OS
1.[OS] Computer System Overview I
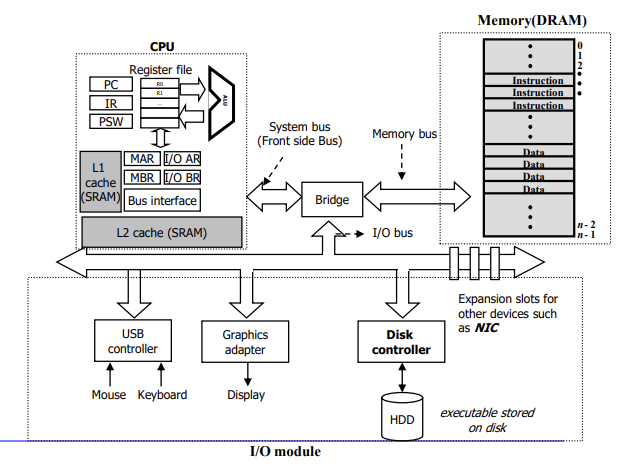
운영체제를 세세하게 배우기 이전에 전체적인 시점으로 확인해보며 기본적인 용어를 알아보자.기본적으로 disk에 저장되어 있는 실행가능한 파일은 더블클릭(윈도우) 또는 명령어(리눅스)을 통해 실행했을 때, 메모리에 로드된다. 메모리에 로드된 정보들은 Instuction과
2.[OS] Instruction Cycle(1)

컴퓨터 하드웨어의 기본적인 구성요소와 프로그램이 실행되어 Instruction이 처리되는 과정을 알아보자.메모리란 기본적으로 데이터를 저장하는 하드웨어이다. 이 데이터란 0또는 1로 구성된 구분가능한 상태 정보이다. 이 0과 1의 구성으로 문자열 또는 숫자를 표현한다.
3.[OS] Interrupt & Exception
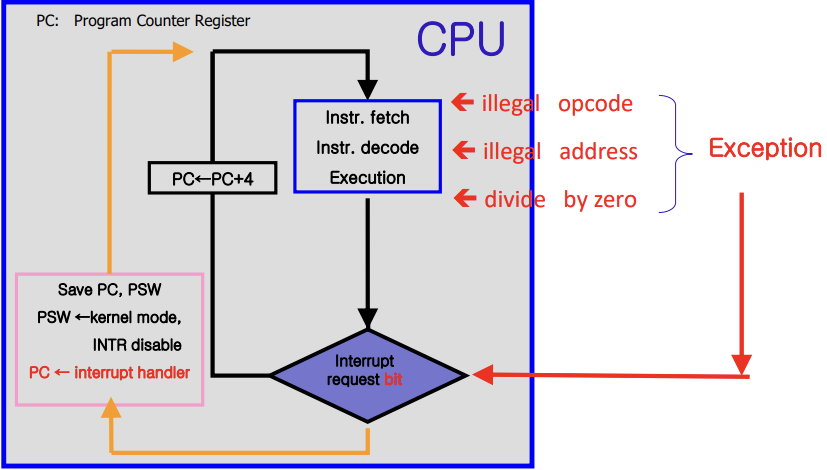
프로세스 과정에 발생하는 동기적, 비동기적 Exception의 원리, 동작, 처리 과정에 대해 알아보자. Interrupt Mechanism(1) Interrupt란 프로세스 처리 중에 일어나는 와부의 사건이다. 프로세스의 Instruction을 처리하는 중에 발생하며
4.[OS] Cache hit rate
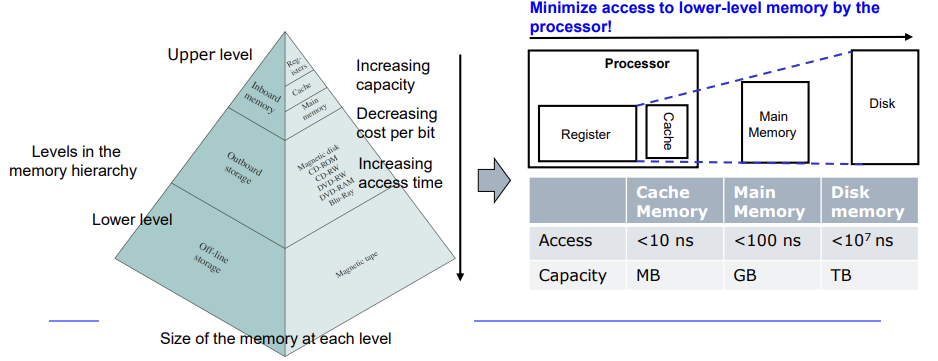
Memory Hierachy를 통해 Cache의 동작 방식과 Cache hit rate 또한 이를 높일 수 있는 방법을 알아보자.메모리란 프로그램(명령어와 데이터)을 저장하는 공간이다. 메모리의 가격, 크기, 속도를 따졌을 때, SRAM은 DRAM보다 빠르지만 비싸고
5.[OS] I/O Device
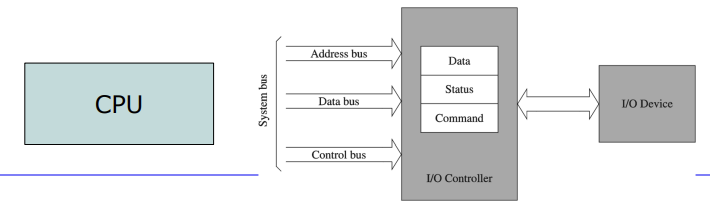
I/O 디바이스들이 주소를 가지고 메모리, CPU와 통신하는 방식을 크게 3가지로 알아보자.CPU가 I/O 장치에 접근하기 위해 데이터 전송을 위한 하드웨어인 system bus를 거치게 된다. 크게 Address bus, Data bus, Control bus 세 가
6.[OS] History of OS
위의 내용을 기반으로 OS의 진화 과정에 나오는 키워드들을 자세하게 알아보자.Serial processing이란 연속적으로 하나씩 프로세스를 처리하는 방법이다.OS가 존재하지 않던 시절 인간이 OS의 역할을 했으며, 여기서 사용하던 것이 Serial procesing,
7.[OS] Multi-programming -> Time-Sharing Systems & Resource Protection
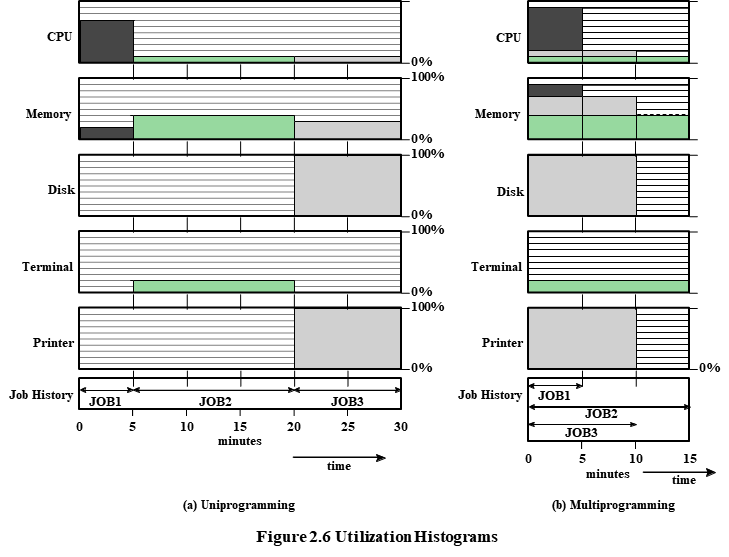
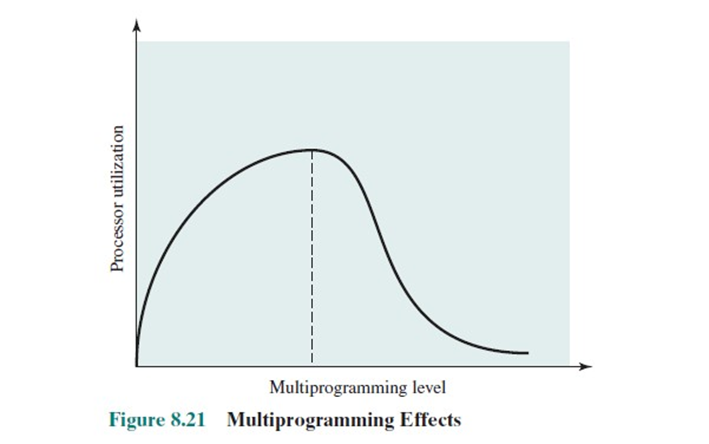
Uniprogramming과 Mutiprograming의 차이점 그리고 Mutiprogramming의 문제점에 대해서 간략하게 알아보자.위의 그림을 통해 Uniprogramming일 때와 Multiprogramming일 때의 자원 사용률을 알아보자.Process use
8.[OS] Process

프로세스, 프로그램. Scheduling, 이를 위한 자료구조 등을 알아보자프로세스란 실행 중이거나 디스크에서 실행 가능한 프로그램을 의미한다.프로세스는 instruction의 sequence와 프로세스를 위한 하드웨어(레지스터)의 상태(정보), 자원(procedure
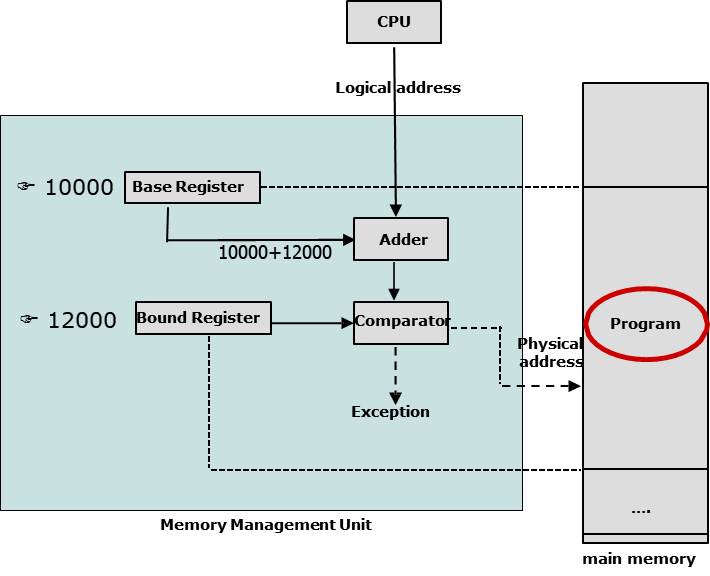
9.[OS] Mode switch & Process switch
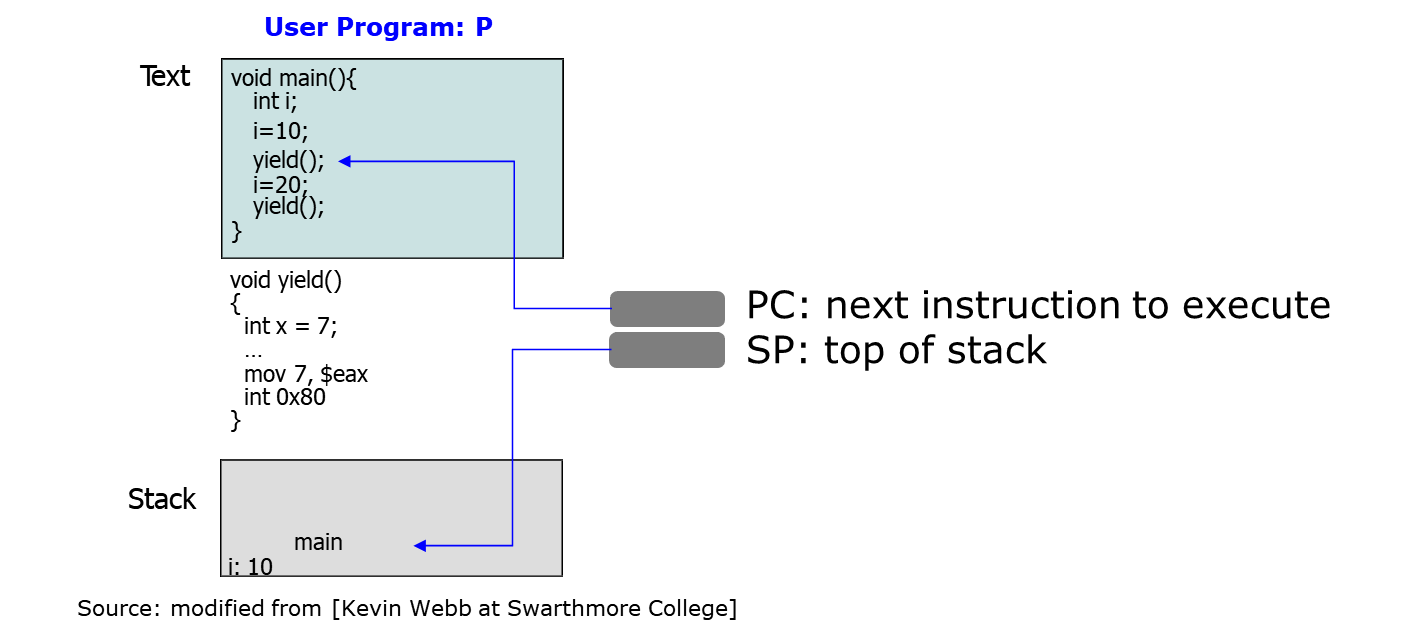
process switch가 일어나기 위한 기작을 mode switch와 PCB의 변화를 통해 알아본다. Mode switch Mode switch란 큰 범위로 OS의 함수를 의미한다. 이 함수들은 process switch, 메모리 관리, system call, I
10.[OS] Type of Process

Process의 생성과 소멸의 과정을 프로그래밍 코드와 함께 알아보자. 프로세스의 생성의 이유는 다음과 같다. >* New Batch Job: disk 또는 tape에 있는 JCL와 같은 job을 처리하기 위한 process Interactive log-on: 사용자
11.[OS] Processor Scheduling Overview(FIFO vs SPN)
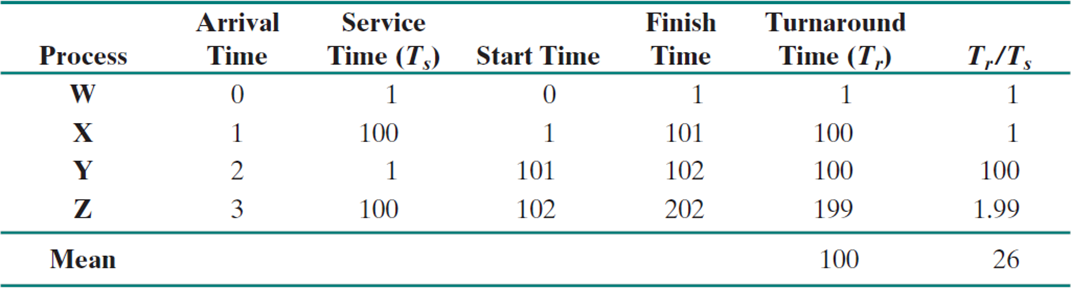
CPU utilization에 초점을 두어 시스템 환경에 따라 달리지는 다양한 process scheduling 기법들을 알아보고 서로 비교하며 장단점을 알아본다.turn-around time을 성능의 지표로 보고 각 scheduler를 비교한다.Burst(time):
12.[OS] Processor Scheduling(2)
Select Function: max(w+s)/sDecision Mode: Non-preemptiveSRN, SRT의 문제점인 longer process의 starvation의 문제를 TAT를 희생하여 해결한 스케줄링이다. 실행시간이 작거나, 기다린 시간이 긴 프로세스
13.[OS] Processor Schedulling in Multiprocessor Environment
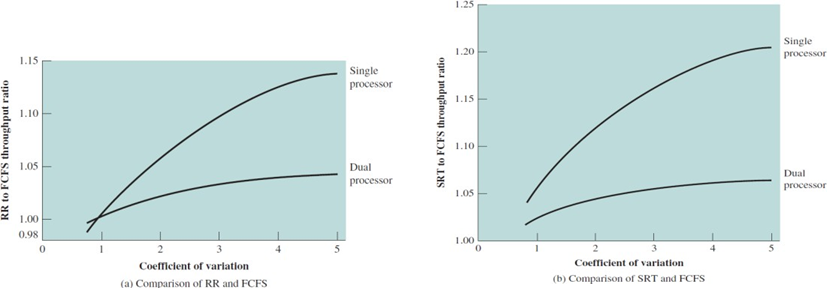
멀티 프로세서 환경에서의 스케줄링을 알아보자.MP 시스템의 종류를 알아보자.느슨하게 결합되어 있거나, 분산되어 있는 프로세서들로 구성된 시스템각각 프로세서들은 자신의 메인 메모리와 I/O 채널이 존재한다.I/O processor와 같이 특정 작업에 특화된 프로세서들로
14.[OS] Real-time Scheduling
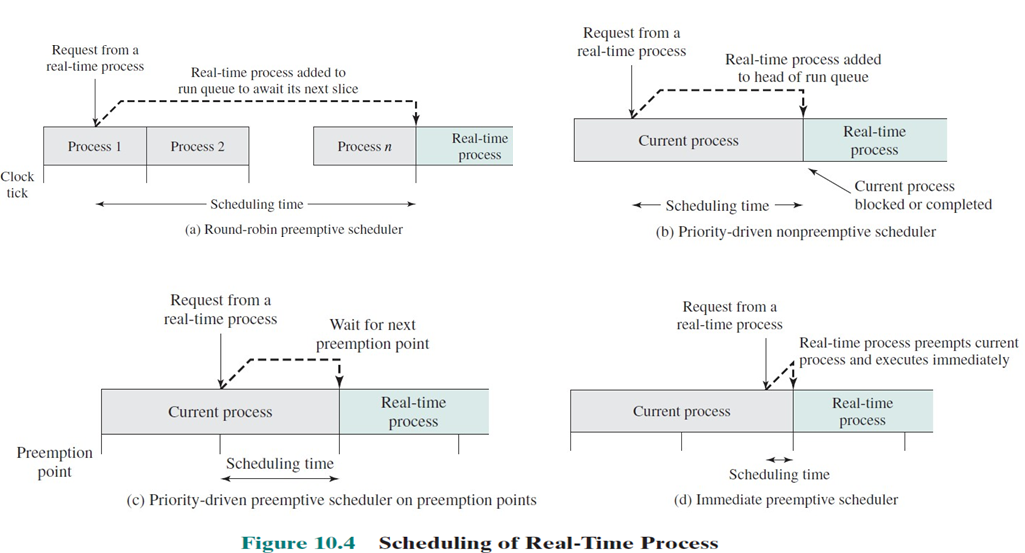
clock 속도나, 전력 소모 측면에서 코어들이 기능적으로 다르게 설계된 시스템을 의미한다.앞서 배운 asymmetric multiprocessing과 다르다. 각각의 코어들이 기능적으로 다른 것이지. 모든 코어에서 커널을 처리할 수 있다. 이 HMP의 목적은 일의 특
15.[OS] Linux Scheduling
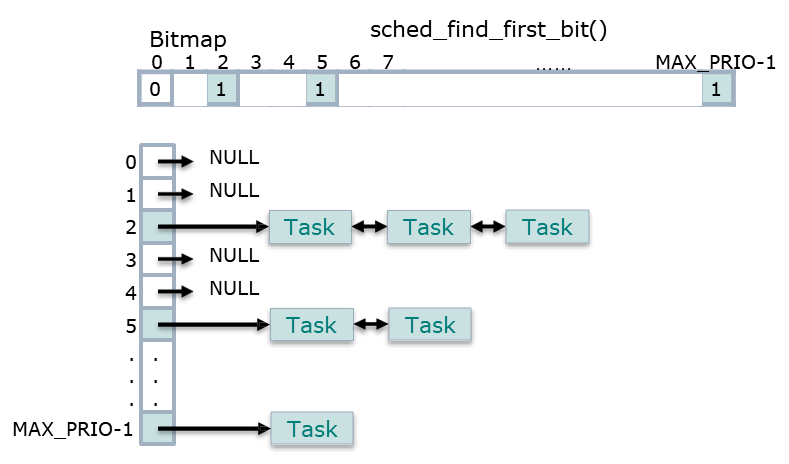
이번 포스트에선 Linux Scheduling을 알아본다.초기의 linux는 single-queue scheduling 방식이었다. processor와 process의 수가 증가함에 따라 확장성의 문제가 발생하고 이를 O(1) scheduling으로 해결하게 되었다.현
16.[OS] Thread
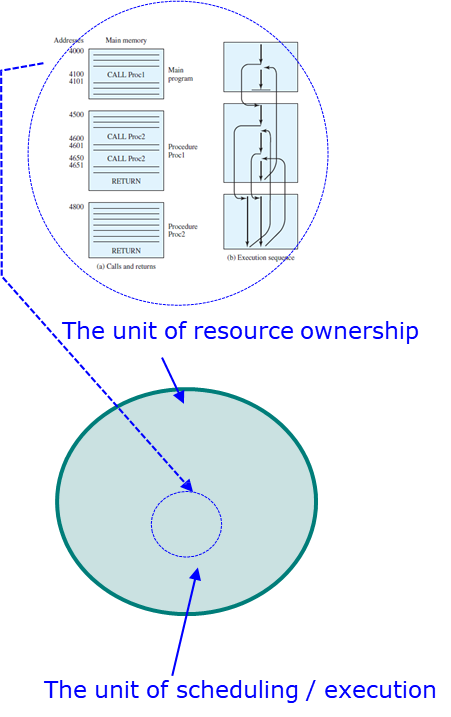
프로세스와 쓰레드의 차이와 멀티 프로세싱과 싱글 프로세싱 환경에서의 쓰레드의 장점과 단점을 알아보자.프로세스는 프로그램의 instance를 의미한다. 이를 좀 더 자세하게 개념화한다면, instruction sequence의 실행 단위로 바라보았다.이는 두 가지의 단위
17.[OS] Thread APIs

쓰레드를 위한 API와 Race condition을 알아보자.typedef void (func)(void );int pthread_create(pthread_t tid, pthread_attr_t attr,func f, void arg);첫 번째 인자: main thr
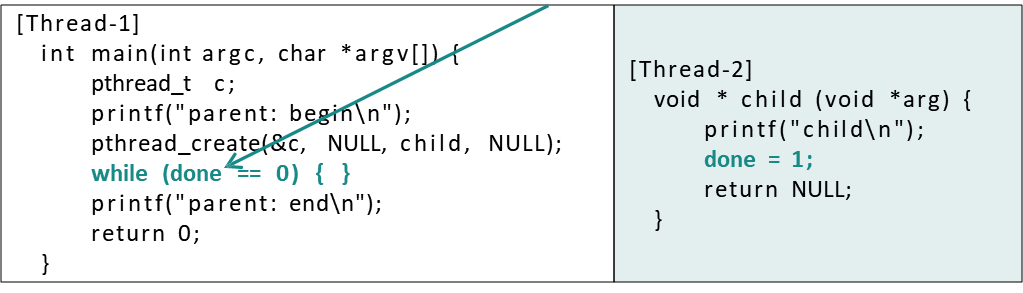
18.[OS] Race condition & Synchrnization
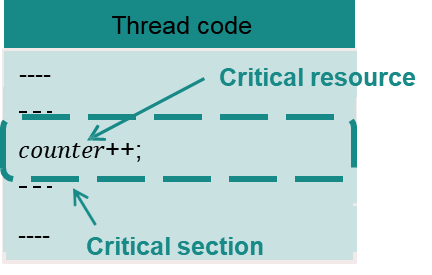
race condtion과 이를 예방할 동기화 기법을 알아본다.위의 코드가 과연 0이 나올까? 각각 1000번의 반복으로 increment, decrement를 수행한다.그러나 특정 순간에 Scheduling이 발생한다면 어떻게 할까?함수명이 바뀌면 scheduling
19.[OS] Many types of Locks

많은 lock 기법에 대해 알아보자.busy waiting, spin waiting 모두 critical section에 들어가기 전에 쓰레드, 프로세스가 아무것도 안 하는 것을 의미한다.이 기법을 이용한 것이 Spin lock이다.스핀락의 특징은 다음과 같다.구현과
20.[OS] Condition Synchronization with Producer & Consumer Problem
조건부 동기화와 이를 통한 생산자 소비자 문제를 알아보자.조건부 동기화란 말 그대로 조건에 따른 동기화 기법이다. 상호배제만 concurrent programmig의 전부가 아니다. 멀티 쓰레드 환경에서 critical section에 접근하기 위해 동기화를 수행해야하
21.[OS] Readers-Writers Problem

세마포어의 동작 원리는 다음과 같다.sem_wait(&s): s의 값이 1이여야 critical section에 접근할 수 있다.0이하에서 시작할 경우 blocked 상태로 변경된다.sem_post(&s): s의 값이 -1 이하일 경우 blocked 상태에 놓여있는 쓰
22.[OS] Deadlocks with Dining Philosophers
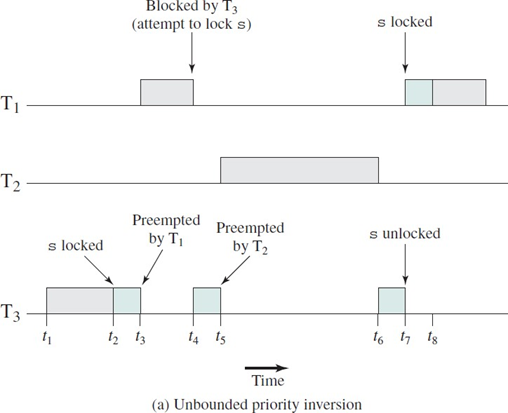
병렬 프로그래밍에서 발생할 수 있는 데드락과 우선순위 역전 문제를 알아보자.우선순위 역전 문제는 우선순위 기반 선점모드인 scheduler에서 발생할 수 있는 문제이다.실시간 스케줄링 문맥에서 바라보자.우선순위가 높은 순으로 p1, p2, p3이 있다. p3가 공유 자
23.[OS] Solution of Dining Philosophers

deadlock을 해결하는 방법 중 Deadlock prevention을 통해 식사하는 철학자 문제 해결법을 알아보고, Deadlock Avoidance 기법을 얕게 알아본다.데드락을 발생하는 주요 원인 네 가지 기법을 알아보자Deadlock Prevetion: 데드락
24.[OS] Memory Management
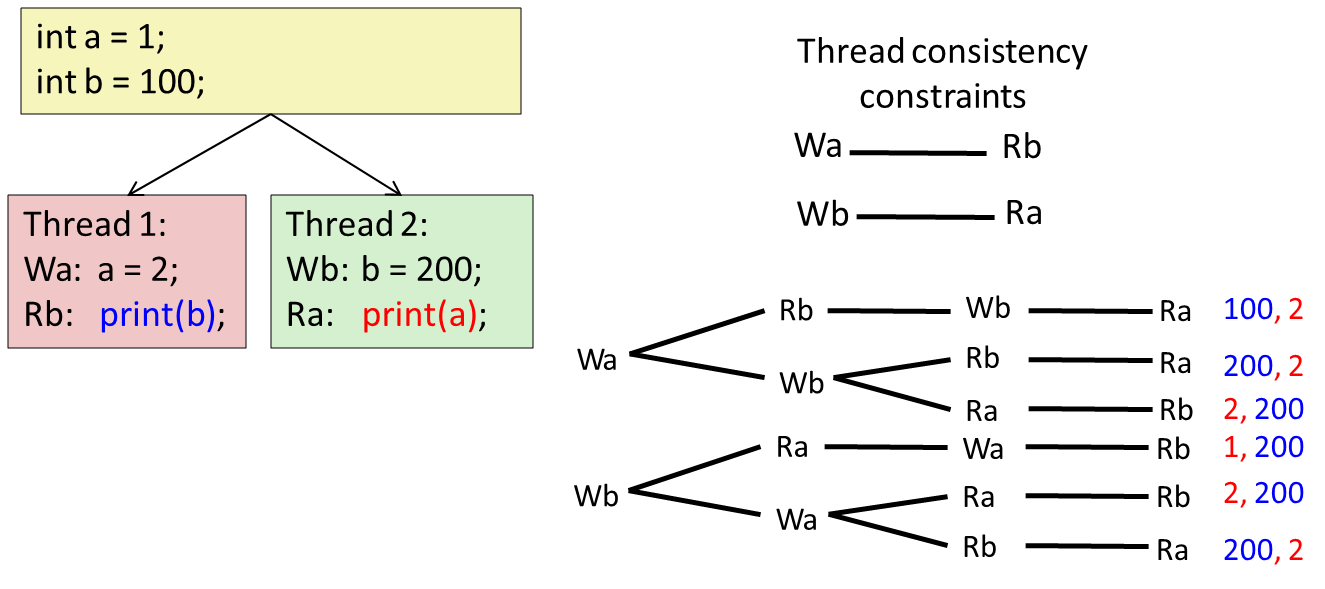
개발자가 구현한 프로그램의 실행 순서는 소스코드의 순서로 수행될 것 같지만 사실은 그렇지 않다.성능을 위한 pipeline을 사용하고 hazard를 막기 위해 reordering, branch prediction 등이 발생한다.만약 멀티 쓰레드, 멀티 프로세스 프로그래
25.[OS] VM: Replacement Policy
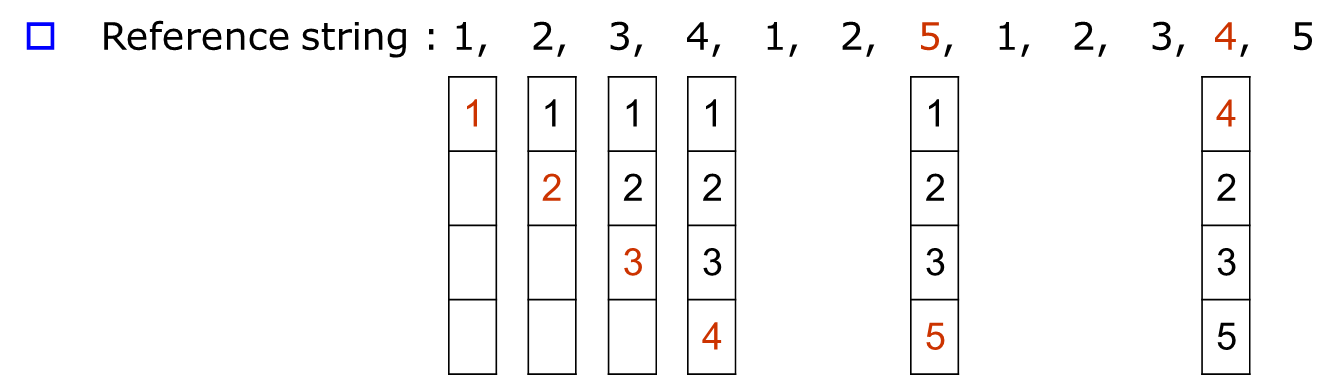
분할적재 방법에 부분적재를 더한 virtual memory에 대해 알아본다.이전에 본 paging과 segmentation 방법이 이해에 도움을 준다.virtual 메모리는 disk에 존재하는 프로그램의 많이 사용되는 부분만 적재한다.그리고 적재되지 않은 부분이 필요할
26.[OS] VM: Resident & Cleaning Policy
이전에 본 replacement policy에 이은 cleaning policy를 알아보자.cleaning policy는 언제 수정된 page를 secondary disk에 wirte back 해야할지를 결정하는 정책이다.만약 메모리에 공간이 없을 때, page 요청을
27.[OS] Virtual Memory
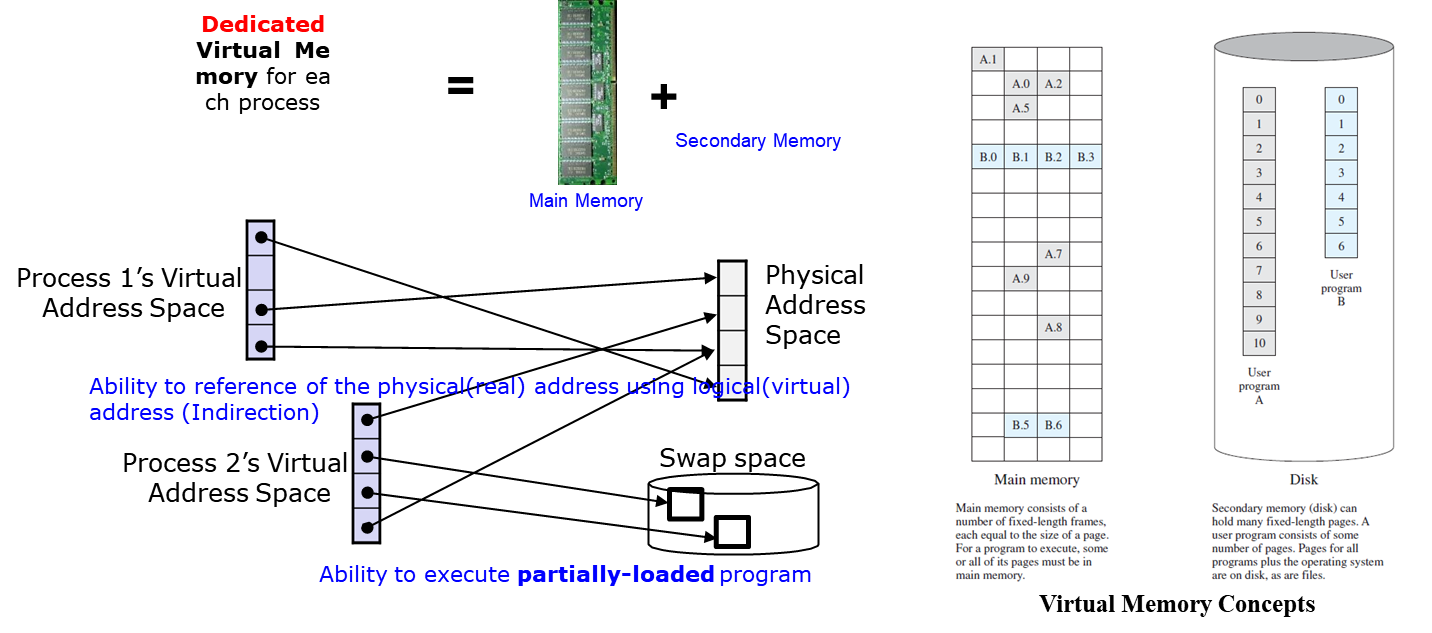
virtual memory는 프로세스를 실행하기 위해 필요한 부분만 발췌해 메모리에 할당하는 방법이다.프로세스를 전체 할당했을 때보다 더 많은 프로세스를 할당하여 실행할 수 있음로 secondary memory를 main memory의 일부처럼 여겨지는 느낌을 받을 수
28.[OS] VM: Page & Table Sizes
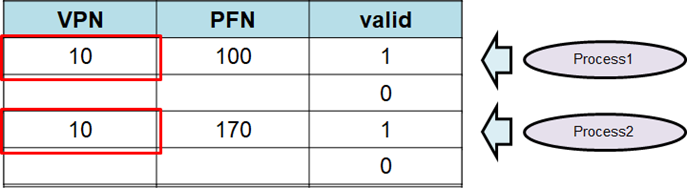
이제 page의 크기가 어떠한 영향을 끼치는지 알아보자.페이지의 크키가 늘어나면 entry 수가 줄어든다. I/O 측면에서 page가 크면 locality가 있다면 효율이 증가한다. (I/O가 적게 발생하기 때문이다.)TLB 측면에서 entry 수가 줄기 때문에 더 많
29.[OS] Disk Scheduling
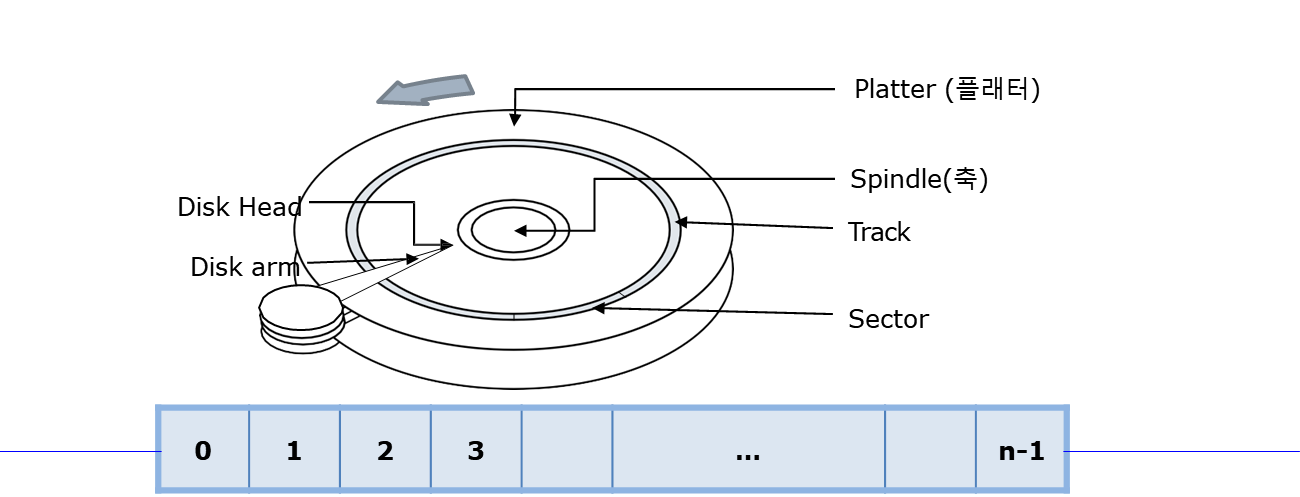
간단한 disk I/O를 효율적으로 하기 위한 disk scheduling을 알아보자.하드디스크는 다음과 같이 생겼다.Platter: 데이터가 저장되는 판이다.Spindle: 플래터를 움직이는 모터이다. RPM을 결정한다.Track: 플래터 위의 동심원이다. 플래터는