멀티 프로세서 환경에서의 스케줄링을 알아보자.
Multi-Processor(MP) Scheduling
MP 시스템의 종류를 알아보자.
- 느슨하게 결합되어 있거나, 분산되어 있는 프로세서들로 구성된 시스템
각각 프로세서들은 자신의 메인 메모리와 I/O 채널이 존재한다.- I/O processor와 같이 특정 작업에 특화된 프로세서들로 구성된 시스템
- 강하게 결합되어 있는 프로세스들로 구성된 시스템
프로세서들이 하나의 메인 메모리를 공유하고 결합되어 OS로부터 관리된다.
세 번째 시스템에 집중하여 스케줄링을 알아본다.
스케줄링 기법은 크게 두 가지가 존재한다.
- 비대칭적인(Asymmetric) 멀티 프로세싱: 다중 프로세서 중, 하나의 프로세서에서만(master) 커널을 처리한다. 나머지 프로세서는 slave라 부른다.
- 대칭적인(Symmetric) 멀티 프로세싱: 모든 프로세서에서 커널을 처리할 수 있다.(peer)
비대칭적인 프로세싱 기법은 확장성이 떨어진다. 프로세서가 많을수록 커널 요청이 많기 때문에 하나의 프로세서에 몰린다. 이는 bottleneck을 유발하며 확장성을 떨어트린다.
유니 프로세서 환경에선 언제 프로세스 switch를 발생시킬지에 대한 문제였다면
멀티 프로세서 환경에선 프로세스를 선택했다면 어느 프로세서 환경에서 처리해야할지에 대한 문제가 있다.
게다가 ready queue를 공유할지, 여러개를 만들지를 고민해야하고 static하게 process를 processor에 고정시킬 것인가, 동적으로 변경할 수 있을 것인가를 고민해야한다.
또한 모든 프로세서의 성능이 다르다면 어떻게 해야할까? 성능이 전부 같다면 동등하게 배분해도 좋을 것이다. 하지만 성능이 다 다르다면 코어의 성능에 따라 job을 분배해야 동등하게 주는 것보다 좋을 것이다.
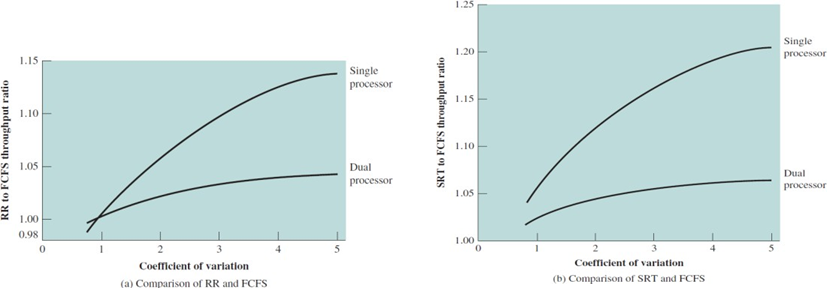
- 는 로 계산되며 는 평균수행시간 의 표준편차이다.
그렇다면 가 커질수록 프로세스 수행시간의 차이가 크다는 것이다. 가 0인 경우 수행시간이 모두 같다는 것이다.
두 그래프의 x축은 프로세스 실행시간의 차이이다.
첫 번째 y축은 프로세스들의 수행시간의 차이가 커짐에 따라 FIFO 대비 RR의 성능이다.
두 번째 y축은 프로세스들의 수행시간의 차이가 커짐에 따라 FIFO 대비 SRT의 성능이다.
FIFO는 프로세스의 실행시간이 모두 같을 때 굉장히 좋은 성능을 발휘한다. process switch가 덜 일어나고 selection function의 cost가 작기 때문이다.
x값이 1미만인 경우 FIFO의 성능이 더 뛰어나다. 하지만 두 차이가 크다면 RR의 throughput이 증가하는 것을 확인할 수 있다.
SRT도 마찬가지이다. 그러나 이것은 단일 프로세서 환경에서 큰 성능 차이를 보인다. 다중 프로세서 환경에선 프로세스를 처리할 프로세서가 많으니 그렇게 큰 차이를 보이지 않는다.
멀티 프로세어에서 스케줄링 함수는 덜 중요하다.
Queues
Single-Queue MP scheduling
하나의 ready queue를 메인 메모리에서 관리하는 기법이다. 각 프로세서가 할 일이 없다면, 큐에 접근하여 프로세스를 가져와 처리한다.
구현이 단순하고 load balanacing(queue에 프로세스를 잘못 분배한다면 idle한 프로세서가 발생할 수 있음)를 신경쓰지 않아도 된다.
그러나 단점으로 동기화 문제가 있다. 하나의 큐에서 여러 프로세서가 접근하기 때문에 race condition 문제가 발생한다.(나중에 알아본다)
또한 cache에 hot data를 많이 저장하여 hit rate를 높혀 놓았다면(warm cache라 부른다), 그 프로세서에서 계속 처리해야 효율적일 것이다 이를 프로세서에 친화력(affinity)이 있다.라고 말한다. 스케줄링에서 얘를 고려해야한다.
그러나 단일 환경에서 고려하기 힘들다.
Processor Affinity
- soft affinity: OS가 Affinity를 지키려는 정책이 있지만, 보장되지 않는다.
로드 밸런싱 문제로 보장되지 않을 수 있다.
hard affinity: static하게 고정시킨다.
Multi-Queue MP Scheduling
멀티 큐 스케줄링 방법은 각각 프로세서마다 자신의 큐가 존재한다.
이러한 이유로 affinity를 증가시킬 수 있고, race condition 문제가 발생하지 않는다.
하지만 load imbalanacing 문제가 발생할 수 있을 것이다.
Example of load imbalancing
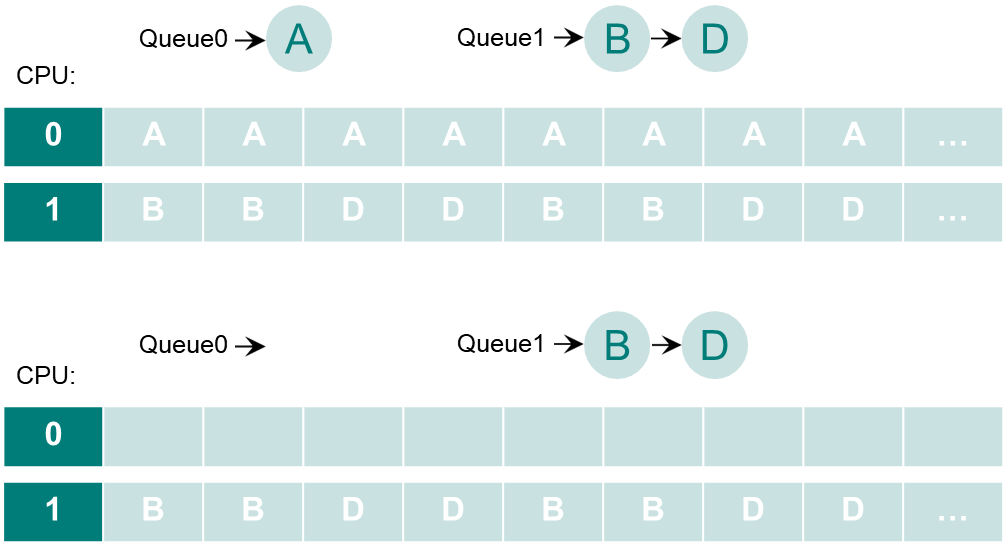
이걸 어떻게 처리해야할까?
idle 한 프로세서가 다른 큐에서 프로세스로 가져올 수 있다.
구현은 달라질 수 있다.
- pull migration: idle할 때, processore가 flag와 같은 bit를 set한다. 그럼 다른 프로세서가 프로세스를 전달해준다.
- push migration: 특정 프로세스가 계속해서 load balance를 체크하고 잘 분배한다.
