Tensor Flow
딥러닝분야에서 가장 많이 쓰이는 두 라이브러리 중 하나인 텐서플로우 기초를 다룰 것이다.
Contents
- Tensors: numpy ndarray와 매우 유사하다.
- Variables: 텐서 플로우의 변수들이다.
- Automatic differentiation: 자동 미분 개념이다. 뒤에서 Gradient descent와 관련이 깊다. 경사 하강법이라 불리우는 Gradient descent가 많이 사용되며 딥러닝의 모델 학습 방법으로 주로 쓰인다.
- Gradient descent
- Linear regression using both TensorFlow low-level API & Keras API
- Image Classification using Keras API
설명란이 없는 내용들은 아래에서 알아보자.
What is Tensor Flow?
오픈소스 딥러닝에 중점적으로 맞춰져있는 라이브러리이다. 구글에서 관리하며 아파치 라이센스를 따른다.
파이썬, 자바스크립트, C++, 자바에서 모두 사용할 수 있다.
Tensors
텐서는 다차원 배열을 지원하는 같은 타입의 배열이다.
tf.Tensor objects를 이용하여 텐서 플로우의 연산을 수행한다.
이 배열의 원소는 상수이다. 초기화 이후 값을 변경할 수 없다.

import tensorflow as tf
rank_tensor = tf.constant(4)
print(rank_tensor)
output >> tf.Tensor(4, shape=(), dtype=int32)
print( tf.constant([[1.5, 2.5], [3.5, 6.3]], dtype=tf.float16)) # 텐서의 타입 고정
tf.Tensor([[1.5, 2.5], [3.5, 6.3]], shape(2,3), dtype=float16)위의 코드를 보면 텐서 배열을 생성하는 매써드는 tensorflow.constant이다. 상수 4만 인자로 전달했기 때문에 shape에 아무것도 없는 것을 확인할 수 있다. 스칼라값이란 의미이다.
안에 파이썬의 리스트 형태로 인자를 전달할 수 있다. 그리고 텐서의 타입을 고정할 수 있다.
Rank는 차원으로 1차원 배열이면 1이 될 것이다.
Tensor to Numpy
# Tensor는 tf.constant()로 생성된 텐서이다. 아래는 텐서를 넘파이 배열로 바꾸는 방법이다.
np.array(Tensor)
Tensor.numpy()Operations
tf.add(a,b) # a와 b 행렬
tf.multiply(a,b) # 원소끼리 곱셈
tf.matmul(a,b) # 행렬곱
tf.divide(a,b) # 원소끼리 나눗셈
# +, *, @, / 연산자로 대체 가능tf.zeros
tf.zeros([3,2,4,5])
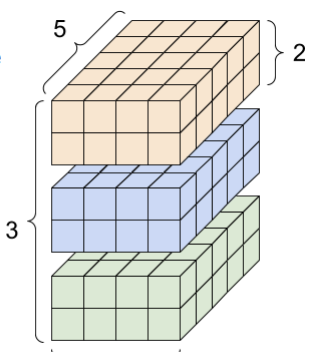
인자로 shape를 list 형태로 받는다. 2,4,5 형태(3d)의 육면체를 세 개 쌓았다고 볼 수 있다.
Attributes
rank_4_tensor = tf.zeros([3, 2, 4, 5])
print("Type of every element:", rank_4_tensor.dtype)
print('Number of axes:', rank_4_tensor.ndim)
print("Shape of tensor:", rank_4_tensor.shape)
print("Elements along axis 0 of tesnor:", rank_4_tensor.shape[0])
print("Elements along the last axis of tesnor:", rank_4_tensor.shape[-1])
print("Total number of elements (3*2*4*5):", tf.size(rank_4_tensor).numpy()) #120개의 원소가 있다.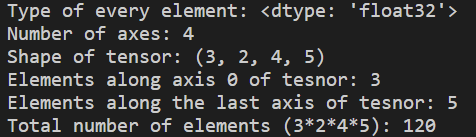
Slices
넘파이의 slicing + 추가 기능을 제공한다.
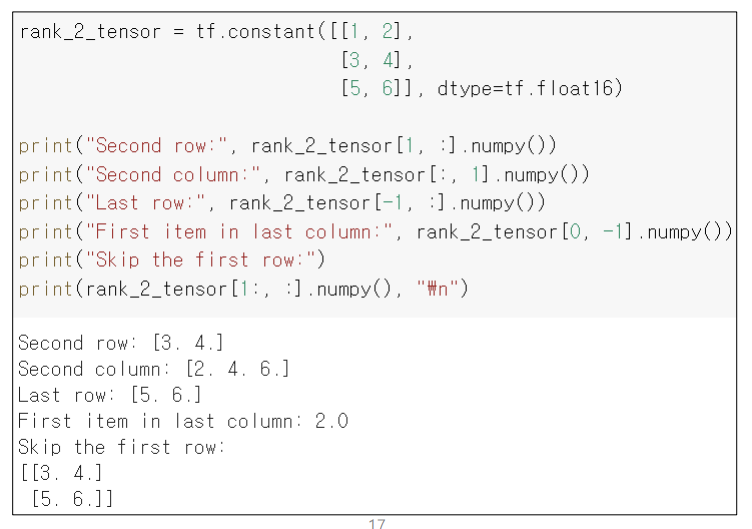
rank_tensor = tf.constant([0,1,1,2,3,5,8,13,21,34])
rank_tensor[2:7:2] # 2이상 7미만 2칸씩 증가하며 slicing
rank_tesnor[::-1] # 마지막부터 거꾸로 순회하며 slicingN Dimentional Slicing
마지막 부분은 복습하자...
tf.reshape(Tensor, Shape)
tensor의 shape를 변경. 변경된 tensor를 반환
바꿀 수 없는 형태라면 error가 발생한다.
인자로 -1을 딱 한 번 사용할 수 있다. 이는 값을 알아서 고정시킨다. 두 번 이상 사용한다면 에러가 난다.
이는 크기를 고려해 알아서 shape가 설정된다. 경우의 수가 하나 밖에 없을 때만 사용하자.

tf.cast(Tensor, dtype=tf.int16)
인자로 텐서와 타입을 전달한다. 그렇다면 타입이 바뀐 텐서가 반환된다.
tf.variable(tensor)
tensor를 인자로 넣으면 원소값이 수정가능한 배열로 바뀐다. 이도 .numpy() 매써드로 넘파이 배열로 변경할 수 있다.
값을 변경할 수 있기 때문에 딥러닝 모델의 파라미터를 나타내는데에 사용된다.
Variable.assign(List)
파이썬 list 형태로 인자를 전달해 값을 변경할 수 있다.
같은 shape가 아닐 시 error가 발생한다.
Automatic differentiation
f(x) 함수 정의 이차함수

f(x)의 값을 받을 y를 이미지와 같이 정의해놓고 tape.gradient(y, x) 형식으로 함수를 호출한다면
4가 반환된다.

스크린 샷으로 이해를 하자. 이정도만 배울 것이다.
Gradient descent(경사 하강법)
first-order iterative optimization 미분을 한 번 수행했다는 뜻이다. 미분 한 번 수행한 값을 통해서 반복하면서 값을 최적해나가는 알고리즘이다.
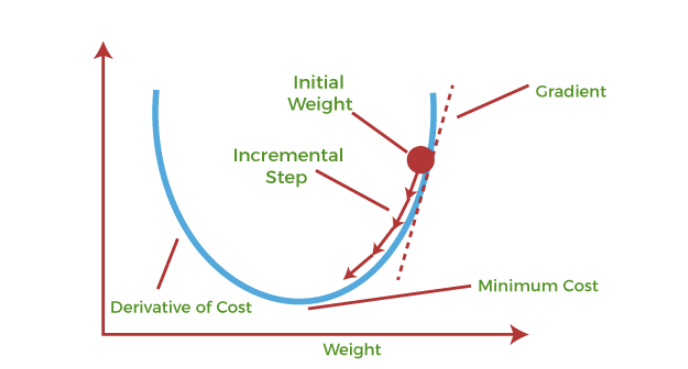
만약 이렇게 2차원 함수형태로 존재할 때, 기울기를 통해 순차적으로 값을 찾아나가는 것이다.
시작지점부터 x 값을 변경해 y가 최소인 지점을 찾는 것이다.
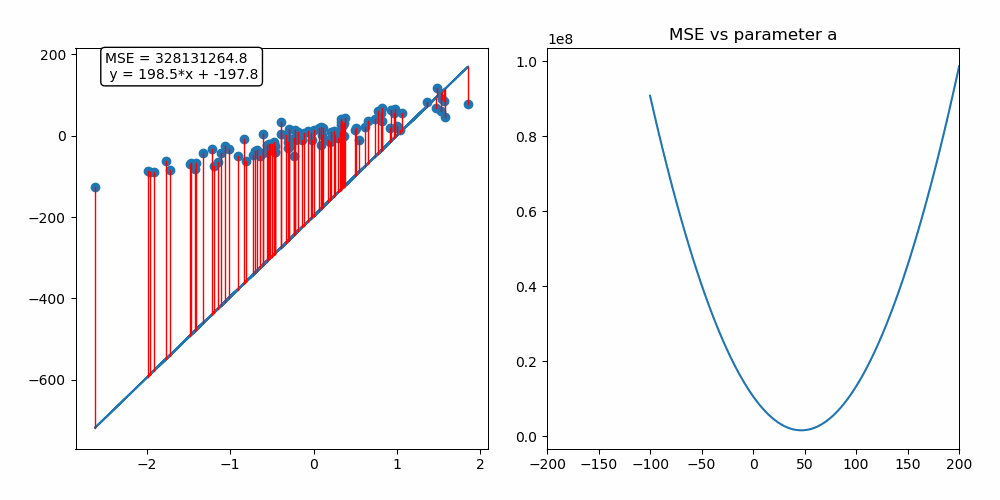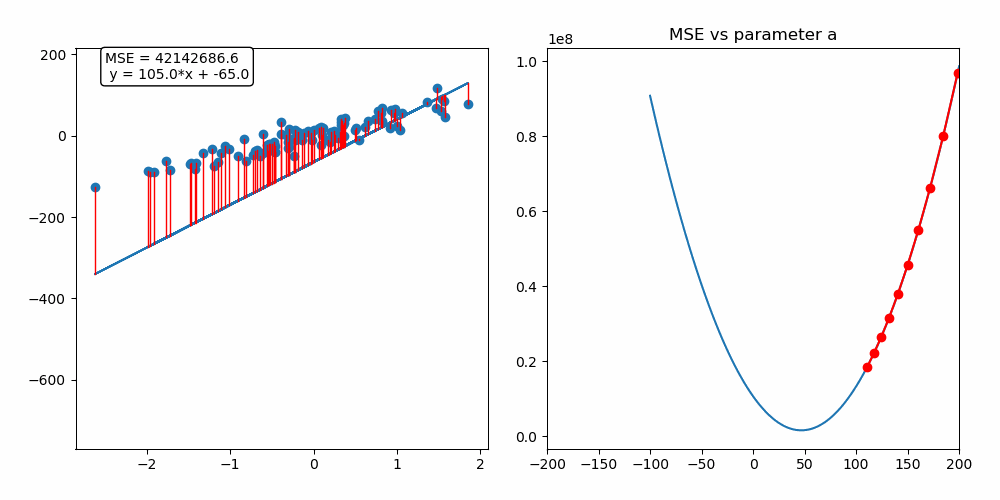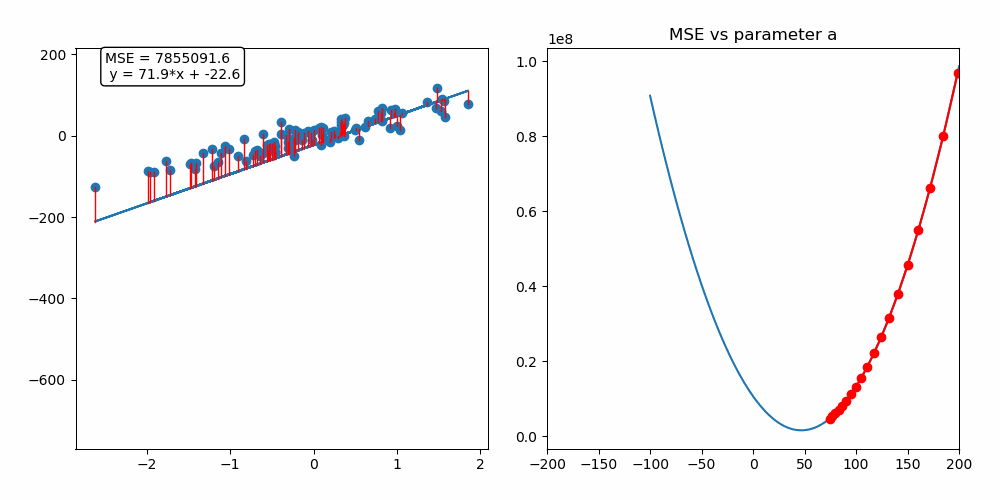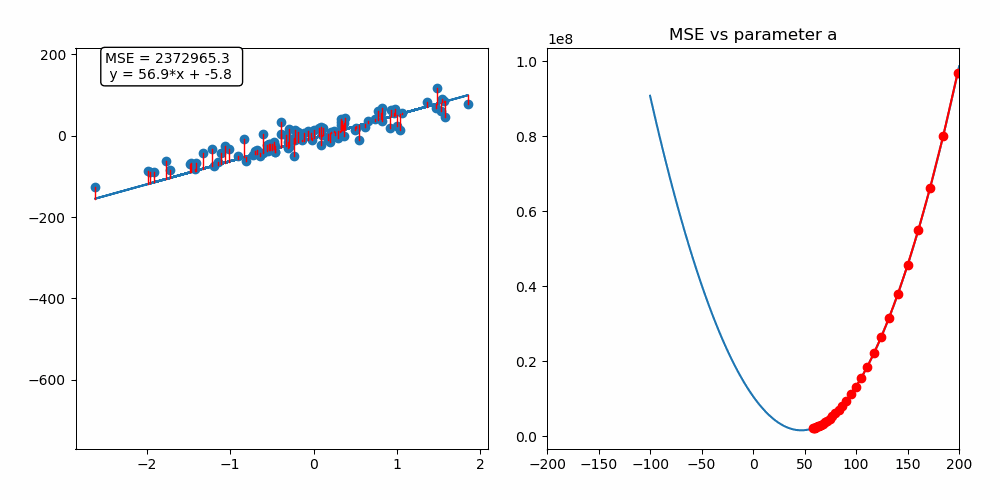
위의 선형모델은 y = ax + b이다.
위의 그림을 보면 160이 시작지점이다. 160에서 순차적으로 내려가며 최적의 a값을 찾는 이미지이다.
선형 모델과 데이터들의 에러가 작아지는 모습을 확인할 수 있다. 데이터들과 선형모델의 거리인 빨간색 선이 에러의 크기인 것 같다.
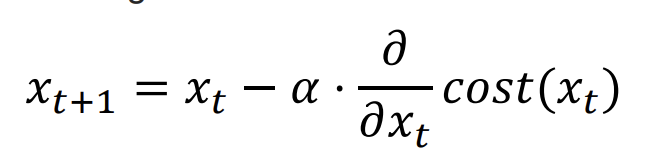
좌항은 업데이트되는 기울기 값이고 좌항의 xt는 업데이트 되기 전의 기울기값이다.
기울기가 양수이면 x의 값을 감소시켜 기울기값을 줄이고 음수일 경우 x의 크기를 증가시켜 기울기값을 줄인다.
그렇다면 낮은 에러를 향해 움직인다.
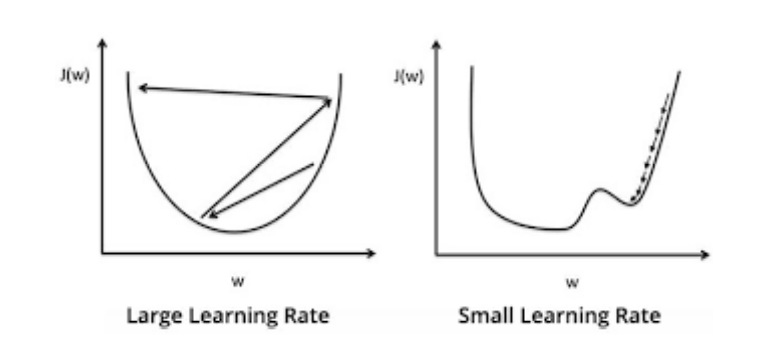
Learning rate
기울기값이 변경되는 step마다 얼마나 바뀌는지를 정해주는 값이다.
상황마다 다르기 때문에 정해진 값이 없다.
값이 너무 크면은 수렴을 못하는 상황이 발생한다. 기울기가 줄어들지 않거나 발산해버린다. 에러율이 높아지는 경우를 뜻 한다.
너무 작으면 특정 구간에서 반복하며 학습이 끝나게 된다. 실재하는 최저값과 차이가 너무 심하게 난게 된다.