프로세스 과정에 발생하는 동기적, 비동기적 Exception의 원리, 동작, 처리 과정에 대해 알아보자.
Interrupt Mechanism(1)
Interrupt란 프로세스 처리 중에 일어나는 와부의 사건이다. 프로세스의 Instruction을 처리중 발생하며, 명령어를 끝내고 사건을 처리하는 Interrupt handler를 OS에게 수행하게 하여 이를 처리한다.
Interrupt를 처리하기 위해서의 하드웨어 그리고 소프트웨어적으로의 처리방식을 자세하게 알아보자.
Purpose of Interrupt
interrupt를 사용하는 이유는 시스템, 즉 CPU utilization(활용성)을 높히기 위해 진화되었다.
이전 포스트에서 봤듯이 I/O 디바이스는 상당히 느린 편이다.
만약 I/O 디바이스의 데이터 전송을 CPU가 주기적으로 검사, 대기(polling)한다면 굉장히 느릴 것이다.
I/O 다이바스의 데이터 전송이 끝났을 때, signal을 보낸다면 이 과정이 처리되는 동안에 CPU는 유의미한 일을 할 수 있을것이기에, interrupt를 사용해 활용성을 높일 수 있다.
timer
현대의 OS들은 대부분 time slice가 존재한다.(ex 4ms) 4ms마다 process switch가 일어나는데, 이를 위해선 시간을 재야한다. 이를 위해 컴퓨터 시스템은 시계가 있는데 총 두 가지 시간을 제공한다.
- 상대시간 : 매 4ms 시간마다 시간을 알려주는 system timer가 존재한다.(resoultion이 존재한다.)
- 절대시간: 진짜 시간을 알려주는 timer가 존재한다.(bias clock으로도 불린다.)
system timer가 4ms마다 시간을 업데이트하고 인터럽트를 발생한다.
인터럽트를 처리하는 Interrupt handler의 실체는 OS의 함수이다.
OS의 함수를 사용하기 위해 권한이 필요한데, 그렇다면 모든 권한이 주어지는 kernel mode로 mode switch가 발생해야한다.
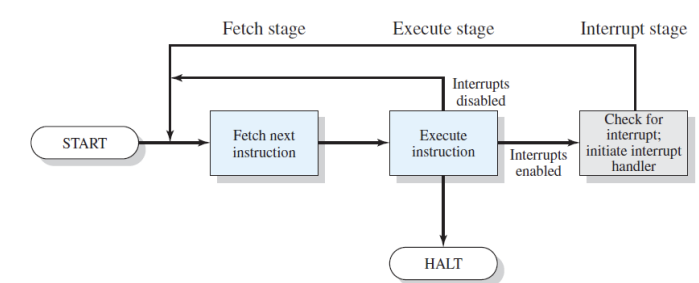
Instruction의 처리 과정 중 하나의 과정이 추가되었다.
하나의 명령어를 fetch, execute 후, 인터럽트가 발생했는지의 정보를 저장하는 one bit을 확인한다.
- 만약 인터럽트가 오지 않았다면 PC에 저장된 다음 명령어를 수행한다.
- 만약 인터럽트가 왔다면 PC값이 interrupt handler의 주소로 변경된다.
인터럽트를 처리한 이후에, 명령어가 중단된 지점으로 다시 돌아가야한다. 그렇기 때문에 PC에 핸들러의 주소를 저장하기 이전에, PC값을 다른 곳에 저장해놔야한다. 이를 프로세스가 사용하는 stack 메모리에 저장하고 인터럽트 처리 이후 다시 복원한다.(레지스터에 저장한다면 process swtich 이후 덮어쓰기 될 수 있다.)
Programmable Interrupt Controller(PIC)
PIC이란 인터럽트 제어기이다. 또 다른 하드웨어이다.
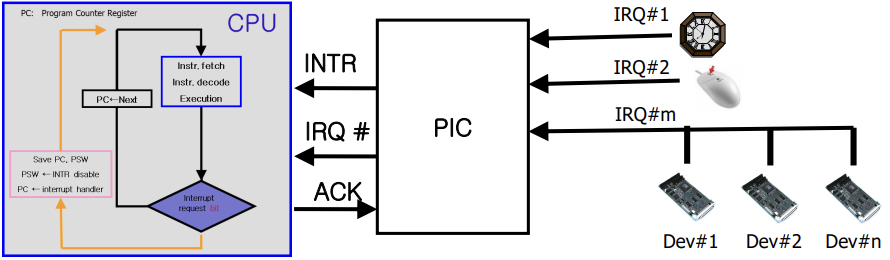
한 컴퓨터에 많은 외부 장치가 있는데, 이를 통합 관리하는 제어기이다. 제어기에 한 라인으로 외부 장치를 연결하면 이 장치가 장치를 식별하는 번호를 부여한다. 이를 Interrupt Request(IRQ)라 칭한다.
이 장치의 첫 번째 기능은 외부 장치에서 시그널이 오면, 이 시그널을 CPU에 알리며 장치 번호(벡터)를 CPU에게 전달해준다.(외부 장치 시그널 정보를 벡터에 저장한다 생각하면 된다.)
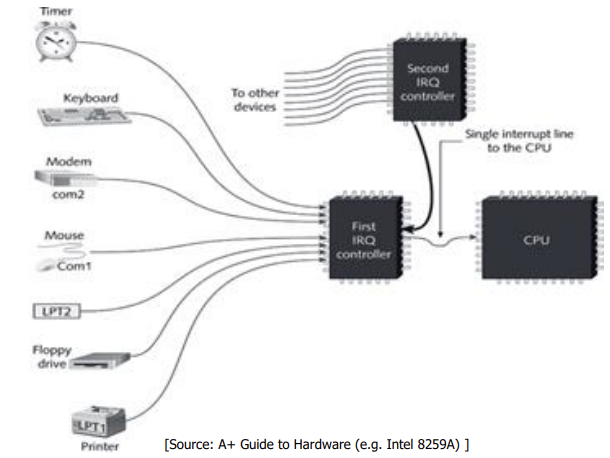
두 번째로, 내부에 레지스터, 메모리 모두 있기 때문에 프로그래밍 가능하다. 이 시그널 전송에 대한 CPU와 PIC의 프로토콜이 있다. 이에 대한 외부 장치 드라이버도 존재한다.(질문) 또한 같은 기계를 직렬연결로 확장할 수 있다.
기능을 정리하자면,
- PIC는 외부 장치의 요청을 IRQ의 번호로 변경하여 CPU에 전송한다. CPU로부터 응답을 기다린다.(동기적)
- 디바이스의 인터럽트를 disable 할 수 있다.(masking)
Interrupt Mechanism(2)
인터럽트를 처리하기 전에 PC와 같이 정보들을 stack에 저장해놔야 한다. PSW란 많은 컨디션 정보를 저장하는데 그 중 하나가 interrupt flag이다. 인터럽트를 받을지 말지에 대한 정보이다.
인터럽터를 처리하는 도중 인터럽트가 또 온다면 어떻게 할까? 현재 진행하는 인터럽트를 처리하고 나서 받는다.
이를 PSW의 interrupt flag(enable, disable)로 처리한다.
그렇다면 PC와 같이 인터럽트 처리후 기존의 프로세스의 state로 회고해야하는데, 기존의 프로세스 처리 과정 중의 PSW 상태도 stack에 저장, 복원해야한다는 것이다.
이 두 가지 레지스터 정보가 interrupt handling 을 위해 미리 저장해야할 최소한의 정보이다.(무조건 변경되기 때문에)
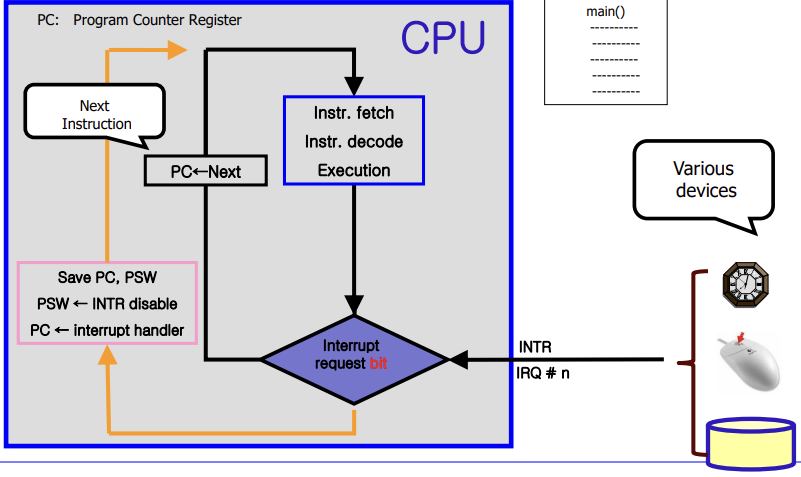
현재 진행 중인 프로세스의 명령어를 수행하는 도중에 인터럽트가 온다면(fetch or execute) 인터럽트는 바로 처리되지 않고 bit를 읽을 때까지 기다려야한다. 포스트 맨 초반에 설명한 비동기적(asynchronous) 인터럽트인 이유가 바로 이것이다.
인터럽트 bit을 읽고 인터럽트가 왔다면, PC와 PSW 정보를 stack에 저장하고 PSW를 disable로 set하고 PC에 핸들러 주소를 저장한다 이후, 핸들러(명령어) 수행은 기존의 inst cycle과 비슷하다.
Interrupt Serive Routine(ISR)
Interrup handling에 있어서, 레지스터의 정보를 저장하고 핸들러를 수행하고 모두 복구하는 것을 Interrupt handler라 칭한다. 외부 디바이스마다(device specific ex. mouse or keyboard) 존재하는 인터럽트 핸들러(OS의 함수) 개별만 가리킨다면 이것은 ISR이다.
 (어셈블리어)
(어셈블리어)
인터럽트 핸들링의 일련의 과정 중 인터럽트 발생 후 커널모드로 바꾸어 진행하는 save all은 PC, PSW를 제외하고 모든 범용레지스터의 정보를 stack에 저장한다. 이후 IRQ를 호출하여 인터럽트를 처리한 이후 restore all을 수행하여 범용 레지스터 정보를 복원한다.
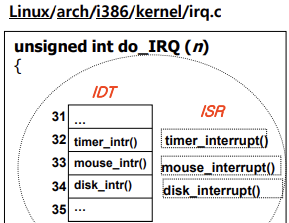
stack에 state들을 저장하고 do IRQ를 호출한다. 이 때 C언어로 넘어온다. 인터럽트 번호를 가지고 이제 핸들러를 호출하여 처리한다.
현대의 아키텍쳐는 인터럽트에 대한 번호가 존재하고 각각의 번호에 따르는 ISR의 주소(함수 포인터)를 저장하는 테이블을 가지고 있고 이를 IDT(Interrupt Descriptor Table) 또는 IVT(Interrupt Vector Table)이라 칭한다.
Interrupt Processing
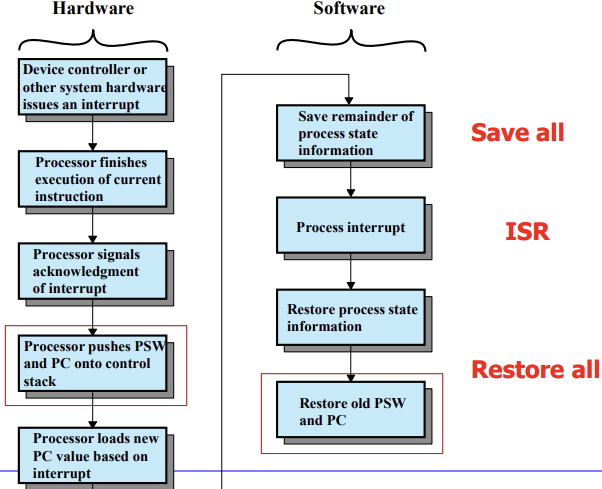
PIC가 인터럽트 발생 -> 프로세서가 현재 명령어를 끝냄 -> 프로세스가 PIC에 시그널 받았다고 응답보냄 -> PC를 인터럽트 핸들러 주소로 변경 -> PSW interrupt disable -> PSW와 PC 정보 stack에 저장 -> save all(모든 범용레지스터의 데이터) -> 커널로 모드 스위치 -> do ISR -> restore all(모든 범용레지스터의 데이터) -> PC와 PSW 정보 복원 -> 유저 모드 스위치
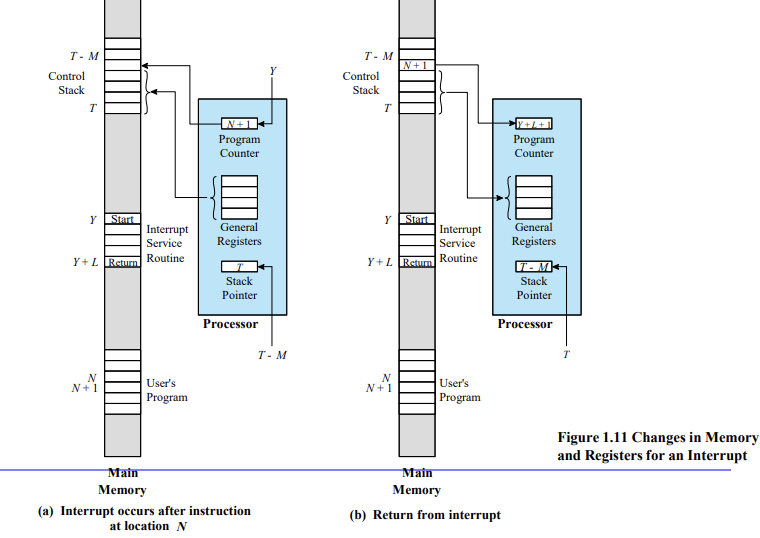
Y+L+1로 PC가 변경됨(넥스트까지 되니까) 그런데 실행되지 않고 반환
Interrupt and Exception
Exception은 이제 이해하기 쉬울 것이다. Exception이란 CPU 내부 동기적 인터럽트이다.
이 사건도 핸들러가 존재하고 리눅스에선 인터럽트와 동일하게 처리된다.
exception의 원인은 아래와 같다.
- divede by zero
- segmentation fault
- page faults
- system call(Intentional exception)
일련의 과정
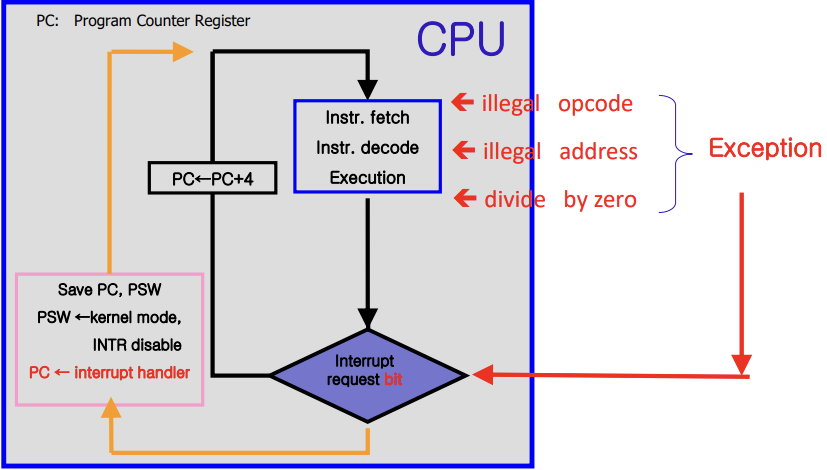
중간에 잘못되면 바로 handling 되기 때문에 동기적(synchronous)이다.
차이점
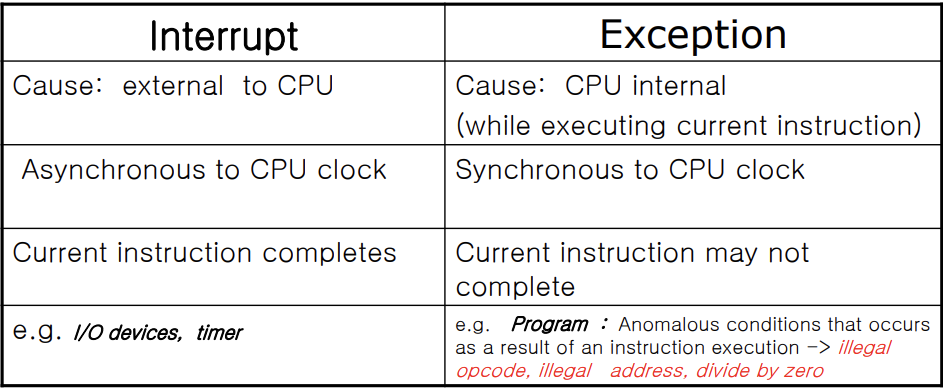
Program flow of control without and with Interrupts
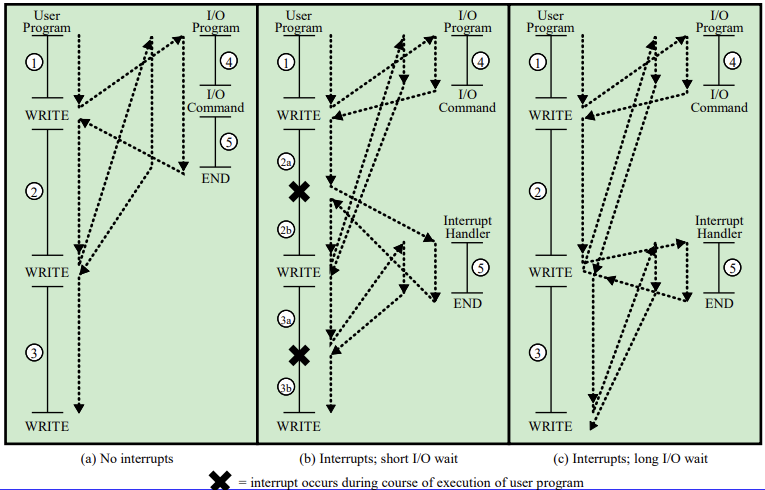
(a)의 경우 인터럽트가 없는 상태의 instruction 처리 부분이다. write 함수를 프린터 출력이라 생각해보자. 프린터를 위해 write를 호출한다면 프로세서는 기존의 명령어 수행을 중지한다, I/O 컨트롤러에 데이터를 넘겨 I/O 장치가 움직인다. 인터럽트가 없기 때문에, I/O 디바이스 작업이 종료될 때까지 cpu는 계속해서 대기(polling) 상태에 머무른다.
일련의 과정은 다음과 같다. 1-4-(대기)-5-2-4-(대기)-5-3
(b)의 경우 인터럽트를 사용하고 write 수행이 짧기 때문에 대기(polling)하지 않고 I/O 장비와 프로세서가 병렬적으로 작업을 수행하고 I/O 디바이스의 작업이 종료됐을 때 인터럽트를 발생시켜 작업을 끝낸다. 훨씬 효율적이다. 일련의 과정은 다음과 같다. 1-4-2(a)-5-2(b)-4-3(a)-5-3(b)
(c)의 경우 인터럽트가 존재하지만 I/O 작업이 긴 경우이다. write 이후 cpu가 다른 작업을 수행하다 작업이 길어 첫 번째 write가 끝나기 이전에 한 번더 write가 발생한다. 이 때의 write는 상호배제로 첫 번째 write가 끝나기 이전까지 대기 상태가 된다. 이후 첫 번째 write의 작업이 종료돼 인터럽트로 이를 끝내고 두 번째 write를 수행한다. 일련의 과정은 다음과 같다.
1-4-2-(대기)-5-4-3-(대기)-5 대기시간은 있지만 인터럽트가 없는 것보다 훨씬 효율적이다.
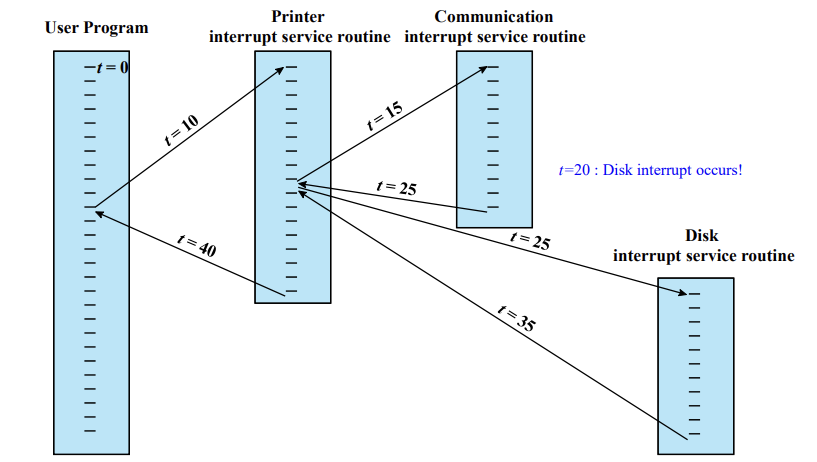
2개 이상의 Interrupt가 발생하면 어떻게 처리해야할까? 두 가지 방법을 소개한다.
Sequential Interrupt processing
말 그대로 잇달아 처리한다. 현재 처리되는 Interrupt를 처리한 후에 다음 Interrupt를 처리한다.
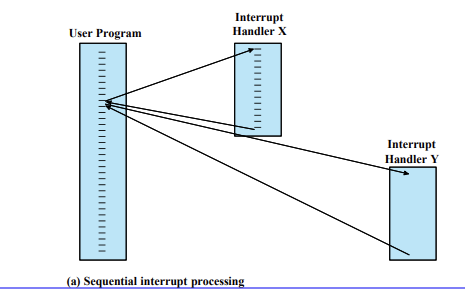
Nested Interrupt processing
Interrupt 발생 시 Interrupt의 우선순위를 기반으로 처리한다.
Interrupt를 처리하다 우선순위가 더 높은 Interrupt가 발생하면, 이를 먼저 처리한다.