Elapsed time은 프로세스의 전체 실행 시간이였다. CPU time은 주어진 프로세스를 처리할 때 CPU가 사용된 순수 시간이다.
I/O, OS 오버헤드를 제외한 순수 CPU Time에 대해 자세하게 알아보자.
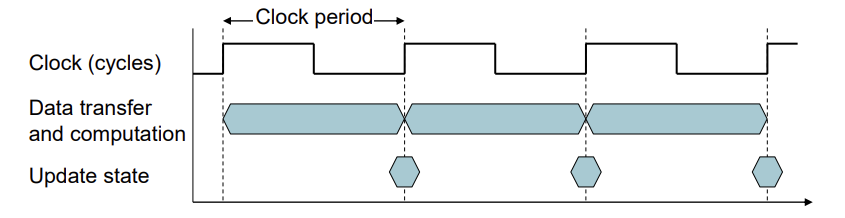
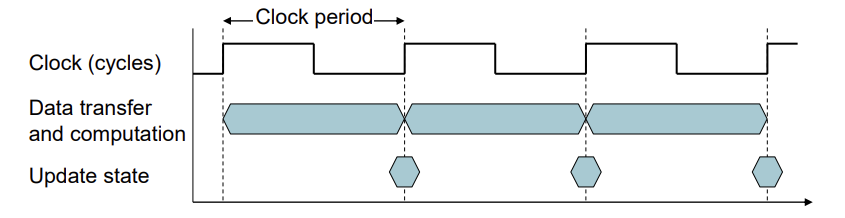
- Clock period: 한 번의 clock cycle 시간이다.
- Clock frequency: 1초당 clock cycle의 횟수이다.
둘은 역수관계에 있다.
CPU Time
CPU 시간은 다음과 같다.
Example 1
Computer A:: 2GHz clock, 10s CPU time
A를 기반으로 6s CPU Time을 가진 Computer B를 설계해 보자.
6s로 시간을 줄이면 clock cycle의 수는 1.2배 늘어난다.
위의 공식을 사용해 4GHz 답이 나온다.
Instruction Count and CPI
위의 공식에서 Instruction Count는 주어진 일을 수행하며 사용된 Instruction의 수이다.
이 수가 작아야 processor는 빠르게 동작한다.
CPI(Cycle Per Instruction)는 하나의 Instruction을 수행에 필요한 cycle 수이다.
Example 1
Computer A는 Cycle time이 0.25ns(4GHz in rate)이고 CPI는 2.0이다.
Computer B는 Cycle time이 0.5ns(2GHz in rate)이고 CPI는 1.2이다.
(서로 ISA는 같다.)
어느 컴퓨터가 얼마나 더 빠를까?
A의 CPU Time은 500ps, B는 600ps가 나온다(Instruction counter는 제외한다). 600/500는 1.2이므로 A가 1.2배 빠르다.
CPI
모든 task의 Instruction 수와 이에 대응하는 cycle 수를 곱하여 총 cycle의 수를 구할 수 있다.
여기에 총 Instruction 수로 나누어준다면 평균 Instruction에 대한 cycle의 평균 횟수를 구할 수 있다.
Which Compiler is better?

Sequence 1과 Sequence 2 컴파일러 환경에서 A,B,C에 대한 Clock cycle 수를 계산해보자.
- Sequence 1:
- Sequence 2:
두 번째게 더 좋다.
Summary
각각 총 Instruction의 개수, CPI, clock period이다.
그리고 CPU 성능에 끼치는 요인들은 아래와 같다.
- Algorithm: Instruction의 수를 줄인다. CPI에도 영향을 끼친다.
- Programming language: low level일수록 더 빠르다.
- Compiler: 프로그래밍 언어를 해석할 때 Instruction count과 CPI에 영향을 미친다.
- ISA: 명령어 set을 잘만들면 Instruction count, CPI, clock perid 모두 줄일 수 있다.(명령어가 더 간단해지면 당연히 clock cycle의 시간이 더 빨라진다.)
참고로 컴퓨터의 성능은 Clock rate를 높이며 발전했다. 그 이후 멀티코어.
Power Trends
~Capacitive load: 회로의 전체적인 크기(부하용량)~
회로가 커지면 Power가 많이 필요하다.
Power의 전압이 올라가면 이의 제곱이 Power에 영향을 미친다.
Clock Frequency을 올리고 Voltage를 낮추며 발전하였지만, 특정 시점 이후로 Voltage를 더 줄이는게 불가능해졌기 때문에, Frequency를 더 올릴 수 없게 되었다.
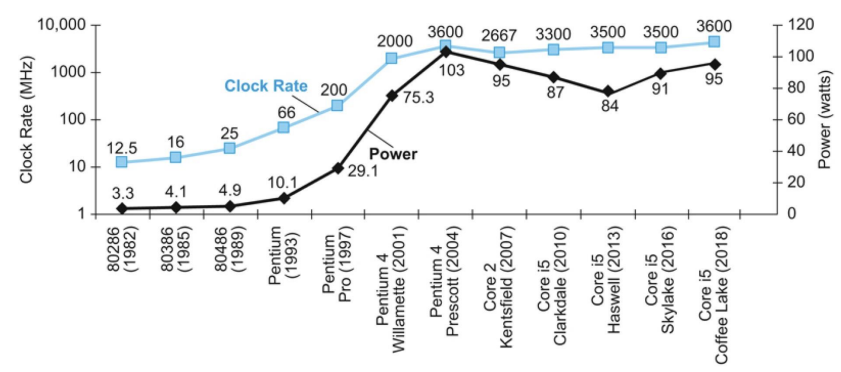
Reducing Power
CPU를 한 세대 발전한다 했을 때, 직접도가 두 배 늘어날 때마다. 같은 크기로 만들어도 Capacity load는 기존에서 85%로 줄어든다 가정한다.
Voltage와 clock frequency도 15% 줄어들었다라고 가정해보자.
위와 같이 새로운 CPU의 Power는 기존 Power의 0.52가 된다. frequency reduction이 없어도. 0.62정도가 나올 것이다. 두 배로 늘려도 1.2 정도 증가한다. 이런식으로 발전하였다.
Voltage를 더 이상 줄일 수 없게 되었고, frequency를 더 올린다면 발열 문제도 발생한다.
이를 해결하기 위해 Multiprocessors을 사용하였다.
Multiprocessors
uniprocessor는 프로세서 하나당 코어도 하나였다. 그러나 지금은 Multiprocessor라 불리는데, 이는 프로세서가 많은 것이 아니라 프로세서 안에 코어 개수가 많은 것이다. Multicore processor라 칭하는 것이 맞다.
코어가 그냥 늘어난다고 성능이 바로 확 좋아지는 것은 아니다. 이를 좋아지게 하기 위해 명시적 병렬 프로그래밍(explicit parallel programming)이 필요하다. 동시에 많은 명령어를 처리하는 Instruction level parallelism(ILP)와 다르다.
전자의 목적은 수동적으로 여러코어에 일을 분배해주는 것이다.
성능을 위한 프로그래밍은 굉장히 힘들고, laod balancing 문제가 존재한다.
추가로 일을 나눈다 해도 일의 순서가 존재할 수 있기 때문에, 하나의 프로세스의 전체 수행 시간은 동일할 수 있다.
그래도 결과적으로 elapsed time은 줄어들 수밖에 없다.
SPEC CPU Benchmark
SPEC CPU Benchmark란 CPU의 성능을 측정하기 위한 여러가지 어플리케이션을 모아놓은 셋이다.
CPU의 성능을 중요하게 여기는 워크로드들을 선별하여 구성한다.
I/O device의 접근과 같은 elapsed time에 영향을 끼치는 것들은 제외한다.
Benchmark을 통해 기존의 컴퓨터에서의 CPU 시간과 새 컴퓨터에서의 CPU 시간을 비교하여 성능을 계산한다.
각각의 어플리케이션의 수행시간의 곱의 제곱을 구한다.(기하평균)
Example
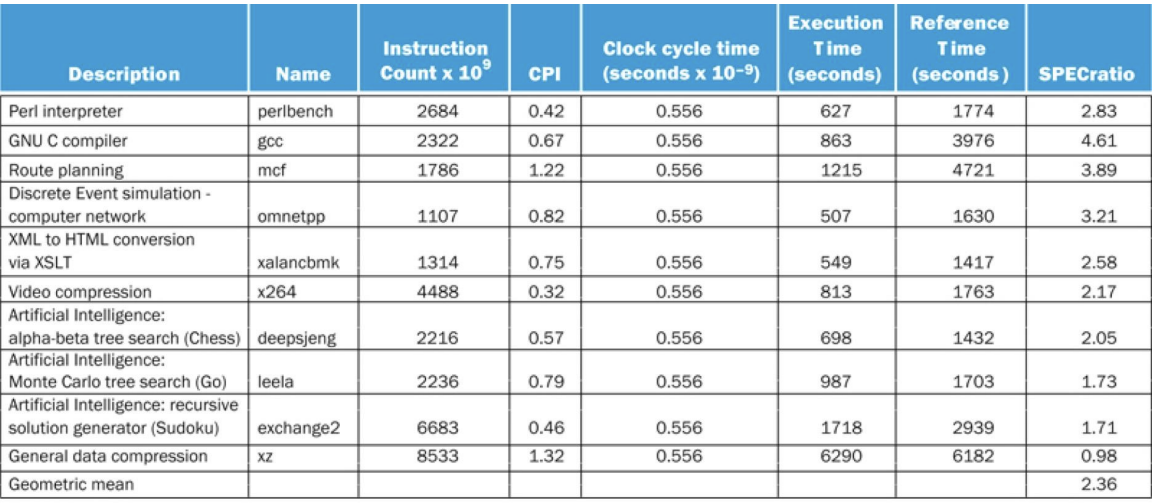
reference time: 기존 컴퓨터
execution time: 새 컴퓨터
Pitfall: Amdahl's Law
암달의 법칙을 통해 빠질 수 있는 함정을 알아보자.
만약 CPU의 성능을 50% 향상했을 때, 전체 시스템의 성능을 50%가 올라갈까? 그렇지 않다.
시스템 일부의 성능을 향상했을 때, 전체 시스템의 성능이 얼마나 향상될지를 계산하기 위해 사용된다. 아래와 같은 공식을 사용한다.
example
어떤 task를 처리하는데 100s가 걸리는데, 80s가 곱하기 연산이다. 이 시스템을 5배 빠르게 하기 위해 곱셈 연산을 얼마나 빠르게 해야할까?
n을 구할 수 없다.
Fallacy: Low Power at Idle
Power benchmark는 컴퓨터의 성능을 얼마나 쓰냐에 따라 필요한 Power의 평균값을 측정하기 위해 사용된다.
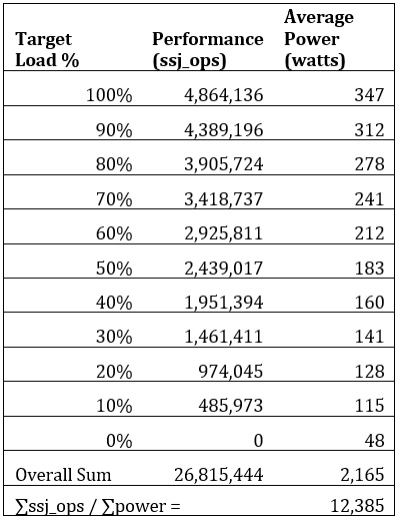
대개 컴퓨터는 10~50%의 성능을 사용한다. 100%를 사용하는 경우는 드물다.
그렇다면 10~50%의 성능을 사용할 때 파워를 적게 사용하게 하는 것이 중요하다.
100%때의 Power는 그렇게 중요한 문제는 아니다.
Pitfall: MIPS as a Performance Metric
MIPS(Millions of Instruction Per Second)란 1초간의 수행한 수백만개의 명령어 수이다.
Instruction의 개수만을 따진다. Instruction을 단순하게 만들면 하나당 시간은 줄지만 수는 많아진다. 그럼 그냥 MIPS가 크게 나온다. 좀 더 고차원적인 컴퓨터는 명령어 하나가 시간이 많이 걸리지만, 하나의 명령어로 더 많은 일을 할 수도 있다.
이는 ISA나 명령어 사이의 complexity 차이를 위해 사용하지 못한다.
보통 동일한 컴퓨터에서 하드웨어의 구조를 변경하고 이 때 성능 측정을 위해 MIPS를 사용한다.
