1. array v.s. linked list
① 결론: 상황에 맞게 선택 및 사용하자
② 비교
- array
- 비유: 특정 개수로 구성된 cell의 집합으로, 하나의 열을 이룸
- 접근성: 좋음. 어느 cell이라도 단번에 접근 가능. 따라서 시간 복잡도는 O(1)로 표현 가능.
- 경직성: 경직됨. 크기 변화 불가. 내부 자료간 자리 이동 시 비효율적임. 처음 설정 시 적합한 크기 조정 중요.
- 어떨 때 사용하면 좋을까? 쉽게 접근 가능하다는 특성을 이용해 자료 저장 후 접근이 잦은 상황에 사용하면 좋을 것 같다. 또한, 변화 가능성이 낮은 자료를 저장하기에 좋을 것 같다. 예를 들면, 지하철 노선의 역명 또는 건물 위치를 저장하면 편리하게 사용이 가능할 것 같다.
- linked list
- 비유: 여러 량(칸)으로 구성된 기차와 같이 칸과 칸이 연결된 배열구조.
- 접근성: 낮음. 처음부터 한칸한칸 차례대로 확인해야함. 보유하고 있는 자료의 수가 N개라면, 시간 복잡도는 O(N)
- 경직성: 유연함. 필요한 곳을 찾아 데이터 삽입 가능.
- 어떨 때 사용하면 좋을까? 데이터의 삭제 또는 수정이 빈번한 상황에 적합한 배열구조다. 예를 들면, 게임 순위를 갱신할 때 또는 접속자 이력을 남길 때 사용하면 편리할 것으로 예상된다.
2. class
① 개념
- 같은 속성과 기능을 가진 객체를 총칭하는 개념
- 종류는 하나 또는 둘 이상의 객체로 구성됨
② 장점
- 속성별로 객체를 구분 가능함
③ 구현 방법
- class 선언 → 객체 속성 규칙 생성(메소드 선언) → 속성을 보유한 객체 생성
class person: # person 이라는 이름의 class 선언
def __init__(self, param_name): # person 함수로 생성되는 사람의 특성을 정의해주는 함수(메소드, method).
print("i am created ", self) # 결과. i am created <__main__.person object at 0yxxxxxxx>
self.name = param_name # person의 속성 설정하기. param_name이 '홍길동'이라면 자기 자신의 이름(self.name)의 결과는 '홍길동'임.
person_1 = person("홍길동") # person class에 객체 하나를 생성함. class 내부 메소드에 선언된 대로 param_name = "홍길동"임.
# person_1의 이름 속성은 "홍길동"임.
print(person_1.name) # person_1의 이름을 현시하라. 결과는 홍길동.
print(person_1) # person_1을 의 이름을 현시하라. 결과는 <__main__.person object at 0yxxxxxxx>.
> ④ 적용
- linked list 이용 시 node 내부의 데이터를 범주화하기 위해 사용
- linked list 이용 시 다른 node의 데이터와 구분하기 위해 사용
3. linked list 구현하기
① 구현 내용
-목표:
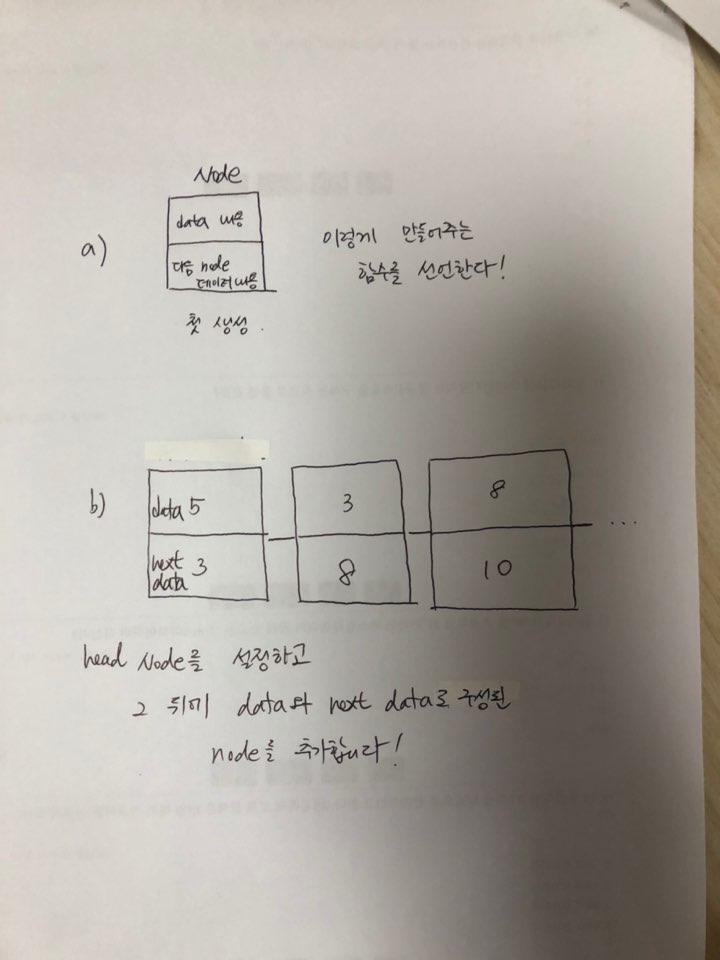
- a) 노드 생성 시 데이터와 다음 데이터 내용을 포함하도록 함수를 선언하기
- b) head node를 생성하고, node를 계속 추가하는 함수 선언하기
-설명:
② 구현하기
a) Node class 선언 → 노드 데이터, 다음 노드 정보 속성 설정하기
b) linkedList class 선언 → 노드 head 만들기 → 노드 추가하기(cur 변수 생성 → head에 cur 위치 → .next에 값이 None일 때까지 cur 위치 변경(while) → 마지막 위치에 도착 시 입력값(value) 만들기)
# a) 노드를 생성하는 함수
class Node:
# 노드 생성 시 필요한 데이터는, 데이터 값과 다음 노드의 데이터 값 2가지다.
def __init__(self, data):
# 노드의 데이터 값
self.data = data # ex) Node(5)의 의미는 data에 5를 대입한다는 것이며, 이는 곧 자신의 데이터 깂이 5가 된다는 의미다.
# 다음 노드의 데이터 값
self.next = None # 다음 노드 값은 None 이다.
# b) 노드를 연결 및 추가하는 함수
class linkedList:
# head 노드를 만드는 함수
def __init__(self, value): # ex) linkedList(5)의 의미는 value에 5를 대입한다는 것이며, 이는 곧 노드 생성 함수 data 값에 5가 대입되며
self.head = Node(value) # ex) 노드 생성 함수를 이용해 노드를 생성(다음 노드 포함)한뒤 head에 할당
# 노드를 추가하는 함수
def append(self, value):
cur = self.head # head 노드에 cur(current의 줄임)가 위치함
while cur.next is not None: # cur가 위치한 노드의 다음 노드 정보가 None이 아니라면
cur = cur.next # cur의 다음 노드 정보를 가진 노드로 cur를 이동시키기
cur.next = Node(value) # 맨 마지막에 append해주는 코드
# 모든 노드를 현시하는 함수
def print_all(self):
cur = self.head # head 노드에 cur(current의 줄임)가 위치함
while cur.next is not None: # cur가 위치한 노드의 다음 노드 정보가 None이 아니라면
print(cur.data) # cur의 현재 데이터를 현시하기
cur = cur.next # cur의 다음 노드 정보를 가진 노드로 cur를 이동시키기4. 생각
① linked list 시작 지점
- 반드시 시작 지점이 head 부분이어야 하는 것인가? 특정 data를 가진 부분부터 시작하면 안되는 것인가?
- 만약 list의 길이가 10^10이라면 마지막까지 도달하는데 많은 시간이 소비될 것이다.
- 이럴 때 각 노드 속성에 규칙을 부여(예, 각 노드에 순서 속성을 부여)하고 (10^10)-1 번째 node를 찾으면 더 빠르게 마지막 노드를 찾을 수 있지 않을까?
② 데이터 구조 배열의 결론(예상)
- class를 사용하여 속성별 객체를 범주화하고, class 내부에 2개 이상의 객체를 생성할 수 있다.
- 이러한 class와 객체가 많아지면 어느 순간부터 나무 뿌리와 같은 형상이 될 것 같다.
- 하지만 깊이가 깊지는 않을 것이다. 깊이를 깊게 만들기 위해서는 하위 class가 필요하다. 만약 깊이가 10인 데이터 구조는 하위 class가 9번 사용되었다는 것을 의미한다.
- 객체는 최하위 클래스(10번째 class)에 존재할 것이다.
- 그 이후에는 또 하나의 질문이 생긴다. class에 몇 개의 객체가 있는 것이 적정한가? 답변에 따라 class의 깊이가 달라질 수 있다. 또한, 적정한 깊이의 class가 존재한다면 이에 따라 class에 포함된 객체의 개수가 달라질 것이다.

몰입하는자