회귀(Regression) 분석 명칭 유래
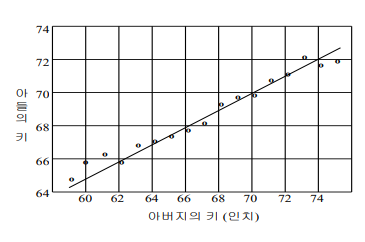
프란시스 골턴(F. Galton, 1889) 연구는 회귀 분석의 기초를 제공했다. 이 연구에서 얻은 관찰 중 하나는 부모의 키가 크면 자녀의 키도 크지만, 자녀의 키는 평균키로 회귀한다는 것이다.
여기서 "평균키로 회귀(Regression)함"이란, 부모의 키가 평균보다 크면 자녀의 키도 평균보다 크다는 경향이 보이지만, 부모의 키를 포함한 다른 요인들의 평균적인 영향을 받아 부모의 키와 평균적인 키 사이에서 "회귀"되는 경향을 보인다는 것을 의미한다.
회귀분석은 독립변수(부모의 키)와 종속 변수(자녀의 키)간의 관계를 설명하는 모델을 만드는 것을 의미한다.
이러한 관계를 설명하는 직선형태를 일차함수 관계식이라고 한다. 이것이 의미하는 바는 부모의 키와 자녀의 키 사이에 일정한 선형적인 관계가 있으며, 이를 통해 자녀의 키를 예측할 수 있다는 것이다.
회귀분석이란?
회귀모형 예시
자녀의 키(𝒚) = 𝛽0 + 𝛽1 부모의 키(𝓧𝒊) + 𝛽2 환경적인 요인 + ε
-
독립변수(𝓧𝒊) = 부모의 키, 환경적인 요인 + ε
독립변수란, 어떤 실험에서 실험자가 직접 변경하는 변수를 의미한다. -
종속변수(𝒚) = 자녀의 키
종속변수란, 독립변수의 값이 변함에 따라 달라지는 값을 나타내는 변수이다.
즉, 회귀분석은 종속변수가 독립변수들에 의해 어떻게 설명되는지를 분석하는 통계적 기법이다.
-
Intercept(절편항) 𝛽0
회귀 모델에서 Intercept은 독립 변수가 모두 0일 때, 종속 변수의 예측값을 나타낸다. 즉, 독립 변수에 영향을 받지 않는 값을 의미한다. -
Slope(기울기) 𝛽1, 𝛽2
Slope은 회귀직선의 기울기를 의미하며, 독립 변수의 단위 변화에 따른 종속 변수단위 변화에 따른 종속 변수의 변화를 나타낸다.𝛽1은 첫 번째 독립 변수의 기울기이고, 𝛽2는 두 번째 독립 변수의 기울기이다.
-
Error(오차항) ε
회귀 모델로 설명하지 못하는 변동이나 불확실성을 나타내며, 종속 변수와 회귀 모델로 예측된 값 사이의 차이를 의미한다.회귀모델은 오차항을 최소화하는 과정이며, 이를 통해 예측된 값이 실제 값과 가까워지게 모델링한다.
회귀분석을 하는 목적
1. 변수들 간에 관계를 설명하는 회귀 모형 구축(Model Building)
종속 변수와 독립 변수들 간의 관계를 나타내는 정확한 회귀 모델을 구축한다. 이를 위해서 독립 변수들의 선택과 회귀식의 형태가 중요하다.
2. 모형에 포함된 모수들의 추정(Parameter Estimation)
모수 추정은 회귀 모델의 파라미터(Intercept, Slope, Error)을 구하는 과정을 의미한다. 이 과정에서는 추정 방법과 추정값의 통계적 유의성 여부가 중요하다.
3. 회귀 모델을 이용한 예측(Prediction)
추정된 회귀 모델을 사용하여 예측을 할 경우, 예측정확도를 검사할 필요가 있다.
선형 회귀 유형
종속변수가 독립변수들에 의해 어떻게 설명되는지를 분석하는 통계적 기법
단순 선형 회귀(Simple Linear Regression Analysis)
단순 선형 회귀는 독립변수가 한 개인 선형모형의 분석 기법이다.
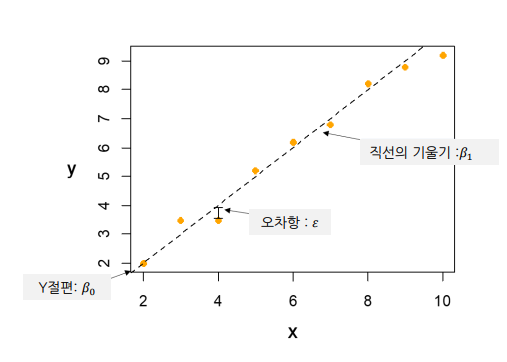
표현식1 : Y= β0*X + β1 + ε
𝛽0 : 절편(intercept), 𝛽1 : 기울기(slope)
표현식2
y = wx + b
w : 독립 변수의 가중치(기울기), b : 절편(intercept)
-
회귀계수 𝛽0와 𝛽1 을 추정하기 위해서는 종속변수 Y와 독립변수 X의 관측값의 표본이 필요하다.
-
선형 회귀 예시
import numpy as np
from sklearn.linear_model import LinearRegression
# 샘플 데이터 생성
X = np.array([1,2,3,4,5]).reshape(-1, 1) # 독립변수
y = np.array([2,3,4,5,6]) # 종속 변수
# 모델 초기화 및 학습
model = LinearRegression()
model.fit(X,y)
# 학습된 모델로 에측
X_new = np.array([[6]]) # 새 데이터
y_pred = model.predict(X_new)
print("예측값 :", y_pred[0])
# 출력 결과 - 예측값 : 7.0다중 회귀분석(Multiple Regression Analysis)
다중 회귀분석 독립변수가 두 개 이상인 경우에 쓰는 분석 기법이다.
표현식1: Y= β0*X0 + β1X1 + β2X2+…… βnXn+ ε
표현식2 : y = w1x1 + w2x2 + ... wnxn + b
다변량 회귀분석(Multivariate Regression Analysis)
다변량 회귀분석은 종속변수들 간의 상관관계가 있을 경우 사용하는 분석 기법이다.
표현식
𝑦𝟏 = 𝛽10 + 𝛽11𝒙𝟏+ … + 𝛽1𝑝 𝒙𝒑 + 𝜖
𝑦𝟐 = 𝛽20 + 𝛽21𝒙𝟏+ … + 𝛽2𝑝 𝒙𝒑 + 𝜖
선형 회귀분석의 4가지 기본가정
-
1. 선형성 (Linearity)
종속 변수와 독립 변수 간의 관계가 선형적이어야 한다.선형 회귀분석의 경우 종속변수(y)와 독립변수(x) 간의 직선 형태를 띤 관계가 있을 것이라고 가정하고 예측하는 모델이다. 때문에 x와 y간의 선형성이 없다면 정확도가 떨어지고, 분석결과도 나쁘다.
-
2. 독립성 (Independence)
변수들 간에 독립성이 유지되어야 하는 것으로, 여러 변수들간의 상관관계가 없어야 한다는 것이다.다중 회귀분석에서 중요한 기본가정으로, '단순회귀분석'은 해당되지 않는다.만약 변수들간의 상관관계가 있다면
다중공선성(Multicollinearity)문제가 발생하게 되고, 잘못된 결과값이 나오기 때문이다.다중공선성(Multicollinearity)을 해결하기 위해서는 상관관계가 높은 데이터를 삭제하거나, 변수를 결합하여 새 변수를 생성하는 것이다.
-
3. 등분산성 (homoscedasticity)
등분산성은 분산이 일정해야 한다는 것을 의미이다. 여기서 분산의 주체는잔차이다. (잔차는 실제 관측값과 예측된 값 사이의 차이를 말하며, 두 값 사이의 오차를 나타낸다.)즉, 등분산성은 모델이 예측한 값 주변으로 잔차가 고르게 퍼져 있어야 한다는 것이다. 만약 독립 변수의 값에 따라 잔차의 흩어짐이 다르다면 등분산성이 만족되지 않은 것이다.
-
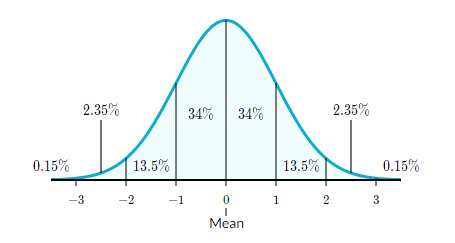
4. 정규성 (Normality)
잔차가 정규성을 만족하는지 여부로, 잔차가 정규분포의 형태를 띠는지를 의미한다. 회귀 분석에서는 잔차가 정규 분포를 따른다고 가정하고 모델을 만들기 때문이다.
회귀 계수의 추정
회귀 계수(β0,β1)란, 독립변수가 변화함에 따라 종속변수에 미치는 영향력 크기를 의미한다. 회귀 분석에서는 회귀 모델을 통해 종속 변수와 독립 변수 간의 관계를 모델링한다. 선형 관계에서는 기울기와 절편을 통해 나타낸다.
회귀 계수의 추정은 최소제곱법(Least Squares Method)과 같은 방법을 사용하여 모델의 오차를 최소화하도록 회귀 계수를 조정하는 과정을 의미한다.
최소제곱적합법 (LSE, Least Square Estimation)
최소제곱적합법(LSE)은 회귀 모델에서 예측된 값과 실제 관측값 사이의 오차(잔차)를 최소화하는 파라미터를 찾는 방법이다.
| 구분 | 의미 | 단순회귀분석 모형 | 다중 회귀분석 모형 |
|---|---|---|---|
| 회귀식 | 독립 변수와 종속 변수 간의 선형 관계를 나타냄 | ||
| 오차 제곱 합 (S) | 회귀 직선과 관측값 간의 거리를 제곱한 값들을 모두 합한 것 | ||
| 최소 제곱 방정식 | x와 y 간의 선형 관계를 잘 설명하는 직선의 방정식 |
예시
광고비(x)와 매출액(y)을 이용해 선형회귀분석을 한다고 가정해보자.
- = 3 : 광고비가 0일때 매출 추정값이다.
- = 1.5 : 광고비가 1 증가할 때 매출액은 1.5 증가
- 예측 : 광고비를 10만큼 투자할 경우 예상 매출액은? : 3+1.5x10 = 18
결론 : 광고비를 10 증가시키면 매출액은 15만큼 증가될 것이다라고 예측가능하다.
회귀모형의 해석
오차와 편차
- 오차는 예측값과 실제값의 차이를 의미하며, 식은 으로 표현한다.
- 편차는 관측치가 평균으로부터 떨어져 있는 정도, 즉 평균과의 차이를 의미한다. 식으로는 으로 표현한다.
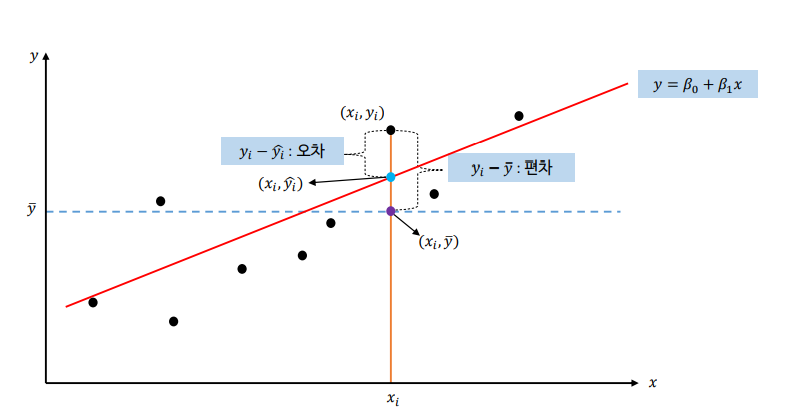
제곱합(Sum of Square)를 이용한 모델의 적합성을 평가
- TSS (Total Sum of Squares, 총 제곱합)
- 종속 변수의 값들이 전체 평균에서 얼마나 퍼져 있는지를 나타낸다.
- TSS는 각 데이터 포인트의 실제 값과 전체 데이터의 평균 값 간의 차이를 제곱하여 모두 더한 값이다.
- 목적 : 모든 데이터 포인트가 평균 주변에 얼마나 분산되어 있는지를 측정한다.
- SSR (Regression Sum of Squares, SSR)
- 총 변동 중에서 회귀식에 의해 설명되는 변동성의 크기를 의미한다.
- SSR은 회귀 모델로 설명되는 종속 변수의 값과 전체 평균 값 간의 차이를 제곱하여 모두 더한 값이다.
- 목적 : 회귀 모델이 종속 변수의 변동성을 얼마나 잘 설명하는지를 측정한다.
- SSE(Residual Sum of Squares, 오차 제곱합)
- 회귀 모델로 설명하지 못하는 나머지 변동성의 크기를 나타낸다.
- SSE는 각 데이터 포인트의 실제 값과 회귀 모델로 예측한 값 간의 차이를 제곱하여 모두 더한 값이다.
- 목적 : 회귀 모델이 설명하지 못하는 오차의 크기를 나타내며, 이 값이 작을수록 모델이 데이터를 잘 설명하고 있다는 것을 의미한다.
결정계수 (R-Square)
결정계수 (R-squared)는 회귀 분석에서 모델의 적합도를 나타내는 지표 중 하나이다. 0에서 1 사이의 값을 가진다. 높은 결정계수 값은 모델이 종속 변수의 변동성을 잘 설명한다는 것을 나타내며, 더 적합한 모델을 의미한다.
하지만 주의할 점은, 값이 높다고 해서 모델이 항상 완벽하게 데이터를 설명하지 않기 때문에 다른 모델 평가 지표와 함께 고려해야 한다.
참고한 사이트
http://kocw-n.xcache.kinxcdn.com/data/keris/2021/leeyoonmo1021/3-4.pdf
