CPU utilization에 초점을 두어 시스템 환경에 따라 달리지는 다양한 process scheduling 기법들을 알아보고 서로 비교하며 장단점을 알아본다.
turn-around time을 성능의 지표로 보고 각 scheduler를 비교한다.
Terminologies
- Burst(time):
CPU burst: CPU가 process 처리를 하며 소모되는 시간
I/O burst: I/O 수행을 위해 CPU가 이를 기다리는 시간- CPU-I/O burst cycle:
각각의 프로세스 수행은 CPU 실행과 I/O를 위한 대기가 cycle의 형태로 구성된다
각각 번갈아 가며 프로세스가 처리된다는 것이다.- CPU bound process: long CPU burst를 가지는 프로세스를 의미한다.
- I/O bound process: short CPU burst를 가지는 프로세스를 의미한다.
각각 I/O blocking 이전의 한 process를 처리하는 cycle의 시간을 의미한다.
process scheduling은 multiprogramming에서 CPU utilization을 높히는 가장 중요한 요소이다.
scheduling은 큰 틀에서 네 가지가 있으며 이 포스트에서 크게 세 개만 본다.
여기서 short-term이란 짧은 기간에 발생한다는 뜻으로, 가장 빈번하게 호출된다는 의미이다.
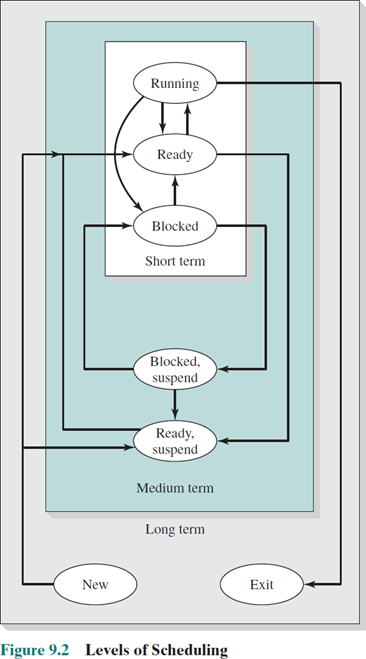
Types of Scheduling
- Long-term scheduling: fork() 후 new state의 process를 ready 또는 ready suspend로 할지 말지 결정한다. 이는 메모리 상태(용량) 또는 ready 상태의 프로세스들의 bound 분배 정도에 따라 결정될 수 있다.(한쪽으로 치우쳐진 bound는 성능 저하를 일으킨다.)
- Medium-term scheduling: ready suspend state -> ready 또는 block/suspend -> block으로 바꾸는 것을 고려한다.(메모리 자원에 따라)
- Short-term scheduling: ready에서 running으로 바꾸는 것을 고려한다.(process switch)
I/O request로 인한 block 또는 우선순위에 따른 선점으로 자주 발생한다.- I/O scheduling: I/O 디바이스가 다양한 프로세스들의 I/O request가 왔을 때, 무엇을 먼저 처리할지에 대한 기법이다.
Scheduling Criteria(스케줄링 기준)
스케줄링의 기준을 두 개의 시각으로 바라보자.
User Oriented
- Turnaround time: 프로세스가 도착 -> 완료까지의 시간(대기시간 포함)
- Response time: 프로세스 도착 -> 반응 도착의 시간
- Deadline: process의 마감 시간, 또는 시작 시간의 상한을 정해준다.
이를 얼마나 만족했는가?(=deadline ratio: 100개 중 하나만 맞춤)
System Oriented
- Throughput: 단위시간당 처리한 프로세스 수
- Processor utilization: 단위시간에 프로세서가 사용된 percentage
- Fairness: 프로세스들이 동일하게 취급되어야 함. starvation이 발생하면 안 됨(특정 프로세스가 처리가 아예 안 되는 경우)
이 모든 것을 동시에 만족할 수 없다. scheduling을 처리하는 기법들은 다양하지만 위의 스케줄링 기준을 모두 만족할 수 없다. 각기 다른 환경에서 성능이 가장 좋은 스케줄러 함수를 사용해야한다.
게다가 scheduling을 하며 소모되는 시간(overhead)도 고려해야한다. 이는 scheduling 함수의 수행시간으로 계산을 한다.
Which metrics(어떤 척도가 중요?)?
- Super computer: Throughput, 슈퍼 컴퓨터는 여러개의 CPU bound process가 많음
- Server Computer for Cloud Server: QoS가 중요하다. 돈에 비례해서, bandwidth가 증가해야함. 진정한 fairness
- Personal Computer: 다양한 작업을 하고 I/O 작업이 많으므로 turnaround time, response time이 중요할 것이다.
- Embeded system: 프로세스가 그렇게 많지도 않으므로 scheduling이 그렇게 중요하지 않다.
중요한 process(e.g. 자동차의 abs)가 있다면, deadline이 중요할 수도 있다.
Selection Function
선택 함수란 ready state process들 중 다음에 실행할 프로세스를 결정하는 함수이다.
이는 우선순위, 시스템 자원, 실행특성(e.g. 얼마나 기다렸나?)을 고려한다.
- w: 프로세스가 실행되기 위해 얼마나 기다렸는지
- e: 프로세스 수행을 위해 사용된 시간
- s: e를 포함한 프로세스를 처리하기 위한 전체 수행 시간, 그런데 이걸 어떻게 아냐? 컴퓨터가 예상한다 생각하자.(e.g. 과거에 실행된 시간의 평균)(user가 제공해준다 생각해도 된다.)
Decision Mode
결정모드란 selection function을 호출할 때, 결과에 따라 process switch를 발생시킬 것인가 아님 끝날 때까지 기다릴 것인가를 결정하는 방벙법이다.
- Non-preemptive: process가 끝날 때까지 또는 I/O request를 만나 block되는 것이 아니면 OS가 process switch를 발생시킬 수 없다. (e.g. FIFO)
- Preemptive: OS가 process switch를 발생시킬 수 있다.
e.g. interrupt로 인해 block->ready로 프로세스의 상태가 바뀔 때, clock interrupt, 프로세스 생성 등(무조건 Selection Function이 필요한가?)
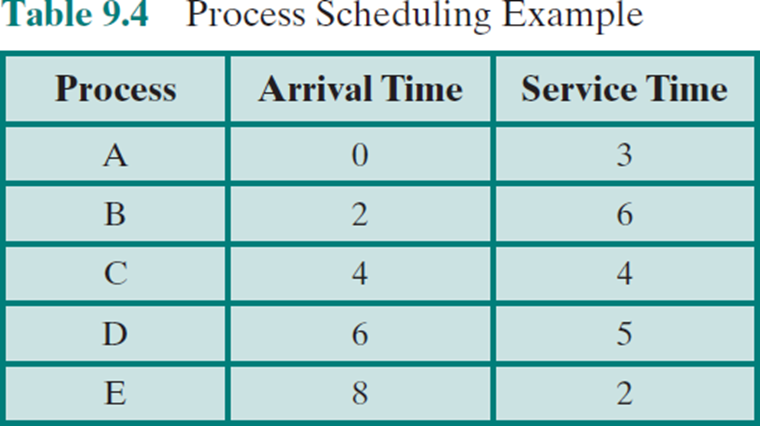
Scheduler example
다양한 scheduling 알고리즘을 알아볼 때, Service time은 원래 정확히 알지 못하나
이해를 위해 안다고 가정한다.
- Arrival Time: process가 ready state가 된 시점
- Service Time: 프로세스가 처리되기 위한 수행시간
- Turnaround Time: 프로세스 종료시간 - 도착시간
I/O 없다. process switch cost는 생각하지 않는다.
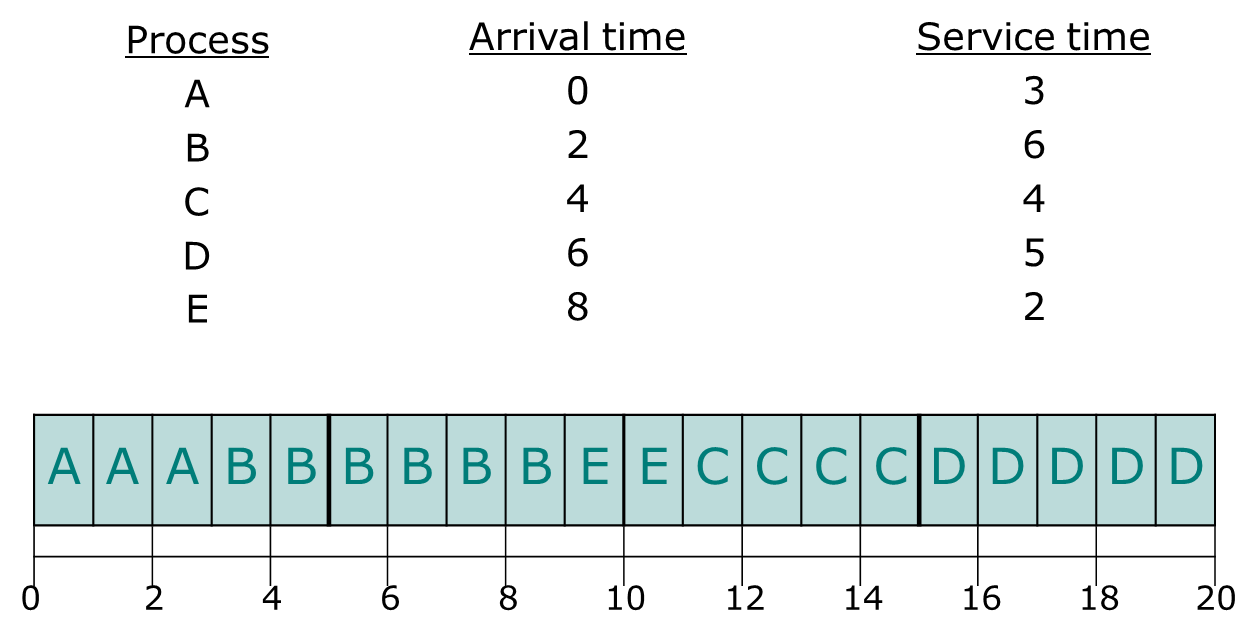
FIFO
FIFO 구조를 사용하는 Scheduler는 가장 먼저 ready list에 들어온 process를 가장 먼저 처리하는 것을 의미한다.
여기서 사용된 selection 함수는 max[w]이다. 그리고 Decision mode는 Non-preemptive이다.
장단점
- 구현이 쉽다.
- CPU bound 프로세스가 많아야 성능이 좋다.(I/O bound process 들은 idle 할 수 밖에 없다.)
- 프로세스가 길어야 더 좋다.
왜냐하면 long process가 계속해서 처리되면 쓰루풋이 높아지고 빠르게 process switch overhead가 덜 붙기 때문이다.- 하지만 average turnaround time 관점에서, 짧은 프로세스가 긴 프로세스에 막혀 성능이 안 좋아질 수 있다.(convoy effect)
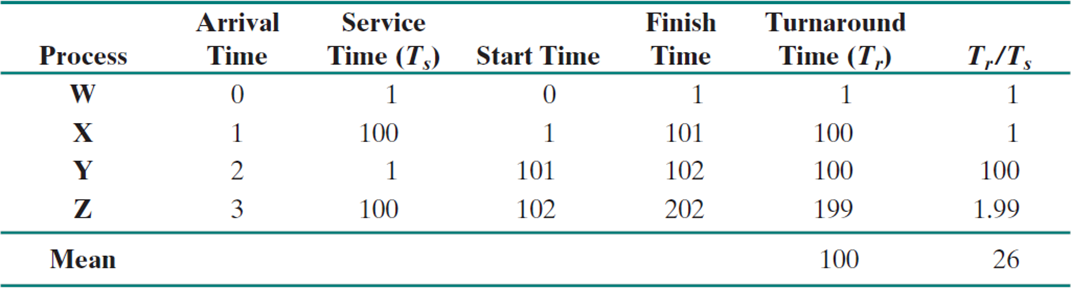
맨 마지막 response ratio는 응답 비율이다. turnaround time / service time으로 계산된다.
참고
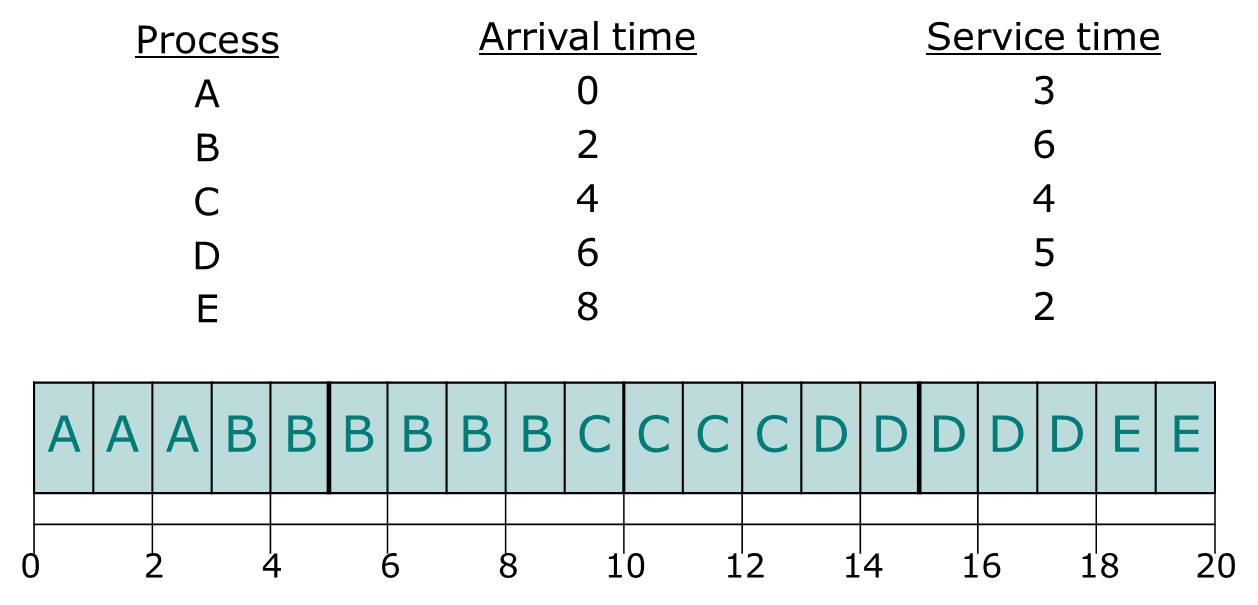
8.6초로 조금 느린거 같다 어떻게 처리해야할까? convoy effect 문제인 것 같다.
Shortest Process Next(SPN)
이는 SPN으로 해결할 수 있다. FIFO에 selection 함수를 min[s]로 두는 것이다.
비선점적이다. running 상태의 process가 종료되었을 때, selection 함수로 가장 작은 프로세스를 맨 앞으로 옮긴다.
7.6초로 개선되었다.
장단점
- Turnaround Average Time이 증가한다.
- 긴 프로세스가 실행되지 않는다.(starvation)
- 예시에는 제공되어 있지만, 사실 수행 시간은 예측해야한다. 이게 어렵다.
OS는 이미 실행된 프로세스들의 평균 시간을 계속해서 측정해야한다.(이게 모든 process의 평균 시간인가?)
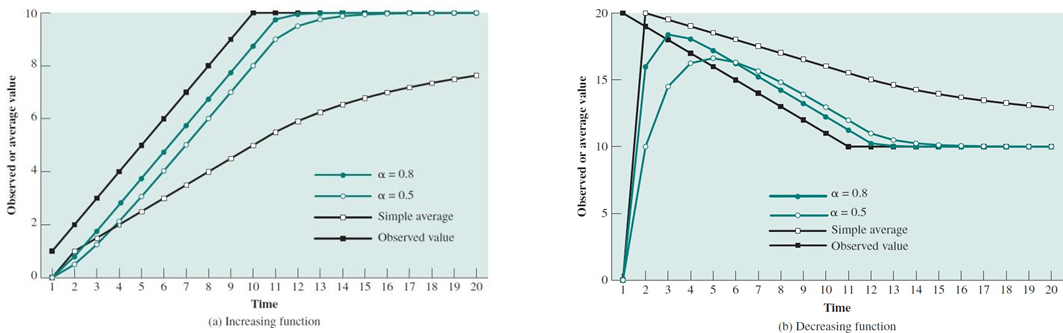
여기서 간단한 평균 시간은 다음과 같다.
->
또는 Exponential average를 사용할 수 있다. 최근 service 시간에 가중치를 더 주는 것이다.
를 사용한다.
그러나 service time이 다 같은 경우는 어떨까? 이럴 땐 FIFO가 훨씬 좋을 것이다. selection function은 constant time일 것이고 이 때문에 cost가 적게 든다.
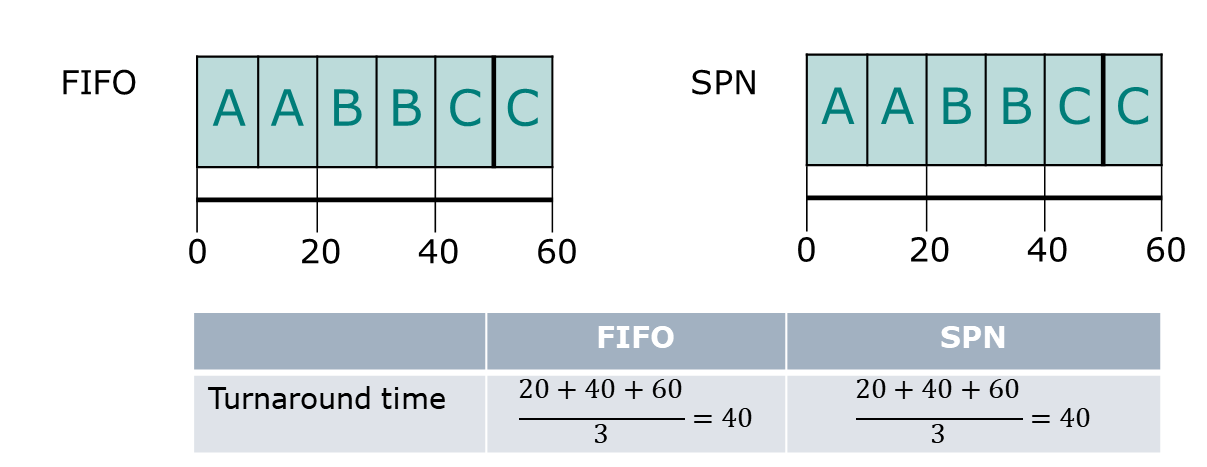
둘 다 40으로 이럴 땐 FIFO가 더 좋다.
