이분탐색 Binary Search
이분(이진) 탐색 (이하 이분탐색)은 검색 알고리즘의 기초적인 알고리즘으로 검색 범위를 줄여 나가면서 원하는 데이터를 검색하는 알고리즘이다. 이분탐색 전에 선형탐색에 대해 먼저 알아보자.
선형탐색(Linear Search)
배열의 각 요소(i)를 처음부터 끝까지 순차적으로 탐색하여 주어진 항목과 일치하는 지 판단하는 검색 방법이다. javascript의 대표적인 built-in 메서드로 indexOf, includes, find, findIndex 등이 있다. 순차적으로 값을 탐색하기 때문에, 배열의 정렬과는 상관이 없다.
선형탐색의 시간 복잡도 O(N)
배열의 첫번째 요소에 일치하는 값을 찾을 경우, 최선의 경우 O(1), 최악의 경우 배열의 마지막까지 검색하게 되므로 O(N)을 갖는다. 즉, 배열의 길이(n)에 비례하는 O(N) 시간 복잡도를 갖는다.
function linearSearch(arr, val) {
for (let i = 0; i < arr.length; i++) {
if (arr[i] === val) return i
}
return -1
}
linearSearch([34, 61, 2, 100, 687, 4, 1, 56], 30) // ==> -1이분탐색(Binary Search)
이분탐색의 기본 개념은 분할과 정복(Divide and Conquer)이다. 배열을 절반으로 계속 분할하며 요소를 탐색하는 방식이다. 선형탐색보다 효율적인 방식이다. 단, 배열의 요소가 순서(0-9, a-z 등)로 분류되어 있을 경우라는 조건에만 가능하다.
이분탐색 구현 (javascript, python)
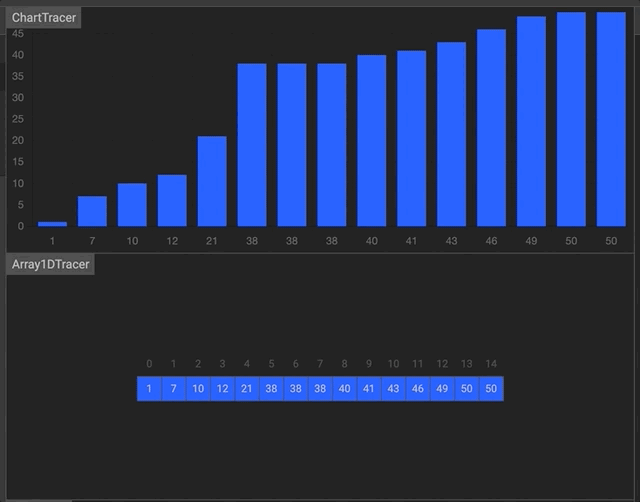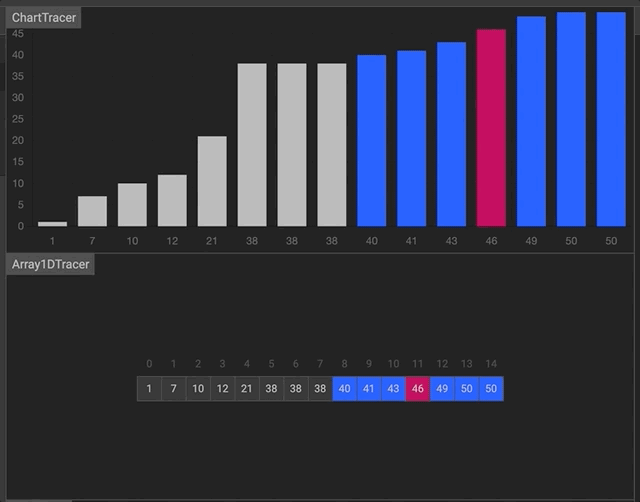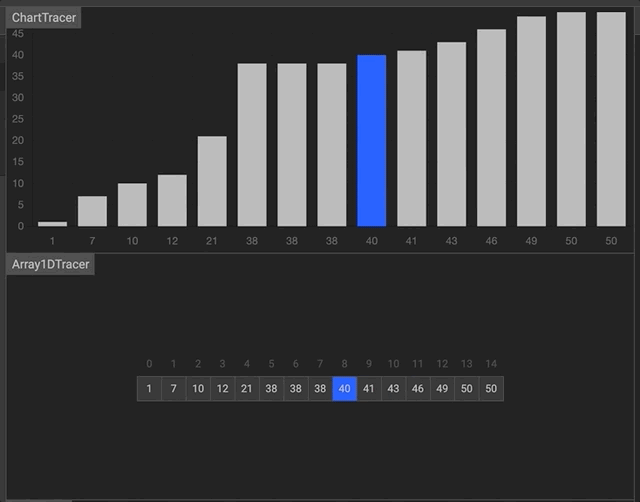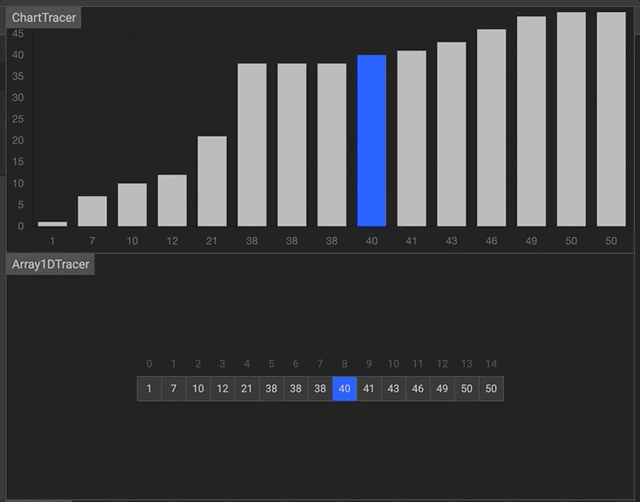
- javascript
function binarySearch (arr, val) {
let start = 0
let end = arr.length -1
while (start <= end) {
let middle = Math.floor((start + end) / 2)
if (arr[middle] === val) return middle
if (arr[middle] > val) end = middle - 1
else start = middle + 1
}
return -1
}
binarySearch([2, 5, 80, 150, 151, 180, 200, 310], 200)- python
def binary_search (arr, val):
start, end = 0, arr.len() - 1
while start <= end:
mid = (start + end) // 2
if arr[middle] == val: return middle
if arr[middle] > val: end = middle - 1
else: start = middle + 1
return -1이분탐색 시간 복잡도 O(log n)
선형 탐색과 마찬가지로 최선의 경우(middle point가 val일 경우) O(1)이며, 최악의 경우 O(log n)의 시간 복잡도를 갖는다.

거의 O(1)처럼 보인다!
🤔 잠깐 log n (logarithms) 개념에 대해!
log₂(8) "2의 몇 승의 값이 8이 되는지"를 의미하며 답은 3이다.
2³ = 8 나눗셈과 곱셈이 짝인 것처럼 로그함수와 지수함수는 짝이다.
알고리즘(그래프)에서는 이진로그를 log₂ === log라고 표현한다고 한다. n의 로그를 찾기 위해서는 n이 1보다 작아지기 전에 2로 나눠지는 횟수를 말하는데, (아래 그림처럼)

8은 1보다 같거나 작아지기까지 2로 세 번 나눠어지는 반면, 25는 2를 1이 되기까지 대략 4~5번 나눠야 함을 알 수 있다.
정확한 계산이 중요한 것이 아니니 거시적인 관점에서 O(log n)이 O(n)보다 더 효율적이고 빠르다, n이 커져도 시간이 별로 늘어나지 않는구나, 정도로 알도록 한다. ٩( ᐛ )و

다시 돌아가서, 이분탐색의 최악의 경우, log₂(32) = 5 이며 이는 O(log n)의 시간 복잡도를 의미한다.
4,294,967,296개(약 43억개)의 원소가 있는 리스트에서 원하는 특정 값을 찾아낼 때 최악의 탐색 깊이(찾는 값이 없는 경우)는 딱 32회이다. 그러나 순차 탐색의 최악의 경우는 4,294,967,296회이다.
0부터 순서대로 숫자가 들어있는 리스트라고 할 때 순차탐색이 이분탐색보다 빠른 지점은 32까지. 33부터 그 나머지 구간에서는 이분탐색이 순차탐색보다 빠르다.
_이분탐색 | 나무위키
😤 알고리즘 문제
이분탐색과 관련된 알고리즘 문제로 나온 것들. 이론이 쉬운 반면 직접 문제를 구현하기 까다로운 것 같다. 난이도가 높은 편.. 🤔
백준, 나무자르기 | 풀이
프로그래머스, 입국심사 Lv3 | 힌트
프로그래머스, 징검다리 건너기 Lv3 (카카오 2019)
더 공부해 볼 것은
이분탐색 찾아보다가 알게 되었는데, 어떤 데이터가 어떤 방식으로 들어가 있는지도 알고 있다면 이것보다 더 빠른 해시 탐색을 사용할 수 있다고 한다. (해시 탐색의 시간복잡도는 O(1) )
출처
