾는다. 그리고 average token과 average token의 개의 이웃을 aggregate하기 위해 트랜스포머를 사용한다.
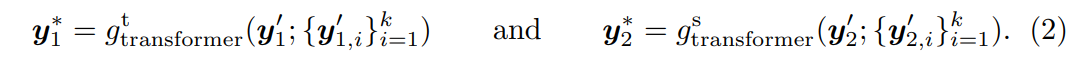
여기서 는 어떠한 patch embedding 계층도 없는 2-layer vanilla ViT를 사용하였고, 입력 class token , 입력 patch token , 출력 class token 을 가진다. 은 와 의 top- 이웃 로부터 나온 것으로, 의 local group을 구성한다. 따라서 은 “local group feature"라고도 불린다.
Mugs는 이 두 개의 local group 특징 과 를 동일한 인스턴스 는 당기고 다른 인스턴스의 local group 특징을 밀어낸다. 마찬가지로 Mugs는 위해 InfoNCE loss를 사용한다.
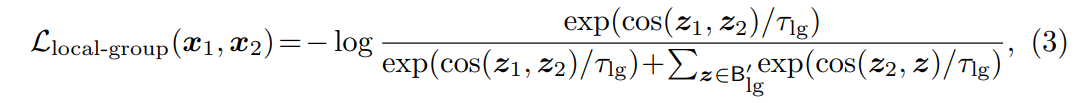
여기서 이고 이다. 버퍼 는 teacher에 의해 생성된 local group 특징 을 선입 선출 순서로 저장한다.
이 지도는 Mugs에게 두 가지 측면에서 이점을 준다. 첫 번째로 IDS에 대한 보완적인 인스턴스 supervision을 제공한다. LGDS loss를 감소하기 위해서는 의 두 개의 crop 과 는 매우 유사한 top-k 이웃을 가져야 한다. 이것은 crop 자체 외에도 crop들이 상응하는 이웃도 잘 정렬되어야 함을 의미하며 IDS와 비교하여 추가적으로 까다로운 정렬 문제이며 local group semantic allignment를 강화한다. 두 번째로 LGDS는 고도로 유사한 인스턴스들이 local group을 형성하고 이러한 local group들을 별도로 흩뿌리도록 한다. 이는 학습된 특징의 의미론적 구별 능력을 높인다. 왜냐하면 같은 지역 그룹 내의 샘플들이 고도로 유사하고 작은 거리를 가지도록 local group을 형성하는 데 도움을 주기 위해 작은 (약 10)를 사용하였고, 현재의 local group 특징을 다른 인스턴스들의 local group 특징으로부터 더 멀리 밀어내면서 다른 local group들을 별도로 흩뿌린다.
이러한 두 가지 측면으로, 이 LGDS는 데이터의 local group 구조를 고려하여 higher-level
fine-grained 특징 학습을 boosting한다.
3.2.3 Group discrimination supervision
GDS는 Mugs에서 가장 coarse level의 supervision이다. 직관적으로 Figure 3(a)의 마지막 sphere에서 보여지는 것처럼 인스턴스와 local group을 의미론적으로 유사한 대형 그룹에 모으는 것을 목표로 하며 이는 IDS와 LGDS에 비해 데이터에서 더 global semantic을 나타낼 수 있다.
인스턴스 의 경우, Mugs는 각각 teacher backnone에서 의 class token 과 student backbone에서 의 class token 를 두 gropu head 와 로 넣는다. 그런 다음 학습 가능한 cluster prototype 를 구축하고 온라인 방식으로 soft pseudo clustering label을 계산한다. 수식은 다음과 같다.
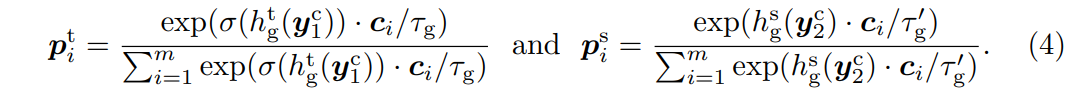
여기서 함수 는 특징 의 다양성을 증가시키고 Eqation (4)에서 soft pseudo label 를 더욱 sharpening 한다. 는 미니 배치 의 지수 이동 평균을 통해 모든 과거 의 추정 평균 통계를 나타낸다. 이 방식은 DINO에서 차용하였다.
Supervised classification task과 유사하게, Mugs는 soft label로 cross-entropy loss를 사용한다. 수식은 다음과 같다.
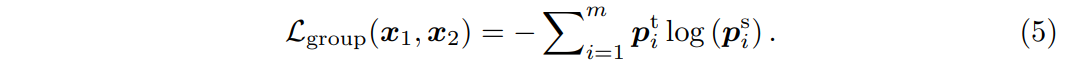
저자들이 상요한 세 가지 granular supervision의 효과에 대해 살펴보자. 이미 언급했듯이 IDS는 같은 이미지의 crop을 함께 모으고 인스턴스 특징을 sphere에서 별도로 흩뿌리는 것이다. 이것은 Mugs가 인스턴스 수준의 fine-grained 특징을 학습하게 도와준다. 다음으로 LGDS는 먼저 IDS에 보완적인 supervision을 제공하여 같은 인스턴스의 crop이 매우 유사한 이웃을 가지도록 한다. 그런 다음, Figure 3(a)의 세 번째 sphere에서 보여지는 것처럼 LGDS는 이러한 local group의 의미론적 구별 능력을 향상시키기 위해 다른 local group을 따로 흩뿌린다. 이 supervision은 주로 local group 수준에서 higher-level fine-grained 특징을 학습한다. 마지막으로 유사한 지역 그룹이 무작위로 또는 멀리 흩어지는 것을 피하기 위해, GDS는 유사한 샘플을 함께 모으고 유사한 local group을 가까이 끌어당긴다. 이것은 Figure 3(a)의 마지막 sphere에서 직관적으로 표현되었다. 이를 통해 그룹 수준에서 coarse-grained 특징을 포착하는 것이다.
이러한 세 가지 granular supervision을 통해, Mugs는 더 나은 generality와 다양한 종류의 downstream task에 대한 transferability를 가진 특징을 잘 학습할 수 있다. 기존의 방법들(MoCo, DINO)과 비교했을 때 Mugs의 주요 novlety는 두 가지이다.
1) Mugs는 세 가지 보완적인 granular supervision을 통해 다양한 downstream task를 더 잘 처리할 수 있는 multi-granular representation을 학습한다.
2) Mugs는 IDS와 GDS를 모두 보완할 수 있는 새롭고 효과적인 LGDS를 제안한다.
3.2.4 Overall training objective
Overall training loss는 다음과 같다.
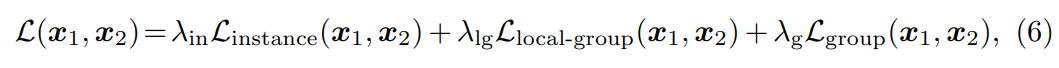
여기서 세 상수 , , 는 세 가지 supervision 사이의 균형을 맞추기 위한 것이다. 저자들은 간단히 하기 위해 모든 실험에서 세 상수를 모두 1/3으로 설정하였다. 그런 다음 loss를 최소화하여 student network를 최적화였다. Teacher network는 student network 파라미터의 exponential moving average를 통해 업데이트된다.
4. Experiments
Mugs의 성능 평가를 위해 classfication task, transfer learning task, detection task, segmentation task, video segmentation task를 수행하고 SOTA 모델들과 비교하였다.
backbone으로는 ViT를 사용하였으며 =8, 버퍼들과 프로토타입의 크기는 65,536으로 설정하였다.
레이블 없이 ImageNet-1K train dataset으로 Mugs를 pretraining 하였다. DINO와 iBOT과 동일하게 symmetric training loss를 사용하였고 data augmentation으로 224x224 크기의 crop 2개와 96x96 크기의 crop 10개를 사용하였다.
4.1 Results on ImageNet-1K
저자들은 linear probing, KNN, fine-tuning, semi-supervise learning 방식을 통해ImageNet-1K에서 Mugs와 SoTA들을 비교하였다.
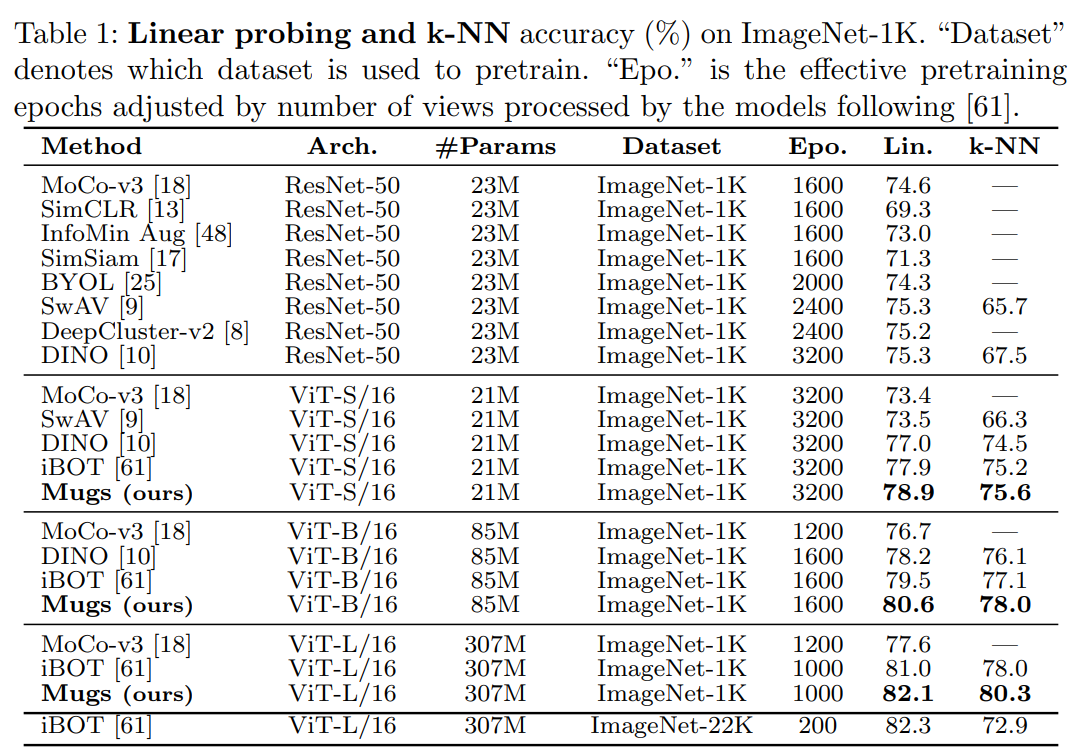
4.1.1 Linear Probing
Pretrain된 backbone을 freeze하고 linear classifier를 추가하여 100 에폭 동안 ImageNet-1K에서 훈련하였다. Table 1를 통해 ImageNet-1K에서 top-1 test accuracy를 알 수 있다. Mugs는 ViT-S와 ViT-B에서 각각 78.9%와 80.6%의 top-1 accuracy를 달성하며, SOTA를 최소 1.0% 이상 향상시킨다.
4.1.2 KNN
DINO와 iBOT 방식을 따라 저자들은 각 모델에 대해 가장 가까운 이웃(10, 20, 50, 100)을 조사하였다. Table 1에서 모든 백본에 대해, Mugs는 ImageNet-1K 테스트 데이터셋에서 최고의 top-1 accuracy를 달성하였다.
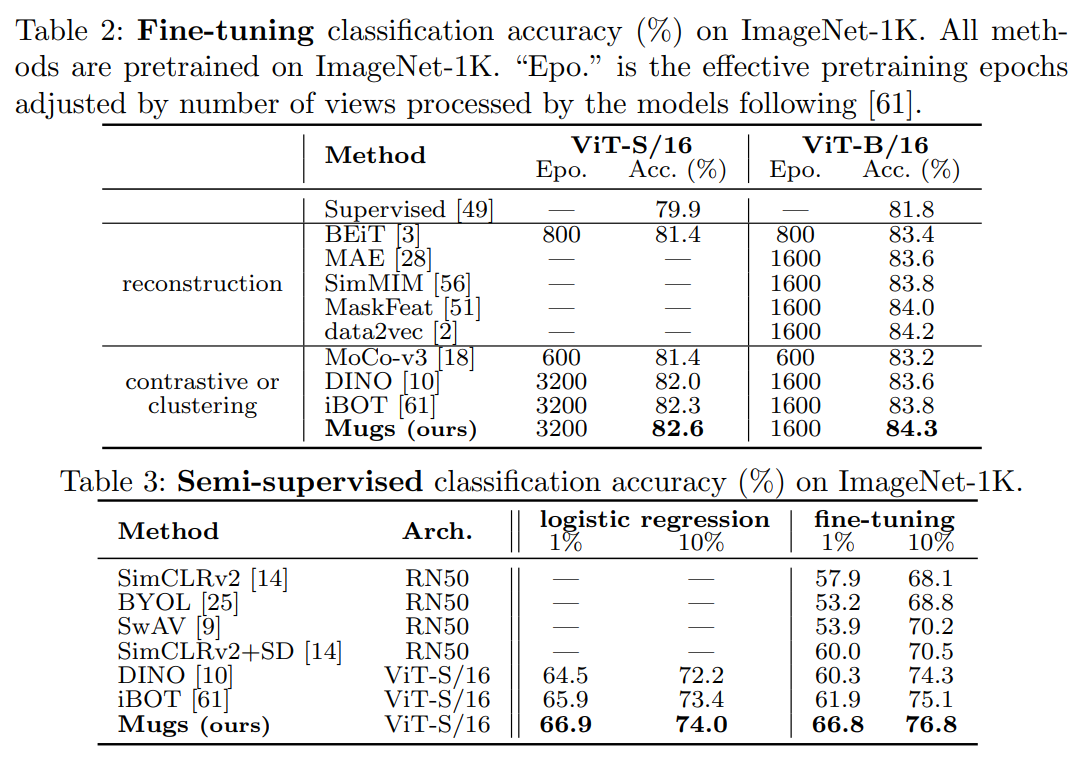
4.1.3 Fine-tuing
Pretrain된 backbone을 linear classifier와 함께 최적화하였다. Table 2를 통해 결과를 확인할 수 있다. Supervised는 DeiT에서 pretrain된 backbone을 사용하지 않고 모델 매개 변수를 무작위로 초기화하고 300 에폭 동안 훈련한 결과를 인용하였다. ViT-S와 ViT-B에서, Mugs는 각각 최고 결과인 82.5%와 84.3%를 달성하였다.
4.1.4 Semi-supervise learning
저자들은 ImageNet-1K의 훈련 데이터의 1%/10%를 사용하여 pretrain된 backbone을 fine-tuing하고, 테스트 데이터에서 평가하였다. DINO와 iBOT를 따라 두 가지 설정을 고려하였다.먼저 freeze된 특징 위에 logistic regression classifier를 훈련시키고, 전체 pretrained backbone을 fine-tuing하였다. Table 3은 1%와 10%의 훈련 데이터에 대해 Mugs가 두 설정 모두에서 이전의 모델들을 지속적으로 능가함을 보여준다.
4.1.5 Result Analysis

Figure 4는 T-SNE를 사용하여 MoCo-v3, DINO, iBOT, 그리고 Mugs 간의 특징 차이를 보여준다. 여기서 각 색깔은 고유한 클래스를 나타낸다. Mugs는 하나의 클래스 안에서도 여러 개의 작은 클러스터로 나눈다. 예를 들어 갈색에 대해서는 6개의 클러스터, 보라색에 대해서는 4개의 클러스터, 빨간색에 대해서는 6개의 클러스터, 그리고 파란색에 대해서는 5개의 클러스터로 나눈다. 이는 특징 공간에서 multi-granular 구조를 부분적으로 보여준다.
반면에 MoCo-v3, DINO 그리고 iBOT은 이러한 multi-granular 특성 구조를 보이지 않는다. 따라서 초록, 빨강, 보라 색으로 표시된 몇몇 어려운 클래스에 대해 Mugs는 잘 구별할 수 있다. 클래스를 하나로 보는 것이 아닌 Mugs는 multi-granular 데이터 의미 구조를 고려하기 위해 multi-granular supervision을 활용하고, pretraining 단계에서 전체 클래스를 몇 개의 쉽게 구별할 수 있는 클러스터로 나눈다.
4.2 Results on downstream task
4.2.1 Transfer learning
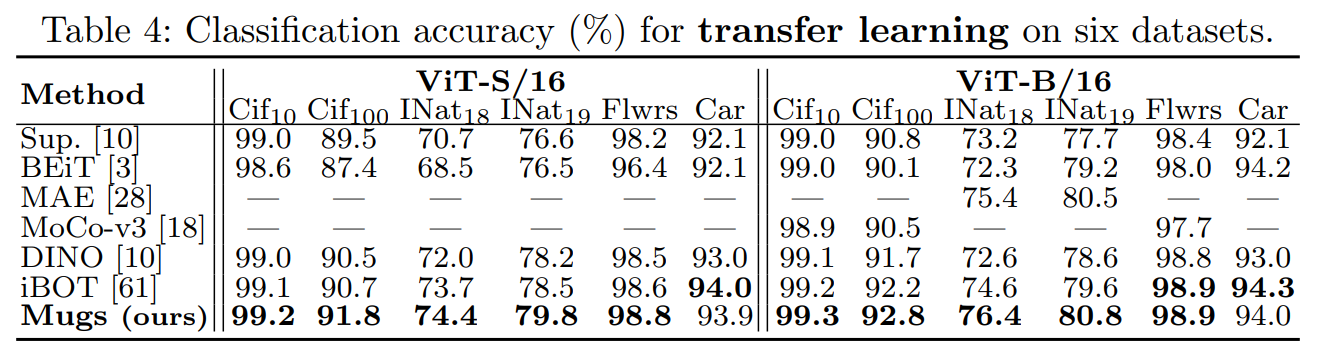
Mugs로 pretrain된 모델들의 transferability을 알아보자. ImageNet-1K에서 모델을 pretrain한 다음 다양한 종류의 다른 데이터셋에서 pretrain된 backbone을 fine-tuning한다. Table 4는 classification accuracy를 보여준다. "Sup."는 ImageNet-1K에서 supervised 방식으로 backbone을 pretrain하고 해당 데이터셋에서 backbone을 fine-tuning하는 설정을 나타낸다. Table 4에서 Mugs는 처음 다섯 개의 데이터셋에서 SoTA를 능가하고, Car 데이터셋에서는 비슷한 정확도를 달성한다.
4.2.2 Object detection & Instance segmentation
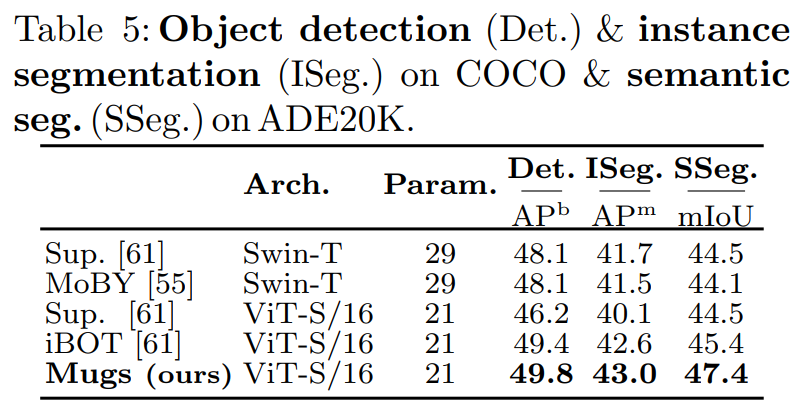

Object detection과 Instance segmentation에 대해 Mugs를 평가한다. Table 5를 보면 Object detection에서 Mugs가 49.8 를 달성하고 iBOT보다 향상을 보인다. Figure 4(b)에서 Mugs가 COCO에서 객체를 정확하게 위치시키고 분류할 수 있음을 보여준다. Instance segmentation의 경우에도 Mugs는 모든 비교 베이스라인을 능가하고 최고의 베이스라인보다 0.4 을 향상시킨다.
4.2.3 Semantic segmentation
Table 5는 모든 Semantic 카테고리에서 mIoU을 보여준다. Mugs는 SoTA들을 지속적으로 능가한다. Figure 4(c)에서 Mugs가 객체의 형태를 정확하게 포착할 수 있음을 보여준다.
4.2.4 Video object segmentation
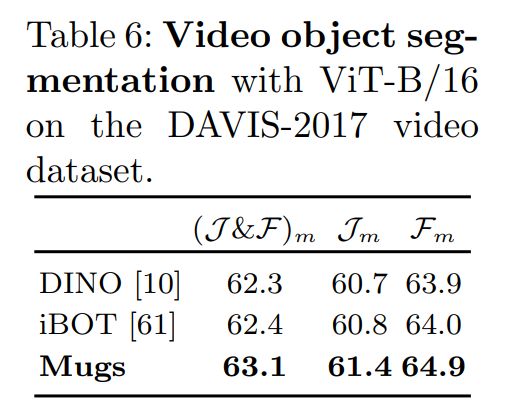
비디오에서 frozen pretrain된 특성의 transferability을 더 평가하였다. Table 6은 ViT-B/16을 사용하여 DAVIS-2017 비디오 분할 데이터셋에서 Jm과 Fm을 보여준다. Mugs가 비디오 분할에서도 DINO와 iBOT보다 더 나은 특성 transferability 가지고 있음을 알 수 있다.
4.3 Ablation study
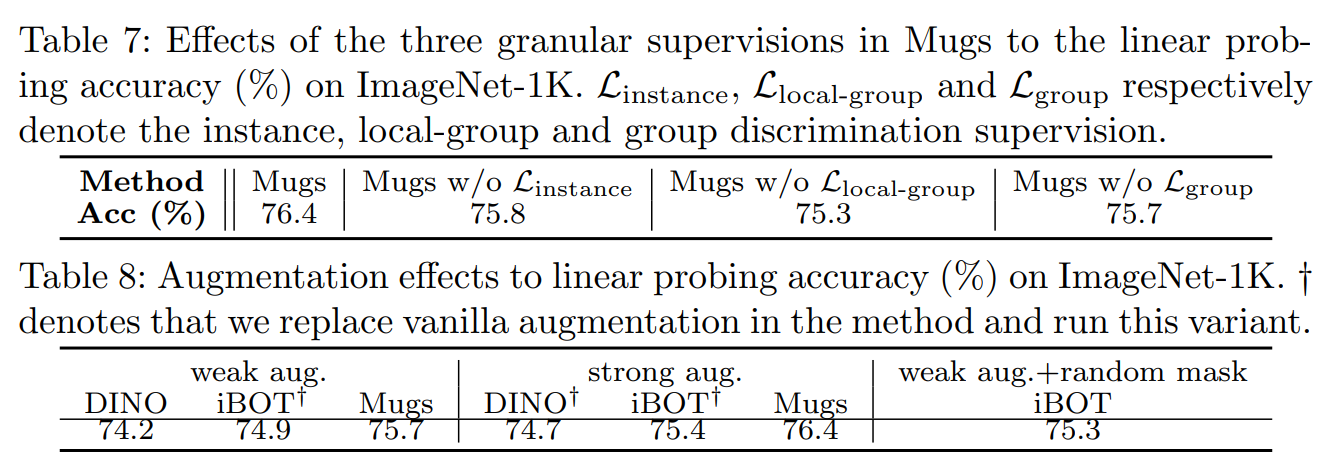
저자들은 Mugs에서 multi-granular supervision의 효과를 각각 실험하였다. Table 7을 보면 각각의 supervision을 제거하면 Mugs의 성능이 저하되는 것을 볼 수 있다. 이는 각 세supervision의 이점을 알 수 있고 특히 LGDS의 이점을 보여준다.
그리고 다양한 증강하에 Mugs와 DINO 그리고 iBOT을 비교하고 증강의 효과도 보여준다. Table 8은 실험 결과를 보여준다. Weak augmentation, strong augmentation 하에서 Mugs는 DINO와 iBOT을 일관되게 능가한다.
Multi-granular supervision 프레임워크는 Mugs에 크게 기여하며, Mugs가 DINO와 iBOT에 비해 크게 향상된 주요 요인이다.
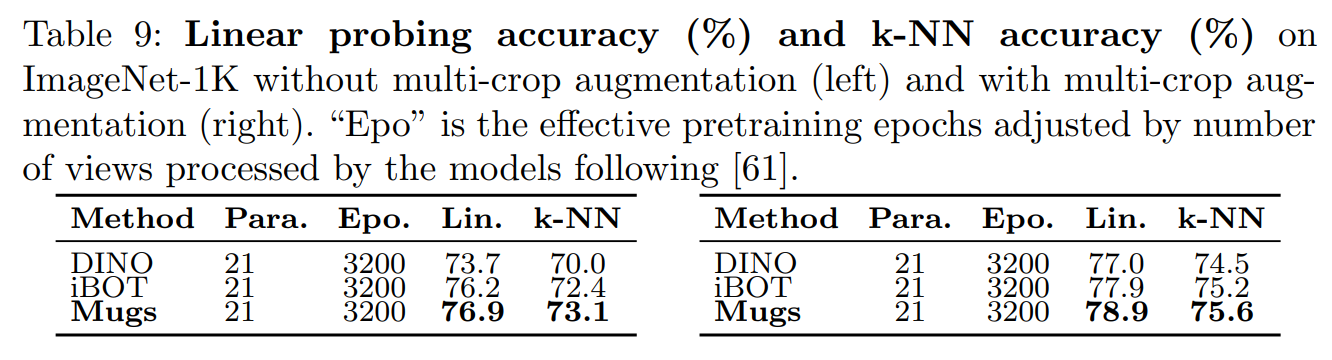
또한 다중 crop augmentation 없이 Mugs를 평가하였을 때 즉, pretrain을 위해 크기가 224×224인 두 개의 crop만을 사용하였을 때 Table 9을 보면 알 수 있듯이 동일한 설정에서 Mugs가 DINO와 iBOT을 포함한 SoTA를 능가한다.
5. Conclusion
저자들은 IDS, LGDS, GDS 세 가지 상호 보완적인 multi-granular supervision을 통해 다양한 특징을 학습하기 위해 Mugs를 제안하였다. IDS는 다양한 인스턴스를 구별하여 fine-grained 특징을 학습한다. LGDS는 인스턴스 주변의 local group을 고려한 다음 다양한 local group을 구별하여 higher-level fine-grained 특징을 추출한다. GDS는 유사한 샘플과 local group을 하나의 클러스터로 묶어 coarse-grained global group semantic을 포착한다.
