마켓과 머신러닝
시작하기 전에
물건을 판매하는 앱 마켓에 특정 카테코리의 이름을 자동으로 알려주는 머신러닝을 개발한다.
특정 물건은 생선이다. 도미, 곤들매기, 농어, 강꼬치고기, 로치, 빙어, 송어이다.
이 생선들을 프로그램으로 분류한다고 가정하자. 어떻게 프로그램을 만들어야 할까?
특성을 알아야한다. 이를 길이로 정할 수 있지만 길이 하나만으론 어떠한 생선인지 알 수 없을 것이다.(분류를 위한 생선이 상어와 새우라면 길이로만 해결할 수 있을 것이다)
다양한 생선(class)을 판매한다면 생선들의 특성(feature)도 다양하게 정해줘야 한다.
이를 머신러닝이 스스로 기준을 찾아 class를 분류한다.
지금부터 도미와 빙어 두 가지의 class를 길이와 무게를 통해 분류할 것이다.
머신러닝에서 어러 개의 종류(class라 부른다) 중 하나를 구별해 내는 문제를
분류(classfication)라고 부른다. 특히 여기서 2개의 클래스 중 하나를 고르는 문제를이진 분류(binary classfication)라고 한다.
이진분류
도미
35 마리의 도미에 대한 길이(cm)와 무게(g) 파이썬 코드는 아래와 같다.
bream_length = [25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0, 30.7, 31.0, 31.0, 31.5, 32.0, 32.0, 32.0, 33.0, 33.0, 33.5, 33.5, 34.0, 34.0, 34.5, 35.0, 35.0, 35.0, 35.0, 36.0, 36.0, 37.0, 38.5, 38.5, 39.5, 41.0, 41.0] bream_weight = [242.0, 290.0, 340.0, 363.0, 430.0, 450.0, 500.0, 390.0, 450.0, 500.0, 475.0, 500.0, 500.0, 340.0, 600.0, 600.0, 700.0, 700.0, 610.0, 650.0, 575.0, 685.0, 620.0, 680.0, 700.0, 725.0, 720.0, 714.0, 850.0, 1000.0, 920.0, 955.0, 925.0, 975.0, 950.0]
두 특성을 숫자로 보는 것 보다 그래프로 표현하는 것이 데이터를 잘 이해할 수 있다.
길이를 x축, 무게를 y축으로 정한 그래프에 도미에 대한 데이터를 표현해본다.
이러한 그래프를 산점도라고 부른다.
이를 표현하기 위한
맷플롯립(matplotlib)의 산점도를 그리는 scatter()함수를 사용한다.
import matplotlib.pyplot as plt plt.scatter(bream_length, bream_weight) plt.xlabel('length') # 길이 plt.ylabel('weight') # 무게 plt.show() # 그래프를 보여줌
결과
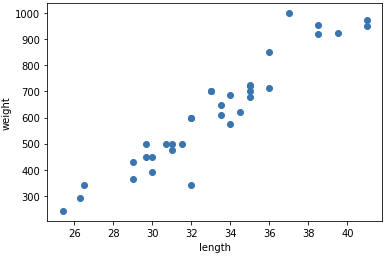
길이가 길수록 무게가 많이 나간다. 선형적인 그래프이다.
빙어
14마리의 빙어도 똑같은 작업을 해준다.
smelt_length = [9.8, 10.5, 10.6, 11.0, 11.2, 11.3, 11.8, 11.8, 12.0, 12.2, 12.4, 13.0, 14.3, 15.0] smelt_weight = [6.7, 7.5, 7.0, 9.7, 9.8, 8.7, 10.0, 9.9, 9.8, 12.2, 13.4, 12.2, 19.7, 19.9]빙어는 크기도 작고 무게도 덜 나간다.
plt.scatter(bream_length, bream_weight) plt.scatter(smelt_length, smelt_weight) plt.xlabel('length') plt.ylabel('weight') plt.show이번엔 도미와 빙어를 하나의 그래프에 색으로 구분하여 표현한다.
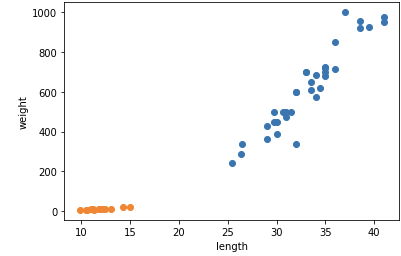
주황색 부분이 빙어의 산점도이다. 빙어는 도미에 비해 길이 무게 모두 작다.
둘이 비슷하게 길이와 무게가 비례하지만 늘어나는 정도가 다르다.
빙어는 도미와 다르게 무게가 많이 늘지 않는다.
따라서 빙어의 산점도도 선형적이지만 무게가 길이에 영향을 덜 받는다 할 수 있다.
이러한 특성은 두 번째 포스트에서 알아본다.
머신러닝 프로그램
학습
여기서 가장 간단하고 이해하기 쉬운 k-최근접 이웃(k-Nearest Neighbors) 알고리즘을 사용해 도미와 빙어의 데이터를 구분한다.
이를 위해 두 class의 두 feature를 하나로 합친다.
length = bream_length + smelt_length
weight = bream_weight + smelt_weight각각의 list는 총 49(35 + 14)개의 feature를 가지고 있다.
scikit-learn
사이킷런을 사용하여 머신러닝을 학습해줄 것이다.
이 패키지를 사용하기 위해 각 특성의 리스트를 shape(49, 2)의 형태로 만들어야 한다.
fish_data = [[l, w] for l, w in zip(length, weight)]
두 번째로 이 feature에 상응하는 class list를 만들어줘야 한다.
머신러닝은 이 두 리스트를 통해 학습한다.
도미는 1, 빙어는 0이다.
fish_target = [1] * 35 + [0] * 14 print(fish_target)
이제 사이킷런 패키지의 k-최근접 이웃 알고리즘을 구현한 클래스인 KNeighborsClassifier를 임포트하고 객체 생성.
from sklearn.neighbors import KNeigborsClassifier kn = KNeighborsClassifier()
fit() 메써드를 사용하여 머신러닝을 학습(training)한다.
인자로 feature와 class를 list 형태로 전달한다.
kn.fit(fish_data, fish_target)
이렇게 머신러닝 학습이 끝나고 정확도(accuracy)를 평가해야한다.
이를 위해 사이킷런의 score() 메써드를 사용한다. 이는 0에서 1 사이의 값을 반환한다.
1은 모든 데이터를 정확히 맞혔다는 것을 나타낸다.
정확도 = (맞힌 개수) / (전체 데이터 개수)
kn.score(fish_data, fish_target) # 1
위와 같이 반환값이 1이 나오면 모두 맞힌 것이다.
머신러닝 모델 설명
K-최근접 이웃 알고리즘
k-최근접 이웃 알고리즘이란 어떤 데이터에 대한 답을 구할 때 주위의 데이터로 현재 데이터를 판단한다.
예를 들어 산점도의 한 점이 특정 class에 가깝다면 그 점을 class로 분류한다.
k-최근접 이웃 알고리즘의 사용을 위한 조건은 필요한 데이터를 모두 가지고 있는 것이 전부다.
새로운 데이터를 예측할 때, 가장 가까운 직선거리의 어떤 데이터가 있는지를 살피면 된다.
하지만 이러한 특징 때문에 데이터가 아주 많은 경우에 사용하기 어렵다.
데이터가 크기 때문에 메모리가 많이 필요하고 직선거리를 계산하는데 많은 시간이 필요하다.
kn.predict([[30, 600]])위의 코드를 통해 특정 feature가 어떤 class로 분류되는지 확인한다.
kn._fit_x, kn._y를 print 해보면 k-최근접 이웃 알고리즘이 학습한 모든 데이터를 가지고 있는 것을 확인할 수 있다.
이는 사실상 훈련이 아니다. 그냥 저장된 값들을 가지고 최단 직선거리를 구하여 답을 맞히는 것이다.
n_neighbors
n_neighbors란 KNeighborsClassifier 객체 생성자의 매개변수로, 전달 받은 인자로 설정이 된다.
default값은 5이다. 여기서 인자의 수가 의미하는 바는 주변에 가장 가까운 5개의 비교를 통해 모델이 값을 추측한다.
이 말은, 가장 가까운 n_neighbors개의 개체만 비교한다는 것이다.
그렇다면 가장 가까운 개체의 class가 1이고 나머지 4개의 class가 0이라면, 모델은 0으로 추측한다.
가장 가까운 한 개체만 비교하는게 아니다.
kn49 = KNeighborsClassifier(n_neighbors=49) kn49.fit(fish_data, fish_target) if(kn49.score(fish_data, fish_target) == 35/49): print(True)위의 코드의 출력값은 True이다.
위의 코드를 보면 35/49는 총 개체 수에 대한 도미의 비이다.
이말은 가까운 점 49개와 비교를 하여 추측하기 때문에 도미의 개체만 맞히게 되는 것이다.
이러한 이유로 객체 생성시 인자를 잘 설정해야 한다.
KNeighborsClassfier()
k-최근접 이웃 분류 모델을 만드는 사이킷런 클래스
KNeighborsClassifier: 매개변수로 이웃의 개수를 지정. 기본값 5p: 매개변수로 거리 재는 방법 지정. 1(맨하튼 거리), 2(유클라디안 거리)n_jobs: 매개변수로 사용할 코어 지정(최단거리 계산시). -1(모든 CPU 코어), 기본값 1fit(): 사이킷런 모델 훈련 메서드. 매개변수는 특성과 정답predict(): 모델을 훈련하고 예측할 때 사용하는 메서드. 매개변수 특성 데이터 하나score(): 성능 측정 함수. 특성과 정답 데이터를 매개변수로 전달
이 함수는 predict() 매서드로 예측을 수행한 다음 분류모델의 정답과 비교하여 예측한 개수의 비율 반환
Colab
Source code
