[Paper Review] A Simple Framework for Contrastive Learning of Visual Representation
Paper Review
이번 포스트에서 리뷰할 논문은 self-supervised learning에서 contrastive learning을 적용하여 좋은 성능을 보여준 A Simple Framework for Contrastive Learning of Visual Representation(pdf)이다.
Introduction

인간의 supervision이 없이 visual represenation을 학습하는 것은 오랫동안 논의되었다. 기존의 self-supervised learing(SSL)의 경우 대부분 generative model을 이용하였다. 하지만 pixel-level generation은 representation learning에 항상 필요하지는 않을 수 있고, computational cost가 굉장히 크다는 단점이 있다. 따라서 decoder 없이 self-supervised learning을 수행하는 것이 더 효율적인 방법으로 대두 되었다.
이 논문에서는 SimCLR라는 방법론을 제시한다. SimCLR는 논문 제목에서 알 수 있듯이 다른 특별한 구조나 변화 없이 간단히 적용 가능한 방법론이고, previous work를 모두 outperform하며 supervised learning과도 유사하거나 능가하는 성능을 보여준다.
Method
Contrastive Learning Framework
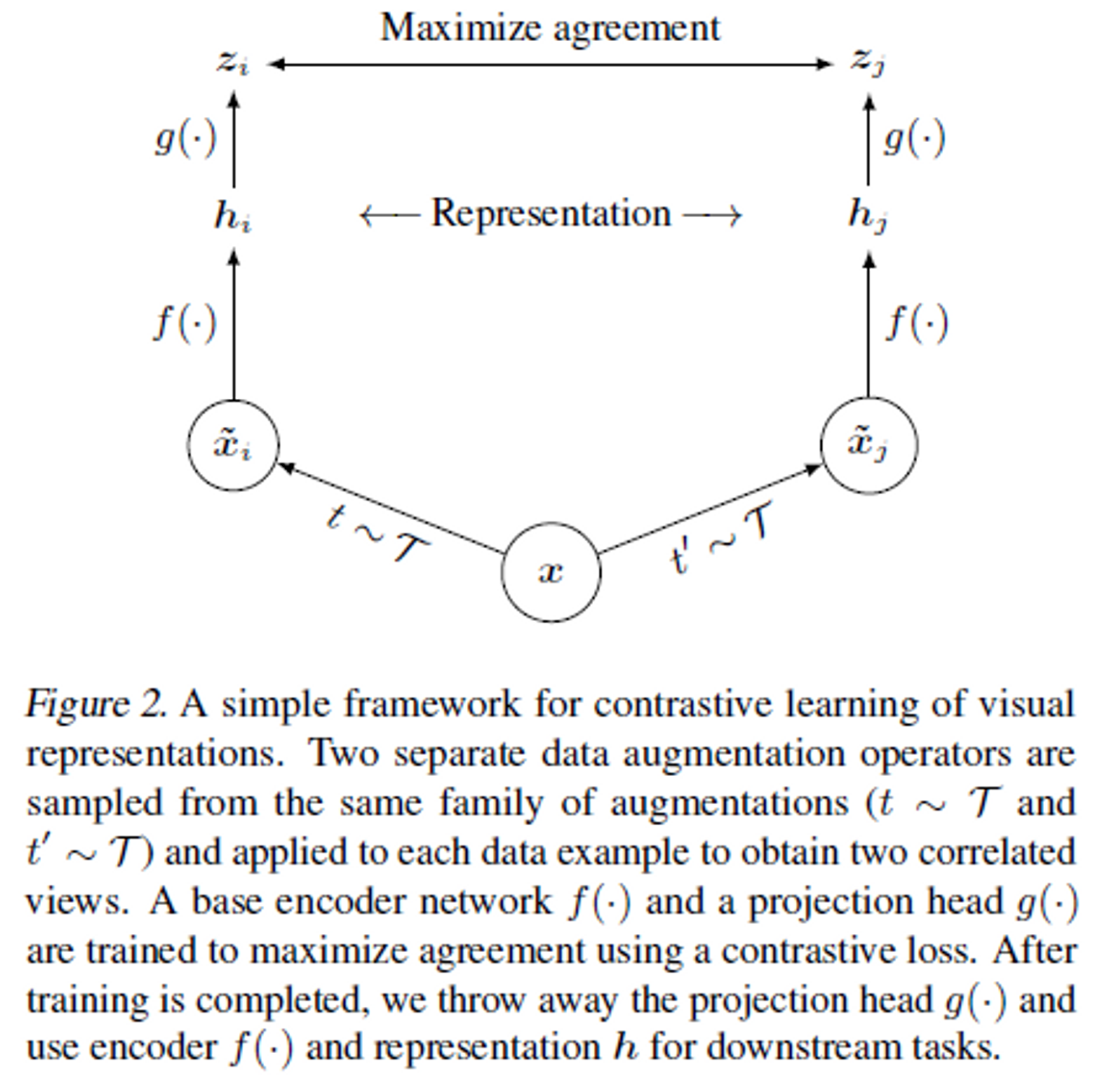
- data augmentation module을 이용하여 주어진 이미지 를 두 가지 버전의 transformed 이미지로 변환한다. 이렇게 하나의 이미지에서 transformed된 두 이미지는 positive pair이다. 본 논문에서 사용한 augmentation은 random crop and resize, random color distortion, random Gaussian blur이다.
- 하나의 이미지에서 transformed된 두 이미지 는 신경망 네트워크 에 입력으로 들어간다. 네트워크는 representation vector 를 추출한다. 본 논문에서는 신경망 네트워크로 ResNet50을 사용하였다. 는 ResNet50의 average pooling layer의 output이다.
- projection head 는 2개의 fc layer로 이루어진 MLP이다. projection head는 representation vector가 contrastive loss가 적용되는 공간으로 mapping한다. 는 projection head 의 output으로, 이다. projection head를 통해 mapping된 로 contrastive learning을 하는 것이 representation vector인 를 이용하는 것보다 성능이 좋았다.
- 동일한 이미지에서 augmentation 된 이미지 샘플은 positive sample로 정의하고, 다른 이미지에서 augmentation 된 이미지 샘플들은 negative sample로 정의한다.
- 개의 sample로 구성된 minibatch가 주어졌을 때 contrastive prediction task를 하면 data augmentation을 통해 개의 sample이 생성된다. 이때 동일 이미지에서 transformed된 2장의 이미지는 positive sample이고, 나머지 이미지는 negative sample이 된다. SimCLR는 이 방식을 통해 negative sample을 명시적으로 사용하지 않는다.
- transformation으로 이미지의 semantic information은 변화할 수 없다고 가정하면, positive sample은 동일한 latent space에 mapping되어야 하며, negative sample은 서로 먼 위치에 mapping되어야 할 것이다. 따라서 InfoNCE loss를 이용하여 SSL을 수행한다. loss function은 아래와 같다.
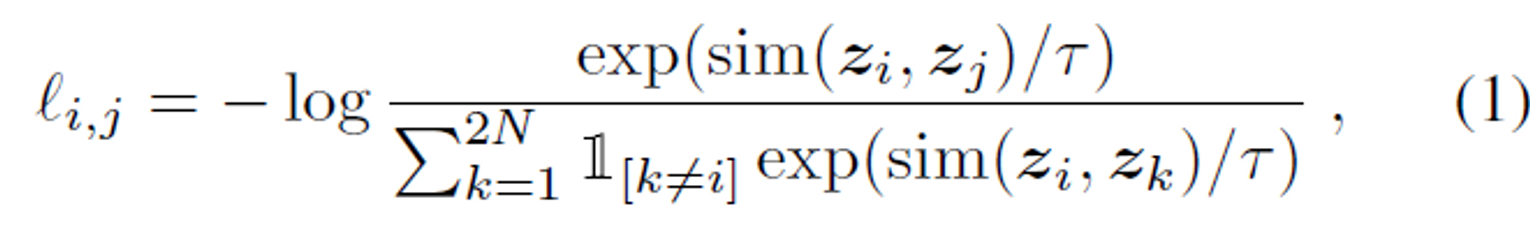
- N은 batch size를 , 는 temperature parameter를 의미한다. 밑의 sigma가 1부터 2N인 이유는, 2개의 이미지로 한 이미지를 transformation하기 때문이다. 이때 index i,j는 서로 positive sample인 이미지 샘플을 의미하고, 그 이외의 샘플은 모두 negative sample이다. 은 두 입력의 cosine similarity를 의미한다. 따라서 positive sample간의 similarity는 올라가고 negative sample간의 similarity는 낮아지도록 loss가 주어진다.
Training with Large Batch Size
- SimCLR은 memory bank를 사용하지 않고, 배치 사이즈를 통해 negative sample의 개수를 조정하였다. 본 논문에서 배치 사이즈를 256부터 8192까지 실험을 하였고, 배치 사이즈를 8192로 할 경우 16382의 negative sample을 가질 수 있다.
- 큰 배치 사이즈로 학습을 할 경우 일반적인 SGD나 Momentum optimizer를 사용하면 학습이 불안정할 수 있기 때문에 LARS optimzier를 사용하였다.
Evaluation Protocol
- 본 논문에서는 encoder network를 학습하기 위해 일반적으로 ImageNet-2012 데이터셋을 사용하였고, CIFAR-10 데이터셋도 사용하였다. 또한 성능 평가를 위해서는 다양한 종류의 데이터셋으로 transfer learning을 진행하였다.
- encoder를 통해 추출된 representation의 성능 평가를 위해 linear evaluation을 하였다. 여기서 linear evaluation은 pretraining된 encoder network를 freeze하고 뒤에 linear classifier를 추가하여 이 linear classifier만 학습하는 것이다. linear evaluation protocol은 base network의 가중치를 freeze하기 때문에 학습된 representation은 변하지 않는다. 이렇게 고정된 representation을 입력으로 사용하여 linear classifier를 학습하고, 테스트 데이터에 대한 정확도를 측정한다. 이 테스트 정확도는 학습된 표현의 품질을 평가하기 위한 지표로 사용된다. 높은 테스트 정확도는 학습된 representation이 입력 데이터의 중요한 특징을 잘 포착하고 있음을 나타낸다.
- 다음은 논문에서 사용한 default setting이다.
- data augmentation → random crop and resize, color distortion, Gaussian blur
- base network → ResNet-50
- projection head → 2-layer MLP(128-dimension)
- loss function → NT-Xent(Info NCE)
- optimizer → LARS
- batch size → 4096
- scheduler → warmup scheduler
Data Augmentation for Contrastive Representation Learning
Data augmentation defines predictive task
- data augmentation은 supervised learning과 unspervised learning representation learning에서 널리 사용되었지만, contrastive prediction task를 정의하는 체계적인 방법으로 고려되지 않았다.

- 본 논문에서는 augmentation 의 각 방법의 영향력 및 조합의 영향력에 대한 실험을 진행했다. 실험을 진행한 방법은 spatial/geometric transformation(crop, resize, rotation, cutout) 방법과 appearance transformation(color distortion, Gaussian blur, Sobel filtering) 방법이 있다. figure 4에서는 논문에서 사용한 augmentation 기법들에 대한 예시를 설명하고 있다.
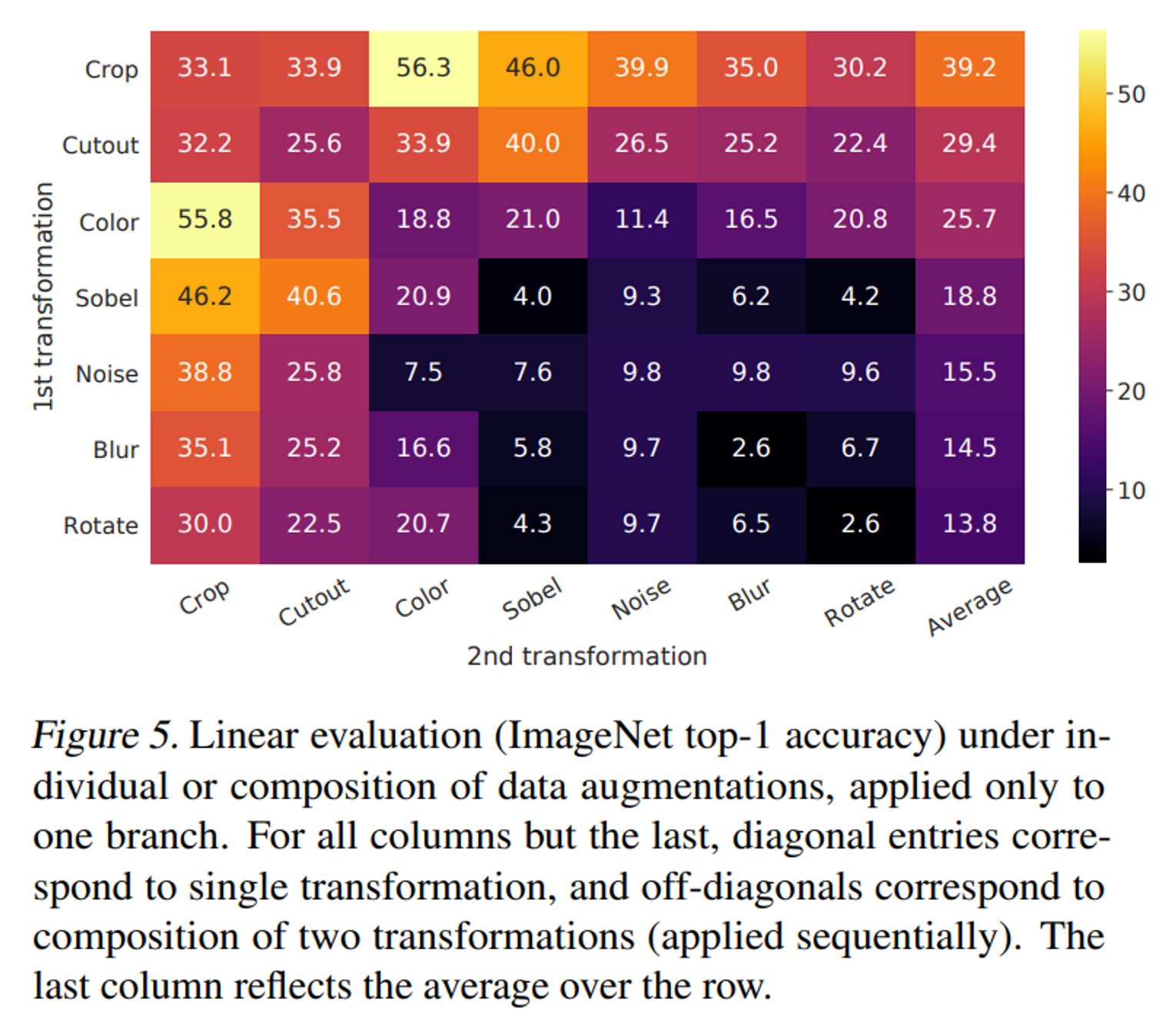
- Figure 5는 transformation의 개별적으로 또는 2가지 조합으로 적용할 때 model 의 linear evaluation 성능을 나타낸 표이다. 모델이 positive pair를 완벽하게 식별할 수 있더라도 단일 transformation으로는 좋은 representaiton을 학습하기에 충분하지 않다. 2가지 조합으로 transformation을 하였을 때 contrastive prediction task는 더 어려워지지만, representation의 품질은 크게 향상된다.
- 표를 보면 Crop과 Color jitter 를 적용했을 때 가장 성능이 높은 것을 알 수가 있다. 만약 Crop만 이미지에 적용하면 아무리 crop을 했다고 하더라도 동일한 이미지에서 추출된 샘플이기 때문에 color histogram이 거의 비슷하게 되는 문제점이 발생한다. color jitter를 이용하여 이에 대한 short cut을 막았을 때, 모델이 SSL을 제대로 이행할 수 있다. 따라서 generalizable 특징을 학습하기 위해서 crop과 color jitter를 함께 조합하는 것은 매우 중요하다.
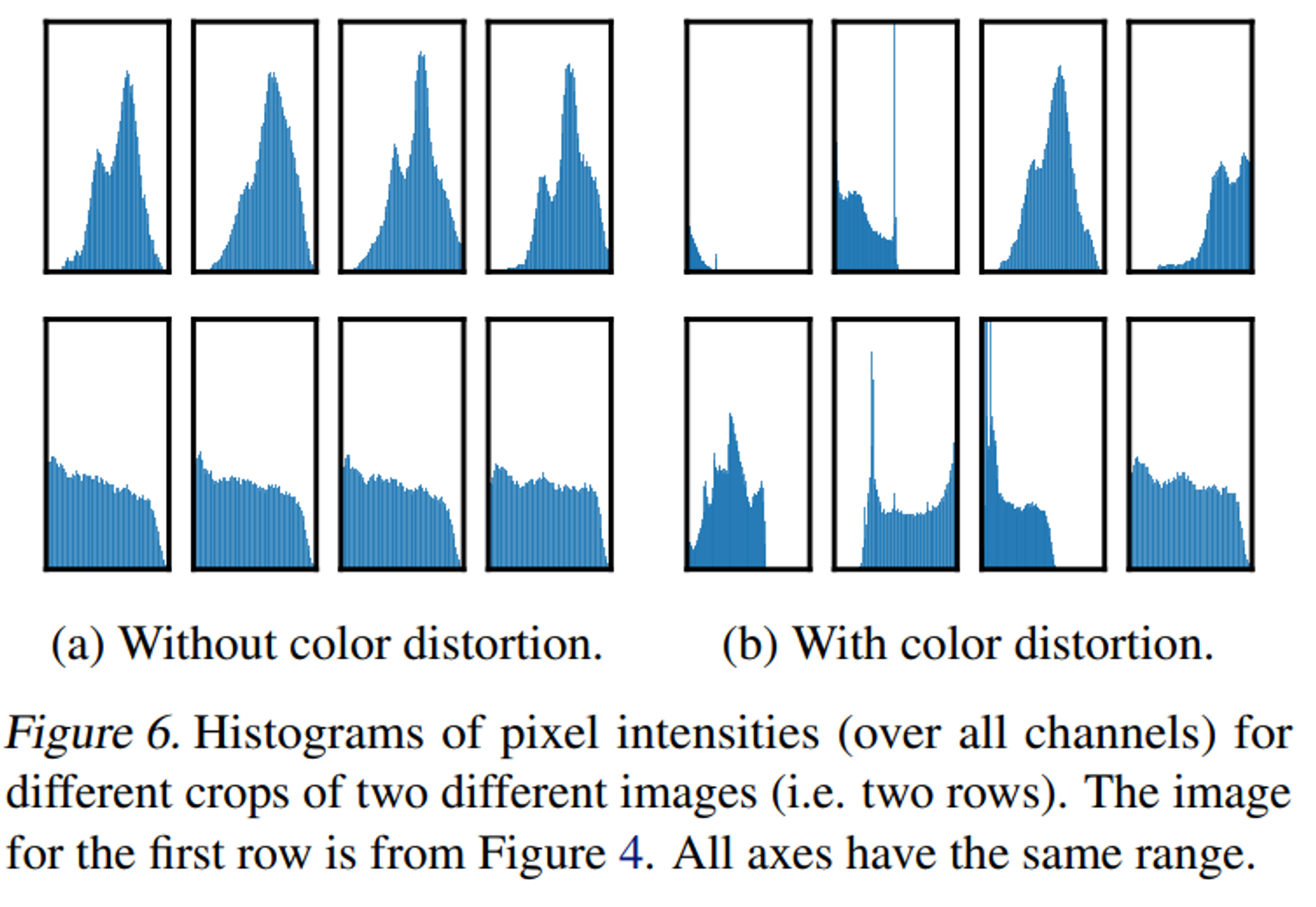
- color histogram에 대한 실험은 figure 6에 나와있다. color distortion을 적용하지 않았을 때는 동일한 이미지(동일 row에 위치한 histogram)의 histogram의 거의 동일한 것을 알 수 있는데, color distortion을 적용하면 다른 분포를 갖게 되는 것을 확인할 수 있다.
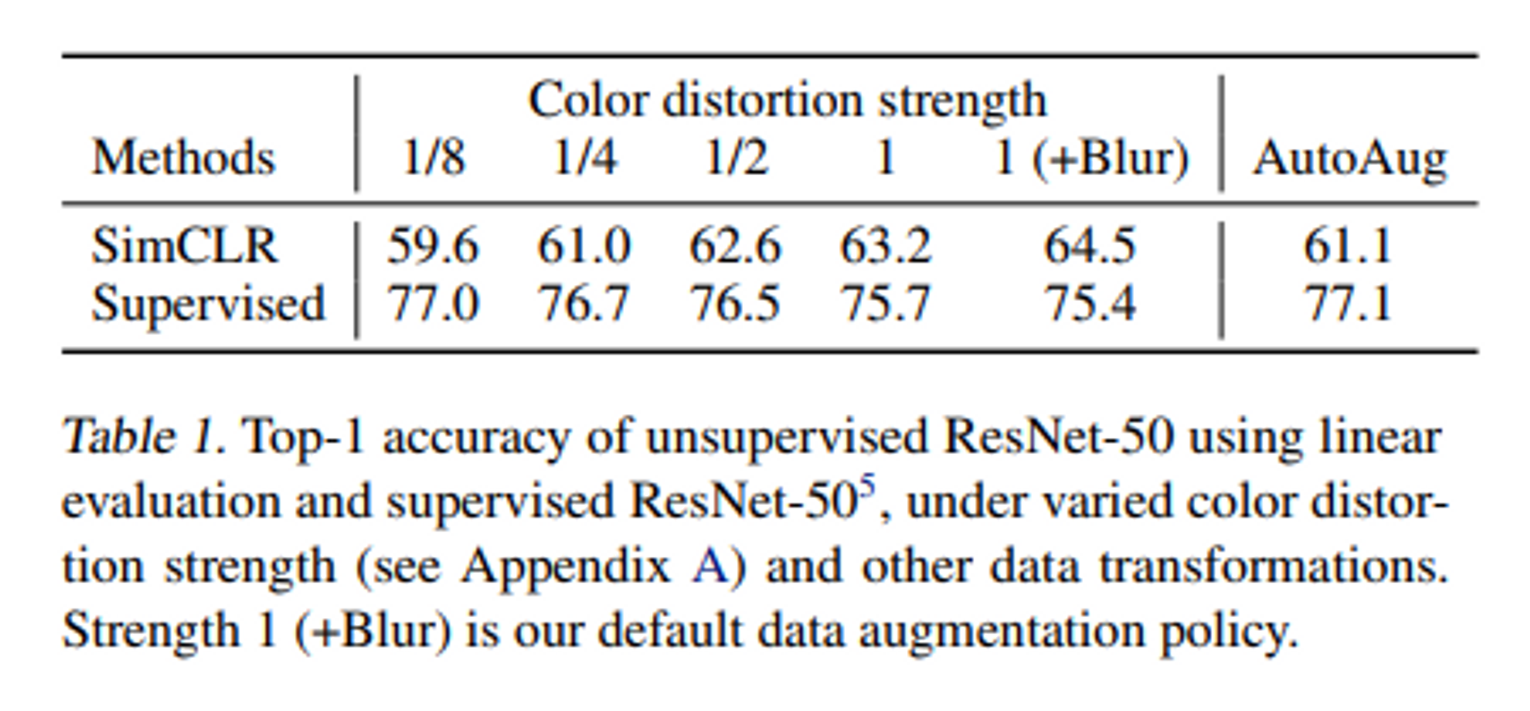
- Table 1은 더 강한 색상 증강이 unsupervised learning에서 성능을 크게 향상 시킬 수 있음을 보여준다. Table 1에서 색상 증강의 강도를 조절하여 실험을 진행하였고, 이를 통해 더 강한 색상 증강이 선형 평가에서 좋은 결과를 내고 있다. 이는 supervised learning을 통해 찾은 정교한 증강 정책인 AutoAugment보다도 간단한 자르기와 강한 색상 왜곡을 함께 사용하는 것이 더 나은 결과를 얻을 수 있다는 것을 의미한다.
- 동일한 증강을 사용하여 supervised learning 모델을 훈련 시킬 때는 강한 색상 증강이 성능을 향상 시키지 않거나 오히려 성능을 저하 시키는 것을 알 수 있다. 이는 unsupervised learning은 지도 학습보다 강한 색상 데이터 증강을 필요로 한다는 것을 나타낸다.
Architecture for Encoder and Head
Unsupervised contrastive learning benefits from bigger models
- Figure 7에서는 모델이 깊고 넓을수록 성능이 향상되는 것을 보여준다. 이는 지도학습에서도 유사하게 나타난다.
- 지도 학습 모델은 모델 크기가 커짐에 따라 성능 증가 폭이 매우 작지만, SimCLR 모델은 지도학습에 비해 성능 향상 폭이 큰 것을 알 수 있다. 따라서 지도학습보다 모델 크기에서 더 큰 이점을 얻을 수 있다.
A nonlinear projection head improves the representation quality of the layer before it
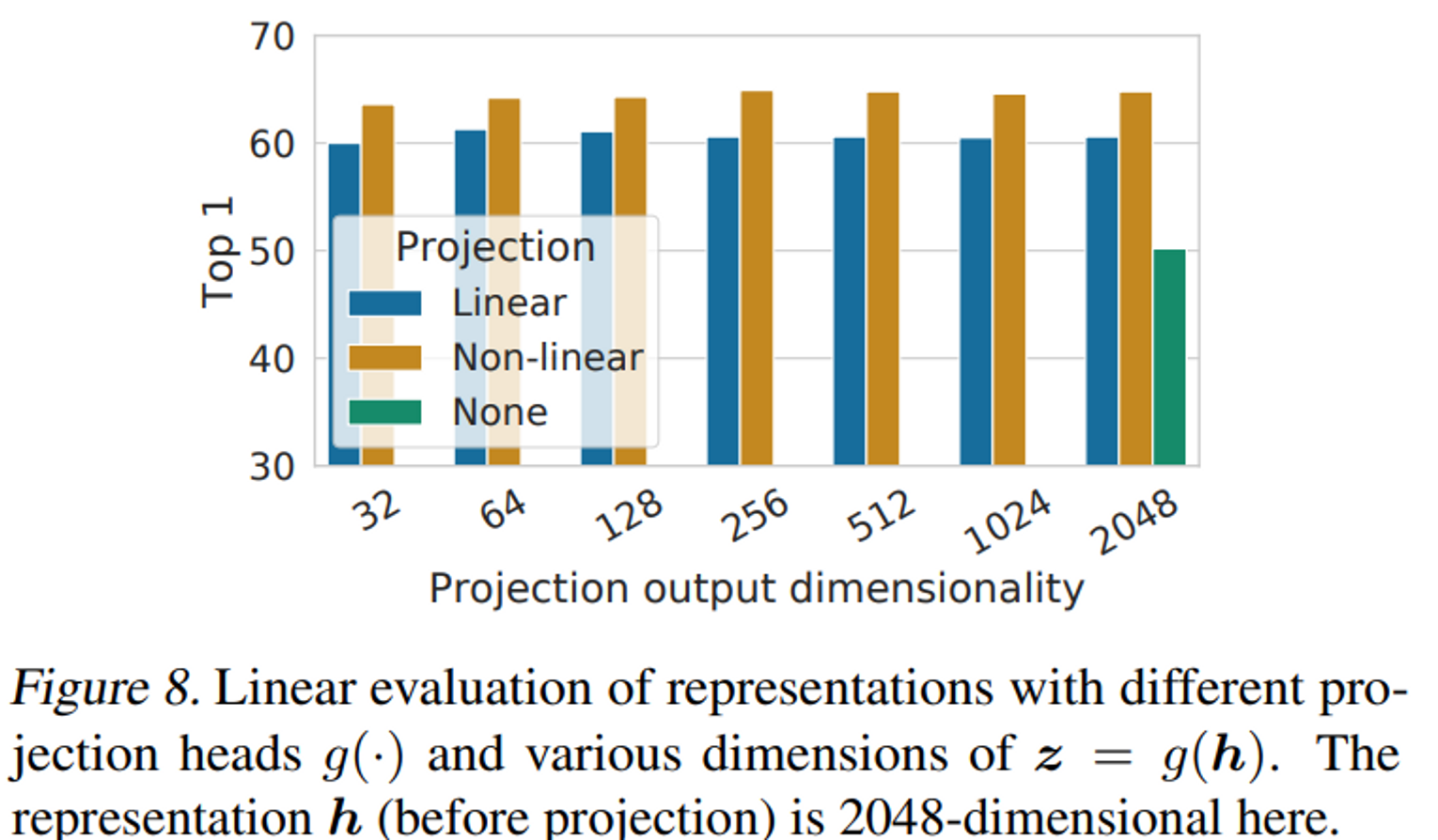
- Figure 8은 projection head에 대한 ablation study이다. 여기서 None은 identity mapping, 즉 projection head를 사용하지 않은 것이고, linear는 선형 classfier, non-linear는 2-layer mlp를 사용한 것이다. 이때 Non-linear가 가장 높은 성능을 보이는 것을 보여준다. 이때 dimension별 성능은 큰 차이가 없다는 것을 확인할 수 있다.
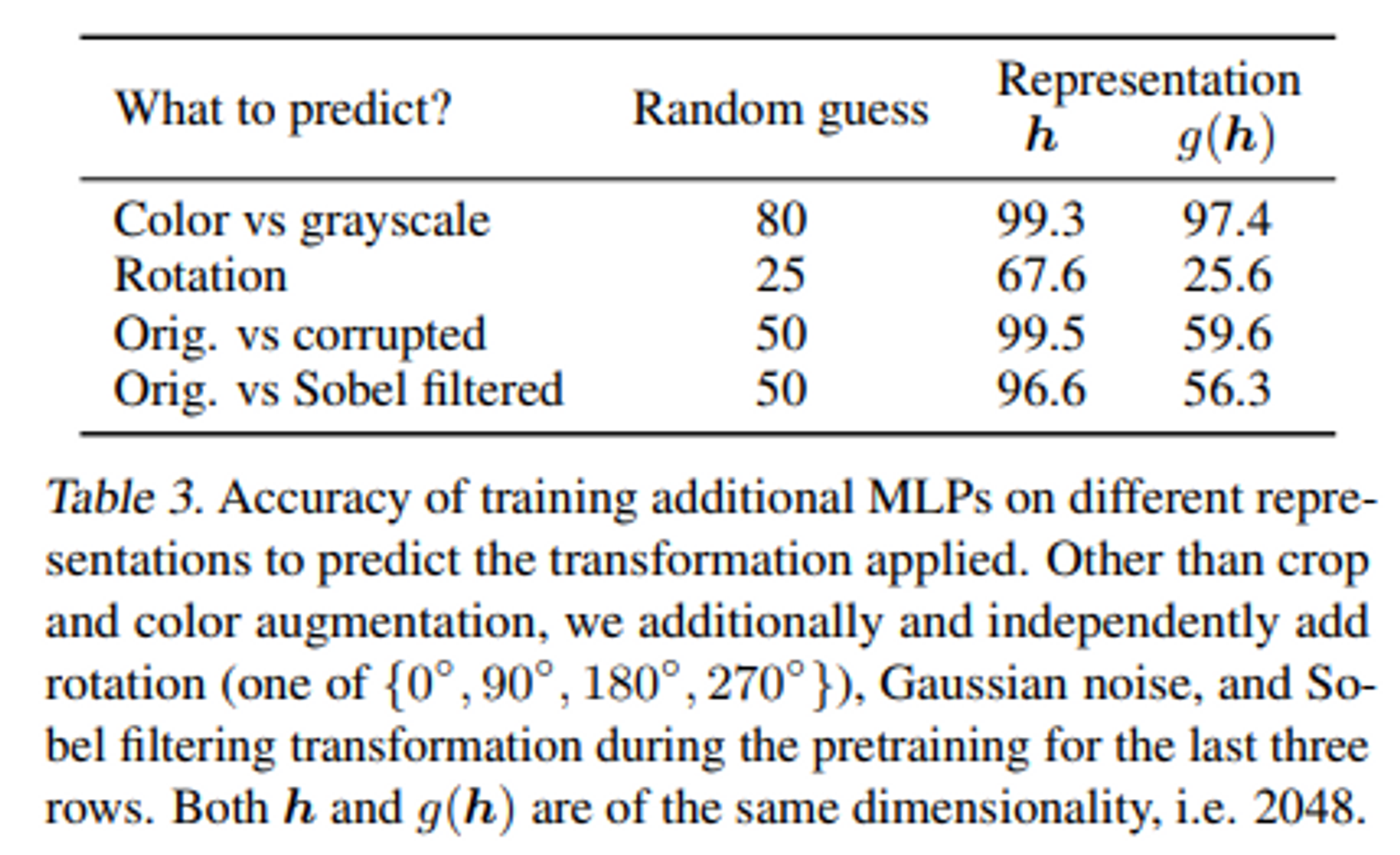
- Table 3은 projection 이전의 representation은 projection 이후의 representation보다 더 많은 정보를 가지고 있다는 것을 보여준다. 이 실험을 위해 와 뒤에 각각 FC-layer를 추가하여 실험을 진행하였다. 이때 와 모두 color, grayscale에 대한 정보는 가지고 있지만 rotation, corrupted, Sobel filtered에 대한 정보는 만 가지고 있는 것을 확인할 수 있다. SimCLR 학습을 할 때 와 가 같아지도록 학습을 하기 때문에 이 과정에서 projection head 이후의 representation은 data transformation의 정보 대부분은 사라지게 되는 것이다. 따라서 downstream task를 할 때는 더 많은 정보를 가진 를 사용하게 된다.
Loss Functions and Batch Size
Normalized cross entropy loss with adjustable temperature works better than alternatives

- 논문에서는 NT-Xent loss를 logistic loss와 margin loss와 같은 다른 일반적으로 사용되는 대조 손실 함수와 비교하였다. Table 2는 각각의 목적 함수의 손실 함수의 입력에 대한 gradient를 보여준다.
- 정규화와 temperature를 함께 사용하는 것이 다양한 sample에 효과적으로 가중치를 부여하는데 도움이 되고, 적절한 temperature는 모델이 hard negative를 판단하는데 도움을 준다.
- cross-entropy와 다르게 다른 objective function들은 negative sample에 대해 상대적 어려움에 따라 가중치를 부여하지 않는다.
Larger batch sizes and longer training
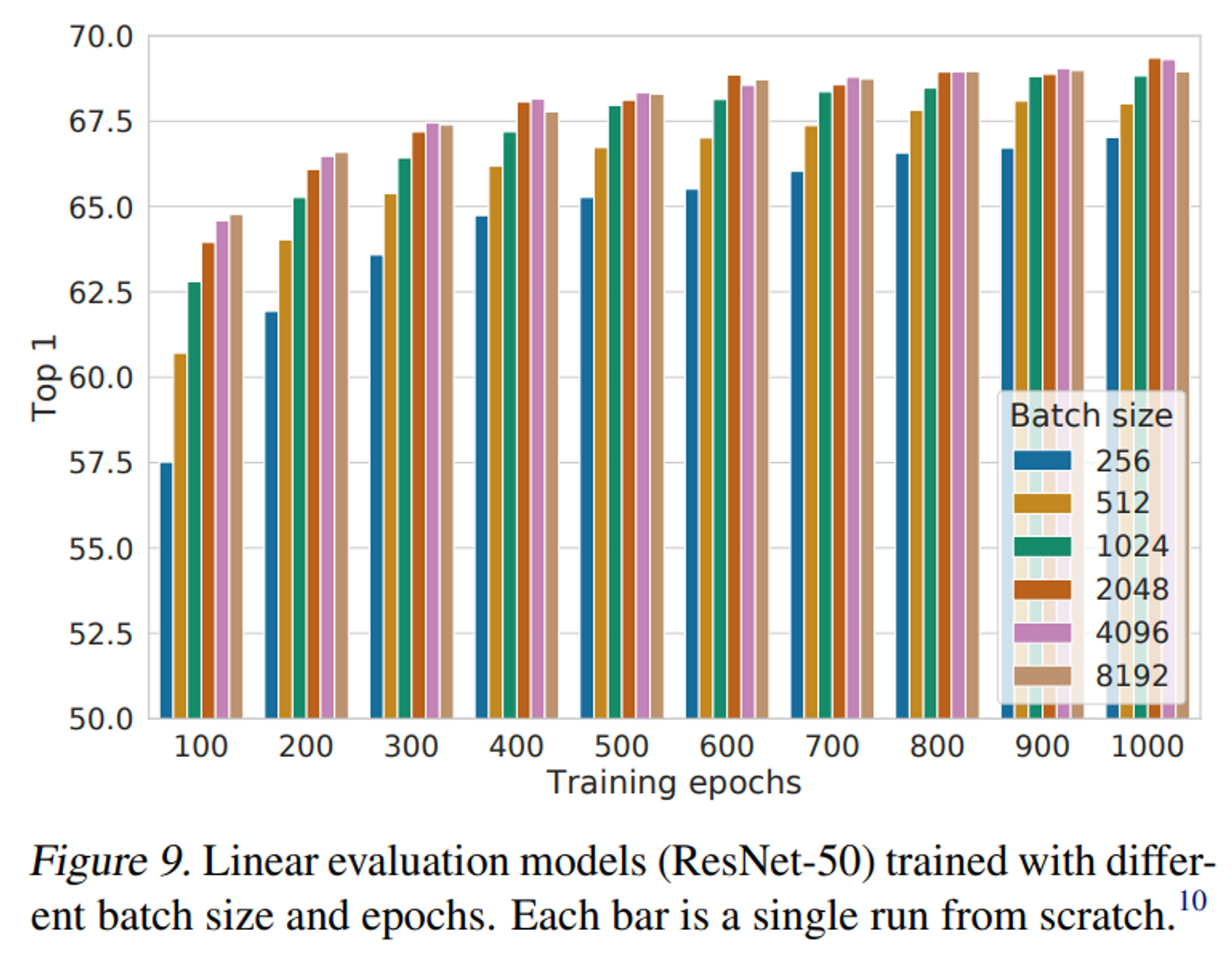
- Figure 9은 batch size가 커질 수록, traning epoch을 길게할 수록 모델의 성능이 좋아짐을 보여준다.
- batch size가 커질 수록 negative sample이 많아지기 때문에 더 다양한 이미지와의 비교를 통해서 더 유용한 정보를 학습할 수 있게 되는 것이며, ssl은 training epoch이 길어질 수록 overfitting되는 현상없이 모델의 성능이 향상되는 것을 확인할 수 있다.
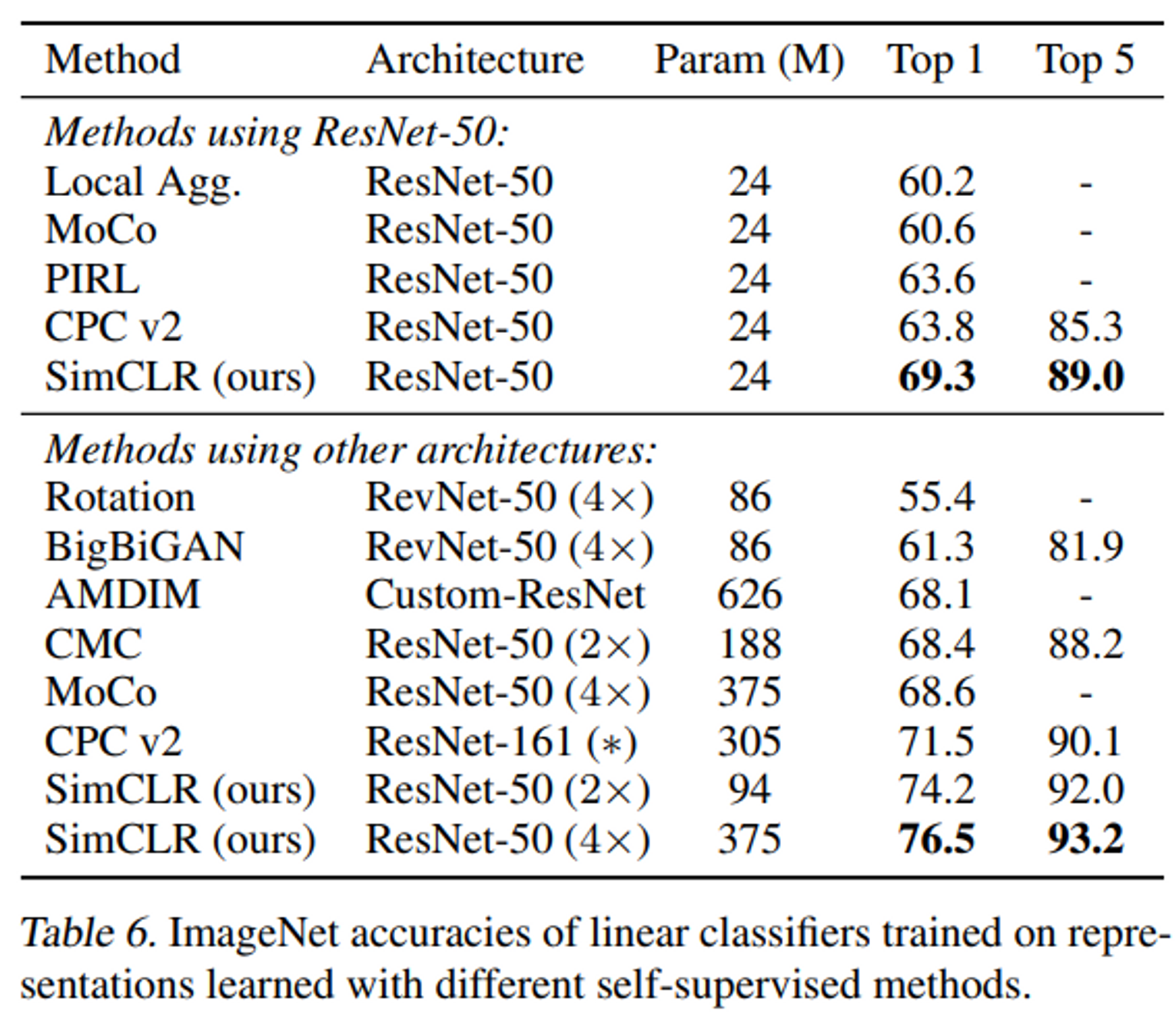
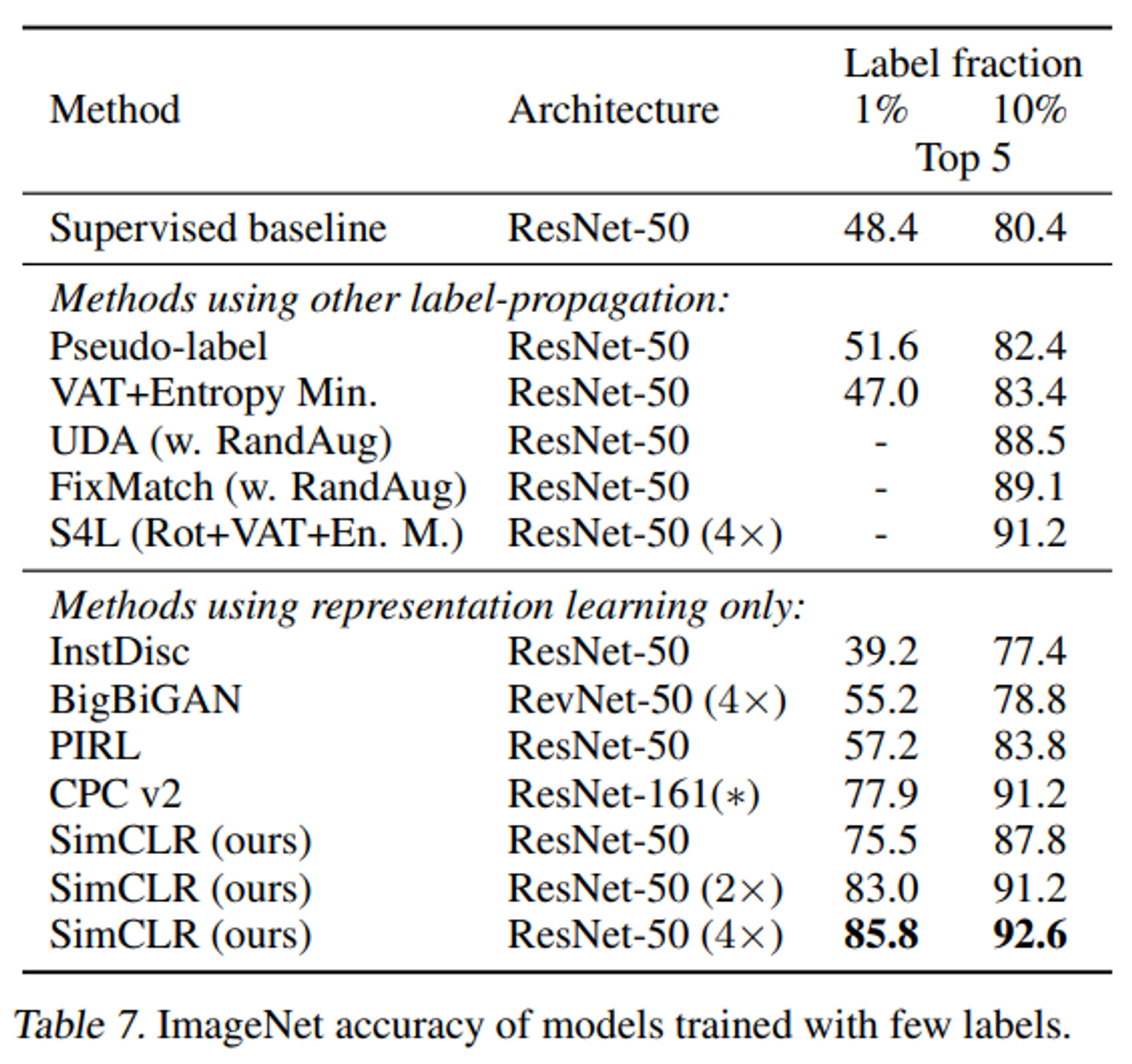
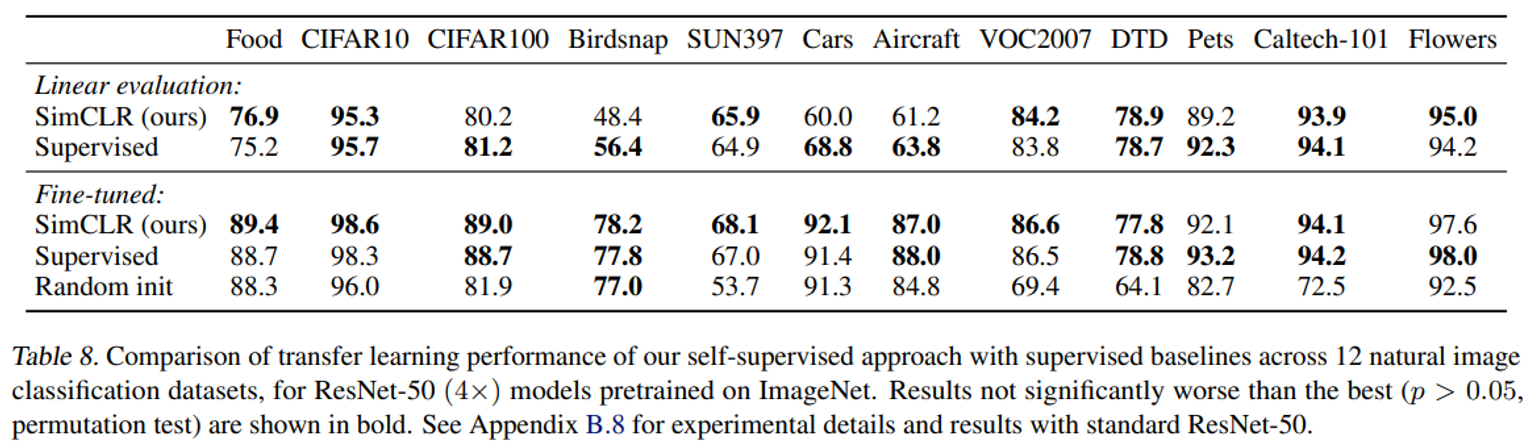
Conclusion
본 연구에서는 간단하지만 우수한 성능을 가진 SimCLR를 제시했다. 이는 많은 실험을 통해서 가장 높은 성능을 내는 방법임이 확인되었다. 또한 non linear projection head를 이용하여 모델의 성능을 대폭 향상 시켰다. 또한 self supervised contrastive learning이 첫 논문으로 기존 SSL 방법들보다 성능이 우수했다.
그러나 negative sampling에 대한 의존도가 커 큰 batch size가 필요하다는 한계가 존재한다.
