클러스터, 세컨더리 인덱스

서론
전에 작성한 포스트에서 나는 DB에서의 인덱스 역할이 무엇인지, 어떤 구조로 인덱스가 생성되는지 다루었다.
이번 포스트에서는 이러한 인덱스 구조지만 다르게 적용이 되는 클러스터 인덱스, 세컨더리 (Non-cluster)인덱스에 대해서 다루어보겠다.
특히, 클러스터와 세컨더리가 MySQL의 InnoDB, MyISAM 스토리지 엔진에서 어떻게 적용되었는지 정리하고 비교해보려 한다.
이전 포스트 참고 : https://velog.io/@rmsgur/index
클러스터 인덱스
클러스터 인덱스는 b-tree, b+tree 두 방법 모두로 구현할 수 있다.
그러나 InnoDB를 예로 들기로 했으니 B+tree로 적용한다는 가정 하에 정리했다.
클러스터 인덱스는 InnoDB,MyISSAM 중 InnoDB 스토리지 엔진 에만 적용되는 인덱스이다.
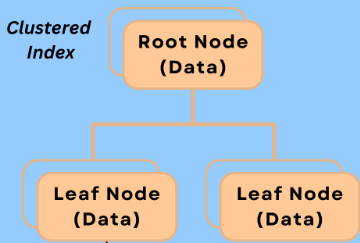
클러스터 인덱스는 각 리프노드에 데이터가 직접 저장된 방법이다.
"이게 그냥 B+tree 아닌가?"라고 생각할 수 있지만 세컨더리 인덱스에는 다른 방법으로 데이터를 가리킨다. 이는 밑에서 자세히 다루겠다.
전 포스트에서도 다루었지만 B+tree는 각 노드들이 트리 구조 ( 이진 트리 X )로 연결되어 있다. 각 노드는 키를 가지고 있으며 이러한 키를 기준으로 정렬을 통해서 데이터가 저장될 리프 노드의 위치를 특정할 수 있다.
클러스터 인덱스는 주로 DB 테이블 엔티티에서 Primary Key에 적용된다.
테이블에서 PK 컬럼이 생성됨에 따라서 클러스터 인덱스가 자동으로 생성되며 PK가 복합키일 때에도 클러스터 인덱스는 이 복합키를 기준으로 정렬하여 하나만 생성된다.
클러스터 인덱스의 리프 노드에 저장되는 데이터는 "전체 데이터" 를 의미한다.
단지 저장되는 순서가 PK값을 기준으로 정렬이 되는 것이다.
PK값만 리프노드에 저장된다고 오해하지 말자!!
그럼 여기서 의문이 들 수 있다.!
"클러스터 인덱스의 리프 노드마다 pk기준으로 정렬이 되고,전체 데이터가 저장되는 거라면
테이블 원본 데이터가 클러스터 인덱스 데이터 인가?
or 테이블 원본 데이터는 클러스터 인덱스 데이터와 별개로 분리되어 존재하나?
답은 "분리되어 있지 않다" 이다. 클러스터 인덱스에는 모든 테이블 데이터가 리프노드마다 저장되어 있으므로 별개의 테이블 원본 데이터가 필요하지 않다.
클러스터 인덱스의 데이터가 테이블 원본 데이터이다.
밑에서 설명한 세컨더리 인덱스의 리프 노드도 결국은 이 클러스터 인덱스의 리프 노드 데이터를 가리키기 때문에 테이블 원본 데이터가 분리되어 존재한다 해도 사용할 일이 없다.
세컨더리 인덱스
세컨더리 인덱스는 InnoDB,MyISSAM 두 엔진 모두에 적용되는 인덱스이다.
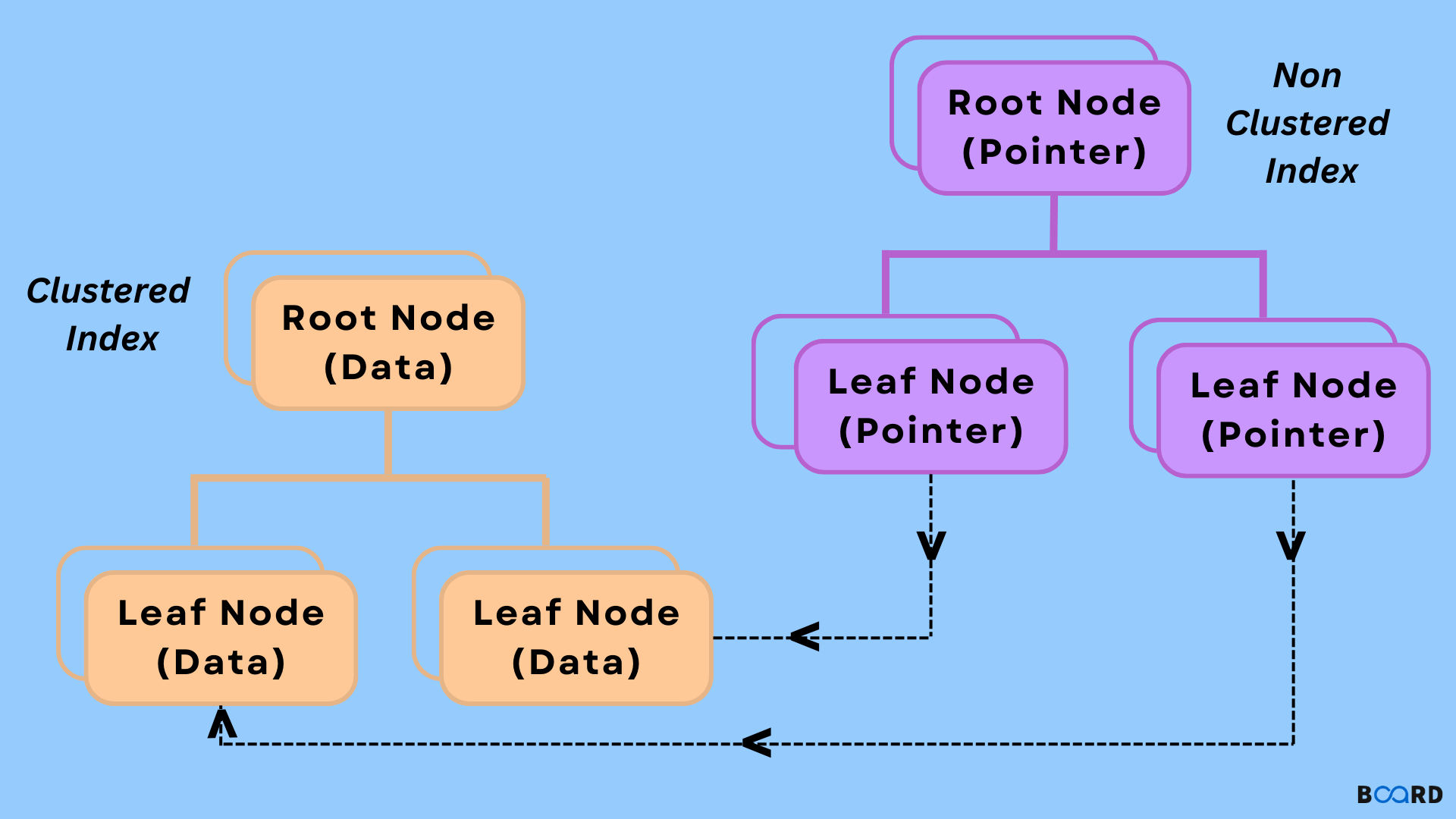
MySQL의 스토리지 엔진에서 사용하는 세컨더리 인덱스의 경우에는, 각 리프 노드가 실제 데이터를 가지는 노드의 위치가 저장된다.
이때, 데이터 노드의 위치는 원본 데이터인 클러스터 인덱스의 리프 노드를 가리키는 것이다.
세컨더리 인덱스는 PK가 아닌 컬럼들에 대해서 사용자가 임의로 인덱스를 생성하려 할 때 적용되는 인덱스이다.
예를 들어 DB 테이블에서 내가 Primary Key를 Auto-increment로 다른 하나의 key를 이름으로 하는 두 엔티티 컬럼을 만들었다면 auto-increment에 대해서는 클러스터 인덱스가 자동으로 적용되고 "이름" 에 대해서는 아무런 인덱스가 적용되지 않는다.
그러나 내가 더 빠른 탐색을 위해서 "이름" 컬럼에 대해서도 인덱스를 적용하고 싶다면 SQL 명령어로 적용할 수 있다.
"CREATE INDEX "인덱스 이름" on "테이블 명"(이름)"이때, 세컨더리 인덱스가 적용되는 것이다.
이후 내가 "이름" 컬럼을 조건절로 데이터를 찾는다면 세컨더리 인덱스를 통해서 리프 노드에 도달하게 된다.
그런데 세컨더리 인덱스에도 클러스터 인덱스와 같이 전체 데이터를 리프노드마다 저장하게 되면 너무 많은 메모리를 요구하게 된다.
이는 데이터 변경에 따른 인덱스마다 전체 변경을 해야 하게 되므로 실제 세컨더리 인덱스의 리프 노드는 테이블 엔티티 데이터를 저장하는 것이 아닌 해당 데이터를 가지고 있는 클러스터 인덱스의 리프노드의 주소를 저장한다.
공통점
클러스터, 세컨더리 인덱스 모두 B-tree, B+tree(주로 이거) 를 이용해 구현할 수 있다.
각 데이터는 모두 인덱스를 적용하는 key 값을 기준으로 정렬한다.
차이점
클러스터 인덱스는 PK를 기준으로 생성되기 때문에 단 하나의 클러스터 인덱스만이 테이블마다 존재한다. PK가 복합키일 때에도 클러스터 인덱스는 이 복합키를 기준으로 정렬하여 생성된다.
클러스터 인덱스의 리프 노드는 실제 데이터를 가지고 있고 이것이 원본이다.
세컨더리 인덱스는 PK가 아닌 일반 키에 인덱스를 적용하려 할 때 생성된다.
세컨더이 인덱스의 리프 노드는 실제 데이터를 가지는 노드의 위치를 가지고 있어 이를 타고 들어가 원본에 접근할 수 있다.
