
🍀 배열의 원소 삭제하기
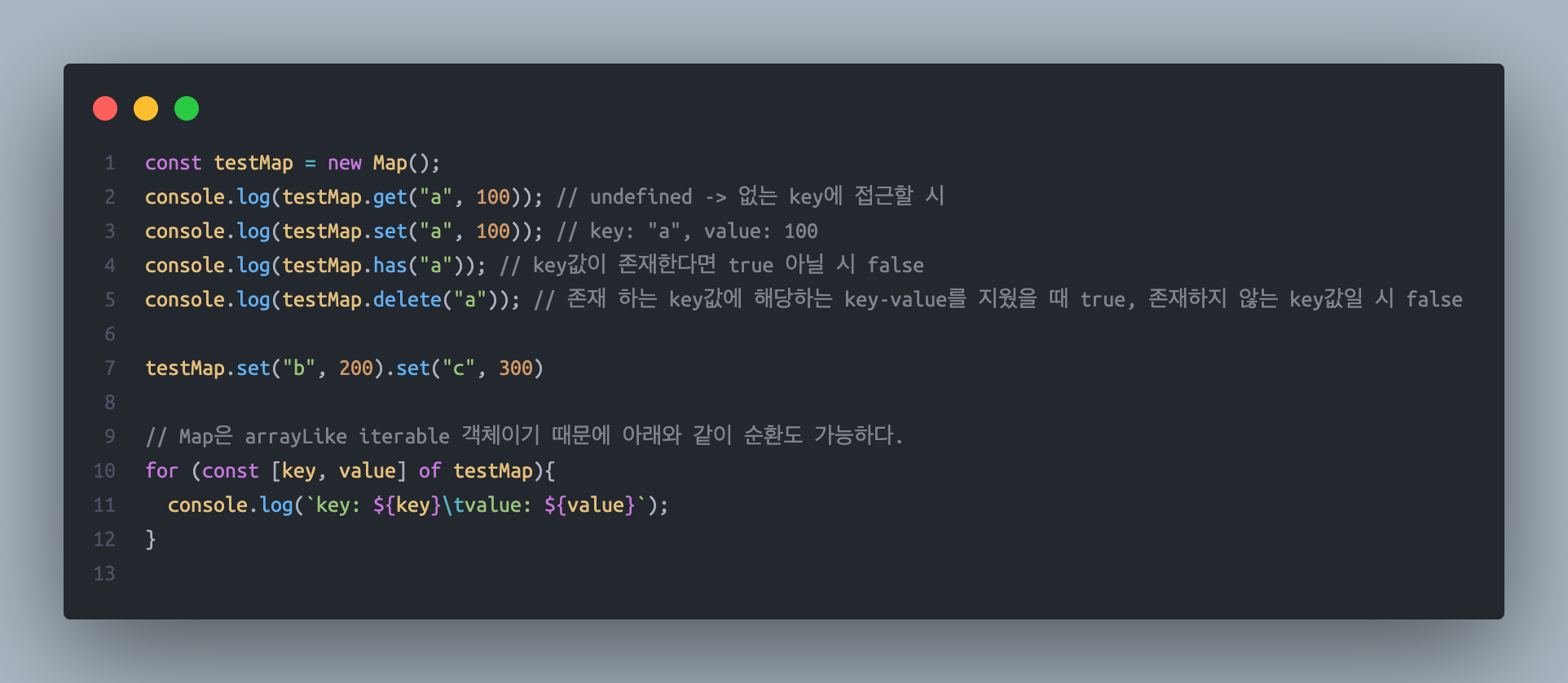
처음에는 delete_list를 돌면서 findIndex로 해당 요소의 위치를 찾아서 제거하는 방식으로 문제를 풀까 생각했으나 이 방법은 O(n^2) 의 시간 복잡도를 소요하기 때문에, 주어진 arr에 나오는 수를 key-value인 객체로 만들어 O(n) 의 시간 복잡도를 갖게 하려 했지만, 객체는 key의 순서를 보장하지 않으므로 로 key-value의 순서가 보장되는 Map 을 사용하여 문제를 풀었다. Map 은 ES6 에 나온 객체이다.
reference → Mapmdn
또한 Array.from을 항상 배열의 길이만큼 주고 fill method를 이용한 방법만 알았는데 새롭게 배워서 적용해 보았다. 아래 두 번째 풀이에서 확인가능.
1️⃣ Map으로 풀이
const createMap = (arr) => arr.reduce(
(acc, cur) => acc.set(cur, 1),
new Map()
);
function solution(arr, delete_list) {
const arrMap = createMap(arr);
delete_list.forEach(num => arrMap.delete(num));
return [...arrMap].map(num => num[0]);
}2️⃣ Array.from 적용
const createMap = (arr) => arr.reduce(
(acc, cur) => acc.set(cur, 1),
new Map()
);
function solution(arr, delete_list){
const arrMap = createMap(arr);
delete_list.forEach(num => arrMap.delete(num));
return Array.from(arrMap, ([key, _]) => key);
}reference → Array from
The
Array.from()static method creates a new, shallow-copiedArrayinstance from an iterable or array-like object.💡💡
Array.from(iterable object, callback)
3️⃣ python 풀이
python에는 dict이라는 객체가 존재하는데, version 3.7 부터 key의 순서를 보장한다고 한다.
reference → default dict usage
처음에 어떤 타입의 데이터를 저장할 지에 따라서 default값으로 저장해주는 값이 다르다.
ex) test_dict = defaultdict(int) ⇒
값을 지정하지 않으면 0으로 자동지정.list라면 빈 배열
defaultdict을 쓰는 이유는 key 값이 존재하는지 안 하는지에 대한 조건검사를 library를 통해서 하지 않기 위함이다. defaultdict을 쓰지 않고 만든다면 아래와 같다.
for num in arr:
if num not in count_dict:
count_dict[num] = 0
count_dict[num] += 1👇 defaultdict을 이용
from collections import defaultdict
def solution(arr, delete_list):
answer = []
count_dict = defaultdict(int);
for num in arr:
count_dict[num] = 1
for num in delete_list:
try:
count_dict.pop(num)
except:
pass
return list(count_dict)
🚀 마치며
비록 프로그래머스에서 기초 트레이닝 단계이지만, 다양한 방법으로 풀기를 시도하다가 새로운 것들을 배웠다. key-value의 순서가 보장 되는 Map 을 알았으며 Array.from 을 보다 더 잘 쓸 수 있게 되었다. 기존에는 시간 복잡도를 생각을 많이 하지 않았지만, 보다 더 효율적이고 빠른 코드를 작성할 수 있게끔 정진해야겠다.
