📌 저장 프로시저란?
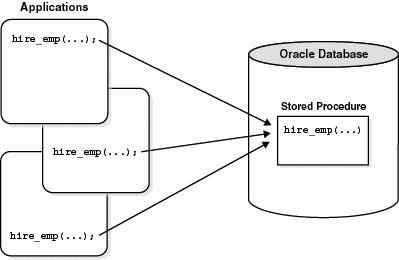
저장 프로시저(Stored Procedure)는 데이터베이스 내에 미리 정의된 SQL 코드 블록이며, 하나 이상의 SQL 문을 그룹화하고 실행 가능한 단위로 만든 것입니다. 저장 프로시저는 주로 데이터베이스 서버에서 실행되며, 데이터 조작, 조회, 비즈니스 로직 수행 등 다양한 작업을 수행하는 데 사용됩니다.
- SQL Server에서 제공되는 프로그래밍 기능. 쿼리문의 집합
- 어떠한 동작을 일괄 처리하기 위한 용도로 사용.
- 자주 사용되는 일반적인 쿼리를 모듈화시켜서 필요할 때마다 호출
- 테이블처럼 각 데이터베이스 내부에 저장
📌 작동 방식
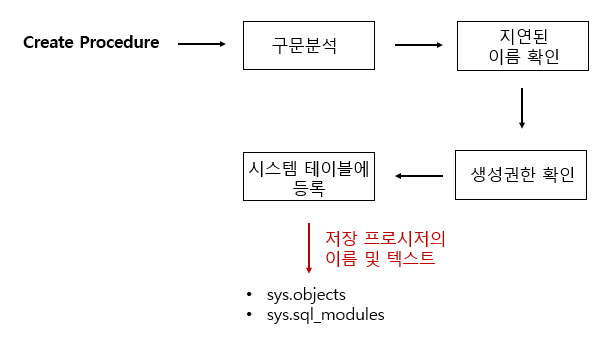
구문분석 : 구문의 오류 파악
지연된 이름 확인 : 저장 프로시저를 정하는 시점에서 해당 개체(ex. 테이블)가 존재하지 않아도 상관없습니다. 프로시저 실행 당시에 테이블 존재 여부를 확인합니다.(개체이름 확인).
생성권한 확인 : 현재 사용자가 저장 프로시저를 생성할 권한이 있는지 확인합니다.
시스템 테이블 등록 : 저장 프로시저의 이름 및 코드가 시스템 테이블에 등록합니다.
처음으로 저장 프로시저 실행
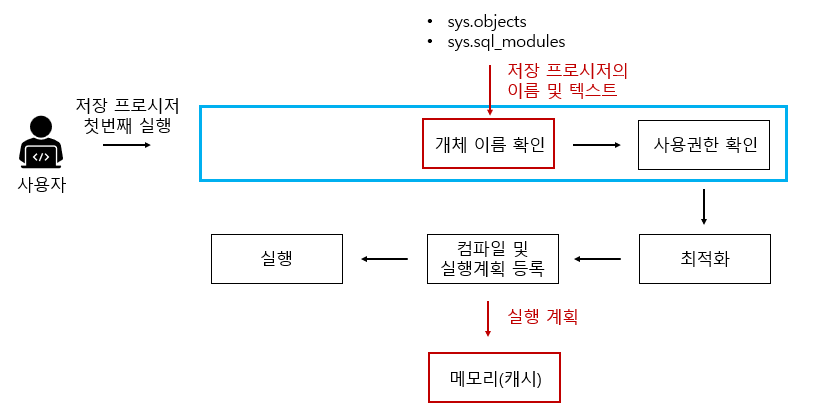
구문분석 단계가 빠지는 것만 빼면 일반적인 쿼리문 수행단계와 동일합니다. 저장프로시저 정의 단계의 지연된 이름확인에서 미루어두었던 해당 개체 존재 유무를 개체 이름 확인을 통해 수행합니다.
이후 저장 프로시저 실행
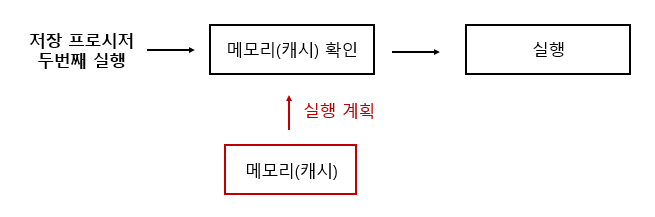
이후에 두번째 실행 부터는 메모리(캐시)에 있는 것을 그대로 가져와 재사용하게 되어 수행시간을 많이 단축합니다.
프로시저 생성 및 호출
CREATE OR REPLACE PROCEDURE 프로시저명(변수명1 IN 데이터타입, 변수명2 OUT 데이터타입) -- 인자 값은 필수 아님
IS
[
변수명1 데이터타입;
변수명2 데이터타입;
..
]
BEGIN
필요한 기능; -- 인자값 활용 가능
END;
EXEC 프로시저명; -- 호출CREATE OR REPLACE PROCEDURE : 저장 프로시저를 생성하거나 변경하는 명령어
(변수명1 IN 데이터타입, 변수명2 OUT 데이터타입) : 저장 프로시저의 입력 파라미터와 출력 파라미터를 정의
IS : 저장 프로시저 본문의 시작을 나타내는 키워드
BEGIN : 실제 저장 프로시저의 본문을 시작하는 키워드
END : 저장 프로시저 본문의 끝을 나타내는 키워드
EXEC 프로시저명 : 생성한 저장 프로시저를 실행하는 명령어, 저장 프로시저가 실행되면서 입력 파라미터로 전달한 값에 따라 프로시저 내부에서 정의한 작업이 수행
📌 장단점
장점
SQL Server의 성능을 향상
저장프로시저의 두번째 실행부터는 캐시(메모리)에 있는 것을 가져와서 사용하므로 속도가 빨라진다. 또한, 여러개의 쿼리를 한번에 실행할 수 있습니다.
유지보수 및 재활용
C#, Java등으로 만들어진 응용프로그램에서 직접 SQL문을 호출하지 않고 저장 프로시저의 이름을 호출하도록 설정하여 사용하는 경우가 많은데, 이때 개발자는 수정요건이 발생할때 코드 내 SQL문을 건드리는게 아니라 SP 파일만 수정하면 되기 때문에 유지보수 측면에서 유리해집니다.( SP 수정으로 조회, 수정, 추가 등의 가벼운 소스 변경 등이 가능)
한번 저장 프로시저를 생성해 놓으면, 언제든 실행이 가능하기 때문에 재활용 측면에서 매우 좋습니다.
강력한 보안 - 권한 체계
저장 프로시저는 사용자들에게 데이타에 대한 제한적인 접근을 허용케하는 전통적인 수단입니다. 사용자별로 테이블에 권한을 주는게 아닌 저장 프로시저에만 접근 권한을 줌으로써 테이블의 모든 정보를 사용자에게 노출하지 않고 프로시저에서 선택한 정보만 사용자에게 보여줄 수 있습니다.
네트워크의 부하(트래픽) 감소
클라이언트에서 서버로 쿼리의 모든 텍스트가 전송될 경우 네트워크에는 큰 부하가 발생하게 됩니다. 하지만 저장 프로시저를 이용한다면 저장 프로시저의 이름, 매개변수 등 몇글자만 전송하면 되기 때문에 부하를 크게 줄일 수 있습니다. (저장 프로시저를 사용하면, 서버내부에서 이동하는 모든 데이타를 임시 테이블 혹은 변수에 저장할 수 있게 된다.)
단점
DB 확장 어려움
서비스 사용자가 많아져 서버의 수를 늘려야할 때, DB의 수를 늘리는 것이 더 어렵다. 또한, DB 교체는 거의 불가능합니다.
데이터 분석 및 디버깅의 어려움
- 개발된 프로시저가 여러 곳에서 사용 될 경우 수정했을 때 영향의 분석이 어렵습니다(별도의 Description 사용).
- 배포, 버전 관리 등에 대한 이력 관리가 힘듭니다.
- APP에서 SP를 호출하여 사용하는 경우 문제가 생겨도 해당 이슈에 대한 추적이 힘듭니다.(별도의 에러 테이블 사용).
낮은 처리 성능
문자, 숫자열 연산에 SP를 사용하면 오히려 c, java보다 느린 성능을 보일 수 있습니다.
참고
- https://gyoogle.dev/blog/computer-science/data-base/Stored%20PROCEDURE.html
- https://velog.io/@sweet_sumin/저장-프로시저-Stored-Procedure
피드백 및 개선점은 댓글을 통해 알려주세요😊
