Socket
클라이언트 프로세스와 서버 프로세스 간의 통신이다. 사용자와 애플리케이션 개발자는 프로세스의 실제 내부를 알지도 못하고 건드리지 못한다. 따라서 OS에서 제공하는 interface를 사용해야한다.
예를 들어 모니터에 무언가 display하고 싶다면 무언가 프로그램을 만들어 메세지를 적어줘야한다.
마찬가지로 네트워크 관점에서 다른 프로세스에게 메세지를 보내고 싶으면 그거에 맞는 interface에 메세지를 적어주면 이게 전달되는 것이다. 어떻게 보면 OS가 제공해주는 API의 일종이고 이를 Socket이라 부른다.
결국 OS가 제공해주는 기능을 사용하기 때문에 OS내부에 구현되어 있는 것만 사용할 수 있다. OS 내부에는 applcation layer 하위 계층들이 구현되어있다. 결국 application layer와 OS간의 interface이고, 아래에는 바로 transport layer이므로 transport layer가 제공하는 것밖에 사용할 수 없다. transport layer가 TCP와 UDP 두개이기 때문에 application 프로세스가 어쩔 수 없이 socket을 사용하되 TCP socket을 사용하든, UDP socket을 사용하든 둘 중에 하나밖에 고를 수 없다. TCP를 사용하고 싶다면 TCP socket을 사용해서 데이터를 보내야한다.
즉, socket을 사용할 때 종류 자체가 다른것이다.
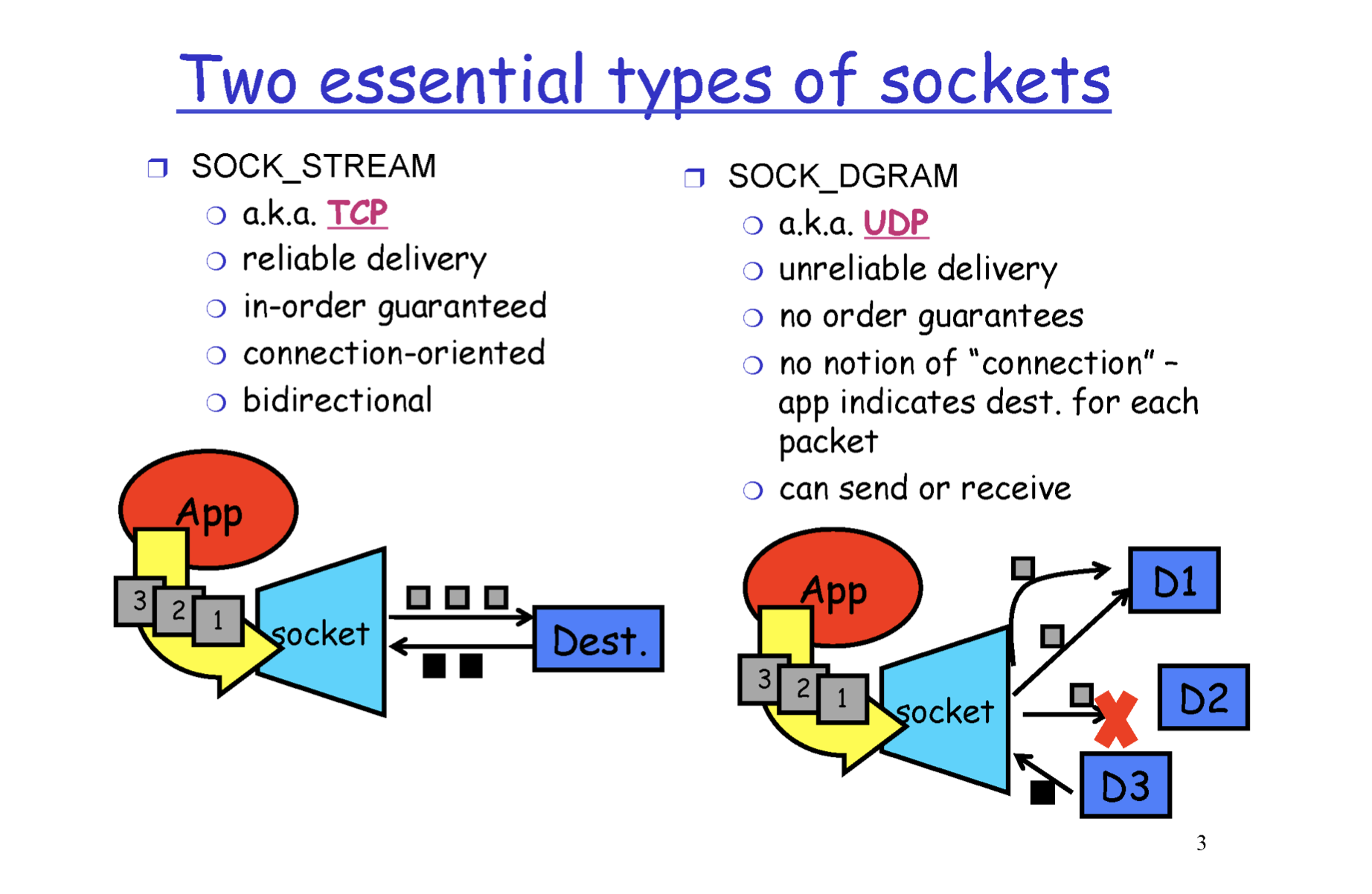
Socket API
web client와 web server의 통신을 보자
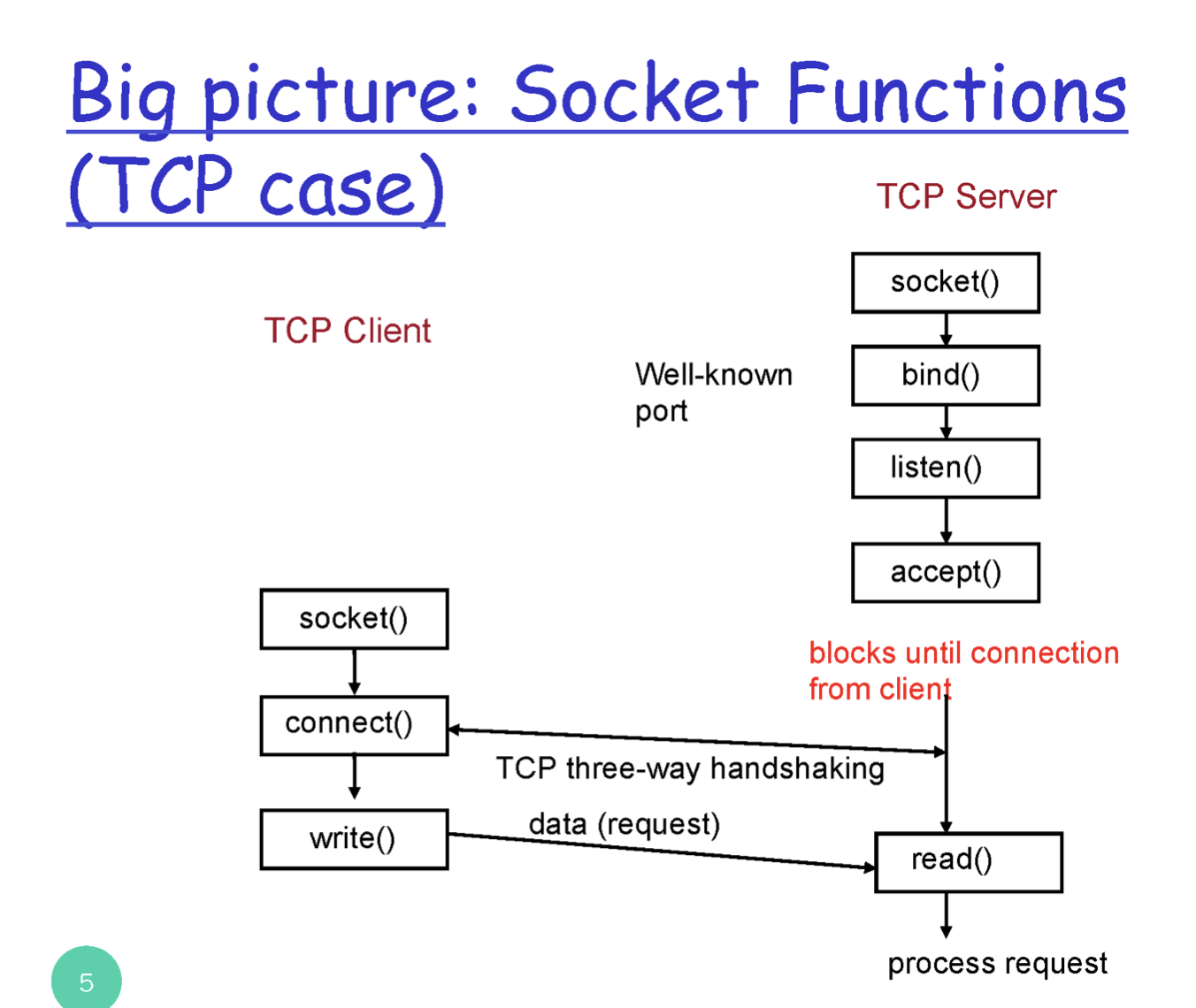
- 웹 서버가 socket을 생성해서 연다. => TCP socket
- bind() : 방금 생성한 socket을 특정 PORT에 바인딩하는 것
- listen() : 생성한 socket을 listen의 용도로 사용하겠다고 하는 것 => server 이기 때문
- accept() : 나는 client로 부터 요청을 받을 준비가 되었으니 들어와라 하는 것
여기까지 하면 server는 client로부터 connection이 들어올 때 까지 block된다.
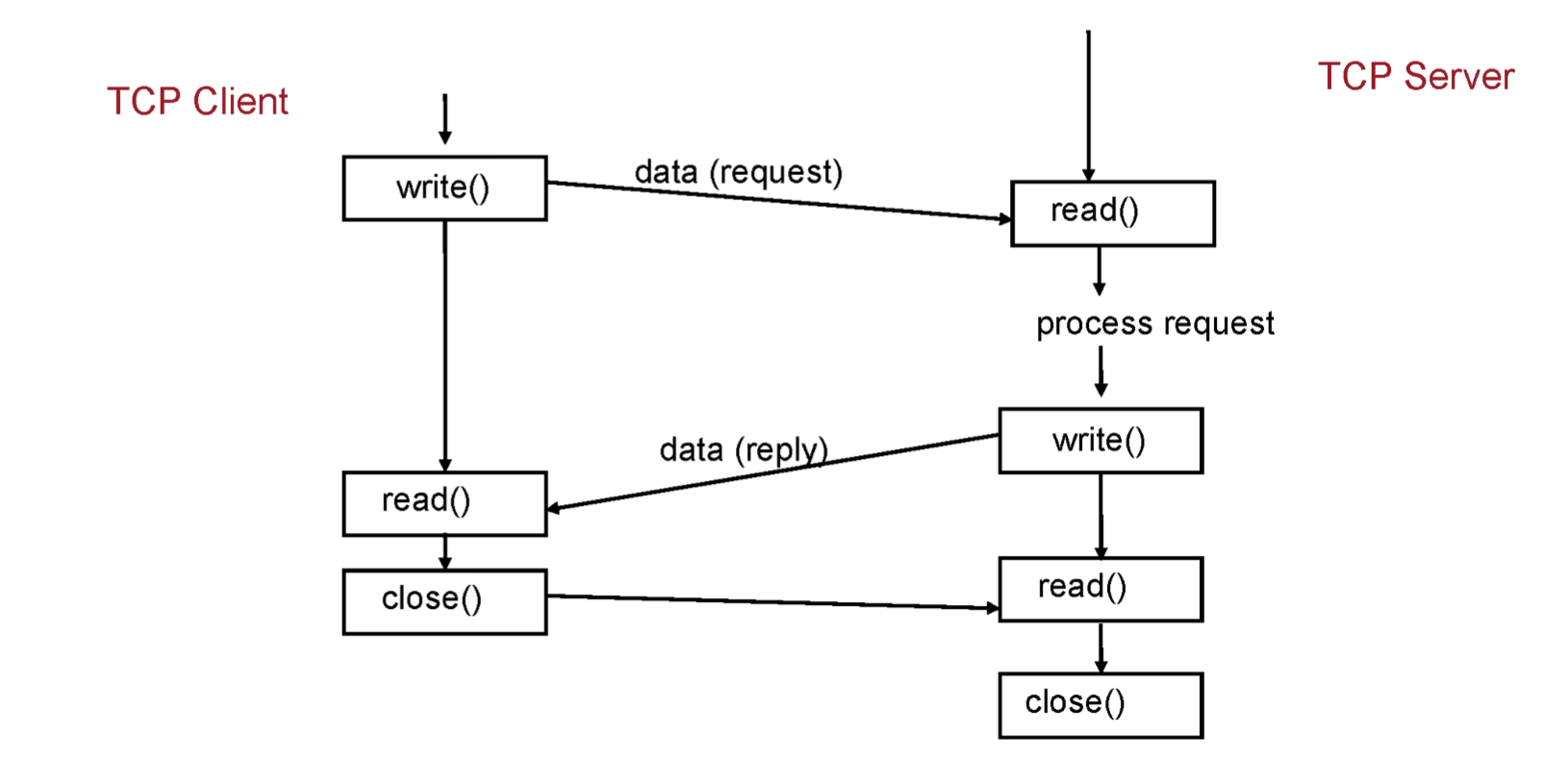
클라이언트도 마찬가지로 socket을 생성하고 server와 연결을 한다. 이렇게 되면 client와 server사이에 연결고리가 생성되는 것이다. 이 이후로는 read(), write()로 통신을 하면 된다.
Creation and Setup
이제 코드를 살펴보자
socket 생성

int socket (int domain, int type, int protocol);
Returns file descriptor or -1. => sockfd를 반환한다.
2nd parameter에 따라 어떤 socket이 만들어질지 정해진다.
socket이 성공적으로 생성되면 return 값으로 방금 생성한 socket의 ID, index, fd라고 불리는 값이 반환된다. 이 값으로 socket을 계속 지칭할 것이다.
bind
socket을 특정 address에 binding 하겠다하는 것이다.

int bind (int sockfd, struct sockaddr* myaddr, int addrlen);
1st parameter는 위에서 socket을 생성하고 반환받은 file descriptor이다.
listen
listen 용도로 사용할 것이고, 동시에 request가 들어온다면 최대 backlog까지 큐에 넣어 놓고 처리한다는 것이다.

accept
다 준비 동작이 끝났으니 client로부터 연결을 기다리겠다는 것이다.

int accept (int sockid, struct sockaddr* cliaddr, int* addrlen);
block하고 있다가 클라이언트의 요청이 오면 수행이 되면서 return이 된다. return될 때 cliaddr에 클라이언트의 IP주소와 PORT number가 담긴다.
- Returns file descriptor or -1.
Establishing a Connection
connect
connect의 paramter에는 당연히 연결할 서버의 주소가 들어갈 것이다.

최종적으로 아래와 같이 준비를 하는 것이다.
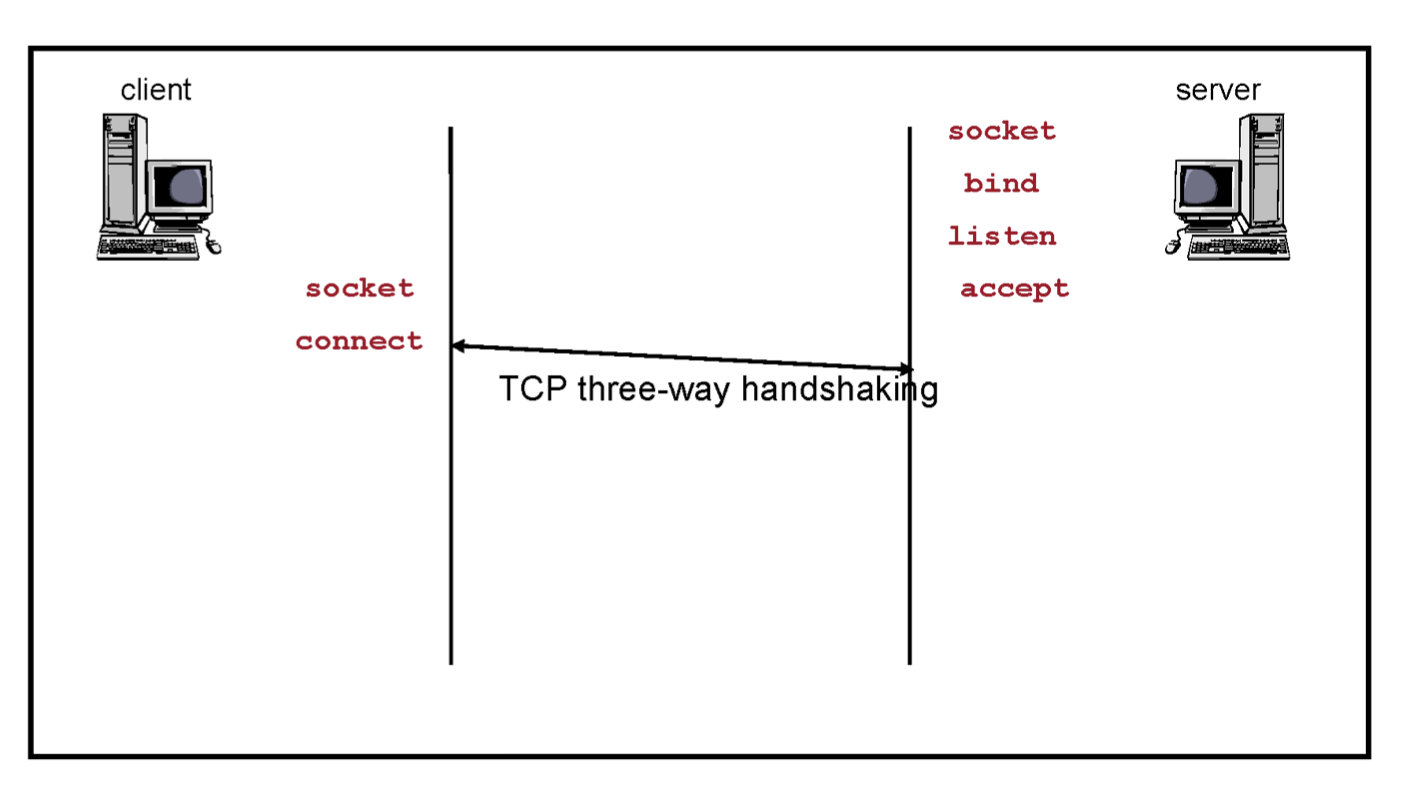
그런데 클라이언트에는 왜 bind를 사용하지 않는 것일까? bind라는 것은 socket을 특정 address에 binding 하겠다는 것인데 클라이언트는 특정 PORT에 바인딩할 필요가 없다. 아무거나 써도 되기 때문이다. 서버는 굳이 80번을 써야되니까 80번을 바인드해야한다.
server의 sample code는 아래와 같다.
#include <stdio.h>
#include <stdlib.h>
#include <errno.h>
#include <string.h›
#include <sys/types.h>
#include <netinet/in.h>
#include <sys/socket.h>
#include <sys/wait.h>
#define PORT 3490
#define BACKLOG 10 //how many pending connections queue will hold
main ()
{
int sockfd, new_fd; //listen on sock_fd, new connection on new fd
struct sockaddr_in my_addr; /* my address */
struct sockaddr_in their_addr; /* connector addr */
int sin_size;
if ((sockfd = socket(PF_INET, SOCK_STREAM, 0))==-1){
perror ("socket") ;
exit (1);
}
my_addr.sin_family = AF_INET;
my_addr.sin_port = htons (MYPORT); /* short, network byte order */
my_addr.sin_addr.s_addr = htonl (INADDR_ANY);
/* INADDR_ANY allows clients to connect to any one of the host's IP address * /
if (bind(sockid, (struct sockaddr *) &my_addr, sizeof (struct sockaddr)) == -1) {
perror ("bind") ;
exit (1);
}
if (listen (sockfd, BACKLOG) == -1) {
perror ("listen") ;
exit(1) ;
}
while(1) { / * main accept() loop */
sin_size = sizeof (struct sockaddr_in) ;
if((new_fd = accept (sockfd, (struct sockaddr*) &their_addr,&sin_size)) == -1) {
perror("accept");
continue;
}
printf("server: got connection from %s\n",inet_ntoa(their_addr.sin_addr)) ;
}client의 sample code는 아래와 같다.
if ((sockfd = socket (PE_INEI, SOCK_STREAM, 0)) == -1) {
perror ("socket");
exit (3);
}
their_addr.sin_family = AF_INET;
their_addr.sin_port = htons (Server_Portnumber);
their_addr.sin_addr = htonl (Server_IP_address);
if (connect (sockfd, (struct sockaddr*) &their_addr, sizeof(structsockaddr))==-1) {
perror("connect");
exit(1);
}Sending and Receiving Data
write

read

UDP의 socket 함수는 아래와 같다. 굉장히 간단한 것을 볼 수 있다.
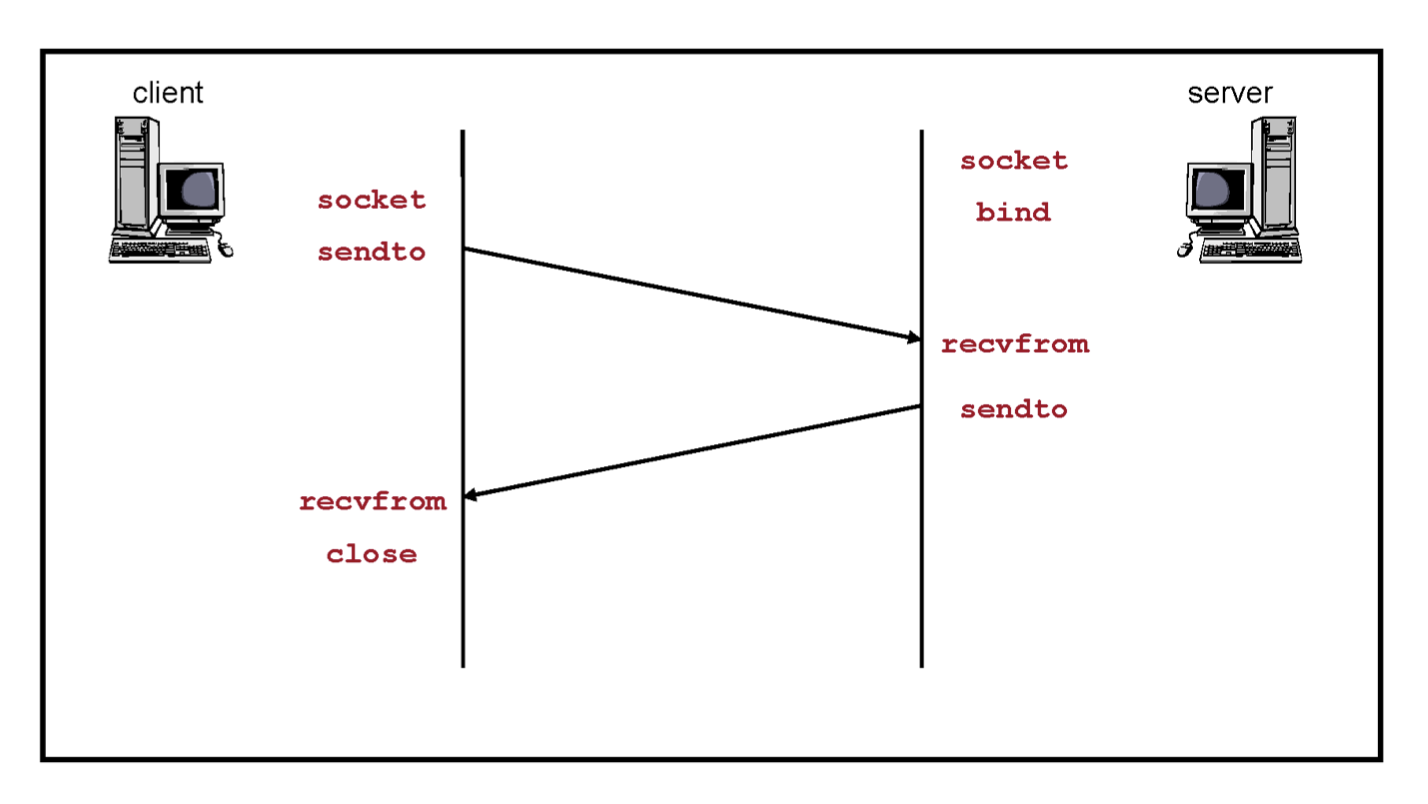
Tearing Down a Connection
close
지금까지 사용했던 socket을 해제해 다른 프로세스가 쓸 수 있도록 한다.

컴퓨터 내부에 프로세스들이 많이 있는 상황에서 이 프로세스들은 각자 socket이 있다. 이 socket들은 transport layer에 메세지들을 내린다. transport는 받은 메세지를 segment 형태로 만들어 아래로 내린다. 받는 입장에선 transport layer에서 segment를 받아 application layer에 메세지를 전달해준다.
어떻게 demultiplexing을 하는가? segment의 header 정보를 가지고 어떤 socket에 정보를 전달할지 파악한다.
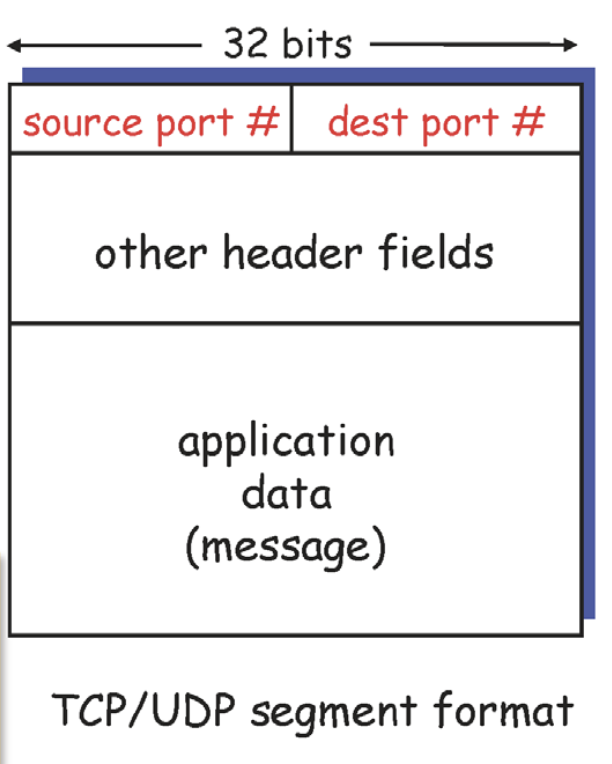
위의 그림은 segment를 나타내는데, payload 위의 부분이 모두 header이다. 이 중 중요한 필드가 source port(자기 자신), dest port(목적지)이다.
데이터 부분은 header 부분에 비해 크기가 엄청 크다. 편지지와 편지 봉투의 내용차이를 생각하면 된다.
UDP
destination IP와 desination PORT number만을 사용해서 어떤 socket으로 올릴지 demultiplexing을 한다.
TCP
source IP, source PORT number, destination IP와 desination PORT number 네개의 튜플로 어떤 socket으로 올릴지 demultiplexing하는 것이다.
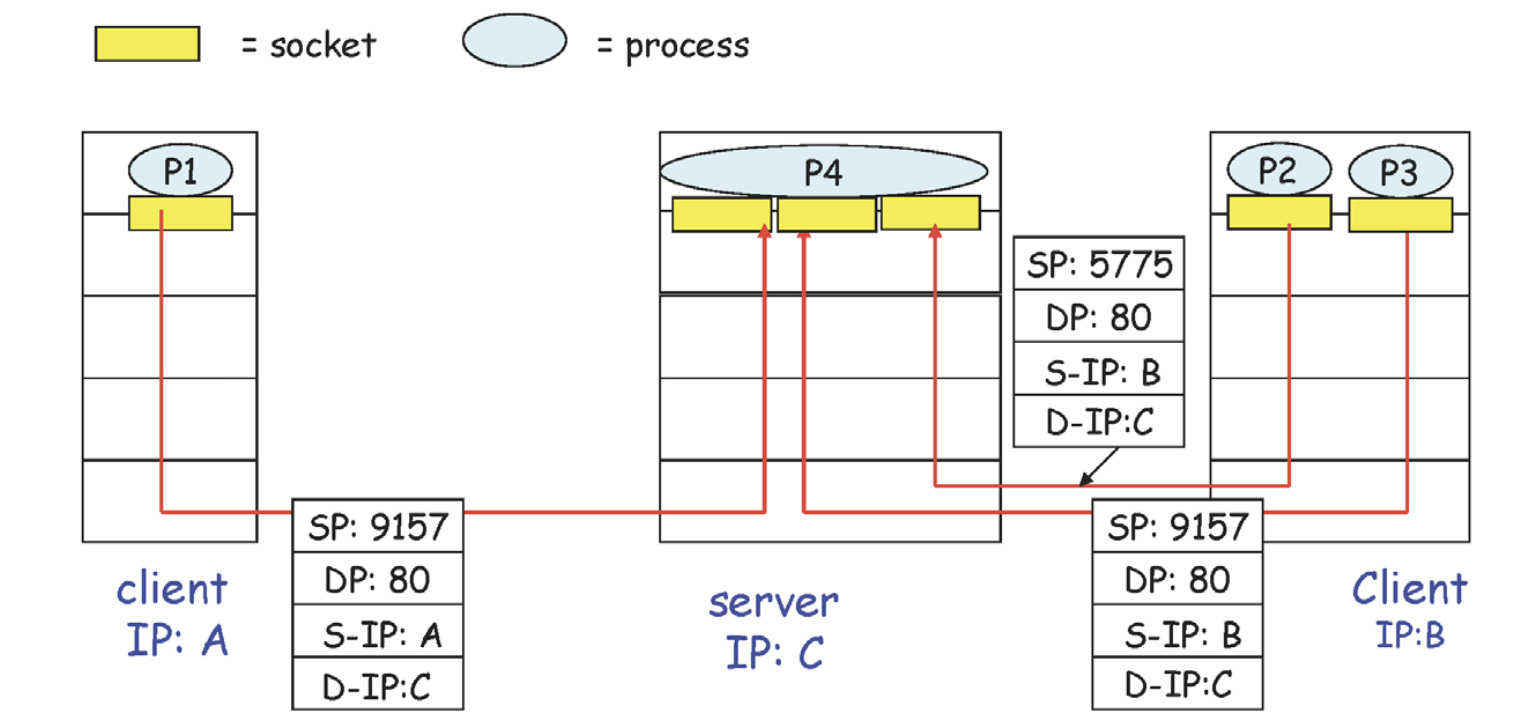
위의 그림을 보면 세개의 segment의 destination IP, destincation PORT number가 모두 같은데, 각자 다 다른 socket을 가리키는 것을 볼 수 있다.
각각 클라이언트를 위해 socket을 생성하고 관리하기 때문에 자원을 많이 소비한다.
UDP
transport가 제공하는 기본적인 서비스는 제공을 한다.
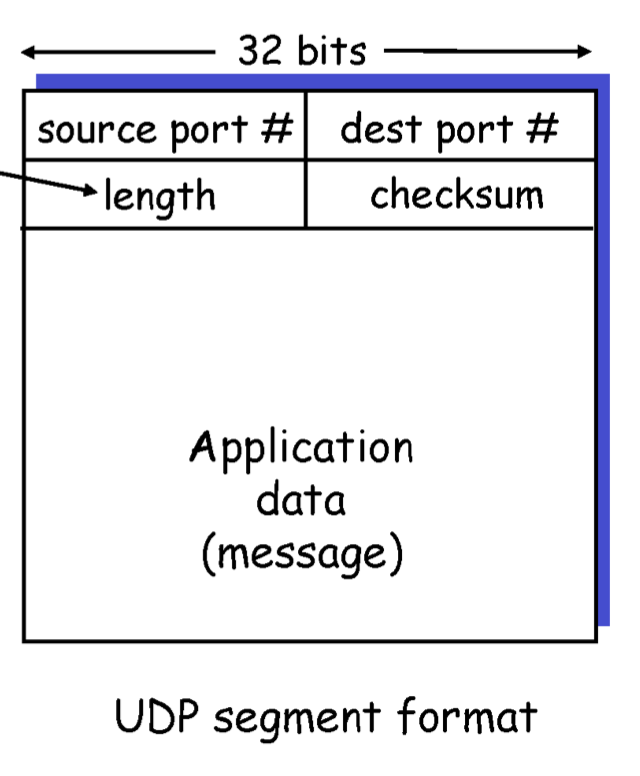
UDP, TCP, IP는 header의 정보가 중요하니 알아야한다.
source port, dest port는 각각 16비트이다. UDP는 각각의 port number로 multiplexing, demultiplexing을 해준다. checksum -> 데이터가 전송 도중 에러가 있었는지 알려준다. receive했을 때 checksum을 확인해 error가 있으면 application layer로 올리지 않고 drop 시킨다.
reliable -> application layer에서 온 데이터가 하나도 유실되지 않고 error없이 전달되는 것
실제 transport 아래 layer들은 reliable하지 않다.
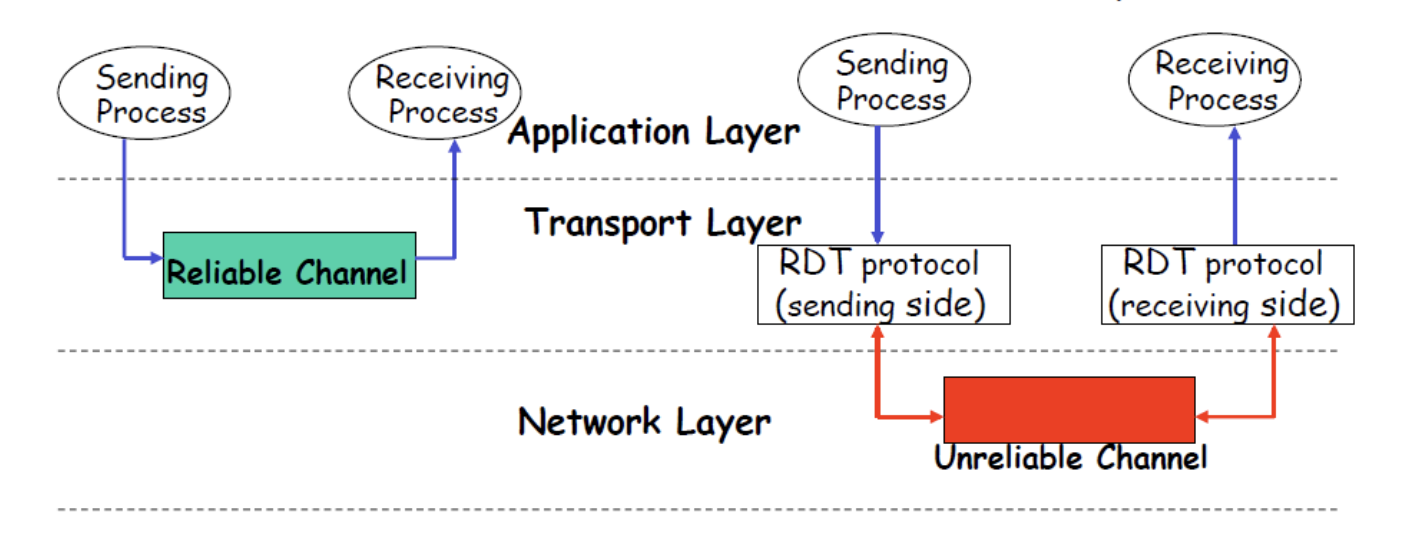
unreliable하면 packet loss, error가 발생한다. 따라서 이를 잘 처리하면 reliable하게 할 수 있다.
패킷을 하나 보내고 확인하고, 하나 보내고 확인하는 simple Reliable Data Transfer Protocol 생각해보자.
error도, loss도 발생하지 않는다면 transport가 할일이 있는가? 없다. 그냥 보내기만 하면된다.
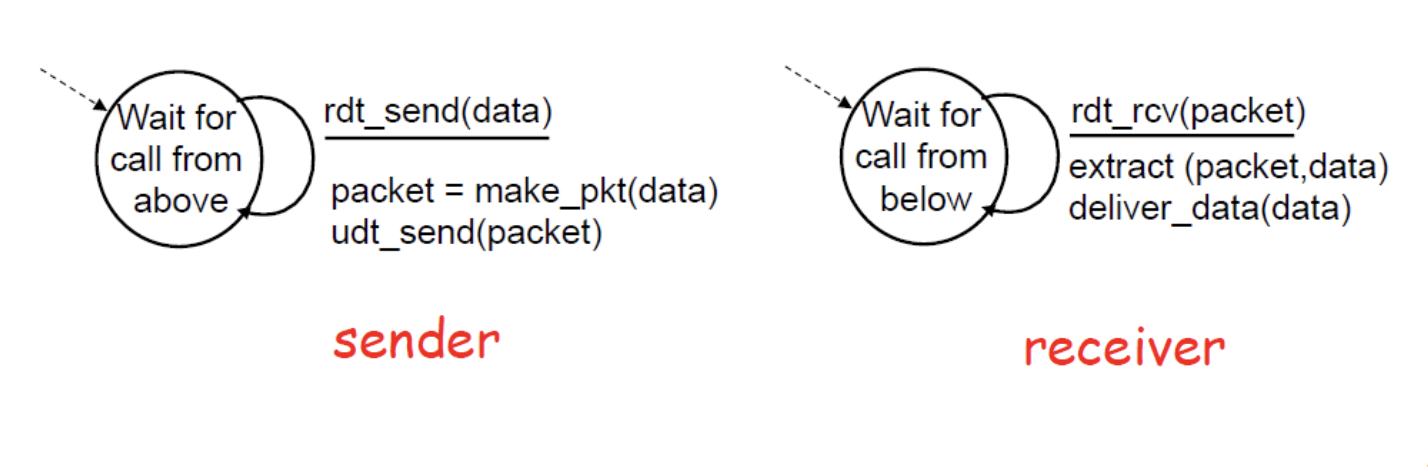
만약에 under line channel이 error가 발생가능하다면, 어떻게 reliable을 지킬 수 있을까?(상대방이 error없는 message를 어떻게 받을 수 있을까?)
- 패킷에 checksum이라는 부가적인 정보를 통해 error를 감지해야한다.
- feedback을 줘 sender에게 패킷의 상태를 알린다.
- error X => Acknowledgements (ACKs): receiver explicitly tells senderthat packet received correctly
- error O => Negative acknowledgements (NAKs): receiver explicitly tells
sender that packet had errors
- NAK을 받게 되면 재전송한다.
error가 있는 상황에서 필요한 메커니즘은 error detection - feedback - retransmission 이다.
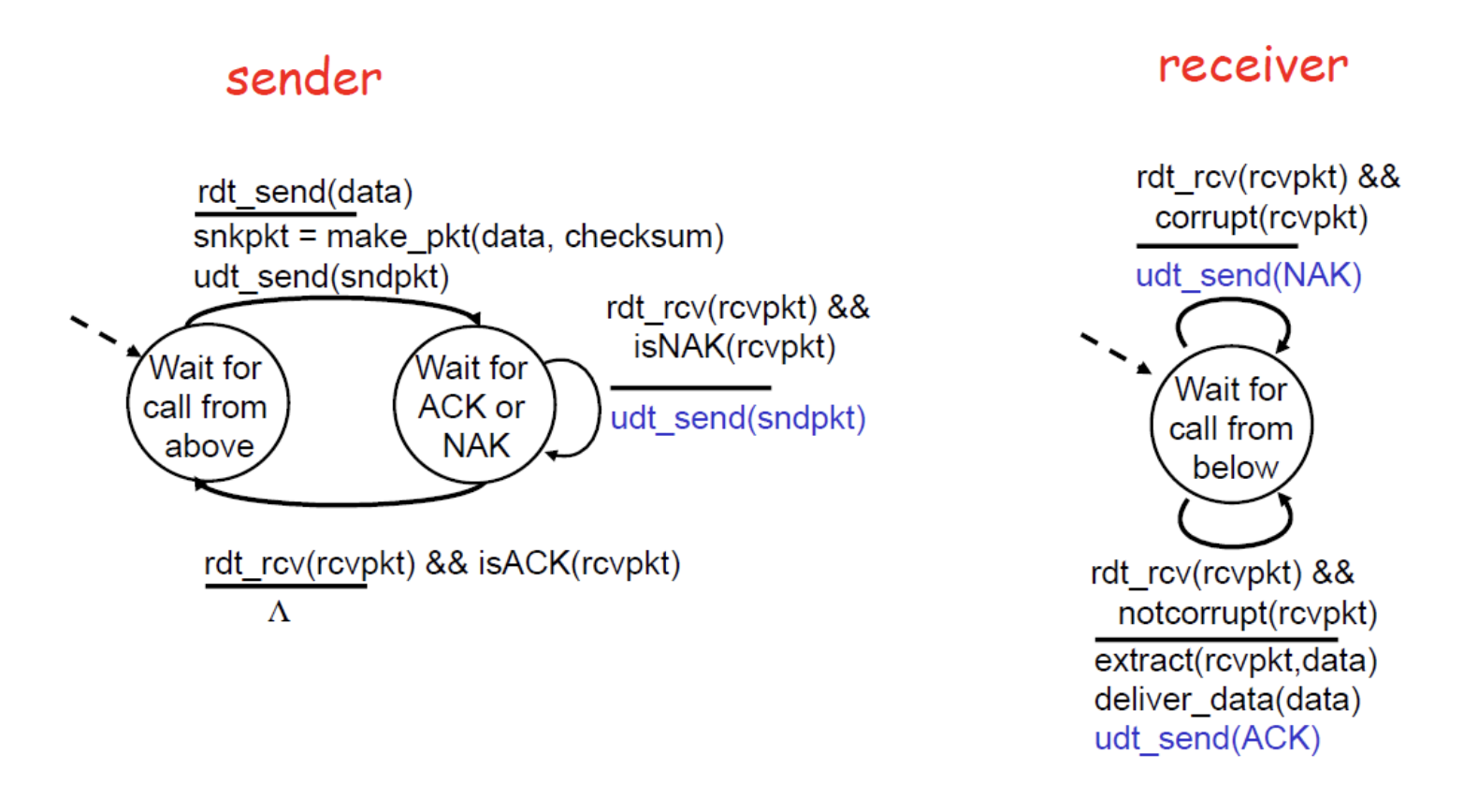
그렇다면 이 메커니즘들로 완벽하게 신뢰성있는 메세지 교환을 할 수 있을까?
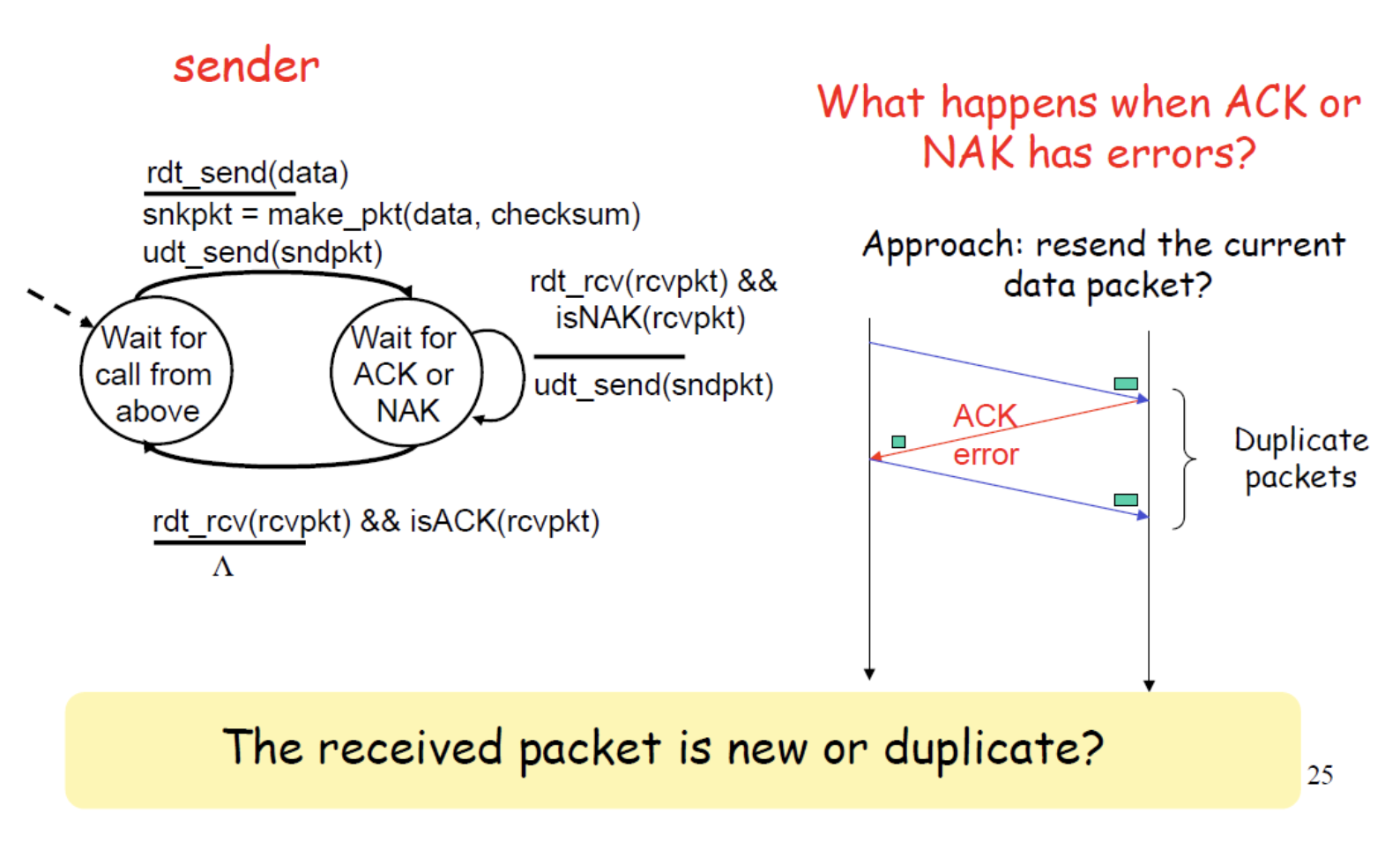
만약 feedback에 error가 있는 경우 처리가 확실하지 않다.
ACK를 주다가 error가 생겨(checksum을 통해 확인) receiver가 ACK인지 NAK인지 알아채지 못하게 되는 것이다.
따라서 받았다고 넘어가기 보단 안받았다고 가정하고 다시 보내게된다. 그렇다면 패킷을 받는데, 이게 중복된 패킷인지 새로운 패킷인지 알 수 없다. 따라서 이 패킷을 구분하기 위해 번호를 붙인다. 이를 seguence number라 한다.
sequence number를 붙이는 가장 직관적인 방법은 0번 부터 순서대로 번호를 붙이는 것일 것이다.
sequence number는 header에 들어가는 정보인데, 위와 같이 순서대로 번호를 붙이면 범위가 무한대로 늘어난다. header의 크기가 작을 수록 좋다. 각각 어떤 필드가 필요한지 최소한의 필드만 사용해야 될 뿐만 아니라 각각의 필드는 최소한의 크기여야 한다. 따라서 이 sequence number를 최소화 시키고 싶을 것이다. 어떻게 최소화시킬 수 있을까? sequence 몇개로 충분한가? 두개이다. 이 protocol은 굉장히 단순해서 한번 보내고 받았는지 확인을 한다. 따라서 sender는 0을 보내고 receiver는 1이 올 때 까지 기다리기만 하면된다. (error가 있는 상황에서 !)
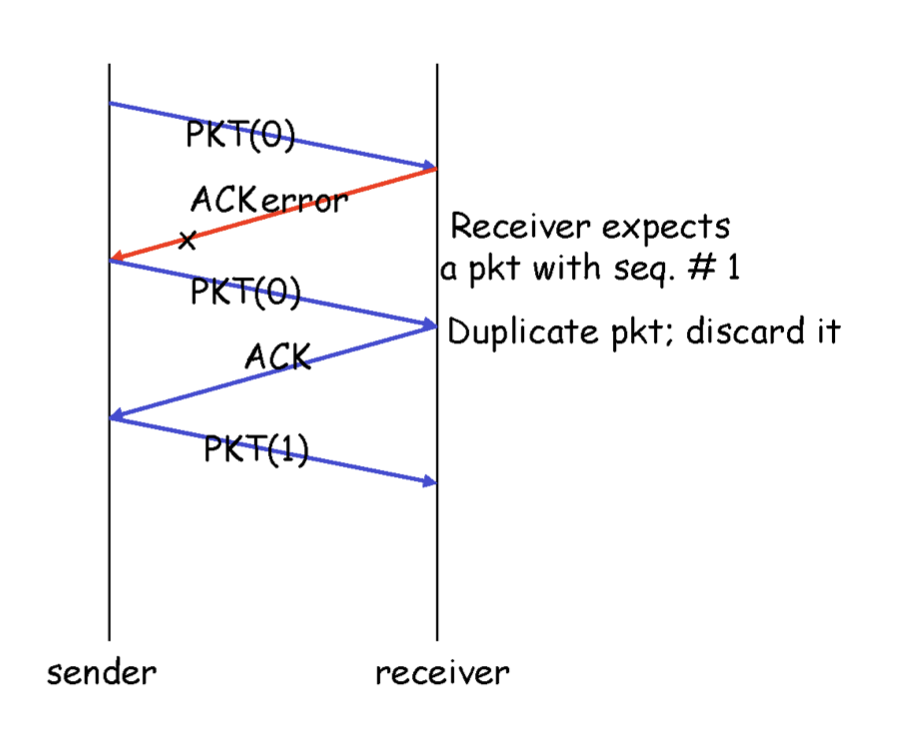
1을 받지 않았더라도 0을 잘 받았으면 ACK를 보내야한다.
NAK를 없앤 protocol (NAK-free)
sender에서 0번을 보낸다. receiver는 무조건 ACK을 보내는데, 이때 sequence번호를 같이 보낸다. 0번을 받았으니 0번을 같이 보낸다. 그리고 sender가 1번을 보내는데 중간에 error가 있다. reciever는 무조건 ACK를 보내야하므로 ACK를 보내는데, 마지막으로 받은것이 0번이므로 0번을 보낸다. 그렇다면 sender 입장에선 1번을 보냈는데 0번을 받았다는 답을 받았으므로 NAK를 받은셈이다. 따라서 sender는 1을 다시 보낸다.
error 뿐만 아니라 loss도 생기는 상황을 가정하자
error가 있는 상황에 대해 메커니즘을 다 구성했으므로 loss에 대비해 수정하면 되는 것이다.
메세지를 보냈는데 유실됐다면 ? 전화를 하는데, 상대방의 답이 중간에 유실됐다면 ? 우리는 조금 기다리다가 괜찮냐고 물어본다. 즉, 알고보면 우리는 마음속에 timer를 가지고 있다.
따라서 sender는 패킷을 보내고 timer를 돌리는 것이다. timer가 돌아갈 때 까지 receiver로 부터 응답이 없으면 데이터가 유실된 것이다. 그렇다면 timer를 얼마나 맞춰야될까? "reasonable" amount of time for ACK 만큼 기다린다.
짧은 timer를 사용했을 때 장점은 유실되었을 때 빠른 대응이 가능하다. 단점은 패킷이 전송되는데 오래걸리는 것 뿐인데 유실된줄 알고 패킷을 한번 더 전송해 중복된다. 따라서 네트워크에 오버헤드가 부여된다.
긴 timer를 사용하면, 네트워크에 오버헤드가 작지만, loss가 발생했을 때 극복이 느리다.
따라서 timer를 어떻게 잡는지가 중요한 issue이다.
timer를 굉장히 짧게 잡아서 패킷을 보낼 때 timer를 틀고, 가서 제대로 돌아
가고 있는데 내 timer가 빨라서 터짐 -> 재전송 -> sequence number가 같다.
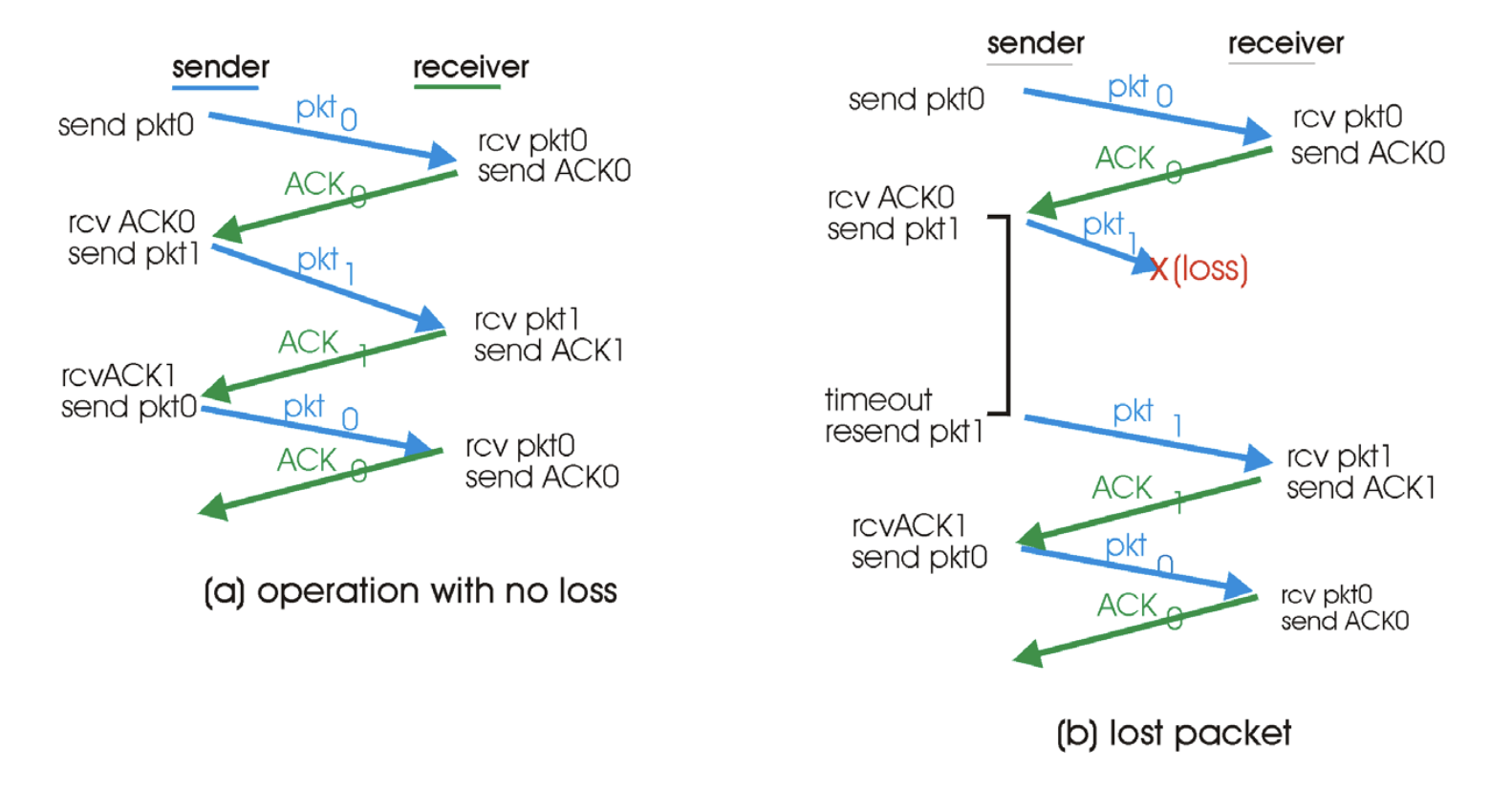
a)에서 sender가 1번째 3번째로 보낸 패킷은 둘 다 sequence number가 0이지만 다른 패킷이다.
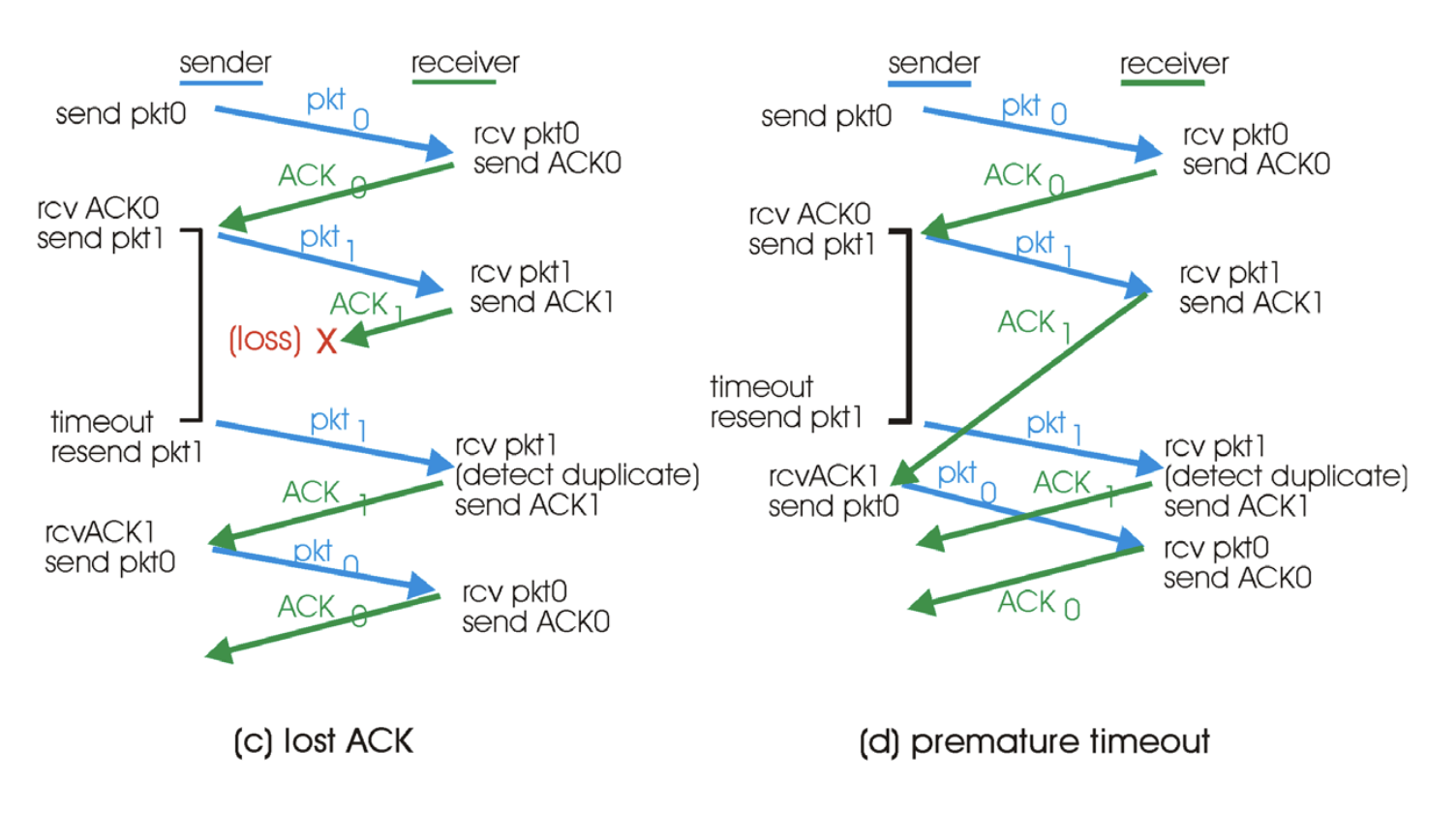
이로써 이 프로토콜은 완벽하게 동작한다.
unreliable channel에서 일어날 수 있는 일 -> packet error, loss
mechanisms for packet error -> Error detection, feedback, retransmission, sequence#
mechanisms for packet loss -> Timeout
우리가 살펴본 RDT는 너무 단순하다.

sender가 패킷을 보내고 아무것도 안한다(네트워크 사용을 안한다). 16차선 고속도로에 차가 한대씩 지나가는 것과 같다. 신뢰성은 보장하지만, 답답하다.
실제로 TCP는 아래 그림의 오른쪽과 같이 진행된다.
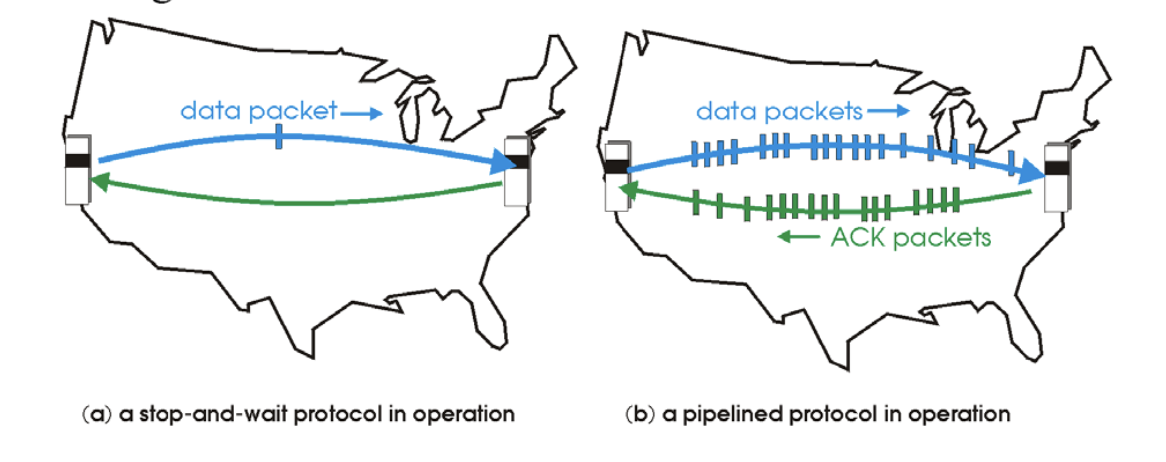
한꺼번에 패킷을 쏟아붓는다고 생각하면 된다.

출처
