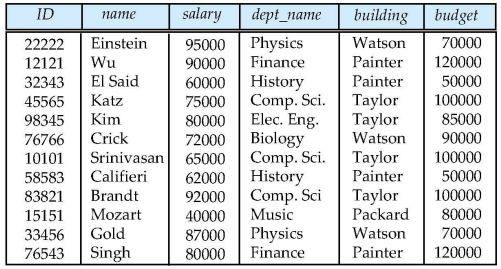
Table declarations
create table instructor (
ID char(5),
name varchar(20) not null,
dept_name varchar(20),
salary numeric(8,2))Table deletions/modifications
drop table instructor;
alter table instructor drop salary;Where clause
select: 행
from: 테이블
where: 조건select name from instructor where dept_name = ‘Comp. Sci.' and salary > 80000
Join
select name, course_id
from instructor, teaches
where instructor.ID = teaches.IDInsertion/Deletion
delete from instructor
where dept_name= ‘Finance’;
insert into instructor
values (12345, ‘Choi’, ‘Comp. Sci.’, 10000);Design database
나이를 attribute로 -> 매년 update
나이를 attribute로
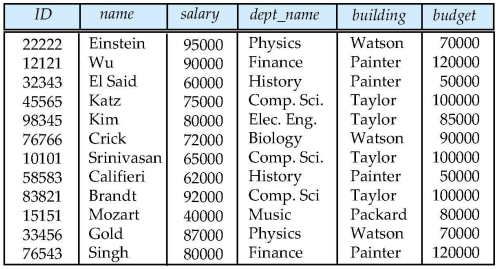
위의 문제점은 dept_name, building, budget이 중복됨.
문제점은 존재하지 않는 학과를 삽입할 수 있음, 교수 정보를 삭제하다 학과 정보가 아예 없어질 수 있음.
The Entity-Relationship Model

위의 해결책은 ER model이다. natural language의 의미를 해석하여 관계로 나누는 것이다.
"학생이 수업을 듣는다." 여기서 "듣는다"는 action이고 이는 관계를 설명한다.
정확히 학생과 수업이 관계를 이루는 것이다. 위도 마찬가지로 교수와 학과가 지도한다라는 action으로 관계를 이루고 있다.
schema를 만들기 전에 이러한 ER model로 관계를 표현한다.
(relationship을 관계로도 나눌 수 있다.)
How DB works
DB가 어떻게 동작하는지 알아보자.
Storage manager
DB와 OS 사이의 인터페이스이다. DB는 OS가 제공하는 시스템 위에서 동작한다. 테이블을 생성했을 때, Storage manager가 OS에게 요청해 file system에게 요청하여 file 형태로 만든다.
또한 indexing과 hashing을 통해 데이터 관리를 효율적으로 수행한다.
중요한점은 Stroage access(어떻게 접근), File organization(테이블을 파일에 어떻게 저장), Indexing & Hashing(얼마나 빠르게 데이터를 관리)이다.
Transaction Manager(Part of Storage manager)
atomic 연산을 보장한다. atomic한 연산이란 2개 이상으로 구성된 연산이 무조건 수행되거나 아예 수행되지 않는 것을 의미한다.
Query processor
Query processor는 사용자가 입력한 쿼리 언어를 parsing, translation을 진행한다.
또한 최적화도 수행한다.
쿼리문 처리
- Parsing and Translation
- Optimization
- Evaluation

쿼리문을 가져와 해석하고 이에 대한 값을 가져오는 수행을 할 때, 좀 더 빠르게 수행하기 위해 통계정보(예를 들어, 특정 attribute의 max 정보를 가지고 있기 때문에 모두 탐색할 필요 없음)를 이용하여 실행 plan들을 구상한다. 이 중 더 빠르다 생각하는 계획을 에측한다.
(현재엔 머신러닝도 사용된다.)
