AWS Public Cloud 이해하기

AWS (Amazon Web Services)와 Ncloud
네이버 부스트캠프 8기에서 우리 팀 프로젝트의 서버 관리를 위해 처음 Ncloud 플랫폼 서비스를 택했다. 이때, micro 서버로 Nginx Middleware 서버를 세팅하고, standard 서버 두 대로는 DB와 WAS를 관리했다. 또, 객체 스토리지를 활용해 사용자와 음식 사진을 저장하는 기능까지 구현하며 서비스를 개발했다.
그러나 NCloud 크레딧의 만료로 AWS 클라우드 컴퓨팅 서비스로의 이전을 결정하게 됐다. 이 과정에서 AWS를 좀 더 깊이 파악할 기회를 얻었고, AWS와 Ncloud 사이의 차이점을 명확히 이해하게 되었다.
AWS는 클라우드 컴퓨팅 서비스의 선두주자로, 다양한 컴퓨팅, 스토리지, 데이터베이스 관리, 인공지능, 머신 러닝 등 폭넓은 서비스를 제공한다. AWS의 가장 큰 장점 중 하나는 글로벌 인프라를 통해 어느 지역에서나 빠르고 안정적인 서비스를 제공한다는 점이다. 반면, Ncloud는 한국 기반의 서비스로, 국내 시장에 특화된 서비스와 지원을 제공한다는 점에서 차별화된다.
AWS로의 이전을 결정한 우리는 AWS의 EC2(Elastic Compute Cloud)를 통해 가상 서버 인스턴스를 설정하고, S3(Simple Storage Service)를 사용해 객체 스토리지를 관리하는 등, Ncloud에서의 경험을 AWS의 서비스에 맞춰 적용하게 됐다. 이 과정에서 AWS의 더 넓은 범위의 기술 스택과 서비스 옵션을 경험할 수 있었다.
결국, 이 전환은 우리에게 AWS와 Ncloud의 차이점을 깊이 이해하고, 두 클라우드 서비스 플랫폼의 각각의 장점을 활용하는 방법을 배울 수 있는 좋은 기회가 됐다. AWS의 서비스와 인프라를 활용하는 것에서 Ncloud에서의 경험은 많은 도움이 되었다.

EC2
AWS에서 서버 인스턴스를 할당하는 것은 EC2를 통해 이루어지는데, 이는 NCloud와 같이 Subnet 설정, ACL 규칙 설정, VPC 할당, 서버 인스턴스 생성의 순서로 이루어졌다.
예전에는 프리티어 계정에서 제공하는 AWS EC2의 인스턴스 유형은 T2 micro였다고 들었는데, 이번에 EC2를 설정하는 과정에서 T3 micro를 제공받았다.
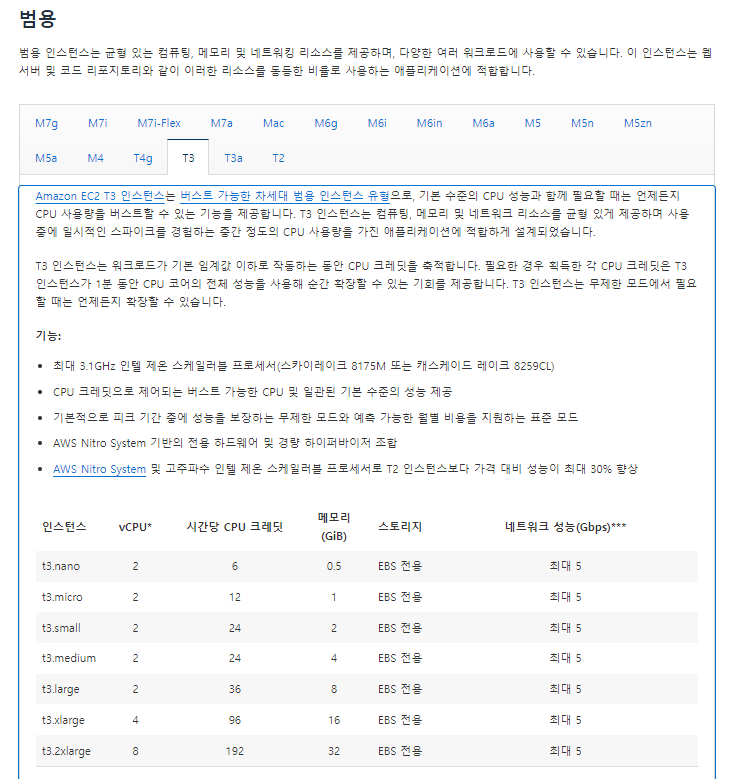
서버를 설정하기 위해서 EC2 T3 인스턴스를 이용하기로 했는데 이후에 추가 선택지가 있었다.
EC2 vs EC2 auto-scailing vs Lambda
EC2
EC2는 우리가 흔히 알고있는 서버 인스턴스를 직접 관리하고 구축하는 방법이다. 서버의 트래픽이 증가한다고 해서 서버가 확장되거나, 트래픽이 감소한다고 해서 서버가 축소되지 않고 일정한 비용을 내며 서버를 직접 관리하는 것이다.
EC2 auto-scailing
나는 Lambda보다 EC2 auto-scailing이 더 신기했는데, 기존에 나는 서버리스 어플리케이션에만 서버의 자동 확장 및 축소 기능이 추가되는 줄 알고 있었다.
그러나, AWS에서는 직접 관리할 수 있는 EC2에도 트래픽에 따른 서버의 확장 및 축소가 자동으로 이루어지도록 설정할 수 있었다.
물론, 그에 따른 비용은 자동 측정되어 지불해야 하지만 좋은 서비스라고 생각한다.
Lambda
AWS의 Lambda Service는 다른 말로 Serverless-application 이라고 할 수 있는데 , 이는 서버의 직접 구현 없이 서비스를 운영할 수 있도록 해주는 서비스이다.
Lambda Service 이용자는 자신이 만들 서비스를 이용하는 사용자의 요청만 처리할 수 있는 api 응답, 관리 코드만 Lambda에게 제공하면 그 구조와 관리는 전적으로 AWS가 알아서 해주는 것이다.
서버 접속하기
EC2로 Ubuntu Server를 설치했는데 접속 과정에서 문제가 있었다.
정확히는 Github Action을 이용해 Docker내 컨테이너로 CI/CD의 자동화를 진행하는 과정에서 문제가 생겼다.
AWS에서 서버의 접속은 NCloud와 같이 password를 이용해 접속하는 방식이 아니었다.
.pem 키 파일을 이용해 사용자가 aws 서비스에게 인증을 하는 방식을 통해 서버로 접속하는 방식이었는데 참 난감했다.
Github Secret Key로 등록을 해둔다 하더라도, 이를 실행하는 github workflow 파일에서 어떻게 이를 파일로 인증을 할 지에 대한 고민이었다.
결과적으로, 워크플로우 내에서 SSH 키 파일을 동적으로 생성하여 EC2 인스턴스에 접속하는 과정을 적용하기로 했다. Linux echo 명령어와 redirection 연산자를 이용해 코드를 파일로 저장하는 방식을 통해 이를 해결할 수 있었다.
스토리지 서비스
AWS로 서버를 이전하면서 Object Storage 이외에도, Block Storage, File Storage 에 대해서 알게 되었는데 각 Storage가 어떤 Storage인지, 어떤 장점과 단점이 있는지 정리해보았다.
객체 스토리지
내가 기존 프로젝트에서 사용한 객체 스토리지는 비정형 데이터 ( 고정된 스키마를 따르지 않는 데이터를 말한다. ex: 이미지, 오디오, 비디오 등) 와 함께 메타데이터를 저장할 때 자주 사용된다.
웹 서비스에서 사용자 프로필 이미지나 녹음, 스트리밍 비디오 파일을 저장해야 할 때 객체 스토리지를 사용한다.
클라우드 컴퓨팅 서버는 이러한 데이터 전체를 저장하지 않는다.
객체 데이터는 어딘가에 있는 여러 분산된 스토리지 에 저장된다.
컴퓨팅 서버의 스토리지는 이러한 분산된 스토리지에 접근할 수 있는 주소값을 저장함으로써 엄청난 양의 객체 데이터에 대한 접근이 하나의 스토리지를 통해 가능하게 한다.
서버는 자신의 서비스를 이용하는 사용자에게 이러한 데이터를 HTTPS나 HTTP를 통해 접근이 가능하게 할 수 있다.
때문에 객체 데이터의 저장이 추가될때에도 비교적 다른 스토리지에 대해 굉장히 유연하다는 장점이 있다.
그러나, 이렇게 분산된 스토리지에 데이터들이 저장된다는 것은 여러 데이터에 대한 접근 속도가 일정하지 않다는 단점을 가진다.
사용자는 어디서나 HTTP나 HTTPS 프로토콜을 통해 데이터에 접근하므로 접근이 용이하지만, 그만큼 속도가 일정하지 않다.
때문에 자주 변경이 되고, 접근해야 하는 서비스에 이용되는 데이터라면 객체 스토리지를 활용하는 것은 부적절할 수 있다.
블록 스토리지
블록 스토리지는 컴퓨팅 서비스 스토리지의 크기를 일정한 블록 크기로 나누어 관리하는 방식이다.
때문에 항상 일정한 크기를 가지는 데이터를 저장할 때 굉장히 용이하다.
예를 들어 DB 테이블 스키마를 통해서 정형화된 데이터의 저장이 필요하다면, 이 테이블 엔티티 데이터는 항상 일정한 크기를 가지므로 고정 크기 블록 스토리지 서비스에 저장하기 적합하다.
뿐만 아니라, DB 데이터를 접근 횟수가 많고 변경이 빈번한 만큼 사용자에게 일정한 데이터 접근 속도를 제공할 필요가 있기때문에
중앙집중형 데이터 관리 스토리지인 블록 스토리지가 적합하다.
우리가 클라우드에서 서버 인스턴스를 할당할 때 제공받는 스토리지가 바로 이 블록 스토리지이다.
이를 통해 서버의 운영체제는 물리적 하드 드라이브에 접근하는 것처럼 스토리지는 사용할 수 있는 것이다.
파일 스토리지
파일 스토리지는 데이터를 파일 형태로 저장하는 스토리지이다.
파일 스토리지는 데이터가 폴더와 파일을 이용하는 계층적 데이터를 저장할 때 효과적이다.
문서를 공유하고, 협업하는 일에서 효과적이다.
