이번 포스트에서 리뷰할 논문은 self-supervised learning의 method중 SimCLR를 이용하여 medical image classification을 해결하는 Big Self-Supervised Models Advance Medical Image Classification(pdf) 논문이다. SimCLR 논문에 대해 알고 싶다면 이전 포스트를 참고하면 된다.
Introduction

Self-supervised learning(SSL)의 많은 연구가 general image domain에서 진행되고 있는데, 본 연구는 medical image domain에 SSL을 적용한 연구를 진행하였다. Self-supervised learning은 data의 label이 없이 모델을 학습가능하기 때문에, label의 cost가 비싼 의료분야에서 특히 더 강점을 드러낸다. 본 연구에서는 self-supervised learning의 방법론이 supervised learning보다 더 좋은 성능을 보여주며, ImageNet으로 학습시킨 모델을 사용하더라도 의료도메인의 task에 잘 작동하는 것을 확인했다. 이러한 결과는 domain shift에 SSL이 강점을 보여주는 것으로 해석할 수 있다.
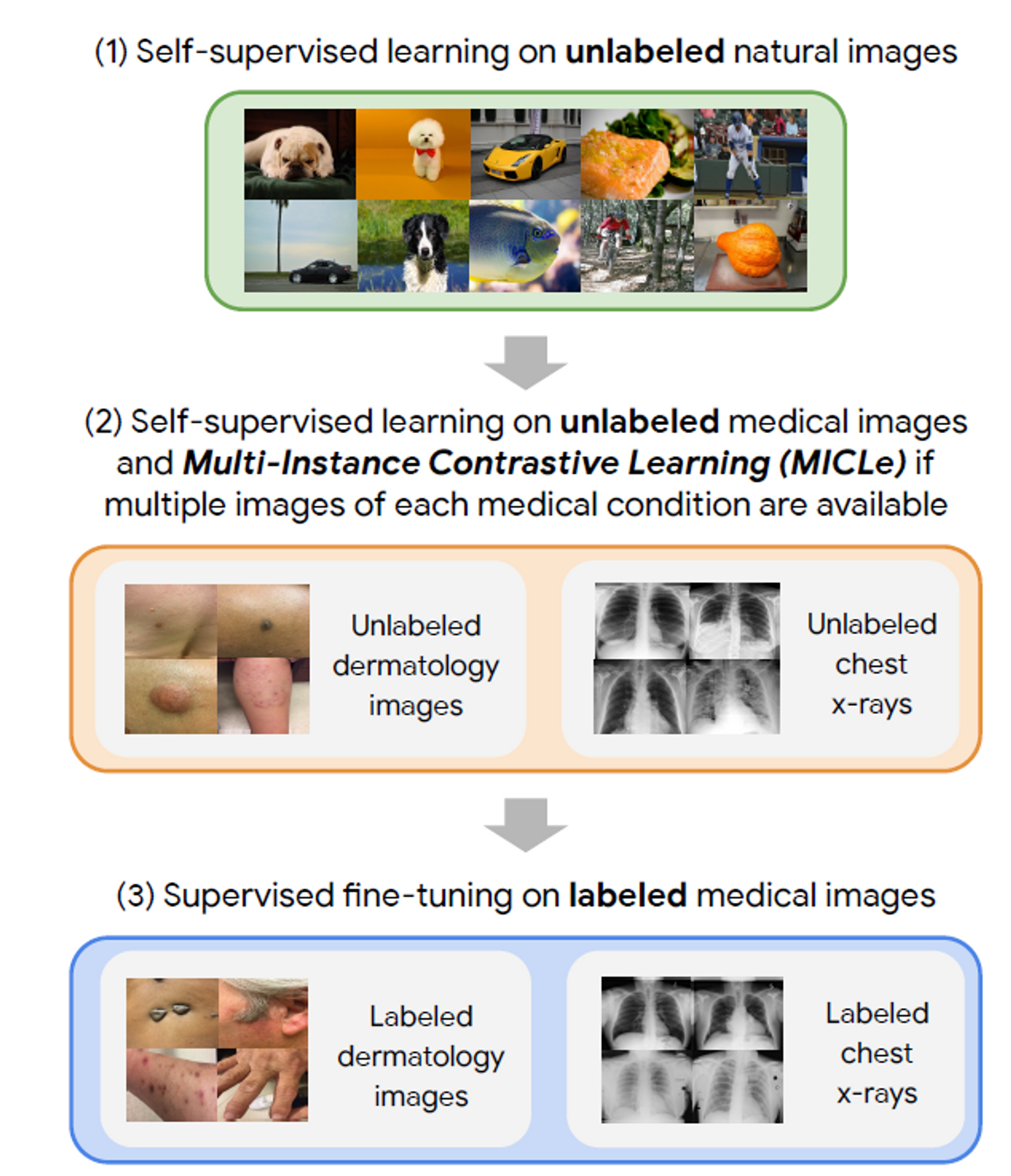
Method
본 연구는 기본적으로 InfoNCE loss를 사용하며 multi-instance가 있는 경우, MICLe loss를 사용한다.
InfoNCE loss는 아래와 같다.
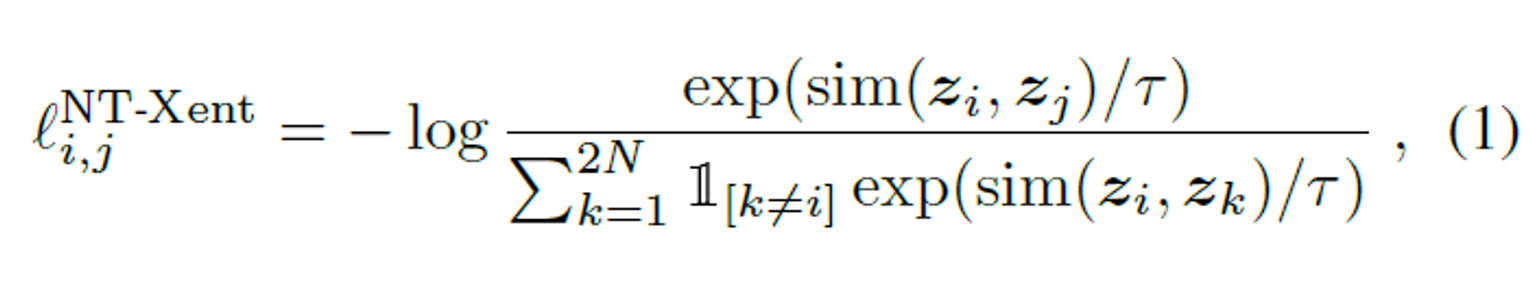
는 동일한 이미지에 transformation을 적용하여 얻은 2개의 이미지에 대한 index를 의미하며 positive sample의 index를 의미한다고 할 수 있다. 는 입력 이미지를 인코딩하여 얻게되는 latent vector 혹은 임베딩 벡터이며, 는 temperature parameter이다. 또한 은 cosine similarity를 의미한다. 위 loss를 이용해서 positive sample은 서로 다른 transformation을 적용하여도 가까운 위치의 vector로 임베딩하게되고 negative sample들은 서로 다른 위치로 멀리 떨어지도록 학습이 된다.
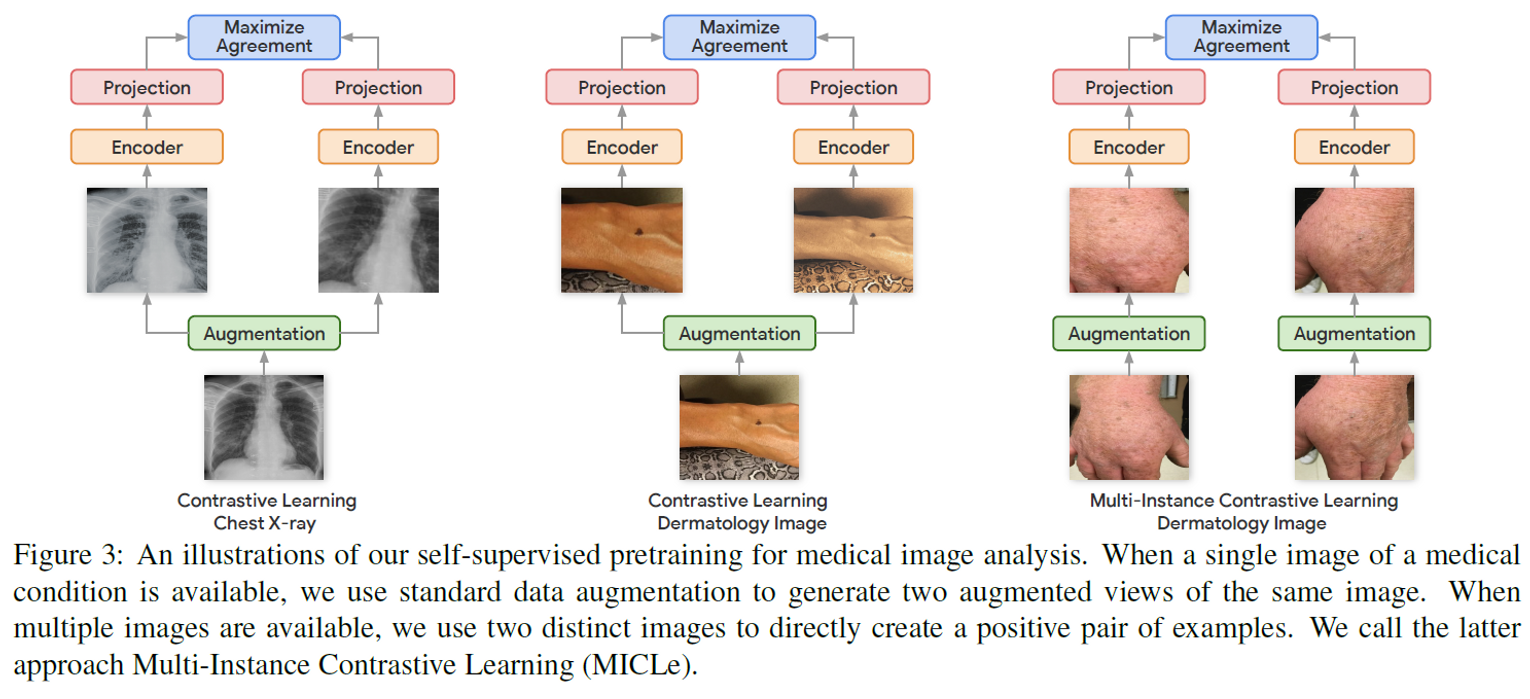
본 논문은 의료데이터를 다루는데, 의료데이터는 한 환자에 대해서 여러장의 image들이 존재하게 된다. 이러한 경우를 multi-instance 라고 하며, 본 논문은 Multi-Instance Contrastive Learning(MICLe)을 제안한다. MICLe은 수식 1의 InfoNCE loss를 사용하되, 기존의 positive sample을 동일한 이미지에서 획득된 transformed 이미지가 아닌 다른 이미지 이지만 동일한 환자에게서 획득된 이미지를 이용한다. Instance의 갯수가 2개 이상인 경우, randomly select하여 2개의 이미지를 뽑는다. pseudo code는 아래와 같다.

Dataset

본 연구에서는 Dermatology dataset과 Chest X-ray dataset을 이용하며 데이터를 위의 표와 같이 나누어 학습 및 실험을 진행한다.
Experiments
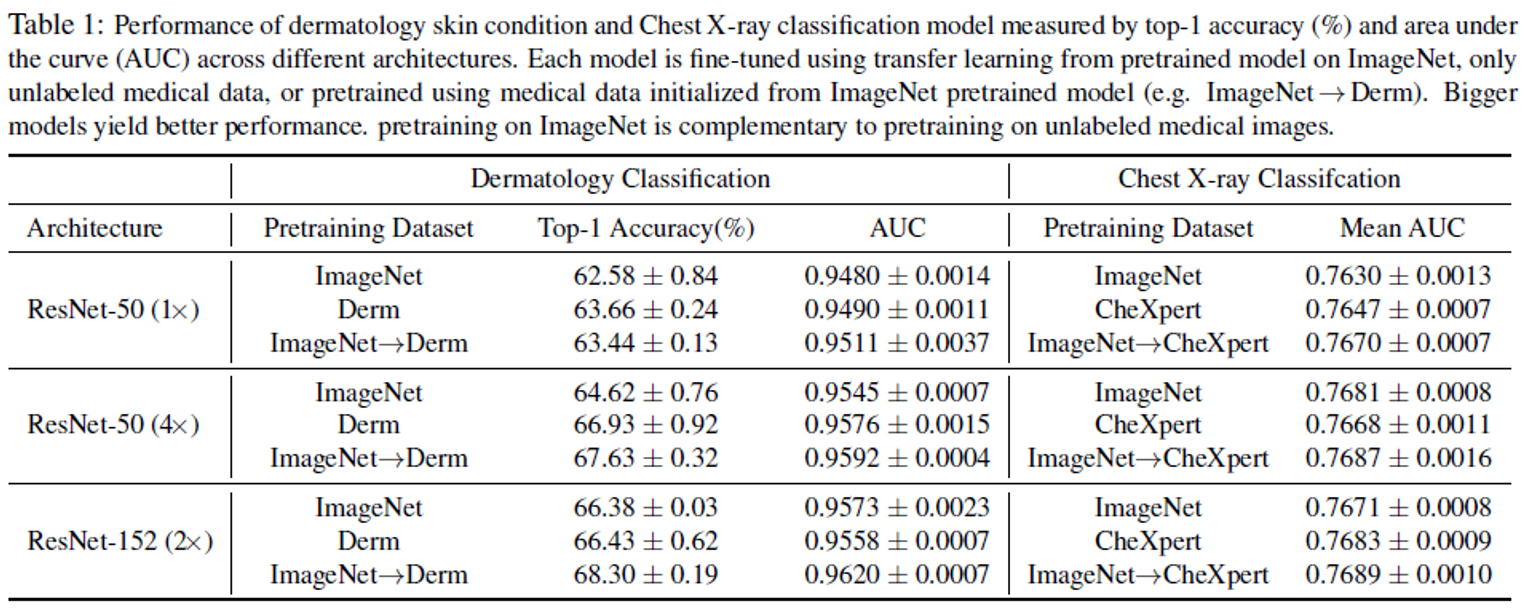
- Self-supervised learning을 진행할 때, 어떤 데이터셋을 이용하여 pretraining을 진행할지는 중요한 요소이다. Table 1은 각 데이터셋에 대해서 SSL을 진행한 후의 classification 결과이다. 본 실험은 linear evaluation을 이용한 것이 아닌, 전체 모델을 학습하였다.
- 데이터를 통해 알 수 있는 것은 target domain과 동일한 domain으로 모델을 학습한 결과가 더 좋다는 점이며, 한 단계 더 나아가, 바로 target domain의 데이터로 학습한 것보다, 대용량이지만 target domain은 아닌 데이터셋으로 학습한 후 target domain에 다시 한번 더 pretraining시킨 결과가 더 좋다는 점이다.
Effect of MICLe
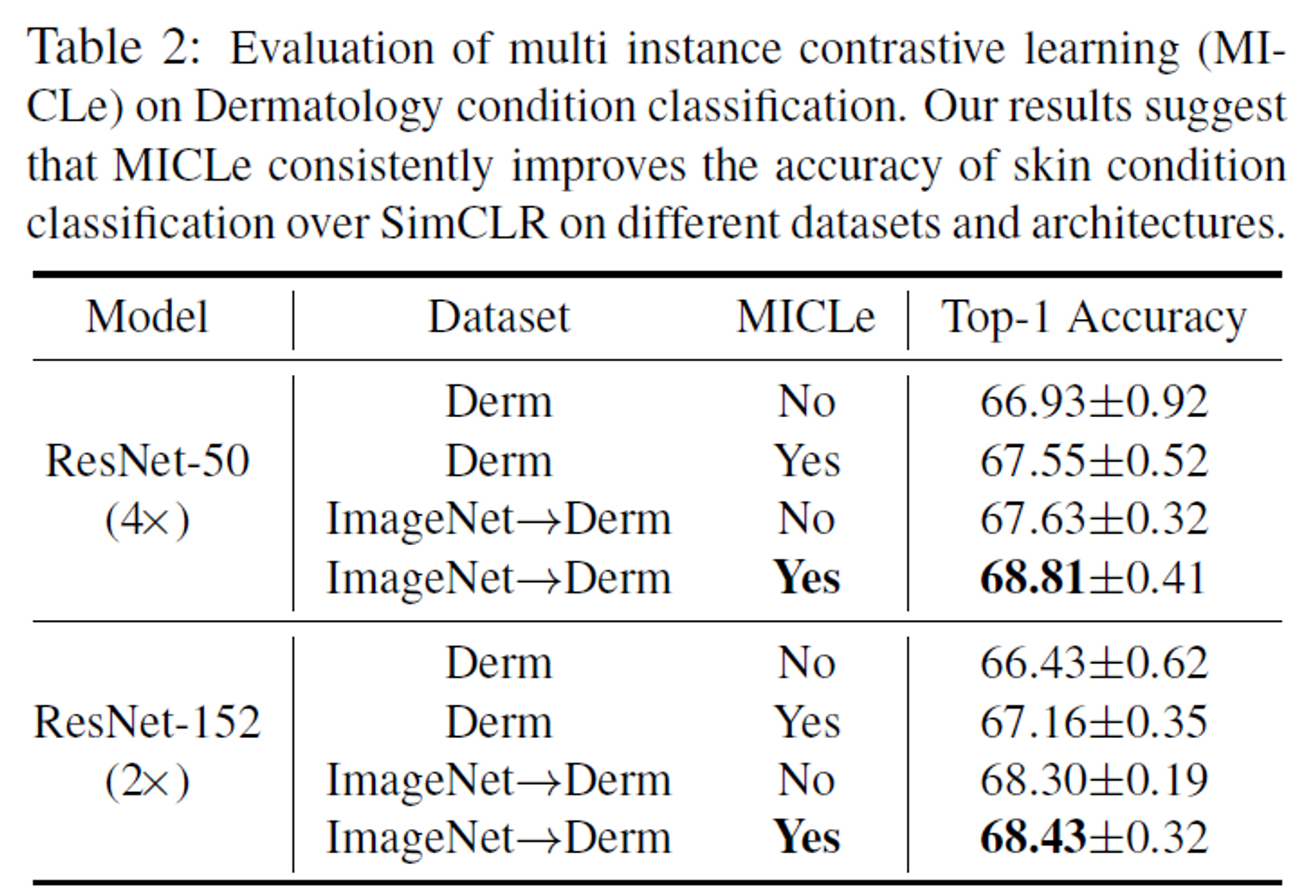
- Table 2는 MICLe의 성능을 보여준다. 데이터셋이 동일할 때, InfoNCE만을 이용한 결과보다 MICLe를 이용한 결과가 더 좋았으며, 이 것은 multi-instance가 있는 데이터를 이용할 때는, 단순히 InfoNCE만을 이용하는 것보다 존재하는 정보를 더 이용할 수록 성능이 높아지는 것을 확인할 수 있는 결과로 볼 수 있다.
- Pretraining을 진행할 때 ImageNet으로 학습한 모델보다 ImageNet으로 학습한 후 Derm으로 학습한 모델의 성능이 우수한 것을 알 수 있다. downstream task가 medical image classification이므로 동일한 domain의 데이터셋으로 학습한 pretrained weight가 더 좋은 성능을 보여준다.
Results

- Table 3와 4에서 진행한 실험은 두 타겟 데이터셋에 대해서, supervised learning과 self-supervised learning을 이용하여 모델을 pretraining 시켰을 때의 결과를 비교한 실험이다.
- 두 데이터셋에 대한 실험 모두에서, self-supervised learning의 결과가 더 좋은 성능을 보였다.
- 이것은 supervised learning보다 self-supervised learning을 이용하였을 때, label 의 정보 이상의 더 generalized된 정보를 학습하게 되는 것으로 이해할 수 있다.
Conclusion
본 논문은 target domain과 다른 domain의 데이터셋이라도 사이즈가 큰 데이터셋은 모델의 성능 향상에 도움을 주는 것을 확인하였으며, pretraining을 진행할 때는, supervised learning보다 self-supervised learning으로 학습한 모델이 더 generalization이 잘되는 것을 확인할 수 있었다. 또한 의료데이터셋과 같은 특성의 데이터셋은 multi-instance가 존재하기 때문에 이에 대한 정보를 이용할 때 더 좋은 성능의 모델로 학습을 진행할 수 있다는 것을 실험적으로 증명했으며 그에 대한 loss인 MICLe을 본 논문은 제시한다.

정리가 잘 된 글이네요. 도움이 됐습니다.