최초의 인터넷이라 불리는 알파넷 -> 네대(네개의 노드)로 시작해 조금씩 커져왔다.
네대로 연결된 작은 네트워크에서 지금의 인터넷의 개념적인 모습은 아래와 같다.
노드의 수를 셀 수도 없을 뿐만 아니라 계속해서 팽창하는 중이다.
인터넷에 접속하는 하나하나가 위 그림의 점들이 된다.
개념적인 인터넷의 모습에서 우리의 위치는 어디일까? 우리는 가장자리에 위치하고 있다. 서버들도 가장자리에 있다고 말할 수 있다. 끄면 쫓겨나고 키면 다시 들어가기 때문이다. 그렇다면 가운데에 위치하고 있는것들은 무엇일까?
라우터이다. 라우터란? 메세지를 전달받아 목적지를 향해 전달해주는 기능을 하는 것이다.
과연 인터넷이라는게 어떤 요소로 구성되어 있는지 얘기해보자.
네트워크의 엣지에 우리들이 위치하고, 코어에 라우터라고 불리는 것들이 위치한다.
Network Structure
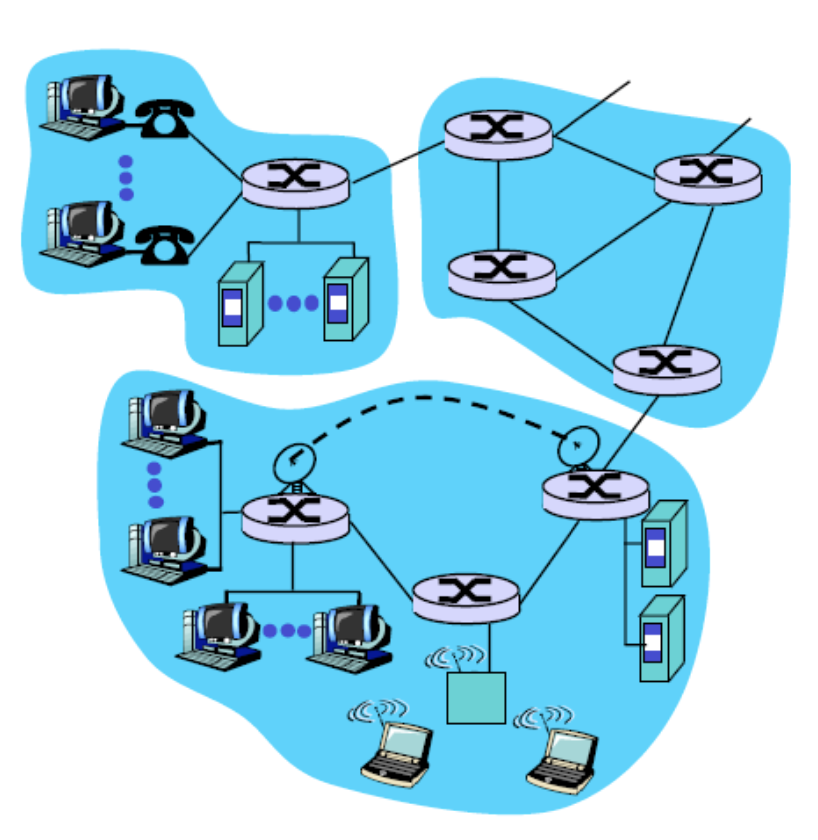
network edge
가장자리에는 application, hosts가 온다. 즉, 우리가 사용하는 웹 브라우저 등이다.
클라이언트라고 분류되는 컴퓨터, 서버라고 분류되는 컴퓨터가 존재한다. 클라이언트라는 네트워크 엣지에 존재하는 컴퓨터는 자기가 원할 때 링크에 연결해서 서버로 부터 정보를 가져오는 요소이다. 서버란 항시 24시간 연결돼 있어서 클라이언트로 부터 언제 들어올지 모르는 요청을 기다리는 요소이다.
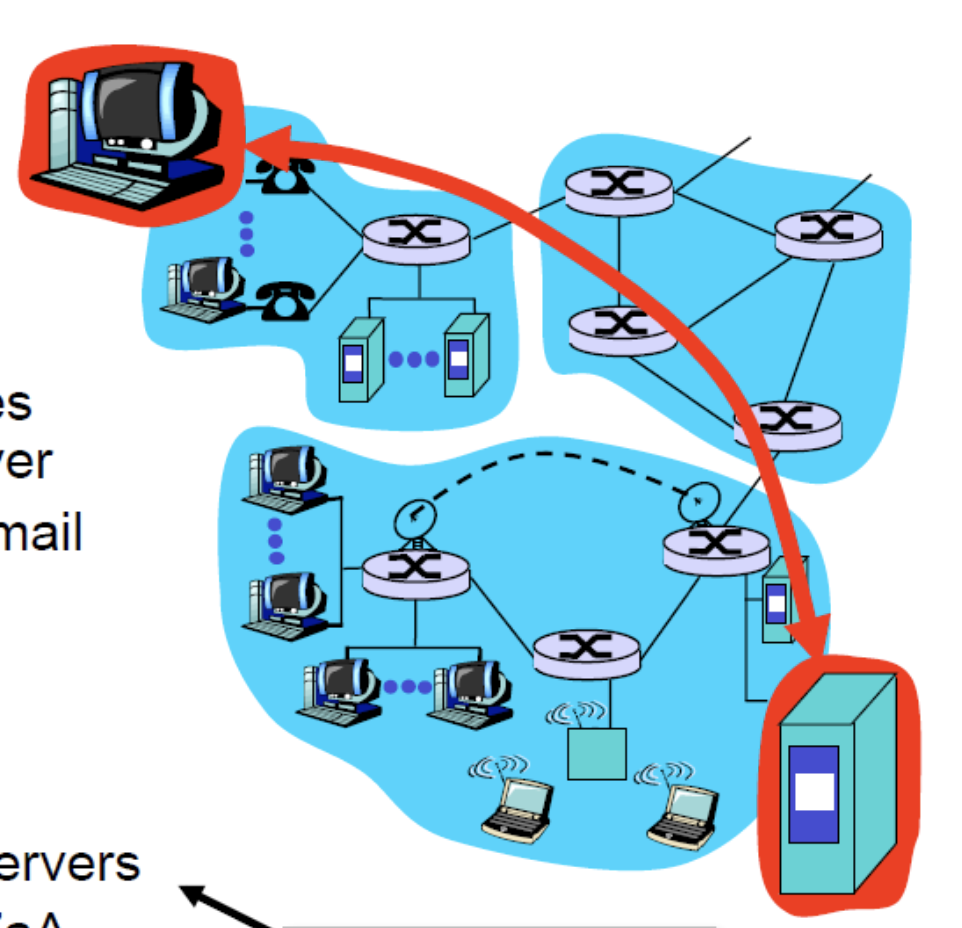
클라이언트의 입장에서 서버와 데이터를 주고 받고자 하는데, 결국 인터넷을 제공하는 서비스를 사용해 데이터를 주고 받는다. 인터넷을 제공하는 통신 서비스에 대해 간략하게 얘기를 해보자
데이터 통신 서비스
데이터 통신 서비스는 두가지가 있다.
connection-oriented service
TCP가 바로 connection-oriented service를 제공하는 통신방법이다. TCP는 클라이언트(사용자)에게 다음의 세가지를 제공한다.
- reliable,in-order byte-stream data transfer
내가 보낸 그대로 데이터가 유실 되지 않고, 순서대로 전송하는 것이다. - flow control
sender가 receiver한테 데이터를 보내는데, 데이터 전송 속도를 알맞게 조절해주는 것이다. A가 B에게 데이터를 전달하는데 A 컴퓨터가 슈퍼 컴퓨터라면 B 컴퓨터는 제대로 소화할 수 있을까? 아니다. 따라서 B가 소화할 수 있는 속도로 데이터를 보내는 것이 flow control의 역할이다. 즉, receiver의 능력에 따라 sender의 전송속도를 조절하는 것이다. - congestion control
A,B가 슈퍼컴퓨터라고 해보자. 그럼 그냥 슈퍼 컴퓨터의 속도대로 데이터를 전송해도 되는 것인가? 아니다. 만약 컴퓨터끼리 연결하고 있는 선이 굉장히 얇은 선이라고 해보자. 그렇다면 슈퍼 컴퓨터의 속도를 이기지 못할 것이다. 그래서 중간의 network 상황에 따라서 해당 network의 능력치 만큼 보낼 수 있도록 조절해주는 것이다.
웹 브라우징 => TCP를 사용한다.
connectionless service
UDP가 connectionless service를 제공하는 통신방법이다.
- connetionless
- unreiable data transfer
- no flow control
- no congestion control
을 제공한다. 즉, TCP에서 제공해주던 걸 제공해주지 않는다. 순서도, 데이터의 신뢰성도 보장해주지 않는다.
그렇다면 TCP는 제공해주는것이 많은데 UDP를 왜 사용하는 걸까? 보내는 사람 입장에서 유실되든 말든 상관없이 마음대로 데이터를 보내도 된다. 뭔가 reilable해야 하면 TCP를 보내고 unreilable하면 UDP로 보내면 된다. 그렇다면 unreiable한 경우는 뭐가 있을까? 예를 들어 real time의 voice 통화이다. 오디오 패킷이 몇개 정도 유실되어도 사람들은 인지하지 못하기 때문이다. 하지만 대부분은 reliable한 상황이어서 TCP를 사용한다.
우리의 실제 우편시스템도 비슷하다. 미국에 있는 친구에게 편지를 쓴다고 가정하자. 편지를 편지 봉투에 담아서 우표 붙여 우체통에 넣으면 간다. 이는 UDP와 같다. 왜냐면 중간에 도착하지 않을 수도 있고 유실될 수도 있다. 하지만 만약에 미국에 있는 친구에게 100만원의 돈을 보내야된다고 해보자. 그런경우에도 그냥 돈을 편지와 같이 넣어 우체통에 넣을것인가? 아니다. 등기로 보내 보장받을 수단을 챙길 것이다. 하지만 등기는 비용이 그냥 우체통을 통해 보내는 것 보다 비싸다. 즉 비용이 더 드는데 이것이 컴퓨터 리소스, 네트워크 리소스인 것이다.
또한 네트워크에서는 편지 봉투와 같은 역할을 하는 것을 packet이라고 한다. 까보면 안에 전달할 데이터나 message등이 들어있는 것이다.
Protocol
UDP, TCP는 모두 P로 끝난다. 이 P 는 Protocol이다. 그렇다면 Protocol은 무엇인가? A와 B가 전화를 할 때 C라는 목적이 있지만, 전화를 받자마자 C에 대해 물어보지 않는다. 안부인사 등 부가적인 이야기를 하고 C에 대해 이야기를 하는 것이다. 이러한 것이 A와 B만의 암묵적인 소통 rule인것이다. 기본적으로 같은 언어를 사용해야 할 것이고, 이것을 넘어 둘 사이의 대화 방식의 약속이 있어야한다. 이러한 것이 Protocol이다.
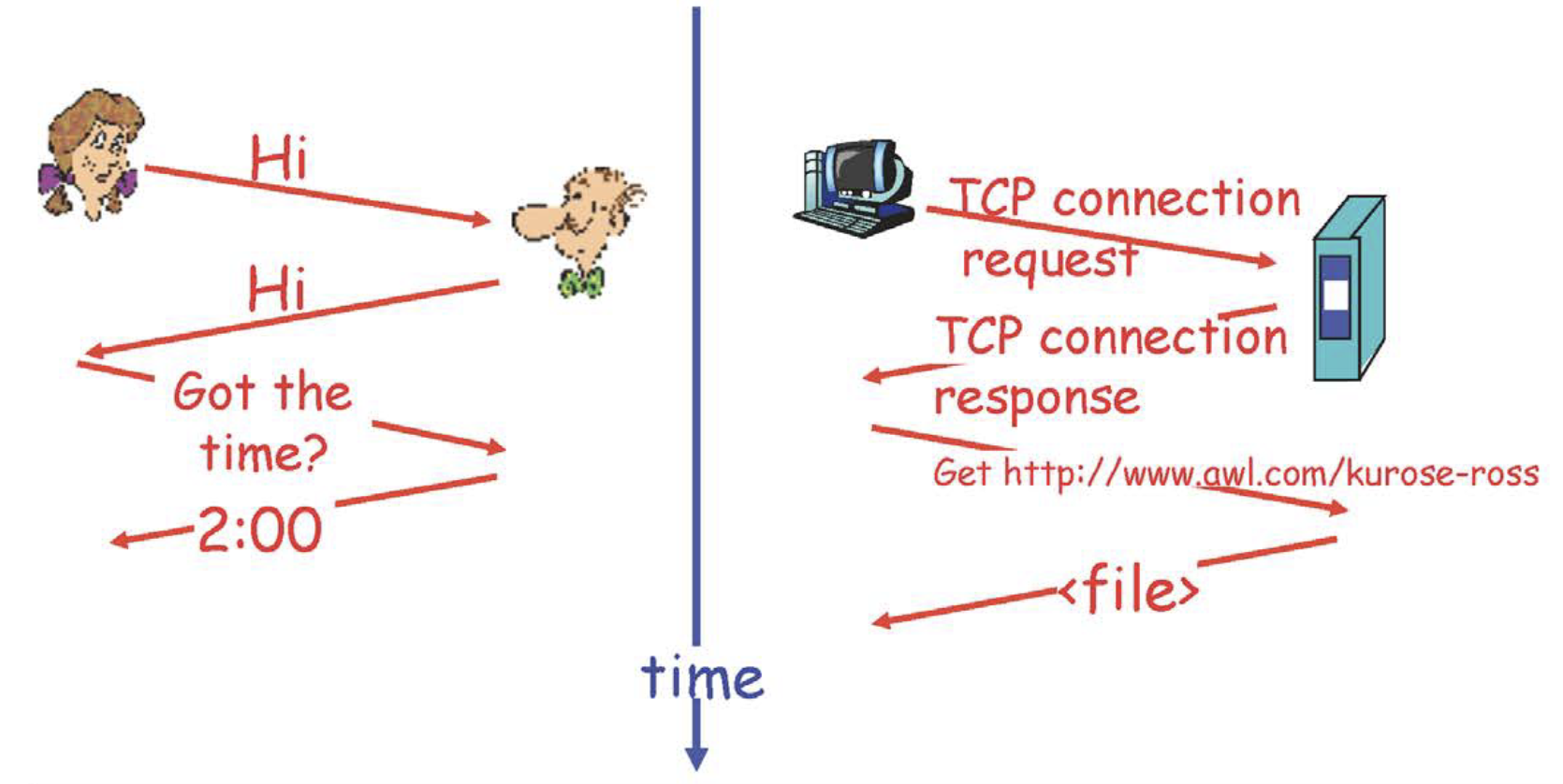
웹 브라우저가 웹 서버에게 정말 하고자 하는 말은 특정 웹 페이지를 달라는 것이지만 그전에 부가적인 것들을 하는 것이다. 즉, 정말 중요한 데이터를 받기 전에 준비동작을 하는 것이다.
그래서 전화통화 예에서 봤듯이 사람간에는 암묵적인 Protocol이 있다. Protocol이 안맞으면 통신이 맞지 않는다. 서로 다른 객체간의 소통이므로 어떤 방식으로 소통할지 미리 약속하지 않으면 안되는 것이다.
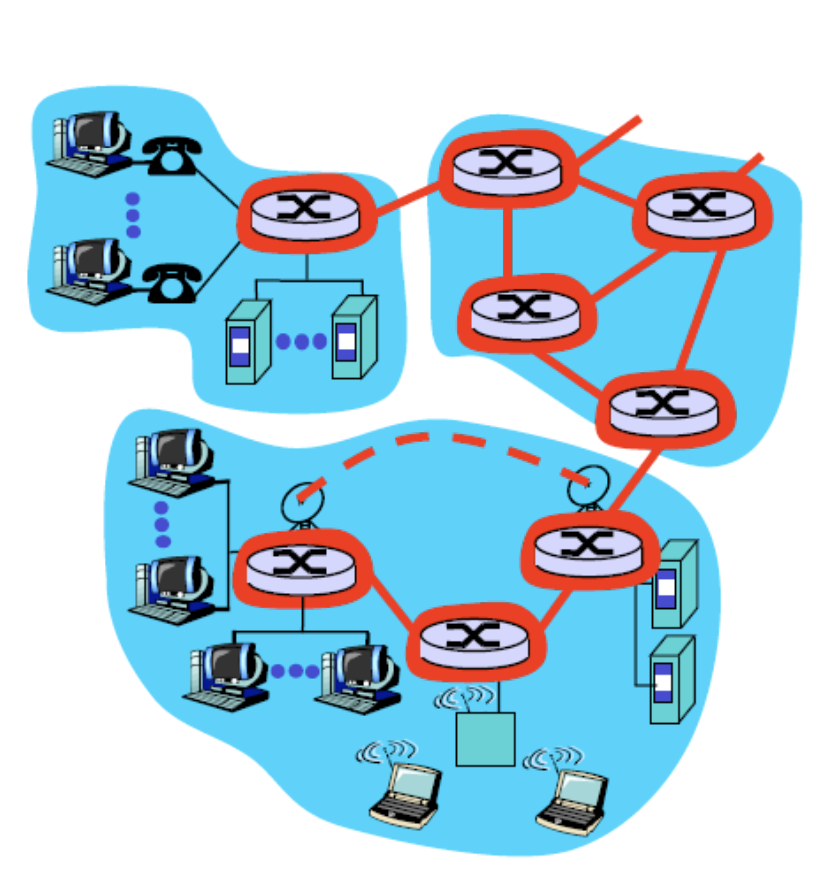
network core
라우터들이 연결되어있는 것을 볼 수 있다. 짧은 원기둥 모양 위에 X 표시가 되어있는 것이 라우터이다.
데이터를 출발지에서부터 목적지까지 전달하는데 어떻게 전달을 하는가? 메세지를 전달하는 방식에는 아래의 두가지가 있다.
circuit switching
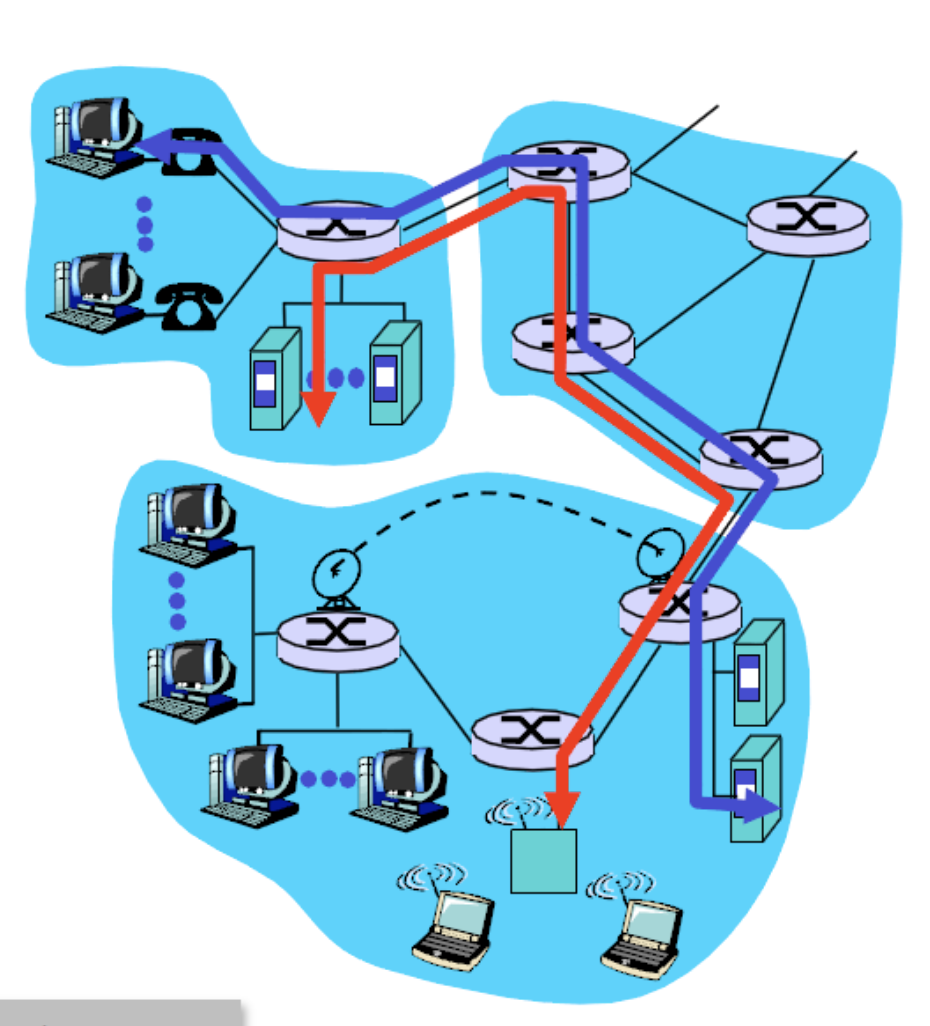
출발지부터 목적지 까지 가는길을 미리 예약해놓고 특정 사용자만을 위해 사용하도록 만들어 놓은 것이다. 옛날 유선 전화망이 사용하던 방식이다.
packet-switching
인터넷에서는 이 방식을 사용한다. 사용자가 보내는 메세지를 패킷단위로 받아서 그때그때 올바른 방향으로 주는 방식이다.
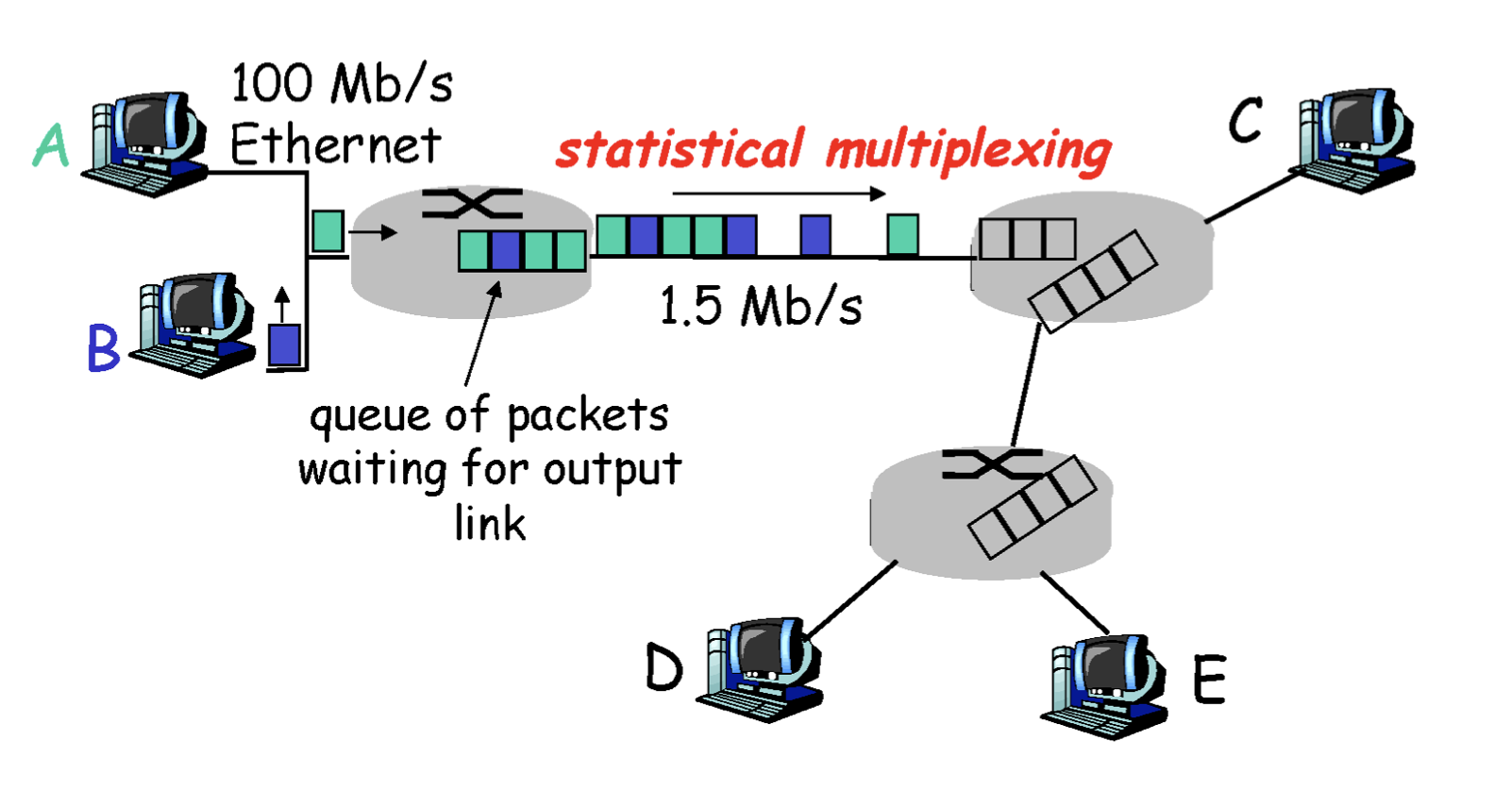
A라는 사용자가 보내는 패킷, B라는 사용자가 보내는 패킷을 들어오는 대로 목적지로 보내는 것이다. 즉, 자원의 예약이 없다.
1Mbpas link는 1Mbit/sec로 초당 1Mbit 크기의 데이터를 한꺼번에 뿜어낼 수 있는 크기를 가진 케이블이다. 이것을 band width라고 한다.
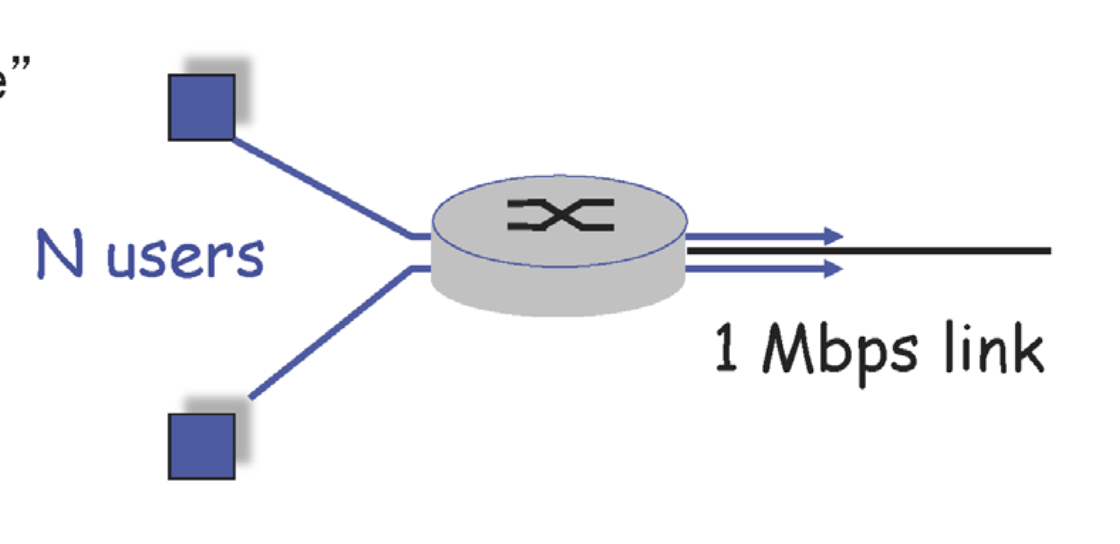
각 사용자가 100 kb/s 만큼의 속도로 데이터를 전송한다고 가정하자.
이를 Circuit switching을 사용하면 몇명의 사용자를 지원할 수 있을까? 10명이다. 왜냐, outgoing link가 1Mbpas이므로 10명까지 가능하다.
Packet switching이라면 몇명까지 가능할까? 그런 개념이 없다. 그냥 들어오는대로 전송하기 때문이다. 따라서 제약이 없다. 그런데 제약이 없다곤 하지만 한꺼번에 10명 이상씩 몰리면 어떻게 될까?
우리가 인터넷을 사용하는 패턴을 생각해보자. 전화를 사용하는 동안 우리는 쉬지 않고 말한다. 웹 브라우징 이라면 기사를 클릭하면 데이터가 온다. 그리고 우리는 클릭을 계속하는 것이 아니라 기사를 보고 있는다. 즉, 클릭을 해서 데이터가 와야 하는 순간은 웹 브라우저를 사용하면서 얼마 되지 않을 것이다.
따라서 circuit을 사용하면 사람들이 사용하지 않고 있는데도 link를 차지 하고 있어 낭비가 되는 것이다. 하지만 packet을 사용하면 사람들이 사용할 때만 전송을 해버리면 되므로 그러게 사람들이 많이 몰리지 않는다. 예를 들어 35명의 사용자가 인터넷을 사용할 때 10명이 동시에 데이터를 전송해야 하는 경우는 굉장히 낮다. 하지만 운나쁘게 10명이 몰린다면, 좋지 않은 상황이 생긴다. packet도 circuit과 마찬가지로 동시에 사용할 수 있는 것은 10명의 사용자 임을 유의하자.
packet switching이기 때문에 어쩔 수 없이 생기는 문제들에 대해 알아보자.
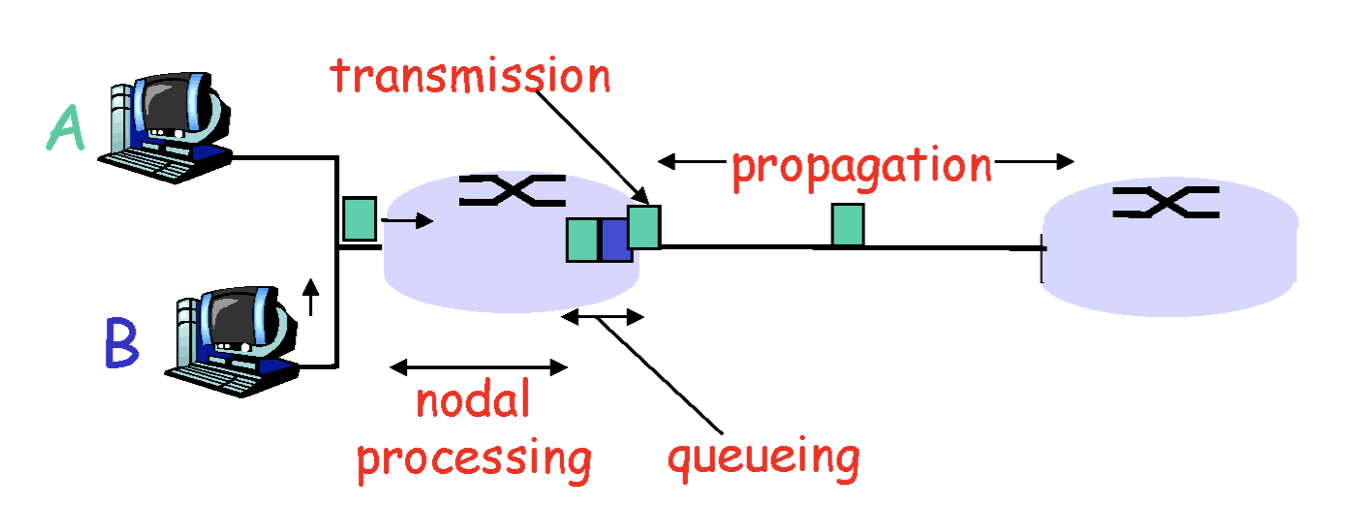
processing delay
라우터에서 새로운 패킷을 받았다면, 이 패킷이 제대로 된 패킷인지 확인하고 목적지로 보내야한다. 이것이 바로 processing delay이다. 이는 어쩔 수 없이 해야하는 작업이다.
delay를 줄이려면 라우터 성능을 개선하면 된다.
queueing delay
만약 사용자에게서 들어오는 속도가 band width보다 크다면? (빠져나갈 수 있는 속도 보다 크다면?) 줄이 생긴다. 그럼 생긴 줄에 대해 처리를 해줘야 한다. 만약 임시 저장 공간이 없다면, 빠져나가지도 못한채 터져버릴 것이다. 따라서 빠져나가지 못하고 줄을 선 패킷을 저장해줄 임시 저장소가 필요하다. 이는 buffer 혹은 queue로 존재한다. 들어왔을 때 패킷을 확인하고 나가야 하는데, 줄이 존재한다면 뒤에 가서 서야한다. 따라서 이 기다리는 시간을 queueing delay이다.
delay를 줄이기에 제일 골치아픈 delay이다. queue의 길이를 각각의 사용자들이 종합적으로 기여하는 것이다. 사용자들이 전부 사용안하는 시간인 새벽에는 queue가 줄 것이고, 사용자들이 많이 사용하는 시간인 낮에는 사용자들이 몰려 queue가 늘어난다. 따라서 각각의 사용자들을 그룹별로 나눠 다른 시간대에 사용하게 해 queue의 길이를 일정하게 유지하는 방법밖에 없는데 이는 현실적으로 불가능하다. 따라서 이는 우리가 조절할 수 없다. 또한 이 delay가 network dynamic의 근원이다.
queue의 크기는 무한대일 수 없다. 최악의 경우엔 queue의 크기보다 더 많이 들어올 수 있다. queue보다 넘치면 더이상 받지 못하고 버리게 된다. 때문에 데이터가 유실되는 것이다.
TCP에서는 데이터의 reliable을 보장해준다고 했다. 따라서 위의 상황에 따라 데이터 유실이 일어나면, 재전송을 해야한다. 그렇다면 재전송의 주체는 어떻게 되는 것일까? 처음 발송지일까, 유실된 라우터 직전의 라우터일까? 바로 처음 발송지이다. 왜 이럴까? 효율성을 생각하면 직전 라우터에서 보내는게 좋을 것 같다. 하지만 라우터는 이미 할 일이 많다. 또한 라우터는 들어오는 데이터를 전달하는 역할에만 충실해야한다.
Transmission delay
queue에서 기다리다가 나가는 순간에 걸리는 딜레이가 있다. 패킷이라는 bit의 집합인 데이터이다. 이는 나갈때 첫번째 비트부터 마지막 비트까지 온전히 나가야한다. 따라서 Transmission delay란 첫번째 비트가 나가는 순간부터 시작해서 마지막 비트가 온전하게 링크로 나가는 시간이다. 이 delay는 쉽게 패킷 크기를 link band width로 나눈것으로 정의된다. (L/R, L:packet length, R:link bandwidth)
파이프가 가늘다면 파이프를 빠져나가는 시간이 오래걸리고, 파이프가 크다면 똑같은 양이어도 파이프를 빠져나가는 시간이 얼마 안걸리는 것과 같다.
delay를 줄이려면 band width를 늘리면 된다.
Propagation delay
마지막 비트가 링크에 올라와서 다음 라우터에 도달할 때까지 걸리는 시간을 Propagation delay라고 한다. 이것은 단순히 마지막 비트가 올라온 순간 부터 도달하는 시간이므로 전자기파가 움직이는 속도 이므로 빛의 속도이다. 따라서 링크길이를 빛의속도로 나눈것이다.
- d = length of physical link
- s = propagation speed in medium (~2x108 m/sec)
- propagation delay = d/s
따라서 우리는 이러한 delay를 줄이기 위해 노력한다.
각각의 차량이 bit이고 이들 10개가 묶여있는것이 packet이라고 하자. 또한 차량 하나가 톨게이트를 지나는데 12초(transmission time)가 걸린다. 따라서 패킷 하나가 톨게이트를 지나는 시간은 120초이다.

패킷단위로 움직이기 때문에 첫번째 차가 12초가 걸려 지났다고 다음단계를 진행하는 것이 아닌 마지막 비트까지 기다렸다가 다음 단계로 진행하는 것이다.
access networks, physical media
연결 선이다. communication links로 여러 길이, 여러 종류의 link가 있다.
네트워크 계층은 다음과 같이 나타낼 수 있다.
| 네트워크 계층 |
|---|
| application |
| transport |
| network |
| data link |
| physical |
application 계층은 network기능을 하는 프로세스라고 생각할 수 있다. 네트워크 application이라는 것은 network edge에 있는 서버와 클라이언트 간의 동작을 이야기 한다.
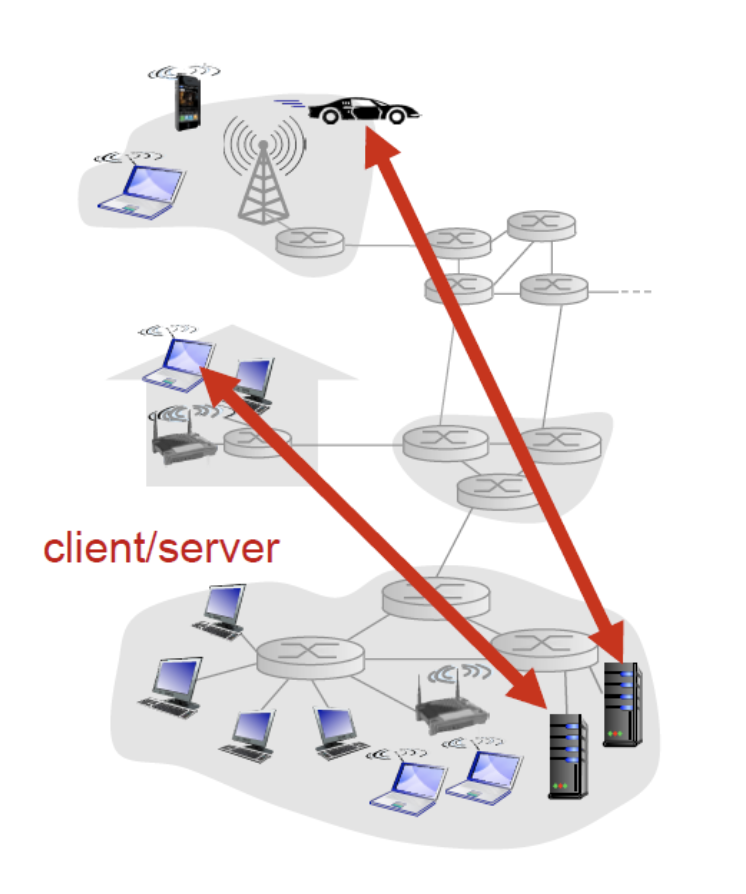
클라이언트는 웹 브라우저, 서버는 웹 서버를 생각하면 된다.
인터넷상에 존재하는 모든 컴퓨터들은 각자의 주소를 가져야 하며 이게 IP 주소이다. 그중에서도 server는 바뀌지 않고 고정된 IP가 있어도 되고, 클라이언트는 고정되지 않아도 된다.
server의 IP가 고정되어야 찾아갈 수 있기 때문이다.
클라이언트 프로세스와 서버 프로세스와의 의사소통(통신) 즉, 프로세스 사이의 통신이다.
프로세스들 사이에 데이터를 주고 받는 통신을 위해 OS가 interface를 만들어 놓았다. 하지만 여기서는 다른 컴퓨터에 있는 프로세스와의 통신인데, 다른 컴퓨터여도 비슷하다. 이때는 socket이라는 interface를 사용한다.
Socket
다른 컴퓨터에 있는 프로세스들끼리 통신을 하려면 사전에 연결을 해야한다. 따라서 상태 socket의 주소를 알아야한다. socket의 주소 역할을 하는 index가 필요하며 이게 IP address와 PORT의 combination이다. IP는 인터넷상에 있는 컴퓨터의 주소를 말한다고 했다. 하지만 하나의 컴퓨터 내에도 여러 프로세스가 돌고 있다. 이 중 어떤 프로세스인지를 나타내는 것이 PORT이다. 더 정확히 말하면 어떤 socket인지를 나타낸다.
웹 브라우저가 다른 프로세스(서버)와 연결하려면 주소(IP, PORT)를 입력해야한다. 하지만 우리는 www.naver.com과 같은 주소로 입력한다. 왜일까? 주소는 외우기 힘들기 때문에 알파벳으로 된 주소를 입력하면 DNS에서 해당하는 IP,PORT를 찾아서 변환해준다. 웹서버를 운영하는 거의 모든 서버들이 PORT를 80번을 사용하고있다. 왜 이들을 공통된 PORT를 사용하는 것일까? 서버는 24시간 켜져있어야하고 주소가 항상 일정해야한다고 했다. DNS는 IP주소만을 변환해주는데 그럼 PORT는 다 외워야 한다. 일일이 다 외우는 것이 힘들기 때문에 PORT만이라도 통일하게 되었다.
계층이라는 개념은 하위 계층에서 상위 계층에게 서비스를 제공하는 것이다. 즉, application을 이야기 하기 때문에 application protocol들은 transport 계층에서 제공하는 서비스들을 사용한다. 개발자 입장에서 transport 계층에서 제공해줬으면 하는 서비스들이 있을 것이다. 아래와 같다.
-
data integrity
데이터가 유실되지 않고 안전하게 도착했으면 좋겠음 -
timing
시간에 대한 희망사항
내가 보낸 패킷이 어떤 시간 범위내에 도착해야함 -
throughput
내가 보낸 데이터가 어떤 용량이 나왔으면 좋겠음
예를 들어 1초에 어느정도양이 도달해야함 각각 패킷이 모든 timing을 맞출 필요는 없다. -
security
내가 보낸 데이터가 보안상 안전했으면 좋겠음
하지만 transport 계층에서 보장해주는 서비스는 data integrity만이다.
따라서 data integrity 기능을 TCP가 제공을 하고 UDP는 제공하지 않는다. 따라서 다른 기능들 timing, thorughput, security가 필요하다면 application에서 해야한다.
음성은 timing이 중요하고, 영화다운은 throughput이 중요하다.
유명한 application들을 구현하고 있는 protocol을 보여준다. 이 중 가장 유명한 것은 Web을 동작시키는 HTTP이다.
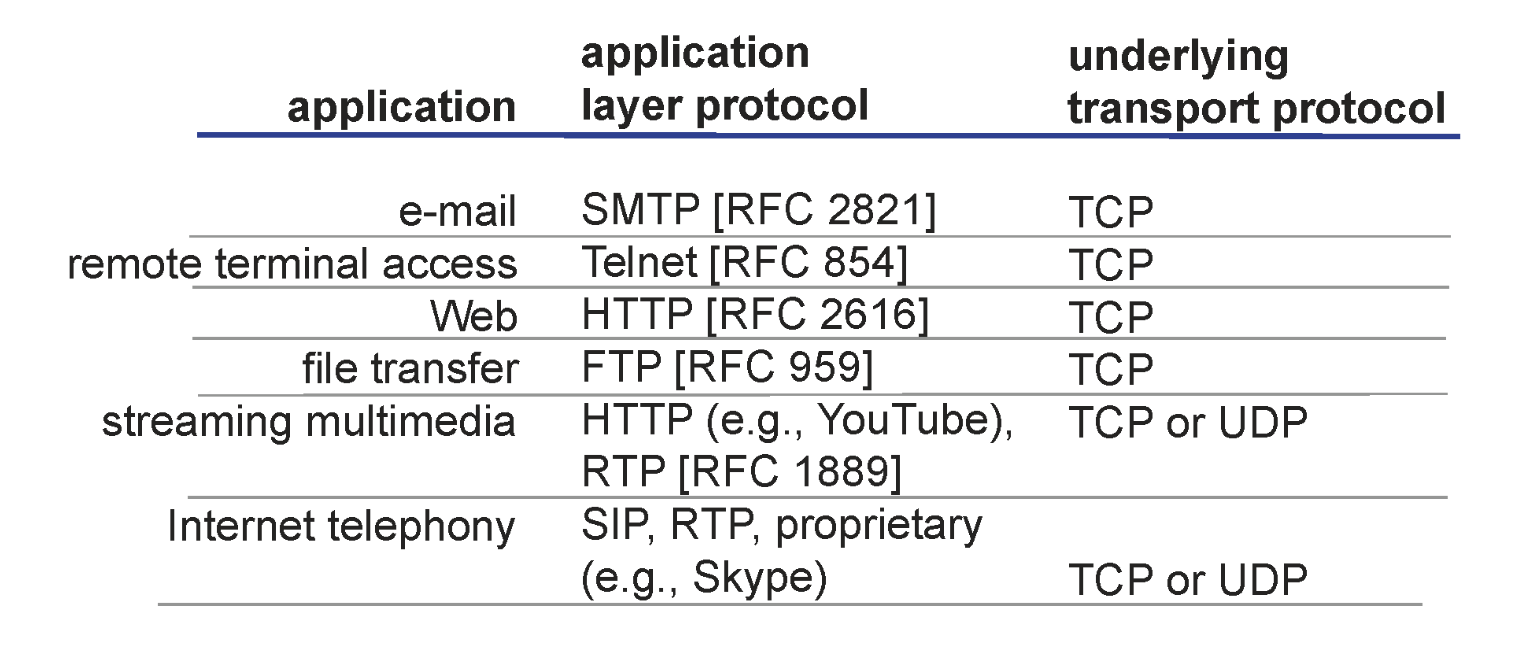
HTTP
Hypertext transfer protocol
hypertext란? 그냥 text인데, 중간중간에 링크(다른 텍스트를 지칭하는)가 있는 것이다. 단순히 이러한 텍스트들을 전송하는 protocol들이다.

HTTP는 TCP를 사용하기 때문에 request, reponse 전에 TCP connection이 있어야한다.
stateless하다. request가 들어오면 해당 파일을 읽어서 response를 보내주고 끝이다. 전혀 상대방에 대해 기억하지 않는다. HTTP는 TCP를 기반으로 데이터를 주고 받는데, TCP를 사용하는 방식에 따라 두가지로 나뉜다.
TCP 연결을 위해선 request, response 전에 TCP connection을 생성해야한다. TCP connection을 생성해 메세지를 주고 받고 connection을 끊으면 non-persistent이고, connection을 끊지 않고 유지하면서 재사용하면 persistent이다.
예를 들어 Naver에서 기사를 읽는다고 가정하자. 이때 기사에는 여러 그림들이 있다. 따라서 전송될 때는 main 기사, 그림 여러장이 각각 전송되어야한다.
만약 non-persistent라면,
1. TCP connection 생성
2. main 기사 request
3. 기사 response
4. TCP connection 끊음
5. TCP connection 생성
6. 그림 request
...
가 될 것이다. 반면에 persistent는 TCP 연결을 끊지 않고 main 기사를 response 받은 뒤에도 그림들을 요청해 계속 받을 수 있는 것이다.


위의 그림은 non-persistent를 나타낸 것이다.
4에서 서버는 자신이 보낼 것을 다 보냈으면 close하고 클라이언트에서 최종적으로 자기가 받을 것을 다 받았다면 확인하고 connection을 끊는다.
HTML 파일을 보다면 <img href=와 같이 읽어와야 하는 그림들이 있다. 따라서 HTML 파일을 쭉 읽다가 필요한 그림을 그때 그때 찾아오는 것이다. 현재 인터넷에서는 non-persistent보다 persistent를 사용한다.
non-persistent나 persistent의 개념 자체는 HTTP 입장에선 같으나 TCP connection을 끊느냐 안끊느냐 차이이다.
출처
