
목표
페이징(Paging)을 구현하다보면 다양한 검색필터와 연관관계에 치여 슬로우 쿼리(slow query)가 발생하거나 성능 개선의 니즈를 갖게 된다. 이번 포스트는 성능 개선을 위한 커버링 인덱스를 알아보고 인덱스를 더욱 효율적으로 써보고자 한다.
사전 질문
Q. Offset, Limit로 페이징을 하면 쿼리 속도가 갈수록 느려질 수 있다는데요?
위 질문을 받았을 때, 어떤 답변이 먼저 생각나는가?
- Limit 갯수만큼만 가져오는데 쿼리 성능이 느려질 일이 있나?
- 제대로 인덱스를 못타서 슬로우 쿼리된 거 아냐?
(백엔드 신입 3개월차 때의 나)
인덱스를 탔다 == 조회 성능을 끌어올렸다 라고만 생각했던 것 같다.
커버링 인덱스(Covering Index)
인덱스가 쿼리를 충족시키는데 필요한 모든 데이터를 갖고 있는 인덱스를 말한다. 때문에 컬럼을 읽기 위한 데이터 블럭에 접근할 필요가 없다.
인덱스는 데이터베이스 안에 추가적인 공간(용량)이 필요하다. (대략 테이블 크기의 10% 정도의 공간 필요) 실제 데이터가 저장되어 있는 공간을 데이터 블럭이라고 칭하고, 빠른 조회를 위해 설정한 컬럼만 B+tree 방식으로 따로 저장된 것을 인덱스라 한다.
먼저, Limit 방식의 페이징이 왜 갈수록 느려지는 지 알아보자.
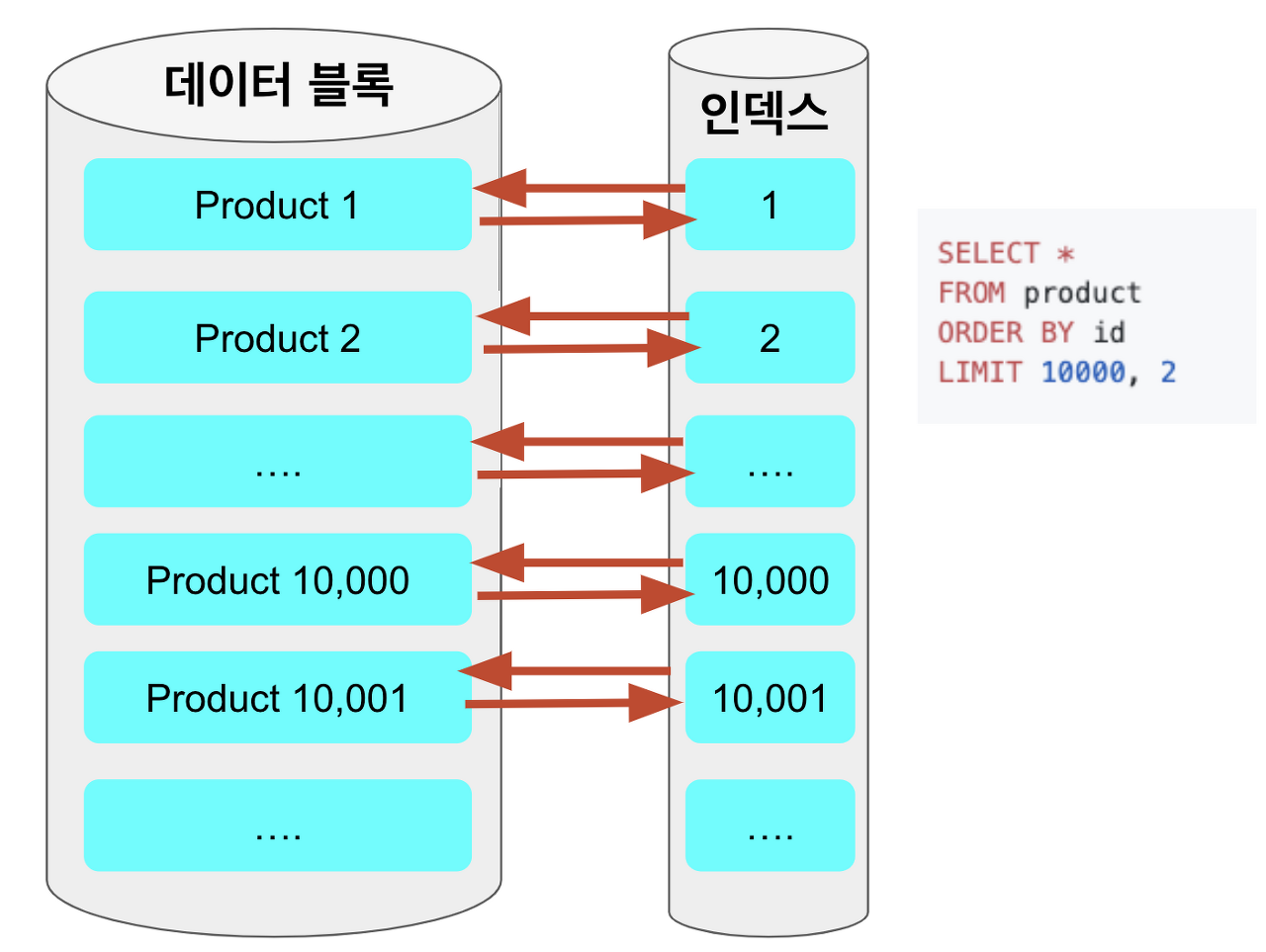
Offset 10000, Limit 2가 걸려있음에도 인덱스에서 10002개의 id 를 가져와 데이터 블럭에 모두 접근하는 것을 볼 수 있다. 페이징 넘버가 증가하면 데이터 블럭에 접근하는 데이터가 훨씬 늘어나게 된다.
그럼 10001, 10002번 데이터만 필요한데 왜 앞단의 무의미한 데이터들도 데이터 블럭에 접근하는 것일까? SELECT 쿼리 실행 순서를 보면 답을 찾을 수 있다.
SQL query execution order
FROM, JOIN -> WHERE -> GROUP BY -> SELECT -> ORDER BY -> LIMIT
SELECT절이 먼저 실행되기 때문에 SELECT *을 위한 컬럼들을 데이터 블럭으로부터 가져오고 LIMIT절이 실행되면서 불필요한 로우들을 제거한다.
즉, Offset, LImit 가 느린 이유는 실제 쿼리에는 필요 없는 데이터가 데이터 블록에 접근하기 때문이다.
커버링 인덱스는 이런 현상을 안정적으로 개선 가능하다.
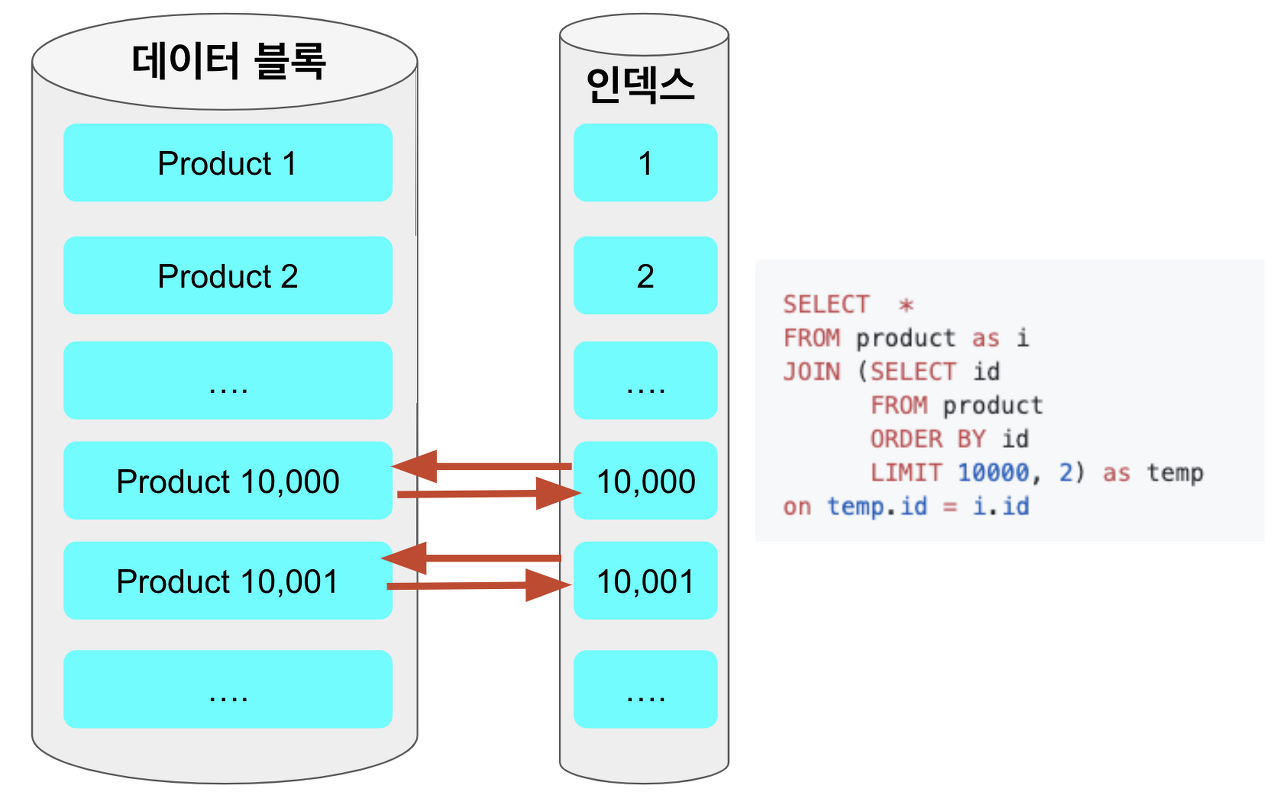
인덱스가 쿼리를 충족시키는데 필요한 모든 데이터를 갖고 있는 인덱스
커버링 인덱스의 정의를 다시 가져왔다. 인덱스가 쿼리를 충족시키는 모든 컬럼을 가지고 있다면 데이터 블럭에 접근하지 않는다.
SELECT id FROM product ORDER BY id LIMIT 10000, 2서브 쿼리를 보면 클러스터드 인덱스가 걸려있는 PK id 컬럼만으로 Offset절, Limit절을 제한하여 데이터 블럭 없이 10001번째, 10002번째 id값을 조회한다.
SELECT *
FROM product as i
JOIN (SELECT id
FROM product
ORDER BY id
LIMIT 10000, 2) as temp
ON temp.id = i=id서브쿼리와 JOIN하여 id = 10001, 10002의 실제 필요한 컬럼들을 조회한다. 결론적으로 데이터 블럭에 접근하는 데이터의 개수를 10002개 -> 2개로 감소시켰다.
************* 1. row *************
id: 1
select_type: SIMPLE
table: usertest
type: index
possible_keys: NULL
key: CHGDATE
key_len: 47
ref: NULL
rows: 9228802
Extra: Using index
1 row in set (0.00 sec)explain 명령어의 extra 필드가 Using Where -> Using Index 로 전환됨으로서 커버링 인덱스가 잘 적용되었는지 확인할 수 있다.
QueryDSL에서 커버링 인덱스 사용하기
QueryDsl에서는 JOIN절에 서브 쿼리를 지원하지 않는다. 하지만 서브 쿼리를 분리함으로서 성능 차이 없이 활용이 가능하다.
SELECT id FROM product ORDER BY id LIMIT 10000, 2 #10001, 10002
SELECT * FROM product WHERE id in (10001, 10002)실제 테스트해보면 하나의 쿼리를 발생시키는 정도의 시간만 추가될 뿐이지 성능 개선은 동일하게 진행된다.
