Dynamic Memory Allocation
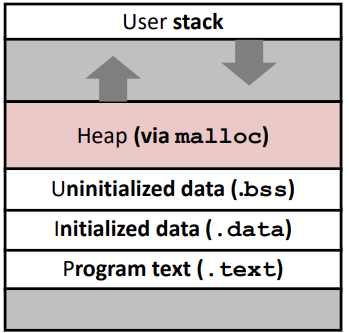
지금까지 배운 메모리 이미지이다. .bss, .data, .text에 들어가는 전역함수, 변수들은 linking-time(compile-time)에 실행파일에 만들이지고 run-time에 메모리에 할당된다. 이를 Static Allocation(정적할당)이라 부른다.
그런데, 프로그램은 예측 불가능하다. 조건에 따라 메모리를 필요로하는 코드를 정적할당을 통해 진행한다면
효율성이 떨어질 것이다.
메모리의 사용은 예측 불가하기에, run-time에 할당되는 Dynamic Allocation(동적할당)을 사용한다.
이번 포스트에서 동적할당이 필요성과 문제점 그리고 동적할당을 지원하기 위한 자료구조를 알아볼 것이다.
Stack
stack도 동적할당을 위해 사용된다. 하지만 stack 자료구조상, top에서만 원소를 가져올 수 있기 때문에
제한적이다. 하지만 단순하고 함수를 관리하는데에 호율적이기에 함수의 시퀀스를 다루기 위해 사용된다.
Heap
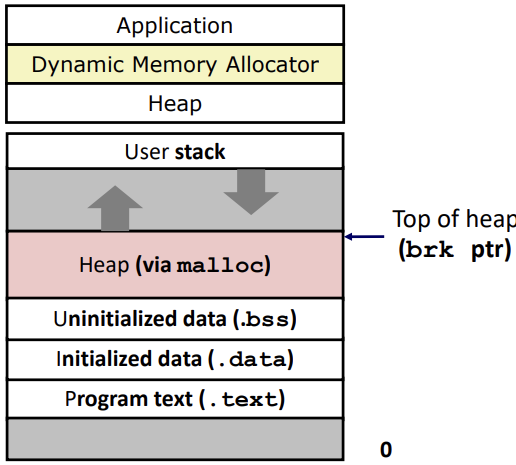
C에서 malloc, free를 사용해 동적할당 한다면, syscall에 의해 동적할당이 된다.
heap은 아래에서 위로 커지기 때문에 head를 가리키는 brk ptr이 존재하고 이를 통해 heap의 크기를 늘릴 수 있다.
Allocator
Allocator는 heap을 가변길이의 block으로 관리한다. 이는 block의 allocated 또는 free 상태를 가지고 있다.
Memory Allocator는 두 가지가 있다. 할당과 해제를 모두 따로 처리해야 하는 allocator를 Explicit allocator라고 한다.
JAVA의 garbage collector와 같이 자동으로 해제하는 allocator를 Implicit allocator라고 한다.
The malloc basics
#include <stdlib.h>
void * malloc(size_t size)
- 성공시 size만큼의 memory block이 heap 영역에 할당된다. 이 block의 시작주소를 반환한다.
- size가 0이거나 실패시 NULL을 반환한다. 실패인 경우 errno이 set된다.
void free(void *p)
heap의 할당을 해제하고 상태가 free가 되고 이 block의 주소가 반환된다.
이 반환된 주소는 이전의 malloc 또는 realloc에 의해 할당된 block의 주소이다.
sbrk
sbrk을 통해 heap의 크기를 늘리거나 줄일 수 있다.
Example
인자로 받은 정수 n 크기의 배열을 생성하는 함수
#include <stdio.h>
#include <stdlib.h>
void foo(int n){
int *p;
p = (int*)malloc(n * sizeof(int));
if(p == NULL){
perror("malloc");
exit(0);
}
for(int i = 0; i<n; i++)
p[i] = i; //배열의 원소를 [0,n)로 초기화
free(p);
}Other functions
| 함수명 | 매개변수 | 반환값 |
|---|---|---|
| void * malloc(size_t size) | size: 할당할 메모리의 크기(bytes) | block의 시작 주소 |
| void *calloc(size_t n, size_t size) | n: size의 수, size: 할당할 메모리의 크기(bytes) | block의 시작 주소 |
| void realloc(void memblock, size_t size) | memblock: 기존의 할당한 block 주소, size: 재할당할 메모리 크기(bytes) | block의 시작 주소 |
(매개변수의 형태: malloc(n * sizeof(int)), calloc(n, sizeof(int)))

Peak Memory Utilization(최대 메모리 사용률)
R0, R1, ..., Rk, ... , Rn-1
Aggregate payload Pk란 Rk 시점에서 Rk가 마무리가 되었을 때, payload의 총합이다.
After request Rk has completed, the aggregate payload Pk is the sum of currently allocated payloads
payload란 malloc(p)에서 실제 데이터가 저장될 공간을 의미한다. 이는 할당되는 공간 중에 padding, header 정보들이 붙게 되는데 이들을 제외한 순수 저장 공간을 의미한다.
Hk란 Rk 시점에서의 heap의 크기를 의미한다.
그렇다면 Peak Memory Utilization은 Uk = (max_i<=k Pi) / Hk이 된다.
힙의 크기와 동적할당된 payload 총합의 비율을 나타낸 것이다.
최대 메모리 사용률이 가장 커야 성능이 좋다고 여겨진다.
Throughput
메모리 할당의 수행시간도 성능 척도의 중요한 요소이다. 단위시간당 request를 처리하는 Thorughput도 중요하다.
5000 malloc과 5000 free를 10초에 처리를 했다면
Trhoughput은 (5000+5000)/10이 된다. 이를 구하는 공식은 operations/second이다.
Memory Utilization과 Throughput을 가장 크게하는 것이 목표이다.
Internal Fragmentation(내부 단편화)

최대 메모리 사용률의 극대화를 어렵게하는 것이 Internal Fragmentation이다. free block을 빠르게 찾기 위한 pointer, alignment 목적의 padding 정보 등 부가정보로 인해, 실제 필요한 payload보다 block의 크기가 더 커진다. 이를 내부 단편화라고 부른다.
내부 정책상의 이유로
External Fragmentation(외부 단편화)
block 밖에서 발생하는 단편화이다.
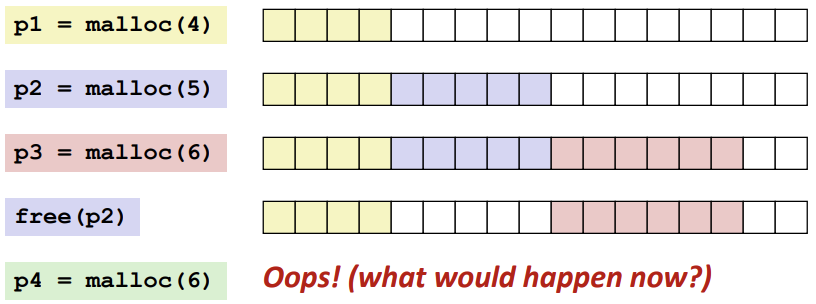
malloc과 free를 할 경우 메모리의 공간은 충분한데 공간이 떨어져있어 할당이 안 되는 경우를 외부 단편화라 칭한다.
Implementation Issues
동적할당을 구현하기 위한 고려사항들이다.
- Free block의 구성: free block을 어떻게 탐색할 것인가?
- Placement: free block 중 어떤 block을 선택할 것인가?
- Splitting: block에 잉여공간이 있을 경우 어떡할 것인가? => free block으로 나누거나 외부 단편화가 될 수 있기 때문에 그냥 모두 할당한다.
- Coalescing: block 할당해제 할 경우 인접한 free block이 존재한다면 병합할 것인가?
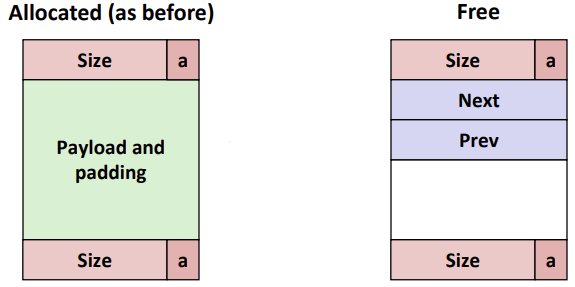
할당된 block은 관리를 위해서 정보가 필요하다. block의 경계, 상태 정보가 존재하고 이를 header라고 부른다.
예를 들어 4개의 payload를 요청했을 때, 하나의 word(int-sized)를 추가 할당하여 block의 size를 저장한다.
3 Methods

위의 이미지는 Implicit free list이다. free block을 찾기 위해 명시적인 free block 없이 모든 header를 순회하며 free block을 찾는다.

위의 이미지는 explicit free list이다. 이는 header뿐만 아니라 free block ptr를 가지고 있어, free block만 순회하며 찾을 수 있다.
세 번째로 위의 segregated free list는 free block을 크기별로 분류를 하여 요청된 크기에 맞추어 free block을 더 빠르게 찾을 수 있는 방법이다.
Implicit Free list를 중점적으로 알아볼 것이다.
Implicit Free List
header를 모두 순회하며 free block을 찾는 list이다. 그렇기 때문에 header에 block 크기와 allocation status가 저장되어 있어야 한다. 이를 어떻게 처리하는지 알아보자.
Standard trick
two words에 block의 크기와 할당 여부 정보를 담는다면 효율적이지 않다. 이를 one word에 저장하여 효율적으로 관리하는 기법에 대해 알아보자.
하나의 word는 할당전 모두 0이기 때문에 이를 이용하여 block의 상태를 저장한다. 1이면 allocated 0이면 free이다.
(block의 크기를 읽어올 때는 훼손될 수 있기에 마지막 bit을 0으로 바꿔서 읽어야 한다.)
이를 충족하기 위해 구조체의 offset과 같이 block의 총 크기가 double-word의 배수가 되어야 한다.
padding은 double-word로 맞춰주어야 하기 때문에 payload 뒤에 붙게 된다.
요악하지면
- allocated, free 상태 정보와 block의 크기를 two words에 저장하지 않고 1 word에 저장한다.
one word 31 bit에 크기를, 마지막 1 bit에 상태를 저장한다. (1 is allocated, 0 is free)- 효율성을 위해 double word의 배수로 block을 할당한다.(block 할당시 다음 block 주소의 low-order은 자연스럽게 0이다. 이것으로 free block과 allocated block을 관리한다.)
- 크기를 읽어올 때, 상태를 저장한 one bit을 0으로
mask out하여 처리한다.

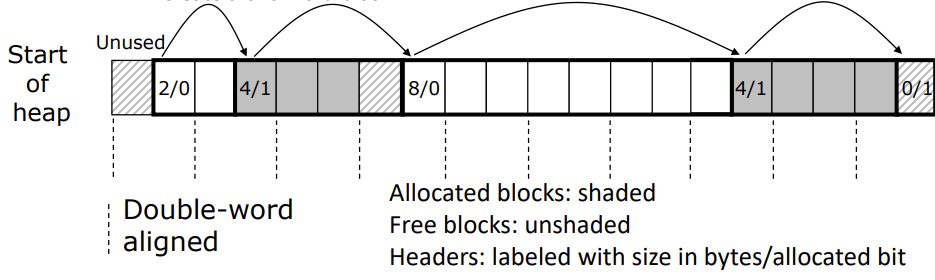
하얀 부분이 free, 회색 부분이 allocated이다.
heap의 시작과 끝은 사용되지 않는다.
1 byte의 payload를 요청하더라도 double word의 주소를 반환할 것이다. 하나는 header 정보이고 나머지 하나는 payload가 될 것이다.
Finding a Free Block
First fit
p = start;
while ((p < end) && \\ not passed end
((*p & 1) || \\ already allocated
(*p <= len))) \\ too small
p = p + (*p & -2); \\ goto next block (word addressed)첫 번째 free block을 찾는 방법이다. (시작주소가 end보다 작을경우 그리고 header가 0이 아닐경우) 또는 free block 이지만, 가용크기가 너무 작은 경우에 다음 block으로 건너 뛸 것이다.
이런 식으로 원하는 크기를 가지는 free block을 찾을 수 있다.
Next fit
first fit과 유사하지만 처음부터 하는 것이 아니라 이전에 탐색이 중단된 시점부터 진행하는 것이다.
반면에 뒤로 갈수록 fragmentation이 나빠질 수 있다.
Best fit
가장 최적의 free block을 찾는 것이다. 요청한 크기와 free block의 크기의 차이가 가장 작은 것을 찾는 것이다. 이는 모든 free block을 순회해야하기 때문에, 속도가 느리다. 하지만 최대 메모리 사용률을 높여줄 수 있다.
Allocating in Free Block
free block을 찾은 후에 할당을 할 때, free block 크기보다 요쳥된 크기가 더 클 수 있기 때문에 block을 나눌 수 있다.
이를 Splitting이라 부르며 아래의 코드는 Splitting을 구현해놓은 것이다.
void addblock(ptr p, int len) {
int newsize = ((len + 1) >> 1) << 1; // round up to even
int oldsize = *p & -2; // mask out low bit
*p = newsize | 1; // set new length
if (newsize < oldsize)
*(p+newsize) = oldsize - newsize; // set length in remaining
}(oldsize 부분은 1..1110과 bitwise 연산을 해줌으로써 상태 flag를 0으로 만들어준다.)
(*p = newsize | 1 부분은 마지막 bit를 1로 바꾸어 상태를 업데이트 한다.)
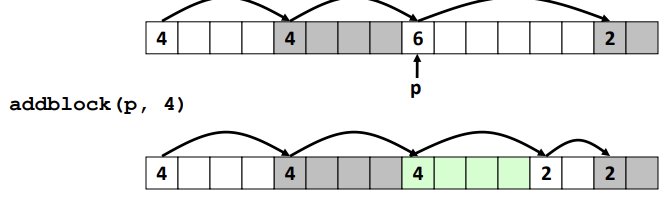
Freeing a Block
free 할 때는 Splitting한 두 개의 영역을 다시 합병해줘야 한다. 인접한 free block은 공간이 충분하지만 할당을 해주지 못하는 flase fragmentation이 발생할 수 있다.
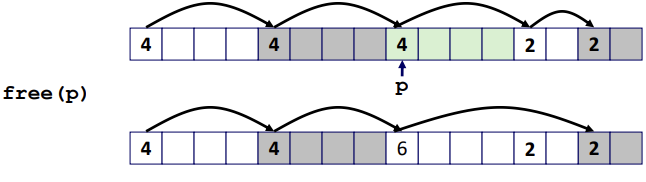
void free_block(ptr p) {
*p = *p & -2; // clear allocated flag
next = p + *p; // find next block
if ((*next & 1) == 0)
*=p = *p + *next; // add to this block if not allocated
} (마지막 조건문 부분은 다음의 free block과 합병해주는 역할을 한다. 다음 free block의 크기와 더한다.)
다음 free block말고 이전의 free block이 존재한다면 어떻게 합병해줘야할까?
Bidirectional Coalescing
Boundary tag
할당해제를 할 때, free block의 양방향 합병을 위해 이전 block의 header를 알아야하는데, 이를 해결할 수 있는 것이 Boundary tag이다. 단순하게 header의 정보를 마지막 word에 복사한 것이다.
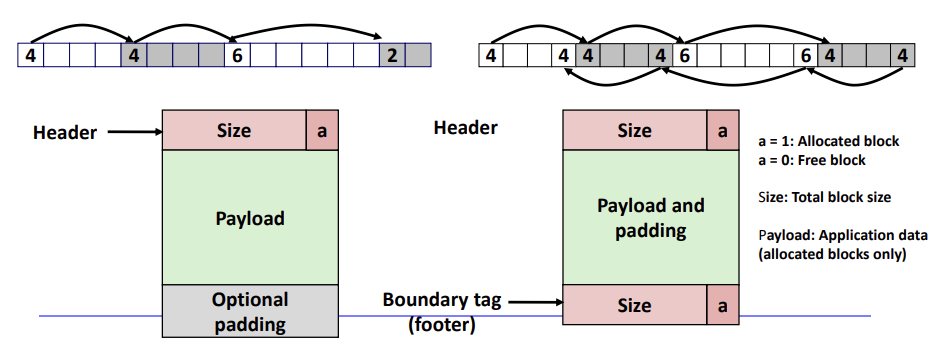
Summary
- 구현은 굉장히 단순하다. 하지만 할당할 때, free block을 모두 찾아 합병해줘야할 수도 있기 때문에
Linear time이다.- 할당해제할 땐 당연하게도
Constant time이다.- 메모리 사용률 측면에선
First-fit,next-fit,best-fit에 따라 달라진다.- 이는 선형타임 시간복잡도 때문에 사용되진 않지만,
Splitting,Boundary tag coalescing은 많은 allocator에 적용되어 있기에 잘 알아두어야 한다.
Explicit Free List
Implicit free lists와는 다르게 free block들이 포인터로 관리되는 기법이다.
더 free block을 빠르게 찾기 위해 명시적으로 두 가지의 pointer, next, prev와 Boundary tag가 존재한다.
double linked-list와 같은 원리로 구현된다. 탐색도 빠르고 양방향 합병이 가능하다.
할당 되었을 때, 포인터가 있던 자리는 payload로 쓰인다.
Logically

논리적으로 위와 같은 형태로 free block이 관리된다.
Physically

물리적으로 위와 같은 형태로 동작한다.
Allocating From Explicit Free List
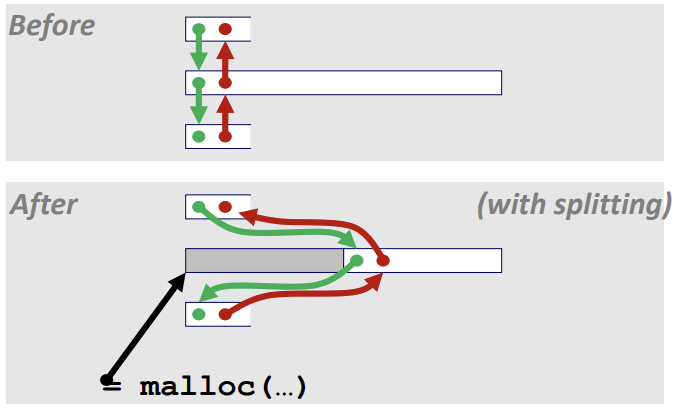
위와같이 Splitting과 함께 할당할 때, 포인터를 바꾸어 주면 된다.
Freeing With Explicit Free List
Insertion policy: 할당을 해제할 때 block을 free lists에 추가되는 방법이다.
block의 메모리 주소 순서로 하는 경우, list에서 처음부터 자신의 주소를 탐색해야하기 때문에 시간이 걸린다.
그래서 더 효율적인 LIFO(last-in-first-out) policy를 이용한다. 이 방법은 할당 해제된 block을 free list의 맨 앞에 삽입한다. 그렇다면 맨 마지막에 들어온 free block이 할당 요청이 왔을 때 맨 처음으로 나가 할당된다. 그래서 cost는 Constant time이다.
Comparison to implicit list:
- 명시적인 포인터로 free block만을 다루기 때문에 할당은 free block들의
Linear time이다.
메모리가 거의 다 찼을 때 굉장히 빠르다.- 구현이 복잡하다.
- 포인터를 위해 두 개의 추가적인 word가 필요하다. 이는 fragmentation을 유발할 수 있다.
이를 발전시켜서 만든 segregated free list를 알아보자.
Segregated Free List
이는 implicit free list에서 추가된 list이다. free block들을 크기를 구분하여 class들로 관리한다.
GNU malloc package에서 사용하는 방법이다.
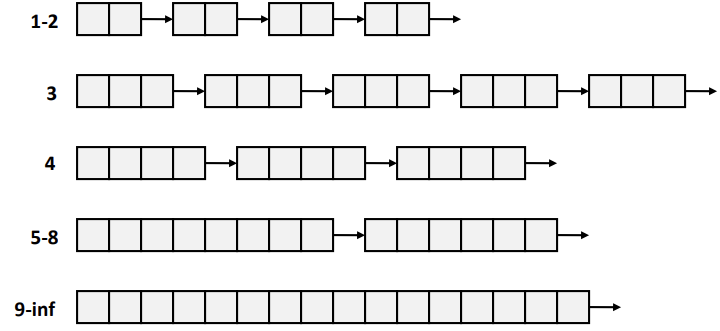
위와 같이 작은 크기들은 각각의 class로 구분하고 특정 수 이상은 2의 제곱형태의 class로 관리한다.
할당의 cost는 Logarithm Time이 된다. 요청된 size와 거의 비슷한 block을 할당할 수 있기 때문에 최대 메모리 사용률도 높아질 수 있다.
할당 원리
size n의 할당 요청
- m>n인 m class를 선택한다.
- 적절한 block을 발견하면 할당한다.(Splitting과 Insertion이 필요할 수 있다.)
- block이 없을 경우 더 큰 class를 탐색하며 반복한다.
- 반복 후에도 free block이 없을 경우 OS의 sbrk()를 이용하여 heap의 크기를 늘린다.
- n bytes를 할당하고 이 block을 가장 큰 class의 list에 삽입한다.
Summary
- 구현이 더 복잡하다.
- 높은
throughput을 가진다.- free block을 크기 별로 관리하기 때문에 높은 메모리 사용률을 가진다.
