[A comprehensive review of object detection with deep learning 정리 자료]
본 포스팅은 객체탐지 (Object Detection)에 대한 서베이 논문인 A comprehensive review of object detection with deep learning를 제 나름대로 정리한 글입니다.
1. Convention Method
해당 논문은 딥러닝 기반 객체 탐지에 집중하기 때문에 기존 방법론 (conventional methods)들은 아래와 같이 문제점 및 한계들만 간단히 설명하고 있습니다.
딥러닝을 사용하지 않는 기존 방법론들은 일반적으로 다음과 같이 3단계의 과정으로 수행됩니다.
-
Selection of region
객체가 있을만한 영역(region)들을 식별하는 과정입니다. -
Extraction of Features
나뉘어진 영역을 기준으로 피처 (feature)들을 추출합니다. HOG, SIFT 등 다양한 방법론들이 사용됩니다. -
추출된 피처를 바탕으로 SVM, Adaboost와 같은 분류기 (classifier)를 사용하여 특정 객체의 영역을 식별합니다.
위와 같은 과정으로 이루어지는 기존 방법론들은 '과도한 계산에 따른 처리시간 증가', '빛 번짐에 의한 피처들의 오염'등 몇가지 문제점을 가지고 있습니다.
2. Object detection frameworks
객체 탐지는 객체 위치 탐지 (object location, objecet localization)과 객체 분류 (object calssification)의 두 가지 문제가 결합된 작업입니다. 이에 따라 모델들은 다음과 같이 두 가지로 분류됩니다.
2.1 Two-stage object detectors: region based
Two-stage object detection는 객체 위치 탐지 (object localization)와 객체 분류의 두 단계로 수행됩니다. 객체 위치 탐지는 객체가 있을만한 지역들을 제안하는 'region proposal'을 포함하며 객체 분류는 객체를 특정 카테고리로 분류하는 과정입니다.
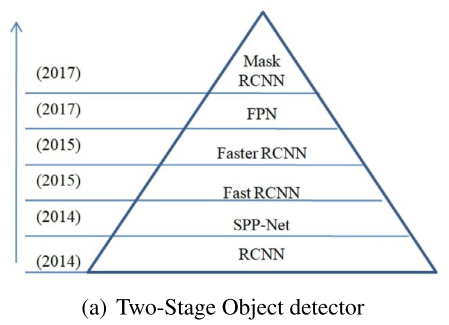
이러한 방법론들은 지역 기반 방법론 (Region-based framework)이라고도 불리며 비교적 정확성이 높다는 장점을, 많은 시간이 소요된다는 단점을 가집니다. 또한 해당 모델들은 다음 그림과 같이 요약될 수 있습니다.
2.1.1. RCNN (Region based Convolutional Neural Network, 2014)
RCNN은 객체 탐지의 초창기 대표적인 모델이며 프레임워크는 다음 그림과 같이 4단계로 설명될 수 있습니다.
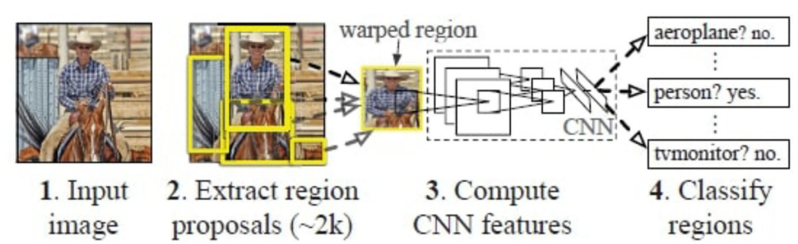
-
1. 영역 제안 (Region Proposal) - Selective search를 활용해 객체 영역을 감지 및 제안합니다. Selective search는 이미지내 반복적인 군집화를 통해 같은 객체의 영역을 탐지하는 알고리즘을 의미합니다. 또한 제안된 영역들은 ROI (Region of Interest)라고 합니다.
-
2. 피처 추출 (Feature Extraction) - 전통적인 CNN의 입력 이미지 크기는 고정되어 있습니다. 따라서 이를위해 이미지의 크기를 일정하게 조정 (rescaling)한 후 CNN에 투입하여 피처를 추출합니다.
-
3. 분류 - SVM과 같은 분류기를 사용하여 객체들을 특정 카테고리로 분류합니다.
-
4. 객체 탐지 - 선형 회귀 (Linear Regression)를 사용하여 이미지내의 바운딩 박스 (bounding box)를 생성합니다.
2.1.2. SPP-Net (Spatial Pyramid Pooling in Deep Convolutional Networks)
RCNN은 전통적인 CNN을 사용하기 때문에 제안된 영역 (객체) 들의 크기를 일정하게 조정할 필요가 있습니다. 이러한 이미지 조정간에 이미지 왜곡 (distortion), 정보 손실등의 품질 저하가 발생할 수 있습니다.
SPP-Net은 이렇듯 이미지 크기를 고정함으로써 생기는 문제들을 SPP layer (Spatial Pyramid Pooling Network layer)를 도입함으로써 해결했습니다. SPP layer는 다음 그림과 같이 CNN의 가장 마지막 층에 위치하며 크기와 관계없이 일정한 길이의 피처 (Fixed-length representation)를 추출하는 역할을 수행합니다.
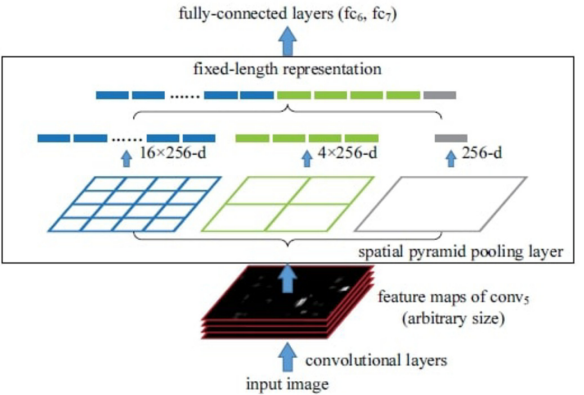
이를 위해 SPP layer는 window size 및 stride를 조정하여 이미지를 16개의 영역, 4개의 역역, 1개의 영역에서 풀링을 진행합니다. 즉, 이미지의 크기에 관계없이 (16+4+1)*C(채널 수)가 됩니다.
SPP-Net은 이러한 특성으로 인해 이미지내의 객체들을 잘라 매번 CNN에 투입할 필요 없이 이미지 자체의 피쳐맵에서 감지된 객체들의 피쳐맵을 SPP-layer를 통해 처리함으로 R-CNN보다 더 빠릅니다.
2.1.3 Fast RCNN
SPPNet의 등장으로 RCNN보다는 빠르고 효과적인 학습이 가능해졌지만 여전히 미세조정 (fine-tuning, 일반적으로 좋은 피처를 뽑기 위대 다른 이미지 분류와 같은 과제들을 먼저 수행 후, 객체 탐지 학습을 시키는 것 같습니다.), 바운딩 박스 예측 (SVM 또는 MLP를 통한), 피처 추출 (ROI를 CNN 혹은 SPP-layer에 투입 시키는 것) 등을 포함합니다.
Fast RCNN은 이러한 비효율적인 절차를 개선한 end-to-end의 프레임워크 입니다. 이를위해 객체 분류기, bounding box regression 모델을 합쳐 하나의 손실함수 (multitask-loss)을 통해 end-to-end로 과제를 학습합니다. 또한, 다양한 크기의 이미지들을 처리할 수 있도록 이미지를 정해진 크기의 구역으로 나누고 max pooling을 적용하는 ROI max pooling을 도입하였습니다. 즉, 매번 분류기와 바운딩 박스 회귀 모델을 따로 학습하지 않고 다른 크기의 ROI들을 CNN 혹은 SPP-layer에 투입시키는 과정이 생략됩니다. 이러한 방법은 속도 측면에서는 물론이고 정확도 측면에서도 좋은 성능을 보였습니다.
2.1.4. Faster RCNN
Fast RCNN은 end-to-end 객체 탐지 모델의 학습을 가능케 했지만 여전히 selective search를 사용한다는 점에서 필연적인 비효율성을 포함하고 있습니다. Faster RCNN은 Region Proposal Network (RPN)을 도입하여 영역 제한 또한 네트워크를 통해 학습합니다.
RPN은 아래 사진과 같이 sliding window를 사용하여 중심점(anchor)을 기준으로 각기 다른 크기 (미리 정해진) 의 ROI를 추출한 뒤, Fast RCNN처럼 객체 분류기, 객체의 존재유무를 학습하는 네트워크를 한번에 학습합니다. 이러한 방식은 selective search대신 객체 존재 유무를 확인하는 네트워크를 사용하지 않음으로써 속도와 성능 측면에서 이점을 갖습니다.
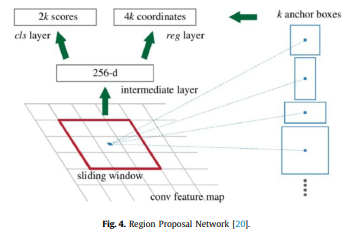
2.1.5. Feature pyramid network
FPN (Feature Pyramid Network)는 계층적 구조를 (hierarchical) 채택하여 다양한 스케일 (mulit-scale)의 resolution을 사용합니다. 이러한 방식은 low-level과 high-level의 피처를 모두 사용함으로써 다양한 과제에서 좋은 성능을 보여줍니다. 구조는 아래 그림과 같습니다.
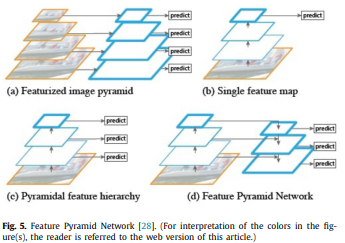
FPN은 down-sampling하여 high-level에서 low-level의 피처맵을 얻는 bottom-up pathway와 high-level에서 up-sampling을 통해 높은 resolution의 피쳐맵을 얻어내는 top-down pathway로 구성되어 있습니다. top-down pathway에서는 lateral connection을 이용해 bottom-up pathway된 low-level에 피처맵 또한 사용함으로써 여러 해상도를 고려한 피처맵을 추출할 수 있습니다. 또한 이 과정의 비용이 적다고 의미하는데 ... 저는 모르겠습니다.
이렇듯 다양한 해상도의 피쳐맵을 사용하는 덕에 원본 이미지 크기의 피쳐맵이 필요한 segmentation이나 instance 분류 과제 또한 수행할 수 있습니다.
2.1.6. Mask RCNN
Mask RCNN은 faster RCNN을 활용하여 object detection과 semantic segmentation이 결합된 instance segmentation을 수행하기 위해 고안되었습니다. Instance segmentation은 아래 그림과 같이 sementic segmentation에서 나아각 instance(객체) 까지도 구별하는 과제를 의미합니다.
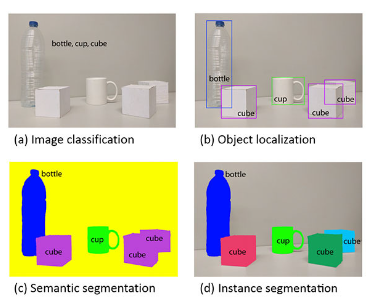
이를 위해 객체의 종류 (classfication loss), 존재 유무 (바운딩 박스를 예측하는 손실값) 외에도 segmentation을 위한 손실값 또한 목적 함수(objective function)에 포함시켜 학습합니다. 또한 기존에 ROI를 일정한 크기를 갖는 피처맵으로 추출하기 위해 사용했던 ROI max pooling을 대체하는 ROIAlign layer를 제안합니다. 이는 투입 이미지와 추출된 피처맵의 크기가 다를 때 ROI pooling을 적용함으로써 일부 이미지 정보의 손실이 있기 때문입니다만 본 포스팅에서 깊게 다루지는 않도록 하겠습니다.
2.1.7 Two-stage object detection 정리
Two-stage object detection은 크게 객체의 존재를 감지하는 혹은 위치를 예측하는 object location과 직접적인 객체 분류를 위한 object detection의 단계로 나뉘어 질 수 있습니다. 세부적으로는 아래와 같이 4가지 단계로 나뉘어 질 수 있습니다.
- Object location
1. 영역 제안 (region proposal) - Object detection
2. 피처 추출 (feature extraction)
3. 객체 분류 (object detection)
4. 객체 탐지 (object detection) or 바운딩 박스 그리기
초창기 모델인 RCNN은 'selective search', 'CNN에 ROI 투입하여 피처 추출', '객체 분류 (classification loss)', 'SVM을 통한 바운딩 박스 예측'과 같이 위와 같은 전 과정을 진행했어야 합니다.
이후 제안된 SPP-Net은 매번 모든 ROI가 아닌 하나의 이미지에서 피처맵을 추출한 뒤 제안된 영역으로 자르고 SPP-layer에서 각기 다른 이미지를 처리하게끔 함으로써 2번에서 소비되던 시간을 크게 줄였습니다.
Fast RCNN은 객체 분류를 위한 손실 함수와 바운딩 박스 예측을 위한 손실함수를 하나로 합침으로써 1번을 제외한 모든 과정을 end-to-end로 학습하게끔 하했습니다.
그러나 역시 selective search에서 소요되는 시간이 많았기에 Faster RCNN은 RPN을 도입하여 이 또한 딥러닝 모델으로 대체 했습니다.
FPN은 계층적 구조를 채택함으로써 다양한 해상도의 피쳐맵을 사용해 성능적인 이점을 가져갔습니다.
마지막으로 Mask RCNN은 새로운 손실 함수를 도입함으로써 instance segmentation을 수행해냈습니다. 논문에서도 각 방법론들에 따른 특징들을 표로 정리했으나 너무 커서 본 포스팅에서는 제외했습니다.
2.2. One-stage object detectors: regression/classification based
One-stage object detector들은 object localization과 object classification을 함께 학습 또는 수행합니다. 따라서 region proposal free framework라고도 불리며 대표적인 모델들은 다음 그림과 같습니다.
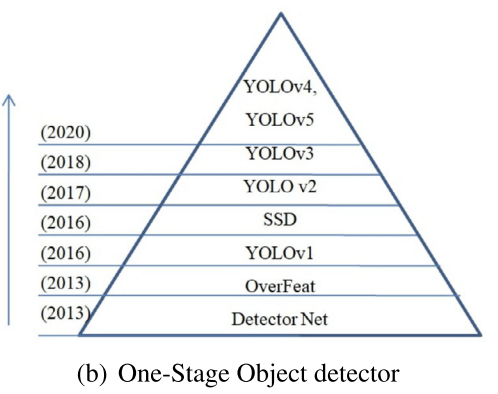
2.2.1. DetectorNet
One-stage method들의 초창기 방법인 만큼 매우 간단합니다. 아래 그림과 같이 이미지를 여러 coarse grid로 나눈 뒤, 회귀를 통해 객체의 존재 유무(마스킹 된 grid에서만 객체가 존재)를 탐지하는 것 입니다.
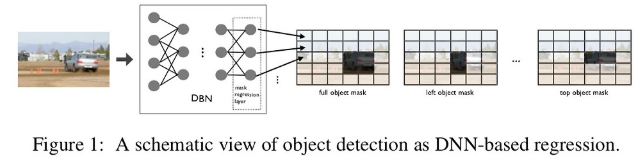
매우 나이브한 방법인 만큼 여러 종류의 객체를 탐지하기 위해서는 각기 다른 신경망을 통해 학습해야 하기 때문에 많은 시간이 소요되고 같은 그리드 내에 유사한(? 같아야지 아예 탐지 못하는 것 아닌가 ...) 객체가 있을 경우 탐지하지 못한다는 단점이 있습니다.
2.2.2. OverFeat
OverFeat는 CNN을 활용해 one-stage로 객체 탐지 및 객체 분류 등을 수행했다는 점에서 의미가 있습니다. OverFeat는 컨볼루션 레이어만 활용하여 마지막 필터맵을 얻은 뒤, 위상적인 정보를 활용하여 각 픽셀의 receptive field 추출 및 객체 탐지, 분류를 수행합니다. 이때 다양한 scale의 이미지를 활용함으로써 최종 객체 영역 및 다양한 크기의 객체를 탐지합니다. 또한 이러한 과정을 한번의 순전파로 수행하기 때문에 one-stage의 학습 및 추론이 가능합니다.
이미지 넷(ImageNet)에서 좋은 성능을 거뒀지만 실질적인 성능은 한달 일찍나온 R-CNN이 더 좋았다고 합니다. 그럼에도 불구하고 one-stage의 방법론으로 인해 Yolo와 같은 모델에 영향을 주었기 때문에 중요한 모델중 하나입니다.
2.2.3. YOLO (You Only Look Once)
YOLO는 Overfeat와 마찬가지로 이미지를 그리도 단위로 나눈 후 객체의 존재 여부를 예측합니다. 하지만 피쳐맵을 추출하는 과정에서 슬라이딩 윈도우를 사용하지 않으며 바운딩 박스의 정보도 (x, y, w, h) regression으로 예측한다는 점이 차이점입니다.
이러한 구조 때문에 완전한 one-pass로 추론이 가능하여 성능에 더불어 매우 빠르게 작동합니다.
2.2.4. SSD
SSD는 Faster-RCNN 처럼 사전 정의된 앵커를 사용하면서도 YOLO와 같이 바운딩 박스 크기를 함께 예측합니다. 앵커를 사용함으로써 아래 구조에서 볼 수 있다시피 다양한 스케일의 피쳐맵을 사용할 수 있습니다. 또한 네거티브 샘플링 기법을 사용함으로써 성능을 높혔습니다.
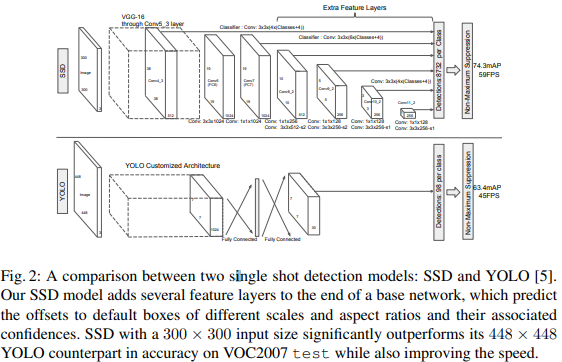
2.2.5 ~ 2.2.6. YOLOv2, v3
얘네들은 딱히 설명드릴 것이 없는게 YOLOv1와 구조가 크게 차이나는 것이 아닌 배치 정규화, 앵커 박스의 활용, 다양한 스케일의 피쳐 사용 등 트레이닝 기법을 통해 성능을 높힌 모델들이기 때문입니다.