밑바닥부터 시작하는 딥러닝 공부
1.[밑바닥부터 시작하는 딥러닝1] 01. 퍼셉트론과 신경망, 활성화 함수
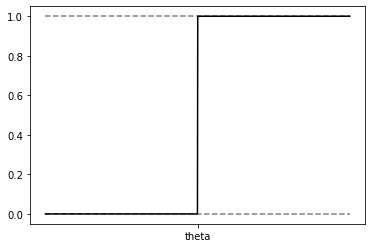
퍼셉트론(Perceptron) 다수의 신호를 입력받아 하나의 신호를 출력 신경망(딥러닝)의 기원 > $$y = \left\{ \begin{matrix} 0& w1x1+w2x2 \le \theta\\ 1& w1x1+w2x2 > \theta \end{matrix}\rig
2.[밑바닥부터 시작하는 딥러닝1] 02. 순전파 및 역전파
훈련데이터로부터 매개변수의 최적값을 자동으로 획득$\\;\\;\\; \\rarr$ 자동으로 학습할 때 손실함수(Loss)를 지표로 사용!$\\;\\;\\;\\;\\;\\; \\rarr$ 손실함수를 최소화하는 매개변수를 찾는다.$\\;\\;\\;\\;\\;\\;\\;\\
3.[밑바닥부터 시작하는 딥러닝1] 03. 신경망 학습 관련 기술

매개변수의 최적값 찾는 문제확률적 경사하강법(Stochastic Gradient Descending)$$W \\larr W - \\eta \\cfrac{\\partial L}{\\partial W}$$기울어진 방향으로 일정 거리만 이동단순하지만 비효율적(특히 비등방성
4.[밑바닥부터 시작하는 딥러닝1] 04. 합성곱 신경망(CNN)
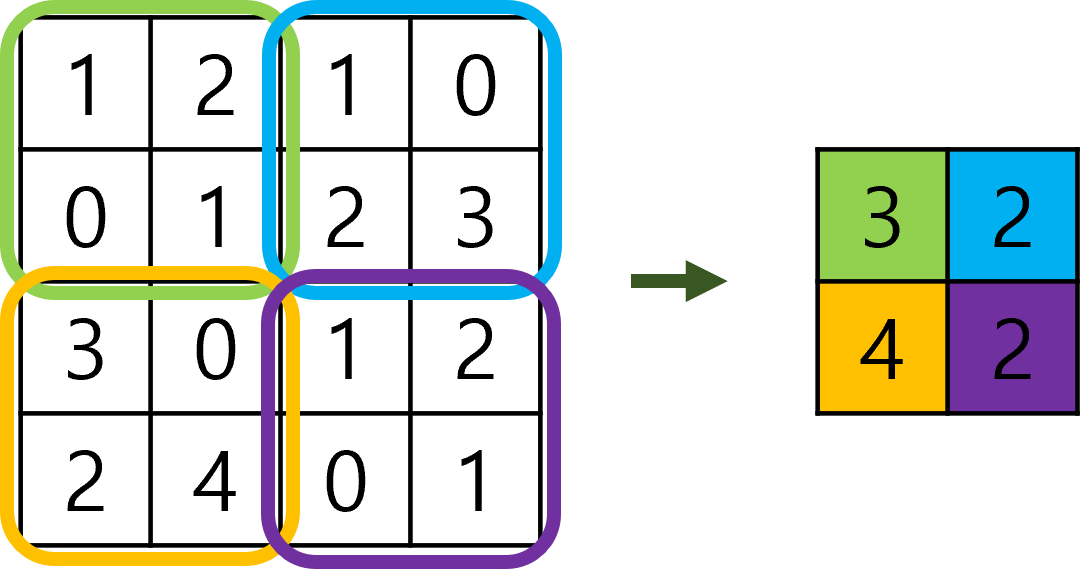
합성곱 신경망(CNN; Convolutional Neural Network) 이미지 인식, 음성 인식에서 자주 사용 합성곱 계층(Convolution Layer), 풀링 계층(Pooling Layer) 존재 풀링 계층은 생략 가능 완전 연결 계층(Fully-
5.[밑바닥부터 시작하는 딥러닝2] 05. Word Embedding
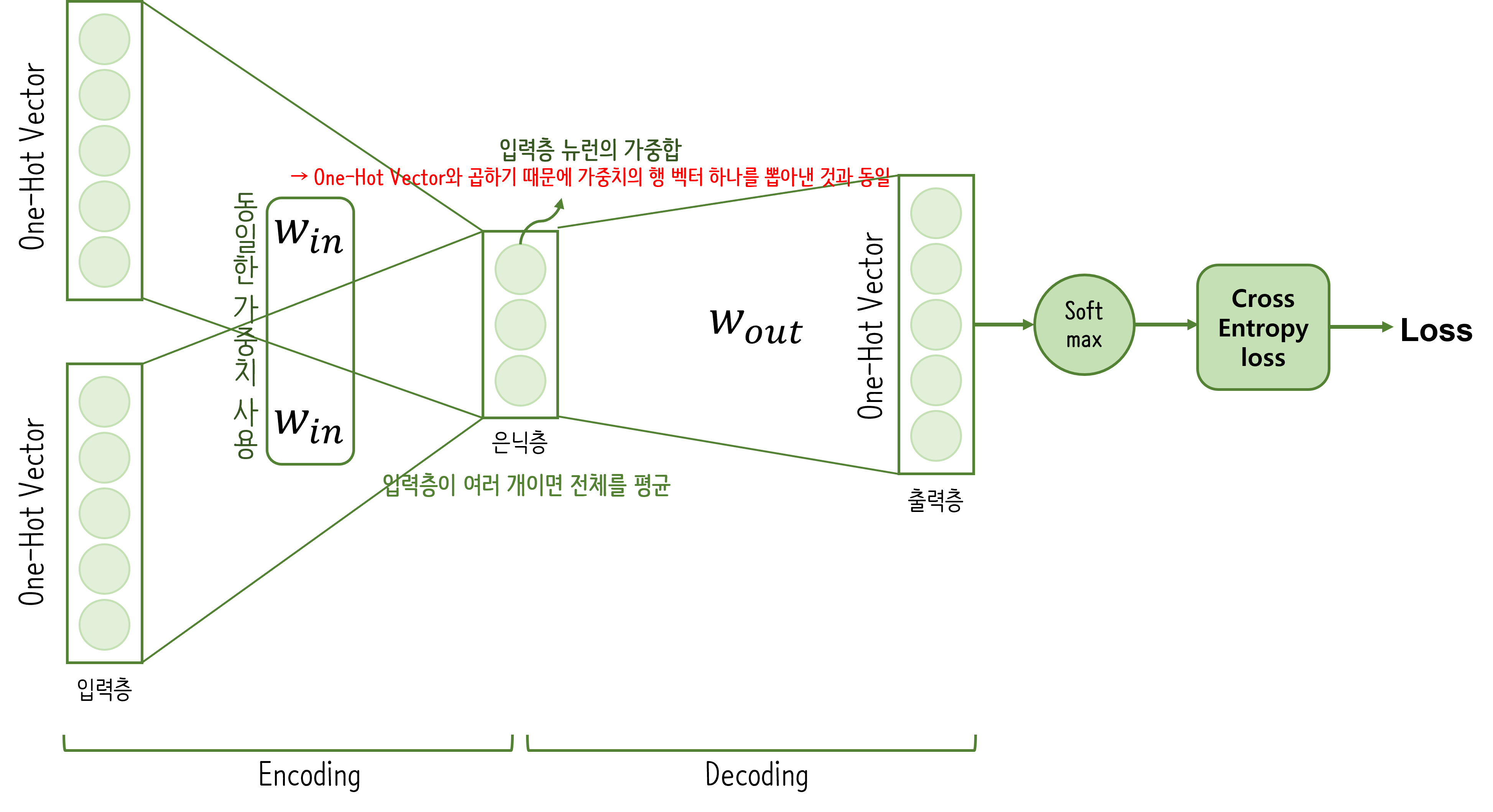
자연어: 우리가 평소에 쓰는 말자연어 처리(NLP; Natural Language Processing): 우리의 말을 컴퓨터에게 이해시키기 위한 분야말은 문자로 구성되고, 문자는 단어로 구성된다.$\\therefore$ NLP에서는 단어의 의미를 이해시키는 것이 중요함
6.[밑바닥부터 시작하는 딥러닝2] 06. 언어 모델
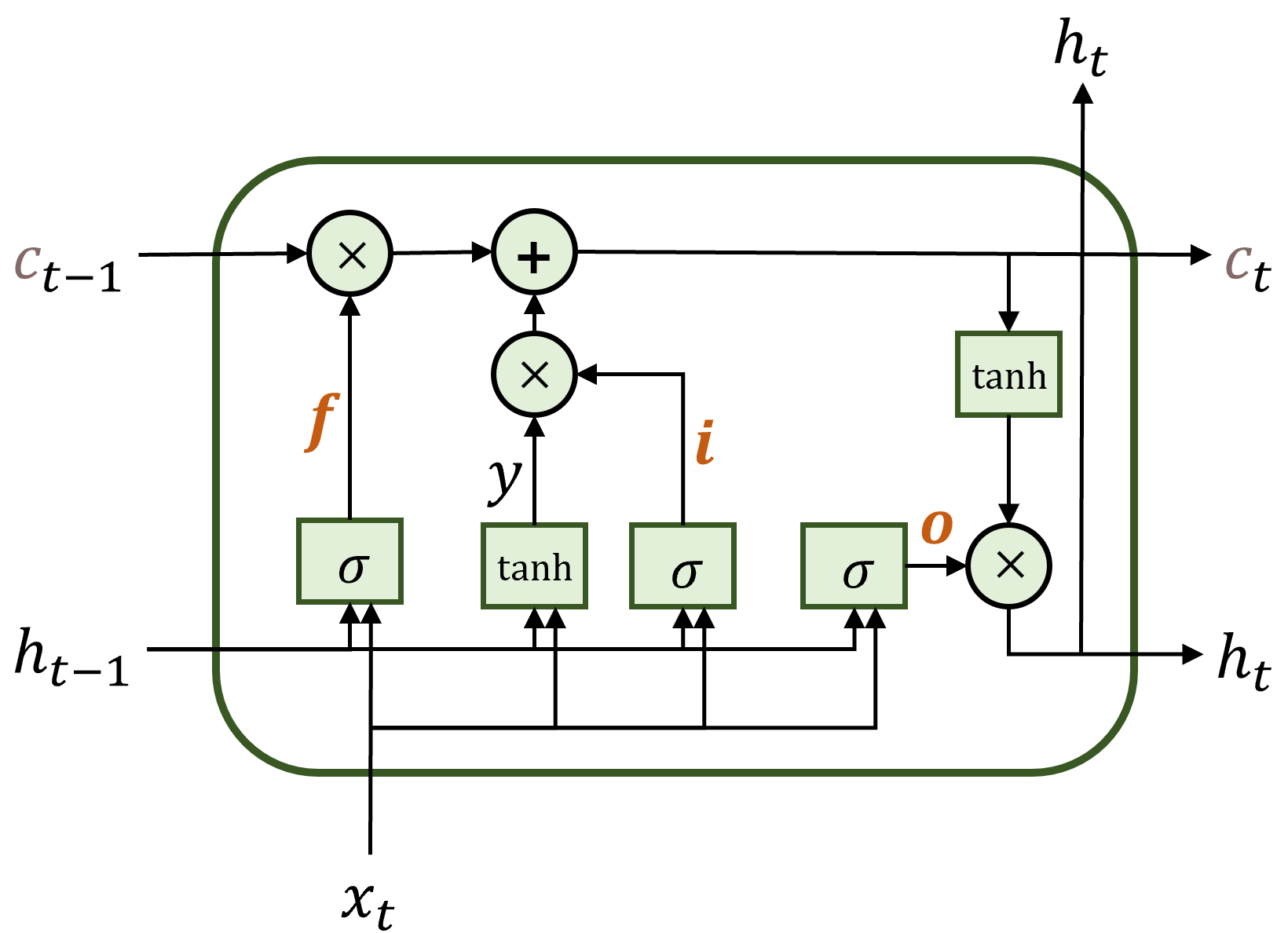
피드포워드 신경망(FeedForward Network) 흐름이 단방향인 신경망 시계열 데이터를 다루지 못함 순환신경망(RNN; Recurrent Neural Network) 등장 W2V: $w{t-1}$, $w{t+1}$로 $w{t}$ 예측 $\rarr L=
7.[밑바닥부터 시작하는 딥러닝2] 07. Seq2Seq

주어진 단어들에서 다음에 출현하는 단어의 확률분포 출력확률이 가장 높은 단어 선택'결정적 방법' (결과 일정)'확률적'으로 선택(sampling)결과가 매번 다를 수 있음해당 작업을 <eos>(종결기호)가 나올 때 까지 반복시계열 데이터를 또 다른 시계열 데이터로
8.[논문 리뷰] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
BERT는 모든 계층에서 왼쪽, 오른쪽 문맥의 unlabeled text로 부터 깊은 양방향 표현법을 사전 학습하기 위해 설계되었다.사전 학습된 BERT 모델은 추가적인 1개의 output layer만 추가하여 fine-tuning되고 넓은 범위의 task에서 SOTA