[Paper Review] Bootstrap Your Own Latent A New Approach to Self-Supervised Learning
Paper Review

이번에 리뷰할 논문은 positive sample만을 이용하여 self-supervised learning을 하는 방식의 Bootstrap Your Own Latent A New Approach to Self-Supervised Learning(pdf) 논문이다.
1. Introduction
컴퓨터 비전에서 좋은 이미지 representation을 학습해야 downstream task에서 좋은 성능을 얻을 수 있다. 기존에는 visual pretext task에 의존하는 다양한 훈련 방식이 제안되었다. 이러한 방법 중에서 현재 가장 좋은 성능을 보여주는 contrastive method는 동일 이미지에서 서로 다른 방법으로 augmented된 view(positive sample)의 representation 사이의 거리는 가깝게, 다른 이미지 뷰(negative sample)의 representation 사이의 거리는 멀어지게 학습한다.
이전에 리뷰한 SimCLR, MoCo 논문들고 이러한 방식을 이용한다. 그런데 이는 negative sample을 신중하게 처리해야 하기에 일반적으로 큰 배치 크기, 메모리 뱅크 전략을 사용한다. 또한, 이러한 방법의 성능은 image augmentation 방식의 선택과 조합에 크게 의존한다.
본 논문에서는 Bootstrap Your Own Latent (BYOL)이라는 새로운 self-supervised learning of image representation 알고리즘을 소개한다. BYOL은 negative pair를 사용하지 않고도 contrastive method들보다 더 높은 성능을 보여준다.
Bootstrap이란, 일반적으로 한 번 시작되면 알아서 진행되는 일련의 과정을 뜻한다. 저자들은 bootstrap이란 용어를 통계적 의미가 아닌 관용적 의미로 사용하였다. 왜 본 논문의 제목에서 bootstrap이 사용되었는지는 포스트를 다 읽어보면 이해할 수 있을 것이다. BYOL은 contrastive method보다 image augmentation의 선택에 더 robust하며, negative pair에 의존하지 않는 것이 robust함의 주요 이유라고 한다. 기존의 bootstraping 방법은 pseudo-label, cluster indices, handful of label을 사용했지만, 저자들은 representation을 직접 bootstrap하는 것을 제안한다.
BYOL은 online 및 target netwokr라고 하는 두 개의 신경망을 사용하여 서로 상호 작용하고 학습한다. 이미지의 확장된 view에서 시작하여 BYOL은 online network를 훈련시켜 동일 이미지에서 다르게 augmented된 view의 target network representaiton을 예측하도록 한다.
2. Related Work
representation learning을 위한 대부분의 unsupervised learning은 generative 또는 discriminative 방식으로 분류될 수 있다. representation learning에 대한 생성적 접근 방식은 데이터와 잠재 임베딩에 대한 분포를 구하고 학습된 임베딩을 이미지 표현으로 사용한다.생성적 방법은 일반적으로 픽셀 공간에서 작동하기 때문에 계산 비용이 많이 드는데, 이미지 생성을 위해 필요한 상세한 수준은 representation learning에는 필요하지 않을 수 있다.
Discirminative 방법 중에서는 contrastive method가 현재 self-supervised learning에서 SOTA 성능을 달성하고 있다. contrastive method는 픽셀 공간에서의 비용이 많이 드는 생성 단계를 피하기 위해 동일 이미지의 다른 뷰의 표현을 가깝게 하고 다른 이미지의 뷰의 표현을 멀게 하는 방식이다. contrastive method가 잘 작동하려면 각 sample을 다른 많은 sample과 비교해야 하므로 negative sample을 다루는 방식이 중요하다.
DeepCluster는 contrastive method의 단점인 negative sample을 다루는 것에 대한 일부를 해결할 수 있다. DeepCluster는 이전 버전의 representation을 bootstrap하여 다음 representaiton을 위한 target을 생성한다. 이 방법은 이전 representation을 사용하여 데이터 point를 clustering하고 각 샘플의 cluster index를 새 representation의 분류 target으로 사용한다. DeepCluster는 negative pair를 사용하지 않지만 clustering 비용이 많이 들고 collapse에 주의해야 한다.
일부 self-supervised learning 방식은 contrastive 방식이 아니지만 사람이 만든 auxiliary prediction task를 사용하여 표현을 학습한다. patch prediction, colorizing gray-scale images, image inpainting, image jigsaw puzzle, image super-resolution, and geometric transformations은 유용하다는 것이 입증되었다. 그러나 적합한 아키텍처를 사용하더라도 이러한 방법들은 contrastive method에 비해 성능이 좋지 않고 pretext task를 위한 인간의 개입이 필요하다는 단점이 있다.
저자들이 제안한 방식은 Predictions of Bootstrapped Latents과 약간 유사한 점이 있다. 이는 강화 학습을 위한 self-supervised representaiton learning으로, PBL은 에이전트의 history representation과 future observation의 인코딩을 함께 훈련한다. Observation encoding은 에이전트의 representation을 훈련하기 위한 target으로 사용되며, 에이전트의 representation은 observation encoding을 훈련하기 위한 target으로 사용된다. 하지만 PBL과 달리 BYOL은 target을 제공하기 위해 representation의 slowly-moving average를 사용하며 두 번째 네트워크가 필요없다.
저자들은 deep RL에서 slowly-moving average target network를 사용하여 online network의 stable target을 생성하는 아이디어의 영감을 받았다. 대부분의 RL 방법은 고정된 target network를 사용하지만 BYOL은 target network의 부드러운 representation을 제공하기 위해 이전 네트워크의 weighted moving average를 사용한다.
Self-supervised learning에서 MoCo는 메모리 뱅크에서 추출된 negative sample의 일관된 표현을 유지하기 위해 slow-moving average network(momentum encoder)를 사용한다. BYOL은 bootstrap 단계를 안정화하기 위한 수단으로 예측 target을 생성하기 위해 moving average
network를 사용한다. 저자들은 이런 단순한 안정화 효과만으로도 기존의 contrastive method를 개선할 수 있다는 것을 보여준다.
3. Method
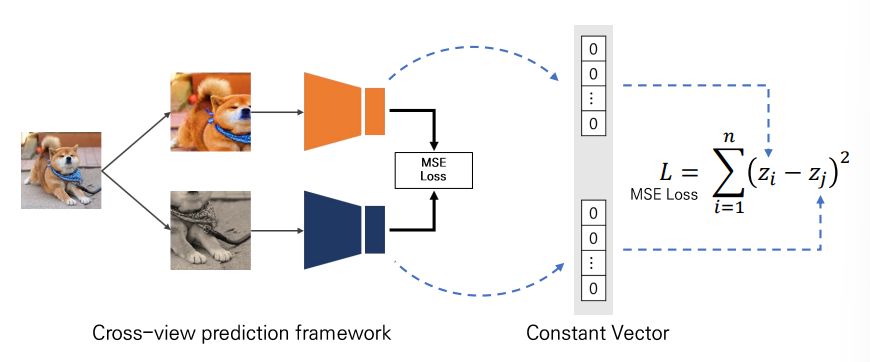
많은 self-supervised learning 방식들은 cross-view prediction framework를 기반으로 한다. 이 방식은 동일한 이미지의 다른 view(positive sample)를 서로 예측함으로써 representation을 학습한다. 동일한 이미지에서 생성된 뷰는 다른 뷰의 representation을 예측해야 하는데, 동일한 이미지의 다른 뷰를 예측하는 것은 collapsed representaiton으로 이어질 수 있다.
collapsed representation은 모델이 어떠한 input에 대해서도 같은 값을 내보내서 생기는 현상인데, positive sample만 학습할 경우 결국 모델은 loss를 0으로 만들기 위해 모두 같은 값을 내보내면 되기 때문에 학습이 되지 않는다. 네트워크 입장에서 계속 같은(augmentation돼서 아예 동일하진 않지만) 이미지끼리 embedding vector를 가깝게 하는 것으로 받아들이고 네트워크는 계속 두 뷰의 similarity가 1이 되도록 embedding vector를 출력한다. 모델은 항상 상수(constant)만 출력해도 두 임베딩 간의 거리가 0이 되어 shorcut을 이용한 학습이 가능해진다. 이렇게 되면 train loss는 작아지지만 representation 학습은 전혀 되지 않는 문제가 발생한다.
Contrastive method는 cross-view prediction에서 collapsed representation을 방지하기 위해 positive sample과 negative sample을 모두 사용한다. 하지만 앞서 언급했듯이 negative sample을 사용하는 contrstive method는 많은 양의 negative sample이 필요하기 때문에 저자들은 negative sample을 사용하지 않으면서 collapsed representation을 방지하고, 고성능을 유지할 수 있는 방안에 대해 연구하였다.
collapsed representation을 방지하기 위한 단순한 해결방법은 fixed randomly initialized network를 사용하는 것이다. 이러면 collapse를 방지할 수 있지만 네트워크가 randomly initialized 되었기 때문에 당연히 좋은 representation을 얻지 못한다. 하지만 이러한 방식을 활용하면 좋은 representation을 얻을 수 있다. 주어진 representation(target)으로부터 목표 representation을 예측함으로써 새로운 향상된 representation(online)을 훈련할 수 있다. 그런 다음 이 절차를 반복하여 점진적으로 품질이 향상된 representation의 sequence를 구축할 수 있다. 실제로 BYOL은 fixed checkpoint 대신 online network에서 slowly moving exponential average를 사용하여 taget network를 update하는 bootstrap 과정을 거친다.
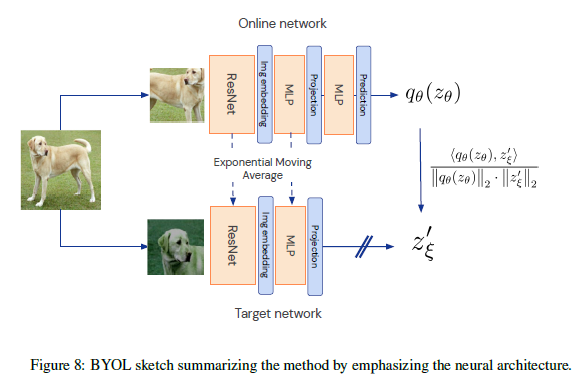
3.1 Description of BYOL
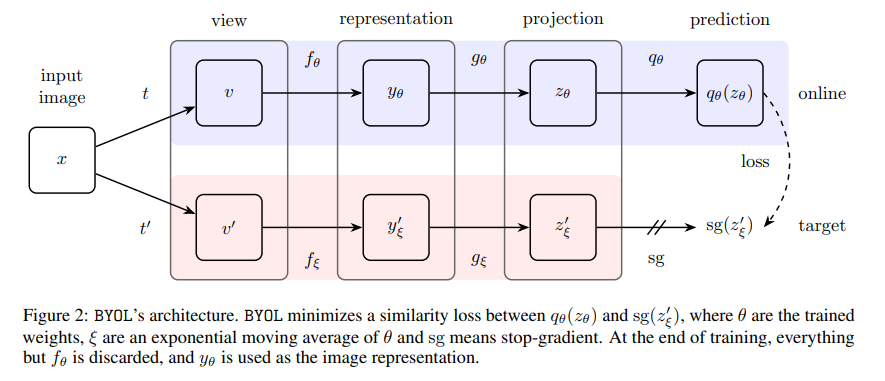
BYOL의 목표는 downstream task에 사용될 수 있는 representation 를 학습하는 것이다. BYOL은 online network와 target network 두 개의 신경망을 사용해 학습한다. online network 가중치 세트 로 정의되며, encoder , projector , 그리고 predictor 로 구성된다. target network는 online network와 같은 구조를 가지지만, 다른 가중치 세트 를 사용한다. target network는 online network를 학습시키기 위한 regression target을 제공하며, 그 파라미터 는 online parameter 의 exponential moving average이다.
주어진 이미지 세트 에서, 랜덤 샘플링된 이미지 와 두 개의 이미지 증강 분포 와 를 사용해 와 라는 두 개의 증강된 뷰를 생성한다. 첫 번째 증강된 뷰 로부터 online network는 representation 와 projection 를 출력한다. target network는 두 번째 증강된 뷰 로부터 와 를 출력한다. 그런 다음 라는 의 예측 값을 출력하고, 와 를 모두 정규화한다. predictor는 online network에만 적용되므로, online과 target 파이프라인 사이의 구조가 asymmetric하다. 마지막으로 정규화된 예측값과 target projection 사이의 mean squared error를 다음과 같이 정의한다:
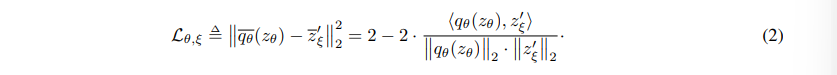
손실 를 symmetrize하기 위해 를 online network에 , 를 target network에 feeding하여 를 계산한다. 각 학습 단계에서, 를 최소화하기 위해 stochastic optimization을 수행한다. 이는 에 대해서만 수행되며, 는 적용되지 않는다. 학습이 끝나면, encoder 만 유지된다.

3.2 Intuition on BYOL's behavior
BYOL은 에 대해 를 최소화하는 동안 collapse를 방지하기 위한 explicit term을 사용하지 않는다. 따라서 BYOL은 이 loss의 최소값으로 에 수렴하는 것처럼 보일 수 있다(ex: collaped constant representation). 그러나 BYOL의 target parameter 의 업데이트는 의 방향과는 관계가 없다. 일반적으로, BYOL의 동작이 을 에 대해 경사 하강법을 사용하는 것이라고 가정할 수 없습니다. 이는 GAN과 유사한데, 둘 다 판별자와 생성자 파라미터에 대해 동시에 최소화되는 손실이 없다. 따라서 BYOL의 파라미터가 의 최소값으로 수렴할 이유가 없다.
BYOL은 를 와 가깝게 만들어 online projection상에서 포착된 다양성을 target projection에 반영하려 한다. 이때, 를 로 hard copy해도 online projection의 다양성을 그대로 가져올 수 있다. 하지만 이럴 경우 target network가 급격하게 변하기 때문에 online network의 optimal predictor 전제 조건이 깨질 우려가 있다. 따라서 predictor의 near-optimality를 만족시키기 위해 는 와의 exponential moving average로 천천히 움직이도록 결정된다. 결론적으로 BYOL이 online network에 additional predictor를 사용함으로써 conditional variance를 줄이면서 동시에 를 moving average로 업데이트하여 predictor가 near-optimality를 유지하게 함으로써 BYOL이 collapsed representation으로 수렴하지 않는다는 것을 사고이론적으로 풀어냈다.
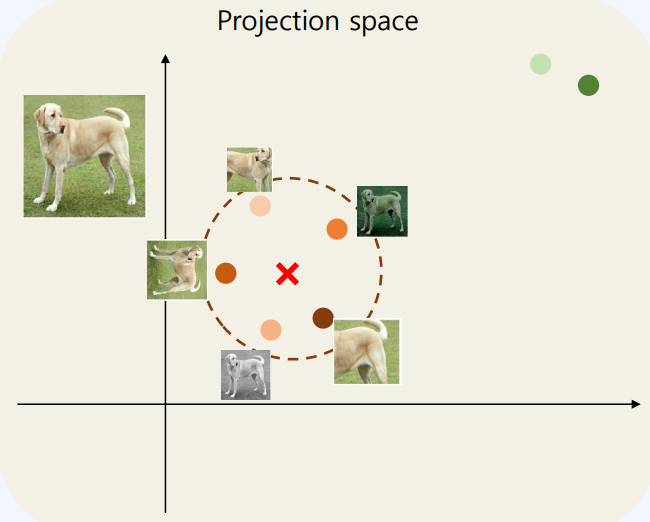
predictor는 target network의 모든 view 값을 에측하도록 학습을 진행하기 때문에 결국 target network의 모든 view의 mean 값을 예측하도록 학습한다고 볼 수 있다. Online network 입장에서는 어떤 view가 target network에 입력되는지 알 수가 없고 projection 값은 항상 다르기 때문에 collapse가 일어나지 않는다.
3.3 Implementation details
3.3.1 Image augmentations
BYOL은 SimCLR와 동일한 이미지 증강 세트를 사용하였다. 먼저, 이미지의 무작위 패치가 선택되고 horizontal flip을 무작위로 적용한 뒤 224 × 224 크기로 resize하였다. 그 다음 color distortion이 적용되며, 이는 brightness, contrast, saturation, hue adjustments, and an optional grayscale conversion이 적용된다. 마지막으로 Gaussian blur와 solarization이 패치에 적용된다.
3.3.2 Architecture
저자들은 encoder 와 로 50개의 layer를 가진 ResNet-50을 사용하였다. 또한 더 깊고(50, 101, 152, 200 레이어) 넓은(1×에서 4×까지) ResNets도 사용하였다. SimCLR와 마찬가지로, representation 는 MLP 와 에 의해 더 작은 space로 project되었다. 이 MLP는 output dimension이 4096인 linear-layer, batch norm, ReLU, 그리고 output dimension이 256인 최종 linear-layer로 구성하였다. predictor 는 와 동일한 아키텍처를 사용하였다.
3.3.3 Optimization
LARS optimizer와 cosine decay learning rate schedule을 사용하며, 1000 에포크 동안 재시작 없이 진행한다. warm-up은 10 에포크이다. learning rate를 0.2로 설정하고 배치 크기에 선형으로 스케일링한다. target network의 경우, exponential moving average 매개변수 는 에서 시작하여 훈련 중에 1로 증가된다.
4. Experimental evaluation
BYOL의 representation의 성능은 ImageNet ILSVRC-2012 dataset의 train set에서 self-supervised pretraining 후 평가하였다.
4.1 Linear evaluation on ImageNet
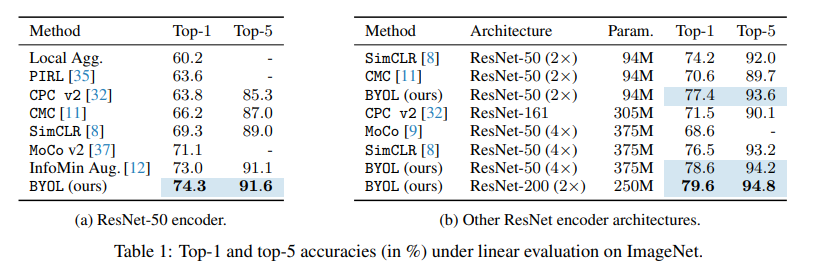
우선 BYOL linear evaluation을 위해 frozen representation 위에 linear classifier를 훈련시켜 평가하였다. Test set에서 top-1과 top-5의 accuracy를 측정하였다. ResNet-50을 사용한 BYOL은 top-1 accuracy에서 74.3%를 얻었고, 이는 이전 self-supervised learning의 최고 기록보다 1.3% 향상되었다. 이것은 self-supervised learning 학습 방식에서는 좋은 성능을 보여주었지만, 기존의 좋은 성능을 보여주는supervised learning method들보다는 현저히 낮다. 더 깊고 넓은 아키텍처를 사용할수록 BYOL은 더 좋은 성능을 보여준다.
4.2 Semi-supervised training on ImageNet
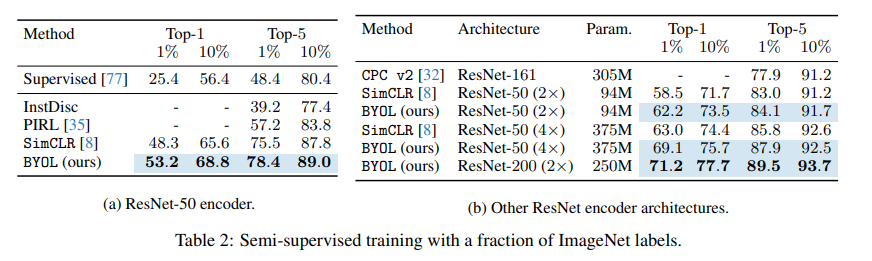
ImageNet train set의 작은 subset에서 label 정보를 사용하여 classification task에 fine-tuning하여 성능을 평가하였다. BYOL은 다양한 아키텍처에 걸쳐 이전 방법들보다 좋은 성능을 보여주었다. 또한, ImageNet 라벨의 100%를 fine-tuning할 때 ResNet-50을 사용하여 BYOL은 77.7%의 top-1 accuracy에 도달하였다.
4.3 Transfer to other lassification tasks
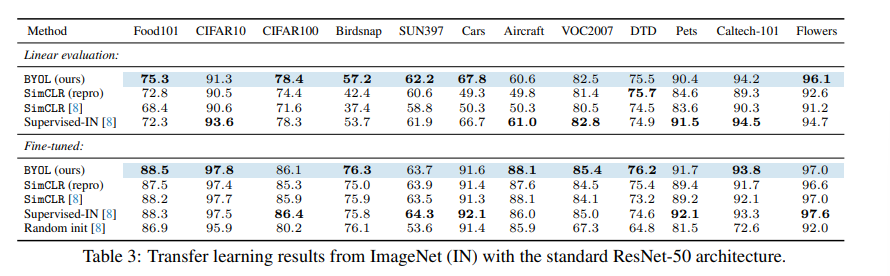
다른 classification dataset에서 평가하여 ImageNet에서 학습한 특징이 일반적인지, 아니면 ImageNet 특화된 것인지를 평가하였다. BYOL은 모든 벤치마크에서 SimCLR를 뛰어넘고, 12개의 벤치마크 중 7개에서 Supervised-IN 기준을 뛰어넘었다. 이 실험에서 의미 있는 점은 BYOL은 ImageNet dataset으로 label을 사용하지 않고 image representation을 학습한 것인데 label을 사용하여 얻은 representation과 유사하거나 더 좋은 성능을 보여준다는 것이다.
4.4 Transfer to other vision tasks
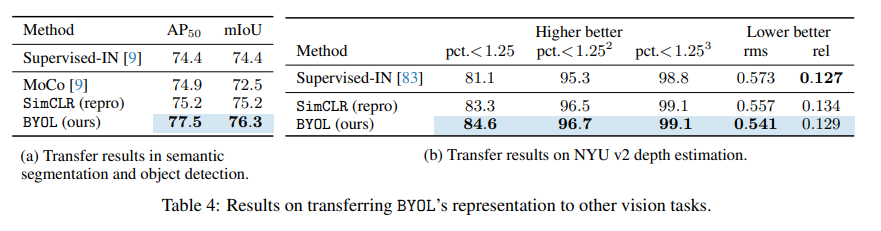
BYOL의 representaiton이 classification task 이외에도 일반화되는지 평가하기 위해, semantic segmentation, object detection, depth estimation과 같은 task에 대해서도 평가하였다. BYOL은 Supervised-IN 기준과 SimCLR 모두를 뛰어넘었다.
5.Building intuitions with ablations
5.1 Batch size
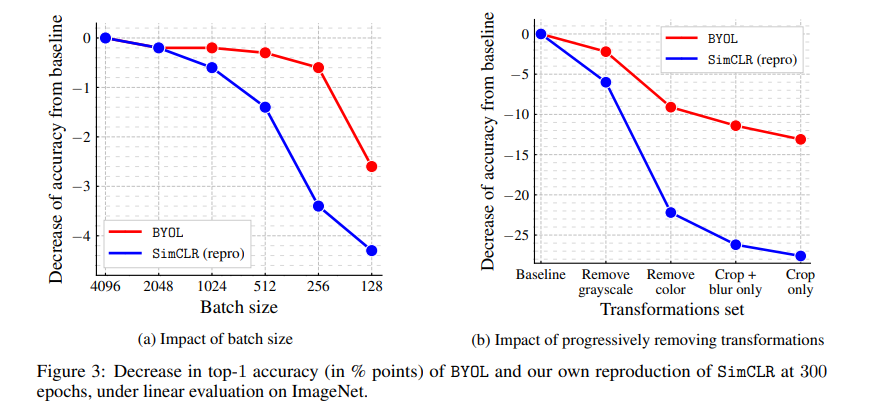
Contrastive method 중 미니배치에서 negative sample을 추출하는 방법은 그 배치 크기가 줄어들면 성능이 떨어진다. BYOL은 negative sample을 사용하지 않기 때문에 더 작은 배치 크기에 대해 더 robust할 것으로 예상된다. 저자들은 이 가설을 검증하기 위해, BYOL과 SimCLR을 128에서 4096까지 다양한 배치 크기로 훈련하였다. Fugure 3(a)에서 알 수 있듯이, SimCLR의 성능은 배치 크기가 줄어들면서 빠르게 악화된다. 이는 아마도 negative sample의 수가 감소하기 때문일 것이다. 반면에, BYOL의 성능은 256부터 4096까지 다양한 배치 크기에서 안정적으로 유지된다.
5.2 Image augmentations
Contrastive method들은 image augmentation 선택에 민감하다. SimCLR은 동일한 이미지의 crop들이 대부분 자신들의 color histogram을 공유한다. 동시에 color histogram은 이미지 간에 다양하다. 따라서 contrastive task가 image augmentation으로 random crop만 사용할 경우 color histogram만 중점적으로 해결할 수 있다. 결과적으로 representation은 color histogram 이상의 정보를 유지하지 못하게 된다. 이를 방지하기 위해 SimCLR는 color distortion을 image augmentation set에 추가한다.
BYOL은 target representation에 의해 포착된 모든 정보를 online network에 유지할 수 있기 때문에 prediction을 향상시킨다. 따라서, 동일한 이미지의 증강 된 뷰가 동일한 color histogram을 공유하더라도 BYOL은 여전히 representation에서 추가적인 특징을 유지할 수 있다.
Figure 3(b)에 제시된 결과를 보면 알 수 있다. Image augmentation set에서 color distortion을 제거할 때, BYOL의 성능은 SimCLR의 성능보다 훨씬 적게 영향을 받는다. 이미지 증강이 단순한 random crop으로 줄어들 때, BYOL은 여전히 좋은 성능을 보이는 반면에 SimCLR는 성능이 30%로 감소한다.
5.3 Bootstrapping
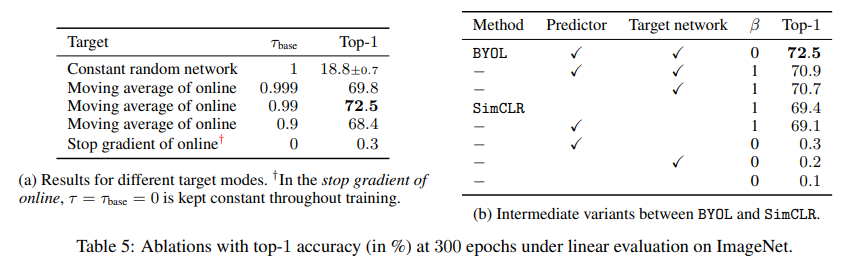
BYOL은 prediction을 위한 target으로 online network의 가중치의 exponential moving average를 사용하여 target network의 projection representation을 사용한다. 이 방식으로 target network의 가중치는 online network의 가중치보다 delay되고 더 stable하다. Target decay rate이 1일 경우, target network는 업데이트되지 않고 초기화에 해당하는 일정한 값으로 유지된다. Target decay rate이 0일 경우, target network는 각 단계에서 online network로 즉시 업데이트된다. Target을 너무 자주 업데이트하는 것과 너무 느리게 업데이트하는 것 사이에는 trade-off가 있으며, 이는 Table 5(a)에서 알 수 있다. Target network를 즉시 업데이트하는 것(τ = 0)은 훈련을 불안정하게 하여 매우 나쁜 성능을 보여주고, target를 전혀 업데이트하지 않는 것(τ = 1)은 훈련을 안정적으로 하지만 반복적인 개선을 방해하며, 결국 저품질의 최종 representation을 얻게 된다. Target decay rate이 0.9와 0.999 사이의 값일 경우 300 에폭에서 68.4% 이상의 top-1 accuracy를 보여준다.
6. Conclusion
저자들은 BYOL(Bootstrap Your Own Latent)이라는 새로운 image representation을 위한 self-supervised learning 알고리즘을 제안하였다. BYOL은 negative pair를 사용하지 않고 이전 버전의 output을 예측함으로써 representation을 학습한다. 저자들은 BYOL이 다양한 벤치마크에서 SOTA를 달성한다는 것을 보여주었다.
하지만 BYOL은 여전히 vision application에 특화된 기존의 augmentation set에 의존하고 있다. BYOL을 다른 modality(ex: 오디오, 비디오, 텍스트 등)로 일반화하려면 각각에 대해 마찬가지로 적합한 증강을 얻어야 한다. 이러한 증강을 설계하는 것은 상당한 노력과 전문성이 필요할 수 있다.
