혼자 공부하는 머신러닝 딥러닝
1.K-최근접 이웃 분류 모델(K-nearest neighbors), 이진분류
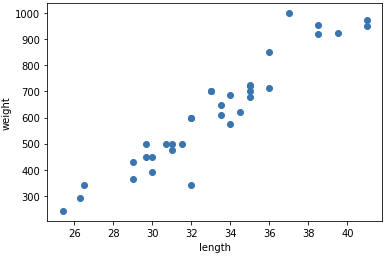
물건을 판매하는 앱 마켓에 특정 카테코리의 이름을 자동으로 알려주는 머신러닝을 개발한다.특정 물건은 생선이다. 도미, 곤들매기, 농어, 강꼬치고기, 로치, 빙어, 송어이다.이 생선들을 프로그램으로 분류한다고 가정하자. 어떻게 프로그램을 만들어야 할까? 특성을 알아야한
2.훈련 & 학습 데이터(train & test set), 무작위 추출, 샘플링 편향(1)
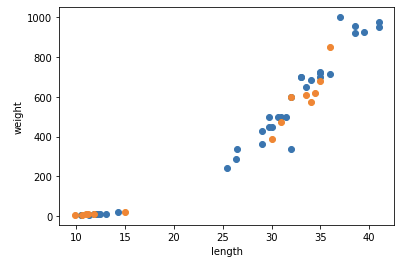
머신러닝 알고리즘은 지도 학습(supervised learning)과 비지도 학습(unsupervised learning)으로 나눌 수 있다. 지도학습은 학습 알고리즘을 위한 데이터와 정답이 필요하다.지도학습에서 생선의 길이와 무게는 입력(input)과 타깃(targe
3.데이터 전처리(Splitting & Scaling), 표준점수(standard score), 샘플링 편향(2)
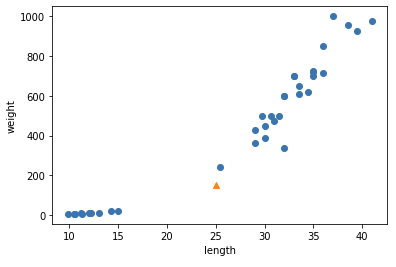
데이터 전처리 방법을 알아본다.35 빙어 14 도미 데이터타겟 데이터는 1과 0을 여러번 곱해서 만드는 것 보다 numpy의 np.ones(), np.zeros()를 사용하여 쉽게 처리할 수 있다.두 배열을 연결할 때 class 단위로 분류하기 때문에 일차원 배열로 만
4.K-최근접 이웃 회귀(K-nearest neighbors regression), 결정 계수, 과대적합, 과소적합
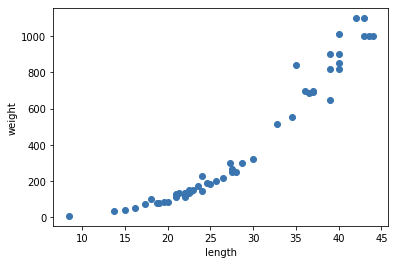
지도 학습 알고리즘은 크게 분류(Classification)와 회귀(Regression)로 나뉜다. 분류는 샘플을 클래스 중 하나로 분류하는 것이다. 회귀는 클래스 중 하나로 분류하는 것이 아니라, 임의의 어떤 숫자를 예측하는 방법이다.예를 들어, 내년도 경제 성쟝률을
5.선형 회귀(Linear regression) & 다항 회귀(Polynomial regression)
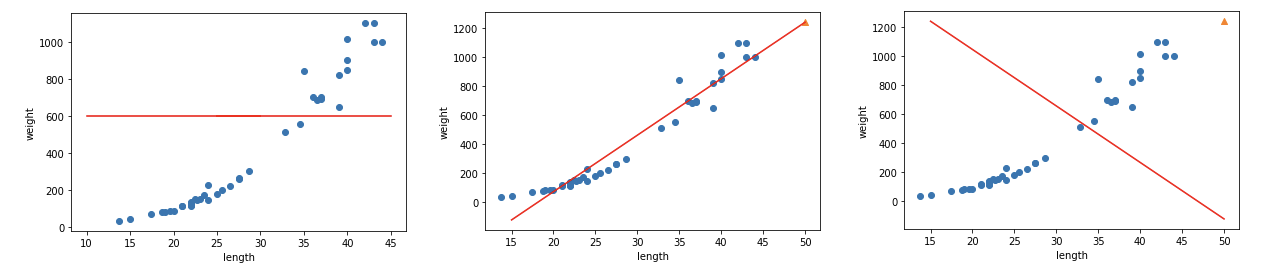
이전 모델의 내용을 그대로 가져와 확인합니다.50cm, 100cm 농어를 예측해보자.위의 코드에서와 같이 50cm, 100cm의 농어의 무게가 동일하게 나온다 문제가 뭘까?바로 이웃한 샘플의 데이터를 통해 예측을 한다는 것이다. 이 모델에서 학습한 샘플의 최고 길이는
6.다중 회귀(Multiple regression), 릿지(Ridge), 라쏘(Lasso)
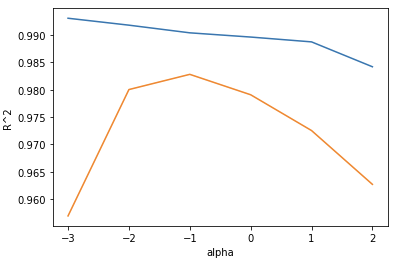
이전 포스트에서 다룬 농어는 과소적합이 있었다. 훈련 셋의 R^2값이 낮았던 것이다.이를 해결하기 위해 feature을 더 추가하여 다중 회귀 모델을 사용해보자. 다중 회귀란 두 개 이상의 특성을 사용한 선형 회귀를 의미한다.이 말은, 특성이 두 개라면 3차원의 평면을
7.로지스틱 회귀(Logistic regression)
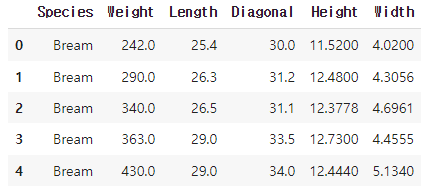
성질들을 이용하여 특정 타깃일 확률을 구하는 머신러닝을 구현해보자.특정 타깃일 확률이란 모든 class에 대한 확률을 의미한다. 이 중 가장 높은 것이 유력할 것이다.feature는 길이, 높이, 두께, 대각선의 길이, 무게를 사용한다.class 7개를 사용할 것이며
8.확률적 경사 하강법
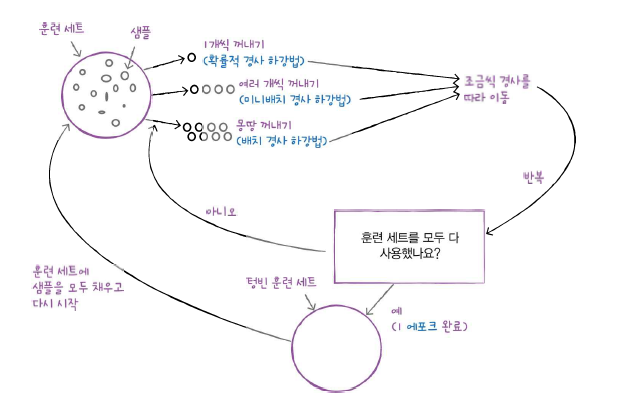
학습할 데이터가 점진적으로 제공될 때 사용할 수 있는 알고리즘이다.만약 매일 제공되는 데이터를 학습한다면 시간이 지날수록 데이터가 늘어나, 서버를 늘려야한다.이를 해결하기 위해 새로운 데이터가 제공될 때, 기존의 데이터를 버리는 방식을 사용할 수 있다. 기존의 데이터를
9.결정 트리 & pandas(통계값)
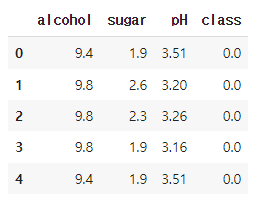
와인 데이터를 통해(도수, 당도 pH 값) 로지스틱 회귀 모델을 적용하여 훈련, 예측해보자.도수, 당도, pH이다. 그리고 class는 0이면 레드, 1이면 화이트 와인이다.로지스틱 회귀 모델을 이용한다면 화이트 와인이 1이다. 즉 양성클래스이다. 이를 골라내는 문제이