언어모델
- 주어진 단어들에서 다음에 출현하는 단어의 확률분포 출력
- 확률이 가장 높은 단어 선택
- '결정적 방법' (결과 일정)
- '확률적'으로 선택(sampling)
- 결과가 매번 다를 수 있음
- 해당 작업을 <eos>(종결기호)가 나올 때 까지 반복
- 확률이 가장 높은 단어 선택
Seq2Seq

- 시계열 데이터를 또 다른 시계열 데이터로 변환 (Encoder-Decoder 모델)
ex) 기계번역, 요약, 질의응답, 챗봇, 이미지 캡셔닝 등 - 입력 데이터를 Encoder로 인코딩 후, Decoder을 통해 인코딩 된 데이터 디코딩
- 인코딩한 정보에는 결과 값에 필요한 정보 응축
- LSTM 2개로 구성 (Encoder LSTM, Decoder LSTM)
- Encoder가 출력하는 벡터 는 Encoder LSTM의 마지막 은닉 상태
- 고정 길이 벡터로 변환 해주는 과정
- 순전파 시, 인코딩 된 정보 Decoder에 전달
- 역전파 시, 연결된 다리를 통해 기울기가 Decoder로 부터 Encoder로 전달
- 샘플마다 데이터의 시간 방향 크기가 다름 '가변 길이 시계열'
- 미니배치로 학습시키기 위해 패딩(padding) 시행
- 원래 데이터에 의미 없는 데이터를 채워 길이 균일하게 맞춤
- 패딩용 문자까지 처리하게 되므로 패딩 전용 처리 추가 필요
1. Decoder에 입력된 데이터가 Padding이라면 손실의 결과에 반영 x(손실 함수 계층에 마스크 기능 추가)
2. Encoder에 입력된 데이터가 Padding이라면 이전 시각의 입력 그대로 출력
- 미니배치로 학습시키기 위해 패딩(padding) 시행
- Decoder의 입력데이터와 출력데이터는 형태가 다름
ex) 입력 데이터: ['-', '6', '2', ''], ['6','2','',''] - 학습 시와 생성 시 데이터 부여 방법이 다름
- 학습 시에는 정답을 알기 때문에 한번에 부여
- 추론 시에는 정답을 모르기 때문에 최초 시작을 알리는 구분 문자만 부여 후 출력 결과를 통해 추론
class Encoder:
def __init__(self, vocab_size, wordvec_size, hidden_size):
V, D, H = vocab_size, wordvec_size, hidden_size
rn = np.random.randn
embed_W = (rn(V,D)/100).astype('f')
lstm_Wx = (rn(D, 4*H)/np.sqrt(D)).astype('f')
lstm_Wh = (rn(H, 4*H)/np.sqrt(H)).astpye('f')
lstm_b = np.zeros(4*H).astype('f')
self.embed = TimeEmbedding(embed_W)
self.lstm = TimeLSTM(lstm_Wx, lstm_Wh, lstm_b, stateful=False)
self.params = self.embed.params + self.lstm.params
self.grads = self.embed.grads + self.lstm.grads
self.hs = None
def forward(self, xs):
xs = self.embed.forward(xs)
xs = self.lstm.forward(xs)
self.hs = hs
return hs[:,-1,:]
def backward(self, dh):
self.dhs = np.zeros_like(self.hs)
dhs[:,-1,:] = dh
dout = self.lstm.backward(dhs)
dout = self.embed.backward(dout)
return dout
class Decoder:
def __init__(self, vocab_size, wordvec_size, hidden_size):
V, D, H = vocab_size, wordvec_size, hidden_size
rn = np.random.randn
embed_W = (rn(V,D)/100).astype('f')
lstm_Wx = (rn(D, 4*H)/np.sqrt(D)).astype('f')
lstm_Wh = (rn(H, 4*H)/np.sqrt(H)).astpye('f')
lstm_b = np.zeros(4*H).astype('f')
affine_W = (rn(H,V)/np.sqrt(H)).astype('f')
affine_b = np.zeros(V).astype('f')
self.embed = TimeEmbedding(embed_W)
self.lstm = TimeLSTM(lstm_Wx, lstm_Wh, lstm_b, stateful=False)
self.affine = TimeAffine(affine_W, affine_b)
self.params = self.embed.params + self.lstm.params + self.affine.params
self.grads = self.embed.grads + self.lstm.grads + self.affine.grads
def forward(self, xs, h):
self.lstm.set_state(h)
out = self.embed.forward(xs)
out = self.lstm.forward(out)
score = self.affine.forward(out)
return score
def backward(self, score):
dout = self.affine.backward(score)
dout = self.lstm.backward(dout)
dout = self.embed.backward(dout)
dh = self.lstm.dh
return dh
def generate(self, h, start_id, sample_size):
sampled = []
sample_id = start_id
self.lstm.set_state(h)
for _ in range(sample_size):
x = np.array(sample_id).reshape((1,1))
out = self.embed.forward(x)
out = self.lstm.forward(x)
score = self.affine.forward(x)
sample_id = np.argmax(score.flatten())
sampled.append(sample_id)
return sampled
class Seq2Seq(BaseModel):
def __init__(self, vocab_size, wordvec_size, hidden_size):
V, D, H = vocab_size, wordvec_size, hidden_size
self.encoder = Encoder(V,D,H)
self.decoder = Decoder(V,D,H)
self.softmax = TimeSoftmaxWithLoss()
self.params = self.encoder.params + self.decoder.params
self.grads = self.encoder.grads + self.decoder.grads
def forward(self, xs, ts):
decoder_xs, decoder_ts = ts[:, :-1], ts[:,1:]
h = self.encoder.forward(xs)
score = self.decoder.forward(decoder_xs,h)
loss = self.softmax.forward(score, decoder_xs)
return loss
def backward(self, dout=1):
dout = self.softmax.backward(dout)
dh = self.decoder.backward(xs)
dout = self.encoder.backward(dh)
return dout
def generate(self, xs, start_id, sample_size):
h = self.encoder.forward(xs)
sampled = self.decoder.generate(h, start_id, sample_size)
return sampled-
개선 방법

- 반전(Reverse): 입력 데이터의 순서 반전
- Input과 Output의 거리가 가까워져 기울기 전파가 원활해짐
- 단어 사이의 평균 거리는 그대로
- 엿보기(Peeky): Encoder의 출력 를 Decoder의 모든 시각의 모든 계층에 전달
- 가 Decoder에게는 유일한 정보이다.
- 입력되는 벡터가 2개가 되었으므로 concat하여 입력
- 반전(Reverse): 입력 데이터의 순서 반전
class Decoder:
def __init__(self, vocab_size, wordvec_size, hidden_size):
V, D, H = vocab_size, wordvec_size, hidden_size
rn = np.random.randn
embed_W = (rn(V,D)/100).astype('f')
lstm_Wx = (rn(H+D, 4*H)/np.sqrt(D)).astype('f') # 변화
lstm_Wh = (rn(H, 4*H)/np.sqrt(H)).astpye('f')
lstm_b = np.zeros(4*H).astype('f')
affine_W = (rn(H+H,V)/np.sqrt(H)).astype('f') # 변화
affine_b = np.zeros(V).astype('f')
self.embed = TimeEmbedding(embed_W)
self.lstm = TimeLSTM(lstm_Wx, lstm_Wh, lstm_b, stateful=False)
self.affine = TimeAffine(affine_W, affine_b)
self.params = self.embed.params + self.lstm.params + self.affine.params
self.grads = self.embed.grads + self.lstm.grads + self.affine.grads
def forward(self, xs, h):
N, T = xs.shape
N, H = h.shape
self.lstm.set_state(h)
out = self.embed.forward(xs)
hs = np.repeat(h,T, axis=0).reshape(N,T,H) # 변화
out = concatenate((hs,out), axis=2) # 변화
out = self.lstm.forward(out)
out = np.concatenate((hs, out), axis=2) # 변화
score = self.affine.forward(out)
self.cache = H
return score
def backward(self, score):
dout = self.affine.backward(score)
dout = self.lstm.backward(dout)
dout = self.embed.backward(dout)
dh = self.lstm.dh
return dh
def generate(self, h, start_id, sample_size):
sampled = []
sample_id = start_id
self.lstm.set_state(h)
for _ in range(sample_size):
x = np.array(sample_id).reshape((1,1))
out = self.embed.forward(x)
out = self.lstm.forward(x)
score = self.affine.forward(x)
sample_id = np.argmax(score.flatten())
sampled.append(sample_id)
return sampled- 문제점
- Encoder의 출력이 '고정 길이 벡터'이다.
- 입력 문장의 길이에 관계 없이 항상 같은 길이의 벡터 반환
- 필요한 정보 못 담길 가능성 존재
- 어텐션(Attention) 메커니즘 등장
- Encoder의 출력이 '고정 길이 벡터'이다.
어텐션(Attention) 메커니즘

- Encoder 개선
- 입력 문장의 길이에 따라 출력의 길이 변화
- 시각별 LSTM 계층의 은닉상태벡터 모두 이용
- 입력된 단어 수와 같은 차원의 벡터 출력
- 각 시각의 은닉 상태는 직전에 입력된 단어에 대한 정보 많이 포함
- 가장 뒤에 있는 단어가 가장 많은 정보 보유(왼쪽에서 오른쪽으로 처리하기 때문)
- 시각별 LSTM 계층의 은닉상태벡터 모두 이용
- Decoder 개선 ①
- 얼라인먼트(alignment) 고려
- 입력과 출력의 여러 단어 중 어떤 단어끼리 연관 있는가?
- '도착어'와 대응 관계에 있는 '출발어'의 정보를 골라내는 것
- 필요한 정보에만 주목(Attention)
- 어텐션 계층은 Encoder의 출력과 Decoder의 각 시각별 은닉 상태 입력 받음
- 필요한 정보만 Affine 계층으로 넘김
- 이러한 선택과정은 미분이 불가능(역전파 불가)
- '모든 것을 선택한다.'는 아이디어로 미분 가능하도록 처리
- 각 단어의 중요도를 나타내는 '가중치' 별도 계산
- 이러한 선택과정은 미분이 불가능(역전파 불가)
- 가중치 와 각 단어 벡터를 가중합 맥락벡터()
- 필요한 정보만 Affine 계층으로 넘김
- Decoder 개선 ②
- 가중치 : Encoder의 출력과 Decoder의 LSTM 계층의 은닉 상태 벡터 유사도
- 여러 가지 방법 존재
ex) 벡터의 내적 이용(두 벡터가 얼마나 같은 방향을 향하고 있는가?)
- 여러 가지 방법 존재
- 점수()를 소프트맥스 함수를 통해 정규화 하면 가중치()
- Decoder 개선 ③
- Fully Connected Layer 계층의 입력은 LSTM의 은닉상태와 어텐션 정보
concat으로 연결
class WeightSum: # 맥락 벡터 구하는 class
def __init__(self):
self.params, self.grads = [], []
self.cache = None
def forward(self, hs, a):
N, T, H = hs.shape
ar = a.reshape(N,T,1).repeat(H, axis=2)
t = hs*ar
c = np.sum(t, axis=1)
self.cache = (hs, ar)
return c
def backward(self, dc):
hs, ar = self.cache
N, T, H = hs.shape
dt = dc.reshape(N,1,H).repeat(T, axis=1)
dar = dt*hs
dhs = dt*ar
da = np.sum(dar, axis=2)
return dhs, da
class AttentionWeight: # 가중치 구하는 class
def __init__(self):
self.params, self.grads = [], []
self.softmax = Softmax()
self.cache = None
def forward(self, hs, h):
N, T, H = hs.shape
hr = h.reshape(N,1,H).repeat(H, axis=1)
t = hs*hr
s = np.sum(t, axis=2)
a = self.softmax.forward(s)
self.cache = (hs,hr)
return a
def backward(self, da):
hs, hr = self.cache
N, T, H = hs.shape
ds = self.softmax.backward(da)
dt = ds.reshape(N,T,1).repeat(H, axis=2)
dhs = dt*hr
dhr = dt*hs
dh = np.sum(dhr, axis=1)
return dhs, dh
class Attention:
def __init(self):
self.params, self.grads = [], []
self.attention_weight_layer = AttentionWeight()
self.weight_sum_layer = WeightSum()
self.attention_weight = None
def forward(self, hs, h):
a = self.attention_weight_layer.forward(hs, h)
out = self.weight_sum_layer.forward(hs, a)
self.attention_weight = a
return out
def backward(self, dout):
dhs0, da = self.weight_sum_layer.backward(dout)
dhs1, dh = self.attention_weight_layer.backward(da)
dhs = dhs0 + dhs1
return dhs, dh
class TimeAttention:
def __init__(self):
self.params, self.grads = [], []
self.layers = None
self.attention_weights = None
def forward(self, hs_enc, hs_dec):
N,T,H = hs_dec.shape
out = np.empty_like(hs_dec)
self.layers = []
self.attention_weights = []
for t in range(T):
layer = Attention()
out[:, t, :] = layer.forward(hs_enc, hs_dec[:,t,:])
self.layers.append(layer)
self.attention_weights.append(layer.attention_weight)
return out
def backward(self, dout):
N,T,H = dout.shape
dhs_enc = 0
dhs_dec = np.empty_like(dout)
for t in range(T):
layer = self.layers[t]
dhs, dh = layer.backward(dout[:, t, :])
dhs_enc += dhs
dhs_dec[:,t,:] = dh
return dhs_enc, dhs_dec
class AttentionEncoder(Encoder):
def forward(self, xs):
xs = self.embed.forward(xs)
hs = self.lstm.forward(xs)
return hs
def backward(self, dhs):
dout = self.lstm.backward(dhs)
dout = self.embed.backward(dout)
return dout
class AttentionDecoder:
def __init__(self, vocab_size, wordvec_size, hidden_size):
V, D, H = vocab_size, wordvec_size, hidden_size
rn = np.random.randn
embed_W = (rn(V,D)/100).astype('f')
lstm_Wx = (rn(D, 4*H)/np.sqrt(D)).astype('f')
lstm_Wh = (rn(H, 4*H)/np.sqrt(H)).astpye('f')
lstm_b = np.zeros(4*H).astype('f')
affine_W = (rn(H,V)/np.sqrt(H)).astype('f')
affine_b = np.zeros(V).astype('f')
self.embed = TimeEmbedding(embed_W)
self.lstm = TimeLSTM(lstm_Wx, lstm_Wh, lstm_b, stateful=False)
self.attention = TimeAttention()
self.affine = TimeAffine(affine_W, affine_b)
self.params = self.embed.params + self.lstm.params + self.attention.params + self.affine.params
self.grads = self.embed.grads + self.lstm.grads + self.attention.params + self.affine.grads
def forward(self, xs, h):
h = enc_hs[:, -1]
self.lstm.set_state(h)
out = self.embed.forward(xs)
dec_hs = self.lstm.forward(out)
c = self.attention.forward(enc_hs, dec_hs)
out = np.concatenate((c, dec_hs),axis=2)
score = self.affine.forward(out)
return score
def backward(self, dscore):
dout = self.affine.backward(dscore)
N, T, H2 = dout.shape
H = H2 // 2
dc, ddec_hs0 = dout[:,:,:H], dout[:,:,H:]
denc_hs, ddec_hs1 = self.attention.backward(dc)
ddec_hs = ddec_hs0 + ddec_hs1
dout = self.lstm.backward(ddec_hs)
dh = self.lstm.dh
denc_hs[:, -1] += dh
self.embed.backward(dout)
return denc_hs
def generate(self, enc_hs, start_id, sample_size):
sampled = []
sample_id = start_id
h = enc_hs[:, -1]
self.lstm.set_state(h)
for _ in range(sample_size):
x = np.array([sample_id]).reshape((1, 1))
out = self.embed.forward(x)
dec_hs = self.lstm.forward(out)
c = self.attention.forward(enc_hs, dec_hs)
out = np.concatenate((c, dec_hs), axis=2)
score = self.affine.forward(out)
sample_id = np.argmax(score.flatten())
sampled.append(sample_id)
return sampled
class AttentionSeq2seq(Seq2seq):
def __init__(self, vocab_size, wordvec_size, hidden_size):
args = vocab_size, wordvec_size, hidden_size
self.encoder = AttentionEncoder(*args)
self.decoder = AttentionDecoder(*args)
self.softmax = TimeSoftmaxWithLoss()
self.params = self.encoder.params + self.decoder.params
self.grads = self.encoder.grads + self.decoder.grads
def forward(self, xs, ts):
decoder_xs, decoder_ts = ts[:, :-1], ts[:,1:]
h = self.encoder.forward(xs)
score = self.decoder.forward(decoder_xs,h)
loss = self.softmax.forward(score, decoder_xs)
return loss
def backward(self, dout=1):
dout = self.softmax.backward(dout)
dh = self.decoder.backward(xs)
dout = self.encoder.backward(dh)
return dout
def generate(self, xs, start_id, sample_size):
h = self.encoder.forward(xs)
sampled = self.decoder.generate(h, start_id, sample_size)
return sampled
어텐션 메커니즘 개선
- 양방향 RNN
- 기존에 왼쪽에서 오른쪽으로만 학습을 진행해 가장 마지막 은닉상태가 가장 많은 정보 포함하는 문제 해결
- 전체적인 균형을 위해 양방향으로 학습(왼쪽오른쪽, 왼쪽오른쪽)
- 두 LSTM 계층의 은닉상태 연결(concat, 합, 평균 등)
- Attention 계층의 출력 이용 방법 변화
- 위의 예시에서는 Fully-Connected 계층에 맥락벡터를 입력했지만, 다른 곳에도 입력 가능
다음 시각의 LSTM 계층에도 입력 가능
- 심층화
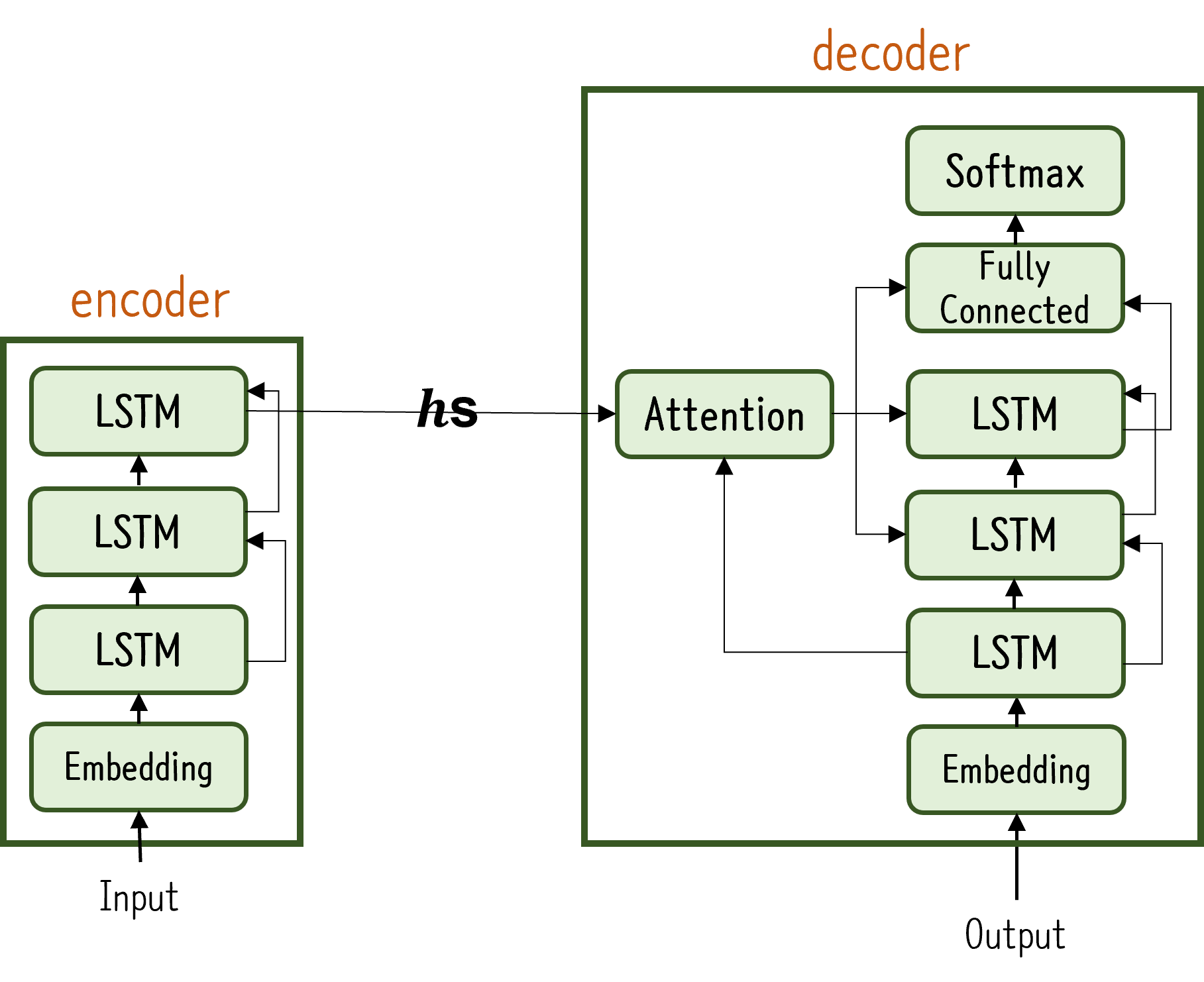
- Encoder와 Decoder에 LSTM 계층 여러 개 이용
- 일반적으로 Encoder와 Decoder의 LSTM 계층 개수 통일
맥락벡터(attention 계층 출력)을 Decoder의 여러 계층에 전파
- Skip Connection
- 계층을 넘어 선으로 연결(층이 깊을 때 효과가 좋음)
- 역전파 시 덧셈은 기울기 그대로 흘려보내기 때문에 파라미터가 증가 x
- RNN의 깊이 방향 기울기 소실 문제에 효과적
어텐션 응용
- 구글 신경망 기계 번역(GNMT; Google Neural Machine Translation)
- Seq2Seq 모델, Attention, LSTM 다층화, skip-connection 이용
- 다수의 GPU로 분산 학습
- Transformer

- RNN의 병렬처리로 인한 병목 현상 해결
- "Attention is All you need"
- RNN 대신 어텐션 사용
- Self-attention
- 하나의 시계열 내에서 각 원소가 다른 원소와 어떻게 관련되는지 파악
- Encoder와 Decoder 입력 동일
참고
밑바닥부터 시작하는 딥러닝2 (사이토 고키)

데이터사이언스를 공부하는 권유진입니다.