Linear regression using both TensorFlow low-level API & Keras API
이전에 배운 경사하강법을 통한 딥러닝 모델을 학습하는 방법은 아래와 같다
- 학습 데이터를 준비한다
- 모델을 정의한다.(학습을 받지 않은 상태이다.)
- loss 함수를 정의한다. 어떤 함수(loss=objective=cost)를 경사하강법을 사용할지.
- loss의 이상적인 값을 계산한다.
- 미분값을 구하여, 기울기의 +/-를 따져 변수를 데이터에 맞게 수정한다.
- 정해놓은 수만큼 반복한다.
- 모델 성능을 반복한다.
y = ax + b 형태의 선형모델로만 실습이 진행된다.
이는 f(x) = W * x + b의 형태이며 W(weight)는 가중치이고 b(bias)는 편향이다.
가중치란 곱하기 연산을 하는 parameter이다. 학습을 하며 값이 변경된다.
bias는 더하기 연산을 위한 parameter이다. 이 또한 학습을 하며 값이 변경된다.
복습하자
Low-levelAPIs는 Core APIs라고 불리우기도 한다.
High-levelAPIs는 Keras라고 불리운다. Keras는 별도의 라이브러리였다. legacy라고 불리었다.
딥러닝을 만드는 사용자 인터페이스였다. 백엔드, 실제로 돌아가는 기저에 있는 백엔드를 tensorflow라고 불렀었다.
아마존에서 사용하는 라이브러리를 MXNET, 초창기에 사용하던 Theano 라이브러리도 존재했다.
기존에 있던 라이브러리를 wrapping 형식으로 사용자 입장에서 사용하기 쉽게 만들어줬던 라이브러리였다.
지금의 Keras는 tensorflow의 API이다.
low-level API는 자유도가 높다. 하지만 코드의 길이가 길고 구현하는데에 시간이 많이 소요된다. 굉장히 효율적으로 구현할 수도 있다.
high-level API는 자유도가 낮지만 구현이 빠르다.
Row-Level API
Data Setting
import tensorflow as tf
import matplotlib.pyplot as plt
colors = plt.rcParams['axes.prop_cycle'].by_key()['color'] # 이미지화 관련 설정이다.
#The actual line y = 3x + 2
TRUE_W = 3.0 # 실제 참조할 Weight
TRUE_B = 2.0 # Bias
NUM_EXAMPLES = 201 # 201개의 데이터 생성. 가져오는게 아니다.
x = tf.linspace(-2,2, NUM_EXAMPLES) # -2와 2 사이에서 201개의 데이터를 생성하고 float type으로 바꿔준다.
x = tf.cast(x, tf.float32)
# x는 [-2,2] 201개의 값
def f(x): # 3x + 2
return x * TRUE_W + TRUE_B
noise = tf.random.normal(shape=[NUM_EXAMPLES]) # 데이터들이 직선에 나타나게 된다면 학습 과정이 수월하다. 하지만 관측되는 값들은 noise가 존재한다.
# 점들이 분포되어 있는데 직선에 붙어 있지 않고 근처에 관측되는 값들을 noise라고 부른다. 직선에서 벗어난 정도이다. 이를 정규분포로 샘플링을 해준다.
y = f(x) + noise # 이를 함수에 더해준다. 관측값 y이다.
plt.plot(x, y,'.')
plt.show() # 데이터가 퍼진 정도를 보면 뭔가 측정해서 구한 것 같은 합성 데이터가 만들어졌다.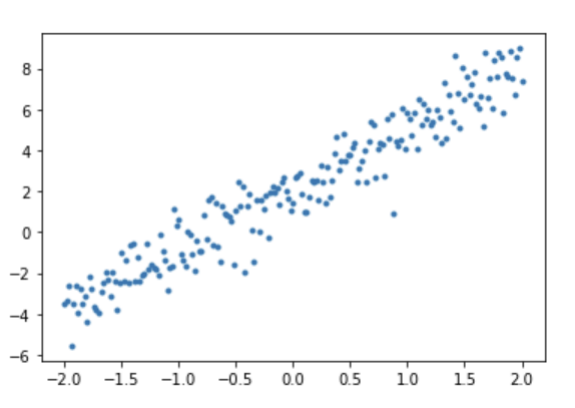
데이터가 퍼진 정도를 보면 뭔가 측정해서 구한 것 같은 합성 데이터가 만들어졌다.
Defining Model
모델을 정의할 때 클래스로 wrapping 해준다면 모델 수정이 간편해진다.
tf.Module을 상속받도록 한다. 가장 뉴런 네트워크의 모델이다. 인터페이스라고 볼 수 있다.
텐서플로우의 모델을 만들 때 이 클래스를 상속받는 것이 좋다.
생성자 부분에서 base class의 생성자를 호출한다.
class MyModel(tf.Module):
def __init__(self, **kwargs):
super().__init__(**kwargs)
self.w = tf.Variable(5.0) # parameter 선언
self.b = tf.Variable(0.0) # parameter 선언
# 원래는 대개 랜덤으로 초기화시킨다. 그럼 정규분포와 유사한 분포에서 값을 선택해 초기화가 된다.
def __call__(self, x): # 해당 클래스의 오브젝트를 인자로 전달해 호출하면 불린다.
# 예를 들어 model(1.5) == model.__call__(1.5)가 되는 것이다.
# 보통 사이킷 런에서 predict와 같은 역할을 한다. 입력이 들어오면 결과가 어떻게 나올지 코딩하면 된다
return self.w * x + self.b
model = MyModel()
print(model(3.0).numpy()) # 15출력Loss Setting
실제 정답과 모델이 예측한 값의 오차이다. 손실이 클수록 오류도 커진다
loss 함수가 종류가 굉장히 많다. 그 중 하나인 mean squared error라는 함수를 사용할 것이다.
(output-label)^2의 평균을 내면된다. 각 element에 대한 평균이다. 그럼 개수가 각 element의 개수가 될 것이다. 여기선 201개이다. 전부 더한다음에 제곱하고 평균을 구해주는 것이다.
def loss(target_y, predicted_y):
return tf.reduce_mean(tf.square(target_y - predicted_y)) # reduce_mean 텐서내의 모든 element 평균Visualization the current model and current loss value
모델과 예측 직선과 loss 값을 나타낸 것이다. 이걸 변화해서 예측 직선과 맞게 할 것이다.
plt.plot(x, y, '.', label="Data")
plt.plot(x, f(x), label="Ground truth")
plt.plot(x, model(x), label="Predictions")
plt.legend()
plt.show()
print("Current loss: %1.6f" % loss(y, model(x)).numpy())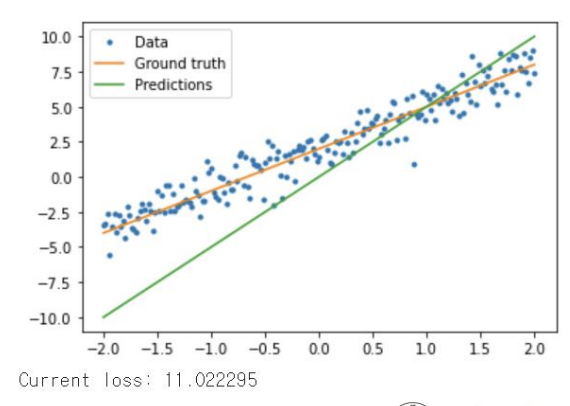
Training
1 모델에 인풋을 넣어 아웃풋을 뽑는다
2 로스값을 계산한다. 모델에 인풋을 넣어 예측값을 받아 손실값을 계산을 한다.
3 자동 미분을 통해 기울기를 얻는다
4 기울기를 수정하며 최적화된 값을 찾는다. loss 값이 제일 적은...
def train(model, x, y, learning_rate): # 학습할 모델, 입력값, label, learning rate
with tf.GradientTape() as t: # 계산하고자할 목표값, 그래디언트
current_loss = loss(y, model(x)) # loss 값 레이블과 아웃풋을 넣어줌 model(x)부분이 1번이다. 나머지 부분이 2번이다. 편미분을 해준다.
# 그래디언트를 구함
dw, db = t.gradient(current_loss, [model.w, model.b]) # w랑 b를 기준으로 모두 편미분하고싶다. 리스트형태로 그럼 dw, db가 나온다.
# assign_sub = w - learning_rate * dw이다.
model.w.assign_sub(learning_rate*dw) # w = w - learning rate * dw
# 메쏘드 입력값으로 들어온 값을 원래의 오브젝트 값에서 빼준다. 그리고 업데이트 해준다.
model.b.assign_sub(learning_rate*db) Loop
epochs는 미리 정한 반복횟수이다. 전체 데이터 셋에 대해 얼마나 반복이 되느냐를 정해놓은 것이다.
train set 10회를 반복하기 위함이다.
weights = []
biases = []
epochs = range(10) # 반복 횟수를 10으로 정해놓았다.
def report(model, loss): # logging을 위한 format 함수이다.
return f"W = {model.w.numpy():1.2f}, b = {model.b.numpy():1,2f}, loss={loss:2.5f}"
def training_loop(model, x, y):
for epoch in epochs:
# 훈련 코드이다. 필수 코드이다.
train(model, x, y, learning_rate=0.1)
# 기록 하는 코드이다.
weights.append(model.w.numpy())
biases.append(model.b.numpy())
curent_loss = loss(y, model(x))
# logging 방법이다. 매 epoch이 끝날 때마다. 로스값 등을 출력한다.
print(f"Epoch {epoch:2d}:")
print(" ", report(model, current_loss))
# 훈련이전의 상태를 logging한다.
current_loss = loss(y, model(x))
print(f"Starting:")
print(" ", report(model, current_loss))
# 훈련을 하며 바뀐 값을 logging한다.
training_loop(model, x, y)plt.plot(epochs, weights, label="Weights", color=colors[0])
plt.plot(epochs, [TRUE_W] * len(epochs), '--', label = "True weight", color=colors[0])
plt.plot(epochs, biases, label='bias', color=colors[1])
plt.plot(epochs, [TRUE_B] * len(epochs), "--", label="True bias", color=colors[1])
plt.legend()
plt.show()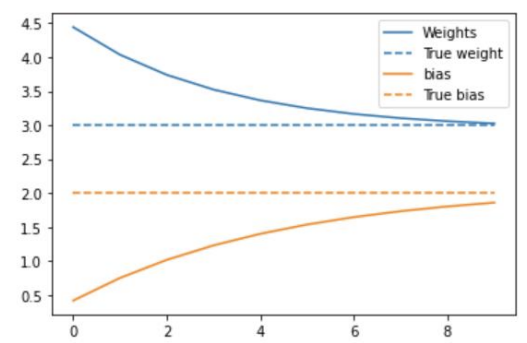
코드는 밑의 이미지를 보여준다.
점선이 실제 값들이다. weight과 bias들이다. 학습이 진행되면서 점점 Weights, biases가 실제값으로 가까워져 loss가 감소하는 것을 확인할 수 있다.
그런데 Weight와 bias가 정확히 3과 2로 수렴할 수 없다. 근사한 값으로 수렴된다. learning rate에 맞춰 값이 수렴되기 때문에 정확한 값으로 수렴이 될 수 없다. 정확도가 100퍼센트가 될 수 없다.
plt.plot(x, y, '.', label="Data")
plt.plot(x, f(x), label="Ground truth")
plt.plot(x, model(x), label="Predictions")
plt.legend()
plt.show()
print("Current loss: %1.6f" % loss(model(x), y).numpy()) 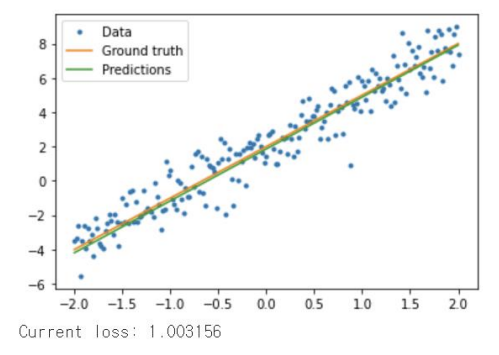
학습된 모델을 확인해보면 두 직선이 차이가 얼마 안나고 loss값이 10~11에서 1으로 된 것을 확인할 수 있다.
High Level
keras_model = tf.keras.Sequential([ # Sequential 클래스는 다양한 요소를 순서대로 쌓은 모델이다.
인자로 리스트를 전달받은 원소들을 순서대로 쌓아 모델을 만든다.
tf.keras.layers.Lambda(lambda x: tf.reshape(x,[-1,1])),
# x의 shape이 201인데, keras에서 이걸 처리하려면 201,1로 만들어야한다. 그래서 reshape을 해주었다.
tf.keras.layers.Dense(units=1)]) # Dense 1은 x가 들어오면 y=ax+b의 형태로 y하나를 전달하겠단 뜻이다. 만약 units이 2이면 y1과 y2를 전달한다. 나중에 한다.
keras_model.compile(
loss=tf.keras.losses.MSE,
optimizer=tf.keras.optimizers.SGD(learning_rate=0.1))
history = keras_model.fit(x, y, epochs=10, batch_size=201, verbose=1)주석
- Sequential 클래스는 다양한 요소를 순서대로 쌓은 모델이다.
인자로 리스트를 전달받은 원소들을 순서대로 쌓아 모델을 만든다.- x의 shape이 201인데, keras에서 이걸 처리하려면 201,1로 만들어야한다. 그래서 reshape을 해주었다.
- Dense 1은 x가 들어오면 y=ax+b의 형태로 y하나를 전달하겠단 뜻이다. 만약 units이 2이면 y1과 y2를 전달한다. 나중에 한다. unit 부분은 출력값 개수만 넣어주면 된다.
- optimizer 부분은 loss랑 learning rate 설정을 해준다. 경사하강법을 사용하는 곳이라 일단 알아두자.
- fit 호출하는 부분이 학습 loop이다. 10번 반복한다. 201부분은 한 번에 보내는 데이터 개수이다.
logging 부분은 1이다.값 출력 부분인가?간단하게 코딩할 수 있다.

keras API는 컴포넌트들을 사용해 model을 만들 수 있는 편리한 API이다.
세세한 부분을 수정하긴 힘들다. 이럴 땐 LOW-LEVEL API를 사용하는 것이 좋다.
커스터마이징을 하기 위해선 LOW-LELVEL을 사용하는게 좋다는 것이다.
이걸로 입문하고 LOW-LEVEL로 넘어가는 것이 좋다.
