DB
1.[DB DB basics

Database란 다양한 기준으로 체계화하여 관리하는 데이터의 집합이다. 이런식의 표현은 이해하기 쉽지 않다. 데이터베이스와 파일은 어떤 차이가 있을까? 둘 다 디스크에 저장되며 데이터를 저장하고 있지만 차이점이 존재한다.좀 더 세세하게 둘의 차이를 비교하며 데이터베이
2.[DB] SQL keywords, storage manager, transaction Manager, query processor
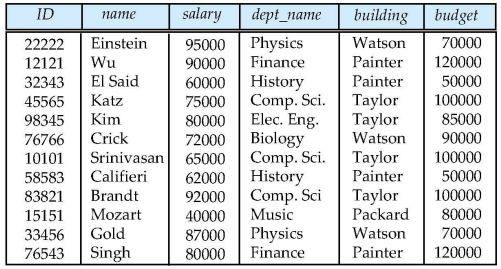
select: 행from: 테이블where: 조건나이를 attribute로 -> 매년 update나이를 attribute로위의 문제점은 dept_name, building, budget이 중복됨.문제점은 존재하지 않는 학과를 삽입할 수 있음, 교수 정보를 삭제하다 학과
3.[DB] Relational Model
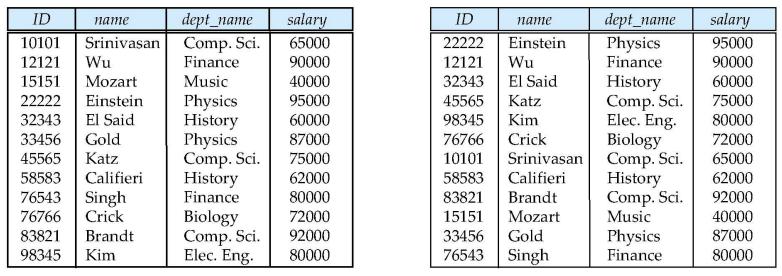
Relation은 row와 column으로 이루어진 행렬 형태의 데이터 저장소이다.이는 table의 형태이며 좀 더 formal한 정의를 알아보자.Relation은 집합간의 관계이다. 한 테이블안에서의 관계, 두 테이블의 관계 등 집합들간의 관계를 나타낸다.doimai
4.[DB] Relational Algebra
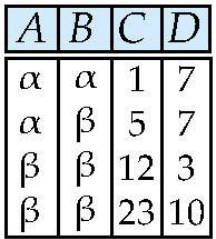
Relation algebra란 함수형 언어로 사용되며, 하나 또는 두 개의 피연산자가 필요하며 결과값은 항상 하나의 relation이다.Select: $\\sigma$Project: $\\Pi$Union: $\\cup$Set difference: $-$Cartesia
5.[DB] ER model
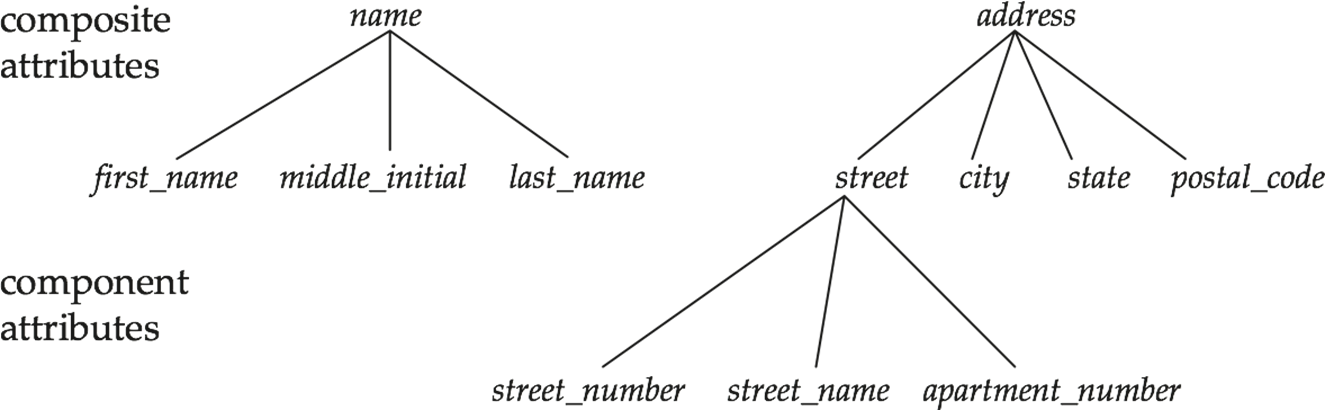
Table의 tuple들의 관계를 정의하는 Relation model 다음으로 Relation들의 model을 정의하는 ER model을 알아보자.Relational model에서, 테이블의 모델링을 배웠다면, ER model에서 테이블간의 모델링을 배운다.Databa
6.[DB] Reduction to Relational Schemas
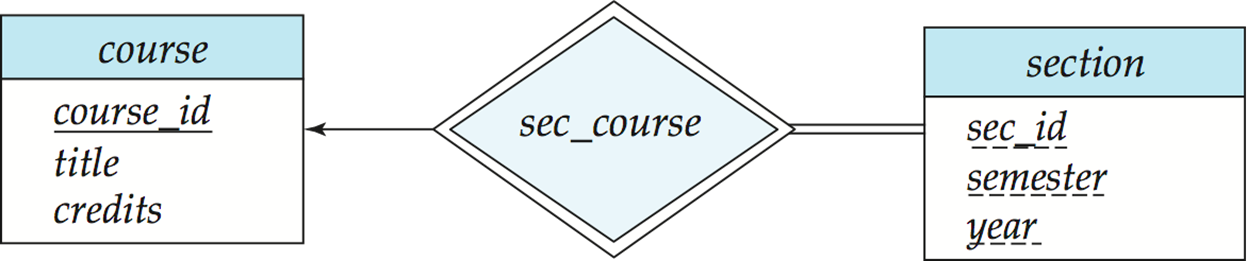
ER Model 설계를 마친 후, 어떻게 Relational Schema로 변경되는지와 이 과정에서 발생하는 문제점을 알아보자.ER Model에서 Schema로 생성하는 과정은 다음과 같다.simple attribute로 이루어진 strong entity set의 sc
7.[DB] Functional dependency & Decomposition
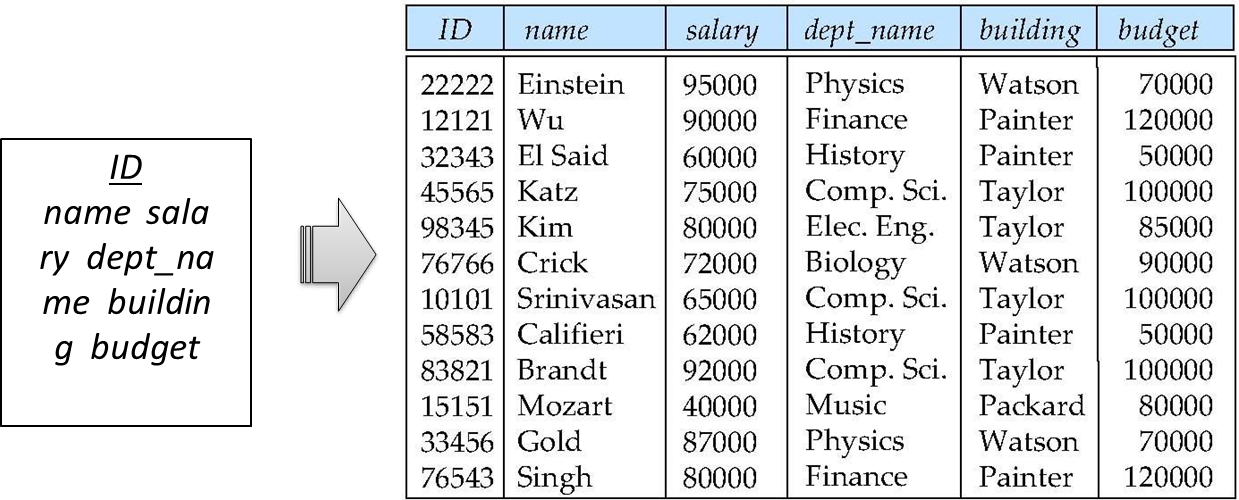
ER model을 Relational model로 변경한 후, 정규화를 수행해야한다. 데이터베이스 정규화란 현재 테이블에서 데이터 중복과 의존성을 줄이기 위한 데이터베이스 최적화이다.(relation을 쪼개어 중복을 줄이고 의존성을 최소화한다.)데이터베이스 정규화 과정
8.[DB] BCNF & 3NF

Boyce-Codd Normal Form과 Thrid Normal Form을 함수 종속성 개념과 자세히 알아보자.BCNF를 만족하기 위해 다음과 같은 조건을 만족해야한다.테스트하는 relation의 $F^+$에 있는 모든 $a \\rightarrow b$에 대해 다음과
9.[DB] Closure of Functional dependencies

$F^+$를 구하는 방법을 자세하게 알아보자.$F^+$를 구하기 위한 암스트롱의 공리를 알아보자. 이 공리를 계속해서 적용하면 $F^+$를 구할 수 있다.if $\\beta \\subseteq \\alpha$, then $\\alpha \\rightarrow \\bet
10.[DB] Storage and File structure
DB가 디바이스에 어떻게 저장되는지 확인해보자. 하드디스크, 메모리, 캐시 등 하드웨어에서 어떻게 동작하는지 알아본다. 추가로 DB를 저장하는 소프트웨어적 자료구조를 알아본다.DB에서 데이터를 사용해야할 때, 그때마다 디스크에서 메모리로 데이터를 가져온다면 굉장히 느릴
11.[DB] I/O time complexity
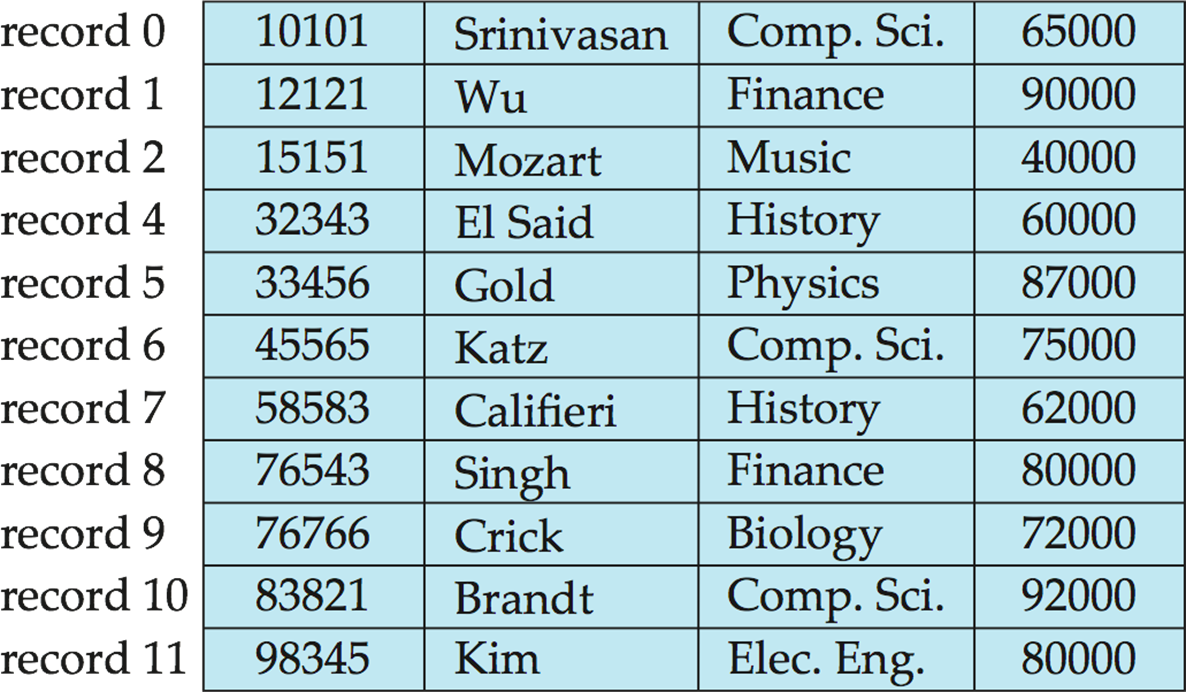
DB는 disk에 저장되기 때문에 메모리로 load를 해야한다. 이는 cost가 크며, 좀 더 효율적으로 insertion과 deletion을 수행하기 위해 I/O 연산의 time complextiy를 계산하여 더 좋은 알고리즘을 찾아야한다. External-memor