저는 주연구분야는 GNN에서도 XAI이지만 최근 LLM 분야에 관심이 생겨서 공부하고 있습니다. 근데 주먹구구식으로 논문 읽고 정리, 읽고 정리 하다보니까 머리속에 남지가 않더군요...
따라서! 저 나름대로 연도별로 모델들을 조금 정리해보려고 합니다. 정리해볼 논문들은 다음과 같습니다. (이것도 ChatGPT가 정리해줌 ... ㅋㅋ)
2018년
- 6월: GPT-1 (OpenAI)
2019년
2020년
2021년
- 1월: DALL-E (OpenAI)
- 4월: CLIP (OpenAI)
- 6월: Codex (OpenAI)
- 10월: Gopher (DeepMind)
- 11월: MT-NLG (Microsoft & NVIDIA)
2022년
- 4월: GPT-3.5 (OpenAI)
- 7월: BLOOM (BigScience)
- 11월: ChatGPT (OpenAI)
2023년
- 3월: GPT-4 (OpenAI)
- 6월: LLaMA (Meta)
- 11월: Claude 2 (Anthropic)
2024년
- 2월: GLaM (Google)
- 2월: SOLAR (Meta)
- 5월: PaLM 2 (Google)
1. GPT-1
- 발표기업: OpenAI
- 등장연도: 2018년 6월
- 파라미터 수: 117M
- 사전학습 데이터 셋: BookCorpus dataset (단어 수: 약 800M, GPT-1에서 기술된 단어수랑 다른데 ...?), Wikipedia(2500M)
- 토크나이져: BPE (Byte-Pari Encoding)
2017년 6월에 Transformer가 발표되고나서 1년만에 LLM의 시초격인 GPT-1이 등장하였습니다. GPT-1은 언어모델들이 사용하고 있는 text data는 학습을 위해 annotation (인간의 labeling)이 필요하며 이는 다양하고 많은 text data의 학습을 저해하는 요소입니다.
따라서 GPT-1은 language modeling (Next token prediction, Causal Language Modeling(CLM))을 통한 Unsupervised pre-training 방법과 task에 specific한 supervised fine-tuning 기법을 사용합니다. 이러한 학습 방법은 pre-training (사전학습)을 통해 대용량의 언어데이터에서 지식을 습득하고 pre-training (미세조정)을 통해 task를 수행하는 능력을 얻어서 작동하는 현재까지의 LLM에 많은 영향을 끼치게 됩니다.
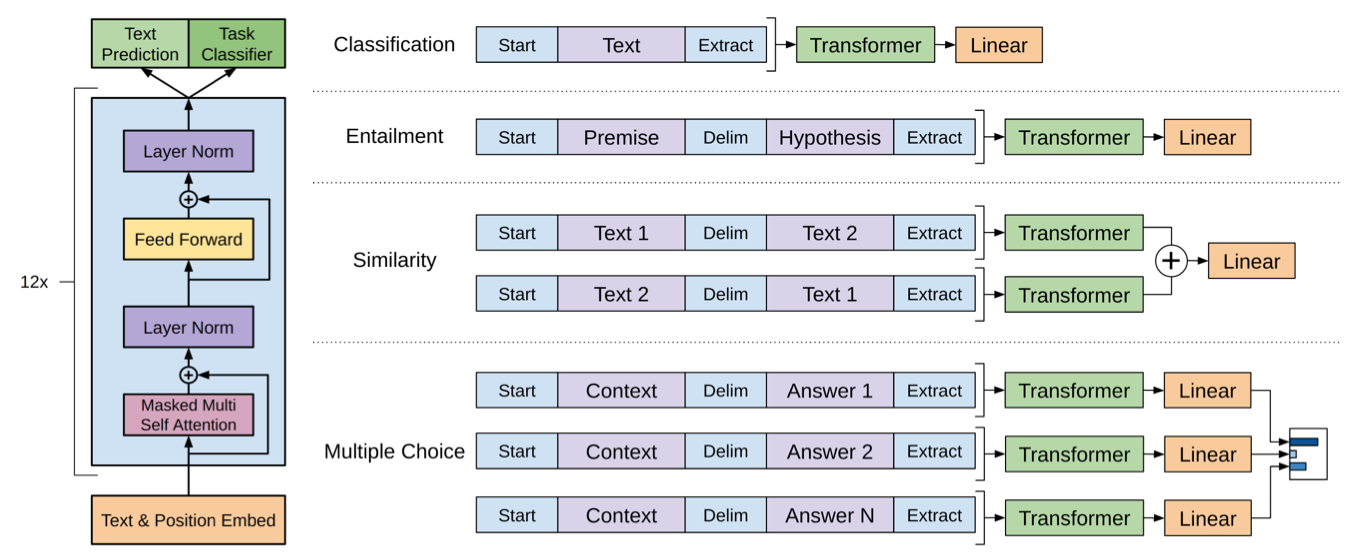
모델의 구조는 다음과 같이 generation을 위한 transformer의 decoder의 구조와 거히 유사한 형태를 띄고 있습니다. 또한 그림을 통해 다양한 task를 수행하기 위해 추출된 sentence 혹은 token 임베딩을 어떻게 활용하는지도 알 수 있습니다.
또한 아래와 같이 거의 최초로 사전학습의 효용성을 검증하기 위하여 미세조정시 전이되는 파라미터의 수에 따른 모델의 성능(왼쪽), 사전학습시 업데이트 되는 파라미터 수에 따른 모델의 성능(오른쪽)에 대한 ablation study를 진행했씁니다.
2. GPT-2
- 발표기업: OpenAI
- 등장연도: 2019년 2월
- 파라미터 수: 1.5B
- 사전학습 데이터 셋: WebText dataset(8만개의 document, 40GB)
- 토크나이져: BPE (Byte-Pari Encoding)
GPT-2는 GPT-1과 동일한 구조에 파라미터수만 약 13배 정도 늘어만 모델입니다. 또한 GPT-2는 GPT-1보다 늘어난 파라미터와 많은 수의 데이터를 통해 generalization model에 집중하고 있습니다. 즉, 미세조정이 말고 사전학습을 통한 zero-shot setting에서 LLM의 성능을 검증하는데 초점을 맞추고 있습니다.
또한 파라미터수 증가외에도 reddit 크롤링 데이터인 WebText 데이터를 통해서도 generalization을 높히려고 하였습니다. 이는 일종의 너무 정제된 데이터 (책, 사전)에서가 아닌 일반적인 대화 속에서 다양한 분야의 데이터를 수집하여 학습하기 위함이라고 생각합니다.
토크나이저단에서도 일반적인 BPE가 아닌 언어를 byte로 변환하여 BPE를 적용함으로써 corpus내에 존재하지 않는 단어 또한 다룰 수 있도록 했다고 하는데 이에대해서는 저도 잘 이해가 안됩니다.
특히나 zero-shot setting에서 잘 작동하는 LLM들의 시초격인 모델인 만큼 실험 설계가 상당히 잘 되어 있는데 분량상 다루지는 않겠습니다. 쨋건 해당 논문, 모델은 fine-tuning 없이도 작동할 수 있는 generalization LLM에 대한 가능성을 제시했다는 점에서 큰 의미가 있습니다.
3. BERT
- 발표기업: OpenAI
- 등장연도: 2019년 11월
- 파라미터 수: BERT(base)-110M, BERT(larget)-340M
- 사전학습 데이터 셋: BooksCorpus dataset(8만개의 document, 40GB)
- 토크나이져: WordPiece
BERT는 꽤 오랬동안 다양한 task에서 sota에 올라있었고 논문에 GPT-1, GPT-2에 비해서 모델의 구조를 좀 더 상세히 다루고 있어 한번쯤은 읽어보시기를 권장합니다. BERT는 기존 LLM들이 transformer의 decoder와 같은 구조를 갖기에 한쪽 방향으로만 (left-to-right) 임베딩이 진행되어 sentence, token 단위의 task에 한계가 존재한다고 주장합니다. 따라서 양방향 (bidirectional)에서 문장, 토큰단위의 임베딩등을 가능케하는 BERT를 제안합니다.
구조는 아래와 같이 transformer의 encoder와 거히 동일한 구조이며 기존 LLM의 학습방법과 유사하게 사전학습과 미세조정으로 학습됩니다.
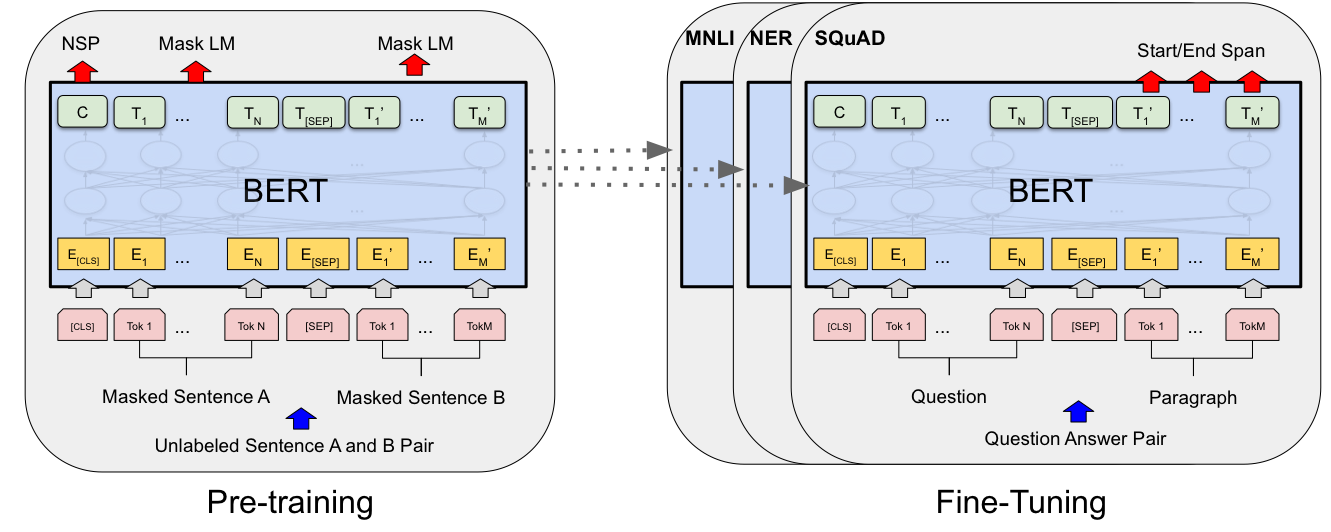
사전 학습은 총 2가지 Masked Language Modeling(MLM)과 Next Sentence Prediction (NSP)로 진행됩니다. 양방향으로 보는만큼 generation task를 수행하는 만큼 CLM을 적용하기는 힘들었는 듯 합니다. 또한 후에 RoBERTa 논문에서는 NSP의 효용성에 대해 의구심을 표현하기도 했습니다.
BERT는 양방향 LLM인 만큼 context 이해가 필요한 다양한 task들에서 높은 성능을 보여주었습니다.
4. T5
- 발표기업: Google
- 등장연도: 2020년 5월
- 파라미터 수: T5(small)-60M, T5(Base)-220M, T5(Large)-770M, T5(3B)-3B, T5(11B)-11B
- 사전학습 데이터 셋: Colossal Clean Crawled Corpus (C4)-745GB
- 토크나이져: SentencePiece (기존의 unigram, wordpiece, BPE와 갖은 토크나이징 방식을 각 언어에 맞게 generalization한 것.)
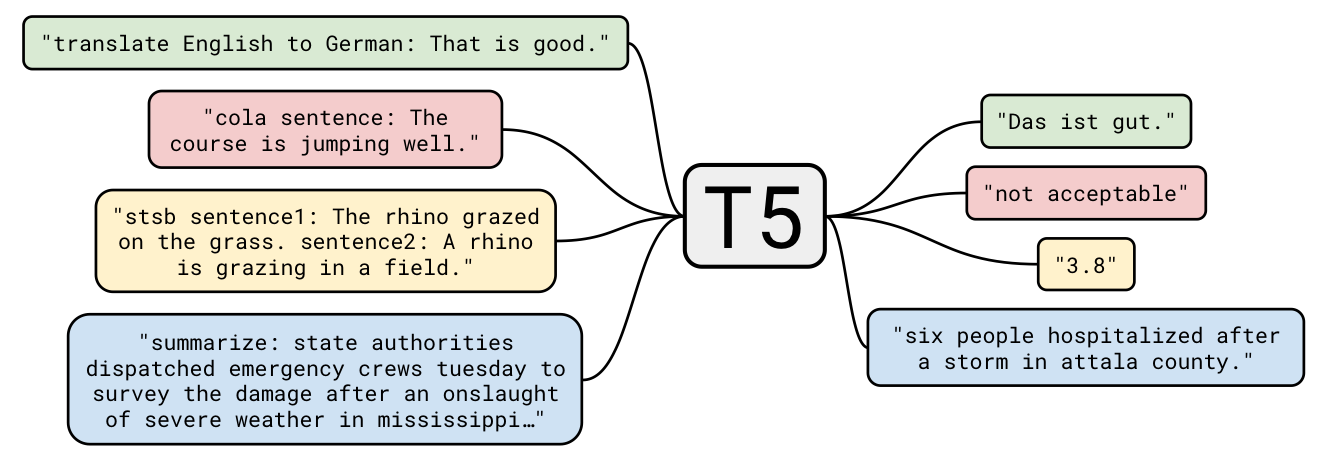
LLM이 다양한 NLP task에서 높은 성능을 내고 있지만 여전히 모델의 파라미터수나 데이터셋을 늘리는 데에만 집중하고 있습니다. 따라서 본 논문은 scale-up된 LLM들과 상당히 큰 데이터 셋등 다양한 조건에서 LLM들을 비교, 실험하는데 집중하고 있습니다. 이를위해서는 task, model에 따른 학습방법이 일정해야 하기 때문에 고안된 방법이 text-to-text를 활용하는 것입니다. text-to-text는 아래 그림과 같이 모든 NLP task를 generation task로 하여 학습하는 것을 의미합니다.
또한 이러한 실험들을 통해 당시 가장 좋은 성능을 갖던 제안 모델이 바로 Text-to-Text Transfer Transformer (T5)입니다. T5의 구조는 아래 그림과 같이 layer normalization의 위치, positional encoding을 절대적 위치에 따른 것에서 상대적 (key-query에 거리에 따른)인 것으로 교체한 것을 제외하고는 기존의 transformer와 동일합니다. 즉, encoder-decoder 구조를 갖고 있습니다.
또한 사전 학습은 CLM보다는 MLM과 유사한 방식으로 진행됩니다. 아래 그림과 같이 input text에서 몇몇 단어 혹은 일부가 sentinel token으로 교체된 후, decoder에서 각 sentinel token을 맞추고 final sentinel token (Z, 종료 토큰)으로 마무리 하는 것입니다.

T5 model은 encoder-decoder로 이루어진 만큼 꽤나 좋은 성능을 보여줍니다. 또한 모델 설명은 간단하지만 논문에서 다양한 사전학습 objectives, fine-tuning, 데이터셋의 크기, 모델 크기에 따른 성능에 대한 실험들이 꽤 많은 만큼 읽어보시면 좋으실 것 같습니다.
이 논문 너무 기네요 ...
3. GPT-3
- 발표기업: OpenAI
- 등장연도: 2020년 6월
- 파라미터 수: 175B
- 사전학습 데이터 셋: Common Crawl (filtered)-570GB, WebText2, Books1,Books2, Wikipedia
- 토크나이져: BPE (Byte-Pari Encoding)
GPT-3는 상당히 이전 LLM들과는 약 10배정도 되는 파라미터 수를 가진 모델입니다. 또한 GPT-2와 마찬가지로 미세조정의 단점을 강조하며 in-context learning을 통해 몇개의 예시(K-shot or zero-shot learning)를 보여주는 방식으로 성능에 어떠한 영향을 끼칠 수 있는지 실험하였습니다. 꽤 좋은 성능을 가졌음에도 몇몇의 task에서는 여전히 sota model에 밀리는 모습을 보여주지만 few-shot learning을 통한 성능의 향상을 검증하고 오직 사전학습을 통해서만으로도 충분한 LLM의 성능을 이끌어 낼 수 있다는 점에서 의미를 지닙니다.
계속 없데이트중 ..