Computer Architecture
1.[Computer Architecture] Overview with Performance
시스템 프로그래밍 중 하나인 OS는 프로그램의 실행 시의 외부 디바이스(I/O 장치)의 자원 관리
2.[Computer Architecture] CPU Time
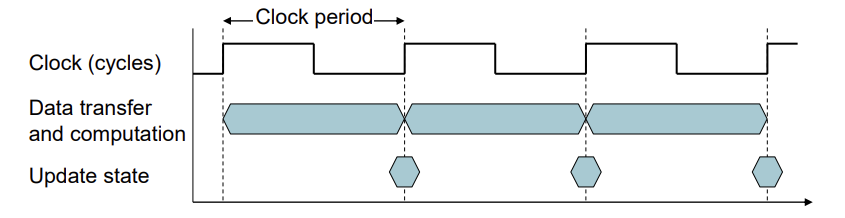
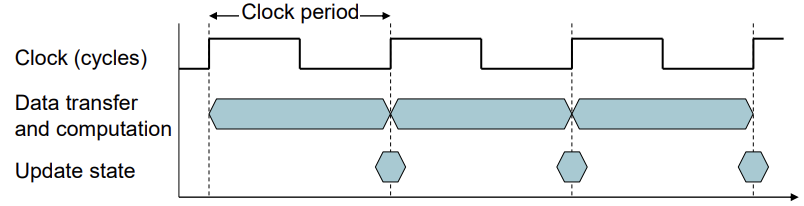
Elapsed time은 프로세스의 전체 실행 시간이였다. CPU time은 주어진 프로세스를 처리할 때 CPU가 사용된 순수 시간이다.I/O, OS 오버헤드를 제외한 순수 CPU Time에 대해 자세하게 알아보자.Clock period: 한 번의 clock cycle
3.[Computer Architecture] MIPS basics

크게 두 가지의 Instruction Set을 사용하는 컴퓨터가 있는데 각각 RISC(Redueced Instruction Set Computer)와 CISC(Complex Instruction Set Computer)이다.전자는 간단한 명령어로 구성되어 있으며 임베디
4.[Computer Architecture] Logical Operations and Procedure Call
Logical Operations 논리 연산은 다음과 같다. shift 맨 마지막 $2^i$(i = 상수)만큼 곱하거나 나누는 연산이다. 이진수로 나타냈을 때, 한 칸씩 앞으로 shift(옮긴다)한다 생각하면 된다. >sll $t2, $s0, 4 # $t2 = $s
5.[Computer Architecture] Branch addressing & Jump addressing

branch addressing과 jump addressing와 이에 필요한 명령어를 알아보자.Byte와 Half word load/store 명령어를 알아보자.lb rt, offset(rs) lh rt, ofsset(rs)rt 레지스터에 나머지 부분을 1(sign
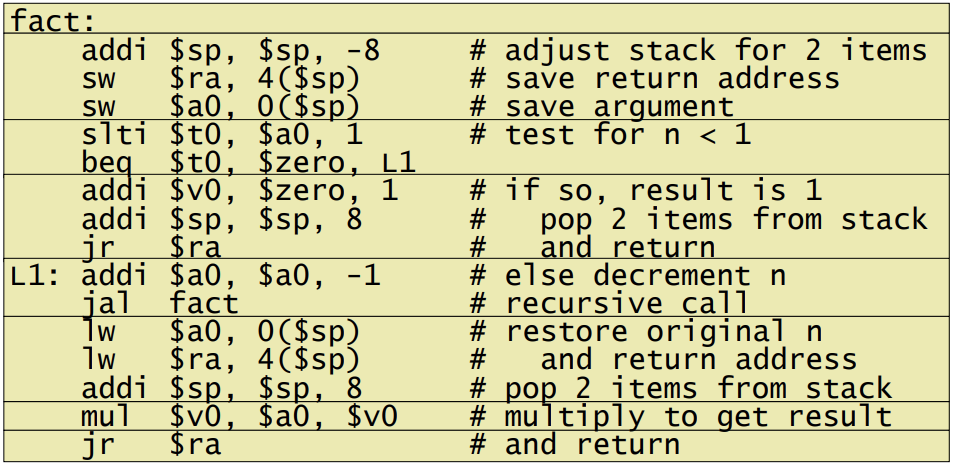
6.[Computer Architecture] Assembly to Linking
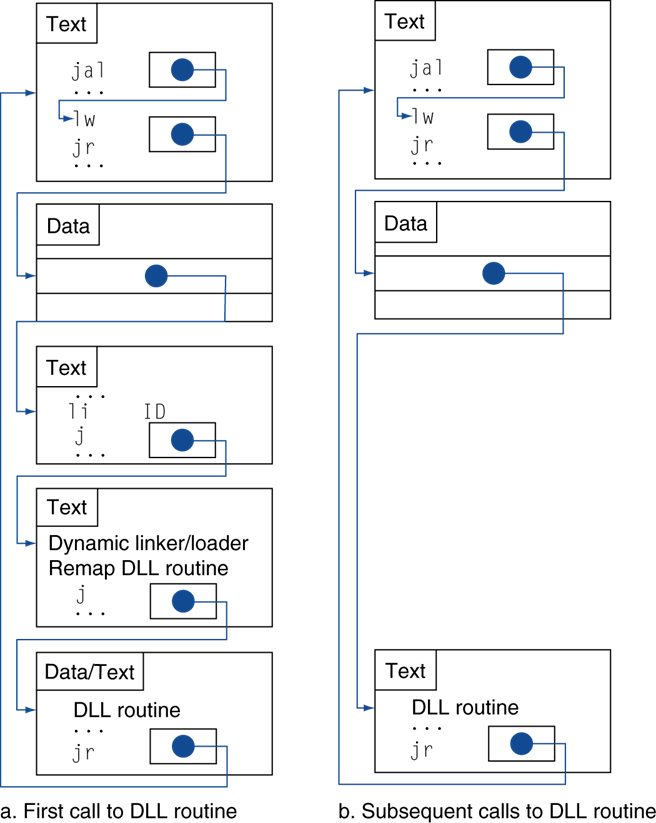
MIPS 컴퓨터 구조에 어셈블리어를 확인해봤을 때, 이는 엄연히 프로그래머 수준의 코드이다. 이러한 이유로 가독성을 높히기 위한 instruction들을 Pseudo-instruction이라 부른다.이 명령어들은 사실 존재하지 않으며 기계어로 번역되었을 때 다른 명령어
7.[Computer Architecture] Arithmetic for Computers
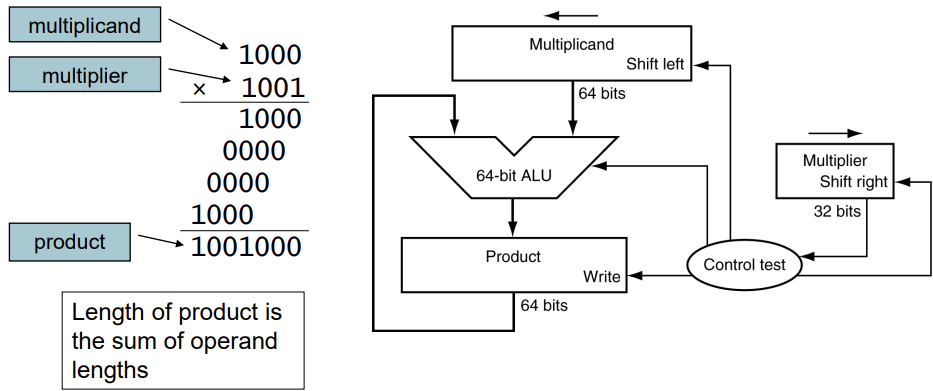
산술 연산을, 레지스터와 연산기 등 하드웨어의 관점을 중심으로 알아본다.정수, 실수, 오버플로우에 대해 모두 알아본다.MIPS에서 overflow가 일어났을 땐 프로그래밍 언어에 따라 다르다. C언어는 오버플로가 발생했을 때 아무일도 일어나지 않으므로, addu, ad
8.[Computer Architecture] Arithmetic for Computers
산술 연산을, 레지스터와 연산기 등 하드웨어의 관점을 중심으로 알아본다.정수, 실수, 오버플로우에 대해 모두 알아본다.MIPS에서 overflow가 일어났을 땐 프로그래밍 언어에 따라 다르다. C언어는 오버플로가 발생했을 때 아무일도 일어나지 않으므로, addu, ad
9.[Computer Architecture] Real ISAs
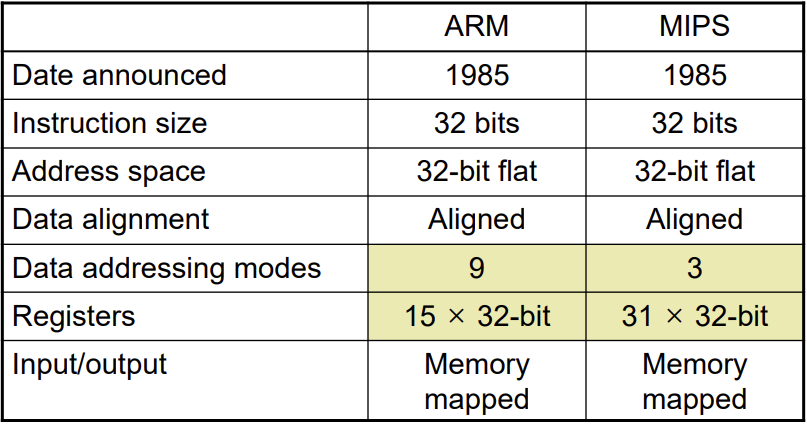
inst의 data addressing mode와 레지스터의 수 차이가 크다.(알아서 찾아봐라)ARM은 condition code(Negative, Zero, Carry, overflow)를 사용하여 MIPS 처럼 명시적으로 branch, jump와 같은 instruc
10.[Computer Architecture] Multiplication & Division
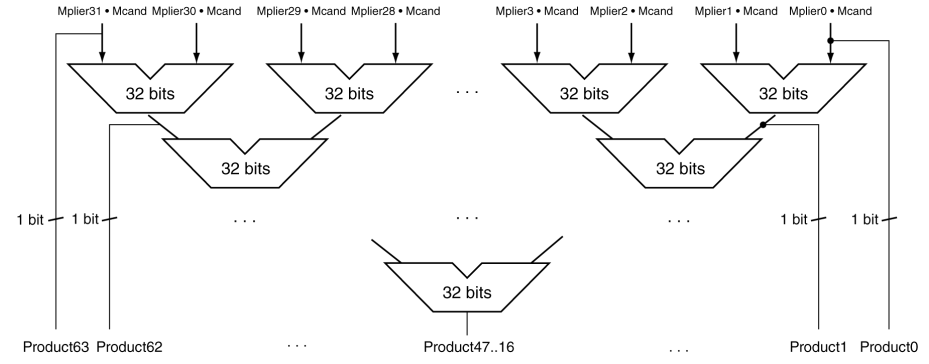
위의 사진은 많은 ALU를 사용하여 적은 cycle 수로 처리하는 multiplier이다.cycle 수도 줄고, 속도는 빨라진다. depth 5의 tree 형태로 형성되어 있기 때문에 5번의 addition이면 연산을 수행할 수 있다. 게다가 pipeline 형식으로
11.[Computer Architecture] Hardware for FP & Instructions of FP
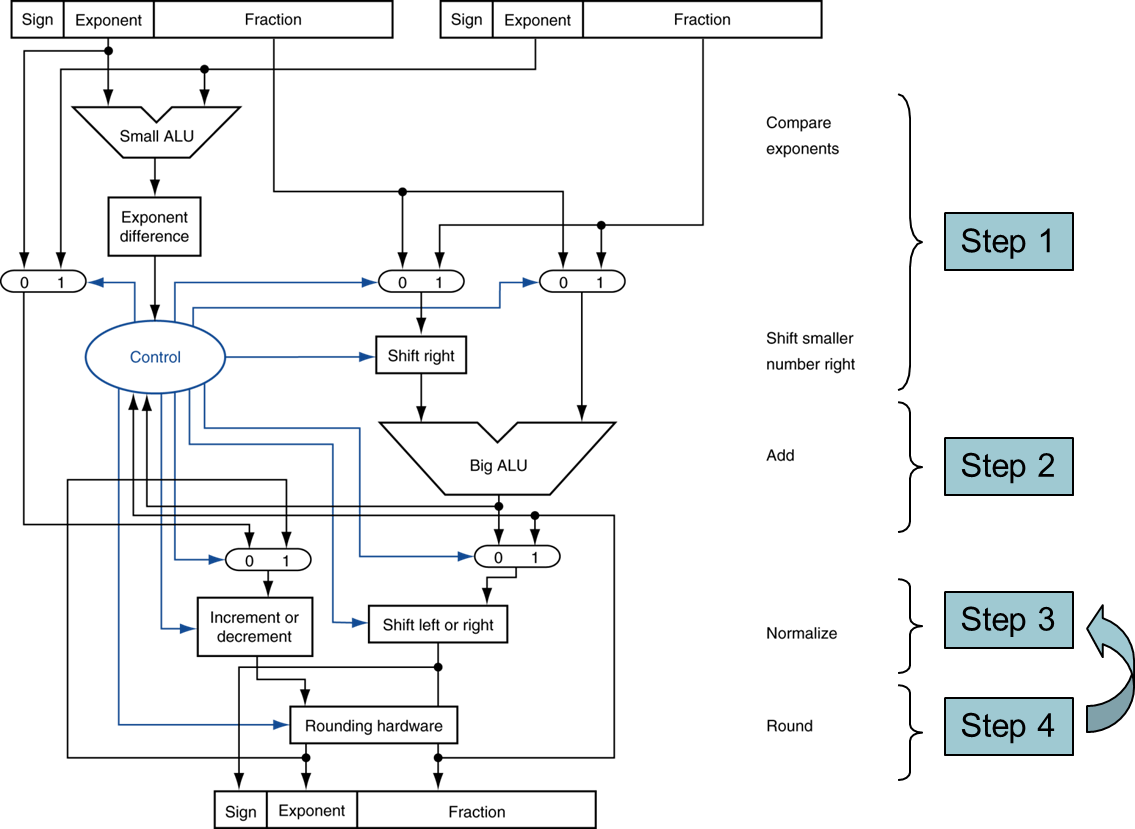
12.[Computer Architecture] Processor Implementation with MIPS(9 Instructions)
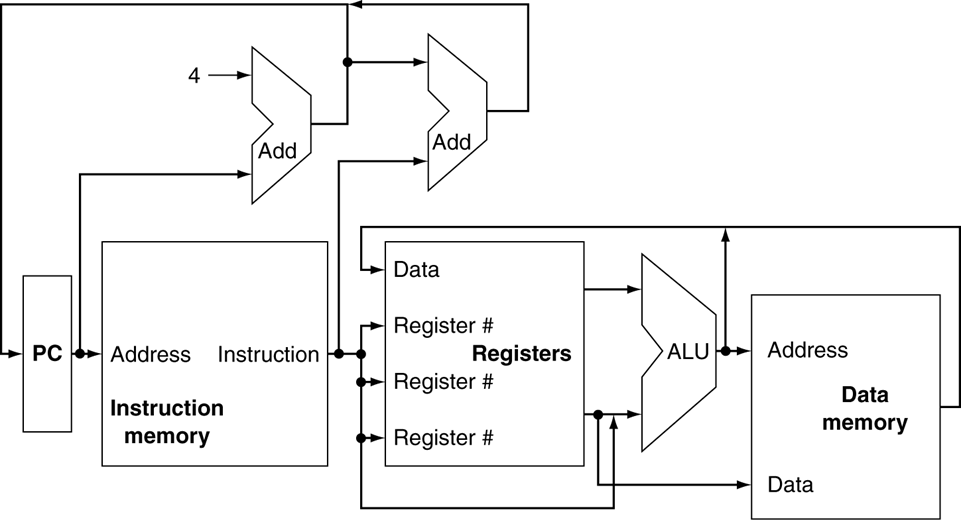
MIPS instruction 9개 lw, sw, add, sub, and, or ,slt, beq, j 에 대한 하드웨어 구현을 간단한 논리회로 지식과 함께 알아보자.CPU 성능의 척도는 대략 instruction count, CPI, Cycle time 등으로 알아
13.[Computer Architecture] Processor Implementation with MIPS(2)

이전 포스트에 이어서 진행한다.beq $t0, $t1, immediateBrach Instruction을 위해 I-format instruction의 immediate값을 16bit을 왼쪽으로 2bit shift하고 sign-extend하여 주소값에 맞게 만들어준다.(
14.[Computer Architectures] Pipelining in MIPS(1)
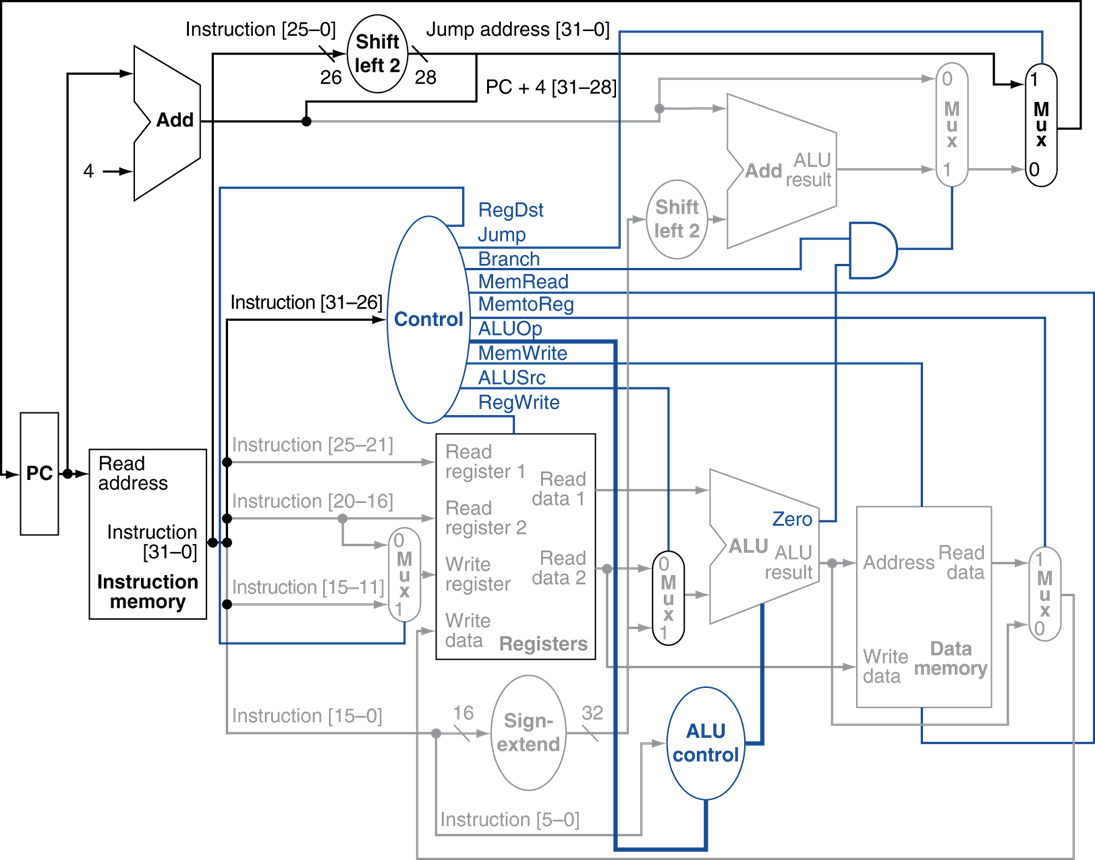
이전에 보았던 component들의 조합으로 위와 같은 MIPS 하드웨어 구현을 알아보았다.여기서 가정은 모든 instruction들이 한 cycle로 수행이 되는 것이었고, load, store instruction이 가장 오래걸리기 때문에 이를 기준으로 한 cycl
15.[Computer Architecture] Hazards
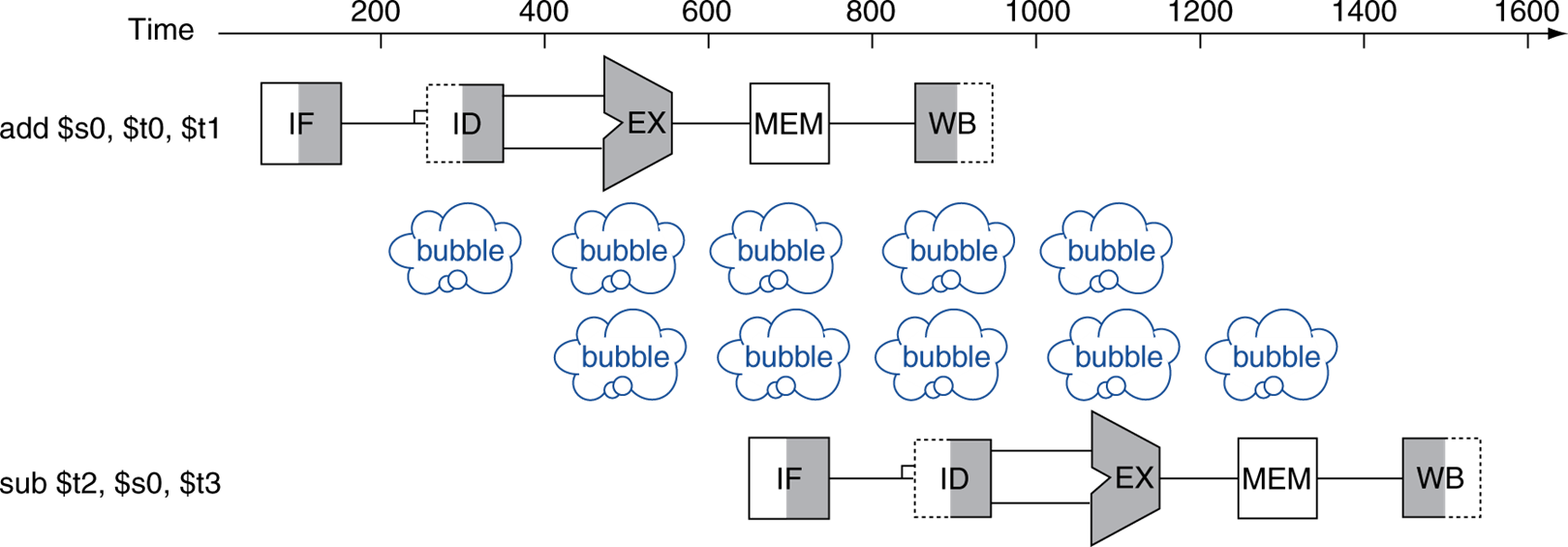
MIPS ISA에서 pipeline으로 인해 발생하는 문제점을 알아보고 이를 어떻게 해결하는지 알아보자.Structure hazards: instruction fetch, lw/sw 수행은 모두 메모리에 접근해야한다.lw/sw을 수행하며 메모리를 이미 사용하고 있기 때
16.[Computer Architecture] Parallelism vis Instruction
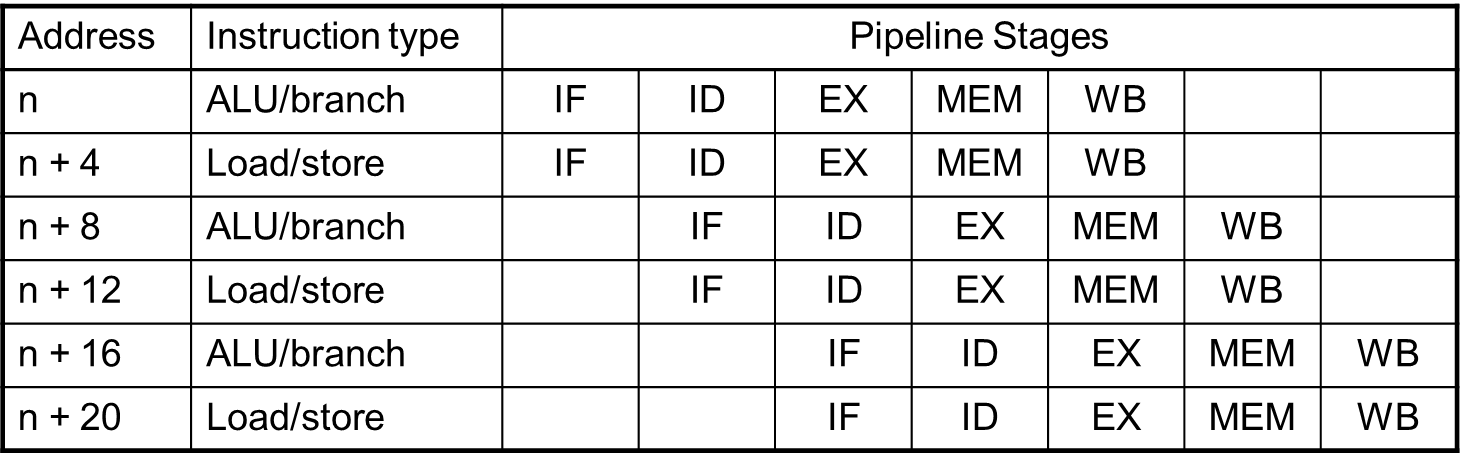
하나의 processor에서 여러 instruction을 동시에 실행해 속도를 더 빠르게 할 수 있다.이렇게 동시에 여러 개의 instruction을 수행하는 것을 Instruction-Level Parallelism(ILP)이라 한다.(멀티 프로세서와 다르다.)ILP