지도 학습 알고리즘
지도 학습 알고리즘은 크게 분류(Classification)와 회귀(Regression)로 나뉜다.
분류는 샘플을 클래스 중 하나로 분류하는 것이다.
회귀는 클래스 중 하나로 분류하는 것이 아니라, 임의의 어떤 숫자를 예측하는 방법이다.
예를 들어, 내년도 경제 성쟝률을 예측하거나, 배달이 도착할 시간을 예측한다.
이전에 빙어와 도미를 분류하였고 이 포스트에선 농어의 무게를 예측할 것이다.
회귀란 두 변수 사이의 상관관계를 분석하는 방법이다.
예를 들아, 아이가 부모보다 키가 더 크지 않는다는 것은 '평균으로 회귀한다.'라고 표현한다.
K-최근접 이웃 알고리즘과 회귀
K-최근접 이웃 분류 알고리즘을 다시 살펴보자
'예측하려는 샘플에 가장 가까운 샘플 k개를 선택한 다음 샘플들의 클래스를 확인하여 다수 클래스를 새로운 샘플의 클래스로 예측한다.'
회귀도 이와 비슷하다.
'예측하려는 샘플의 가장 가까운 샘플 k개를 선택한다. 하지만 분류와 다르게 이웃한 샘플의 타깃은 어떠한 클래스가 아니라
수치이다. 이수치들의 평균을값으로 특정 샘플을 예측한다.'
이제 회귀모델을 훈련해보자.
데이터 준비
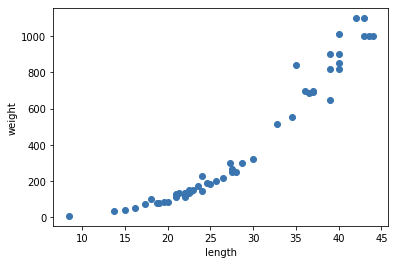
perch_length = np.array([8.4, 13.7, 15.0, 16.2, 17.4, 18.0, 18.7, 19.0, 19.6, 20.0, 21.0, 21.0, 21.0, 21.3, 22.0, 22.0, 22.0, 22.0, 22.0, 22.5, 22.5, 22.7, 23.0, 23.5, 24.0, 24.0, 24.6, 25.0, 25.6, 26.5, 27.3, 27.5, 27.5, 27.5, 28.0, 28.7, 30.0, 32.8, 34.5, 35.0, 36.5, 36.0, 37.0, 37.0, 39.0, 39.0, 39.0, 40.0, 40.0, 40.0, 40.0, 42.0, 43.0, 43.0, 43.5, 44.0]) perch_weight = np.array([5.9, 32.0, 40.0, 51.5, 70.0, 100.0, 78.0, 80.0, 85.0, 85.0, 110.0, 115.0, 125.0, 130.0, 120.0, 120.0, 130.0, 135.0, 110.0, 130.0, 150.0, 145.0, 150.0, 170.0, 225.0, 145.0, 188.0, 180.0, 197.0, 218.0, 300.0, 260.0, 265.0, 250.0, 250.0, 300.0, 320.0, 514.0, 556.0, 840.0, 685.0, 700.0, 700.0, 690.0, 900.0, 650.0, 820.0, 850.0, 900.0, 1015.0, 820.0, 1100.0, 1000.0, 1100.0, 1000.0, 1000.0])농어의 길이와 무게
- feature: length
- target: weight
산점도
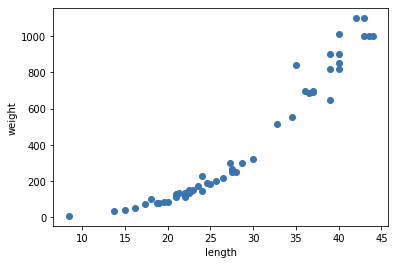
(선형적이다)
from sklearn.model_selection import train_test_split train_input, test_input, train_target, test_target = train_test_split( perch_length, perch_weight, random_state=42)75:25=train:test
사이킷런의 fit 함수는 무조건 2차원 배열을 인자로 전달한다.
import numpy as np train_input = train_input.reshape(-1, 1) # (42, 1) test_input = test_input.reshape(-1, 1) # (14, 1)
결정계수
from sklearn.neighbors import KNeighborsRegressor knr = KNeighborsRegressor() knr.fit(train_input, train_target) knr.score(test_input, train_input) # 0.9928094051010639여기서 0.9928094051010639는 테스트 셋에 있는 샘프를 모두 정확하게 분류한 개수의 비율이다.
값을 동일하게 맞힌다는 것은 거의 불가능하다. 예측하는 값이나 타깃 모두 임의의 수이기 때문이다.
평균값이니 값이 아예 동일하지 않다. 맞혔다는 말이 무엇일까?
예측한 값과 타깃 값과의 특정 계산을 통해 나온 값을 정확도로 사용한다.
이를 결정계수라 한다. 또는 R^2라 한다.
R^2 = 1 - (target - prediction)^2의 합 / (target - mean of targets)^2의 합
위와 같이 계산되며, 예측값이 타깃의 평균값과 가깝다면 결정계수는 0에 가까워지고, 타깃과 가깝다면 0에 가까워진다.

score
그렇다면 scikit-learn의 score() 매서드는 출력하는 값이 높을수록 좋으나, 에러율을 반환한다면 이를 음수로 만들어 실제로는 낮은 에러가 score() 메서드로 반환될 때는 높은 값이 되도록 바뀝니다.
하지만 R^2가 직감적으로 얼마나 좋은지 이해하기 어렵다. 대신 다른 값으로 계산해보자.
타깃과 예측한 값 사이의 차이를 구해 보면 어느 정도 예측이 벗어났는지 가늠하기 좋다.
타깃과 예측값의 차의 절댓값의 평균을 구합니다.
이를 위해 sklearn.metrics 패키지 아래 mean_absolute_error(test_target, test_prediction) 함수를 이용한다.
from sklearn.metrics test_prediction - knr.prdict(test_input) mae = mean_absolute_error(test_target, test_prediction) # 19.157142857142862결과에서 예측이 평균적으로 약 19g 타깃값과 다르다는 것을 알 수 있다.
과대적합 vs 과소적합
kn.score(train_input, train_target) # 0.9698923289099255test input의 R^2 값은 0.9928094051010639였다.
훈련 데이터로 에측을 했는데 왜 테스트 데이터의 R^2값보다 낮게 나올까?
이렇게 훈련 셋보다 테스트 셋 점수가 높거나 또는 두 점수가 모두 낮은 경우를 모델이 훈련 셋에 과소적합(underfitting) 되었다고 말한다.
모델이 너무 단순하여 훈련 데이터에 적절히 훈련되지 않은 경우이다.
훈련 셋이 전체 데이터를 대표한다고 가정하기 때문에 훈련 셋을 잘 학습하는 것이 중요하다.
이와 반대로 훈련 셋에서 점수가 좋았는데 테스트 셋에서 점수가 굉장히 나쁘면 모델이 훈련 셋에 과대적합(overfitting) 되었다고 말한다.
즉 훈련 셋에만 잘 맞는 모델이라 테스트 셋이나 실전에 투입하여 새로운 샘플에 대한 예측을 수행할 때 잘 동작하지 않을 것이다.
원인
과소적합이 일어나는 다른 원인은 훈련 셋과 테스트 셋의 크기가 매우 작기 때문이다.
여기서 학습한 모델에서 굉장히 작은 데이터를 사용했기 때문에 이러한 결과가 도출됐다.
데이터가 작으면 테스트 셋이 훈련 셋의 특징을 따르지 못할 수 있다.
해결
모델을 조금 더 복잡하게 만들면 이 문제점을 해결할 수 있다.
즉 훈련 셋에 더 잘 맞게만들면 테스트 셋의 점수는 조금 낮아질 것이다.
모델을 복잡하게 만드는 방법은 이웃의 개수 k를 줄이는 것이다.
이웃의 개수를 줄이면 훈련 셋의 있는 국지적인 패턴에 민감해지고, 이웃의 개수를 늘리면 데이터 전반에 있는 일반적인 패턴을 따를 것이다.
여기서 기본값 5를 3으로 맞추어보자.
knr.n_neighbors = 3 knr.fit(train_input, train_target) knr.score(train_input, train_target) # 0.9804899950518966k 값을 줄였더니 훈련 셋의 R^2 점수가 높아졌다. ㅇ
knr.score(test_input, test_target) # 0.974645996398761예상대로 테스트 셋의 점수는 훈련 셋보다 낮아졌으므로 과소적합 문제를 해결했다.
또한 두 점수의 차이가 크지 않으므로 이 모델이 과대적합 된 것 같지도 않다.
이 모델이 추가될 농어 데이터에도 일반화를 잘할거라 예상할 수 있다.
