playdata data engineering
Oracle VM install
1 새로 만들기
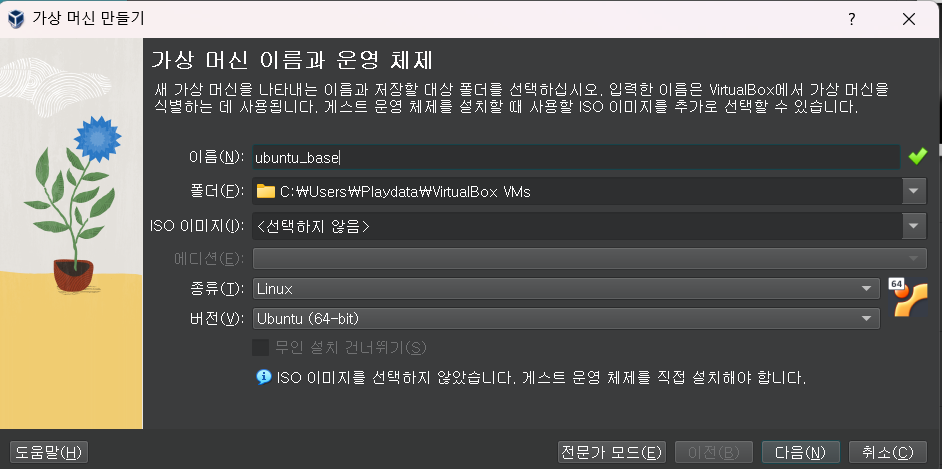
2 가상 머신 이름과 운영 체제
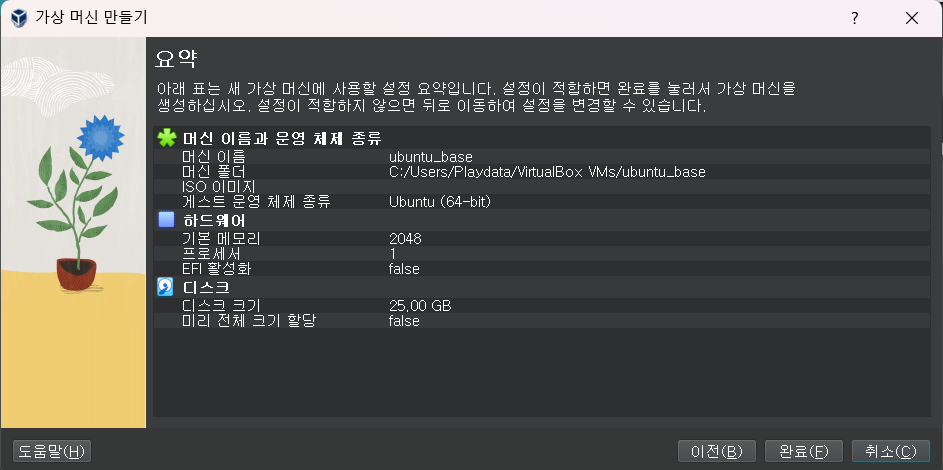
이름: ubuntu_base
ISO이미지적용
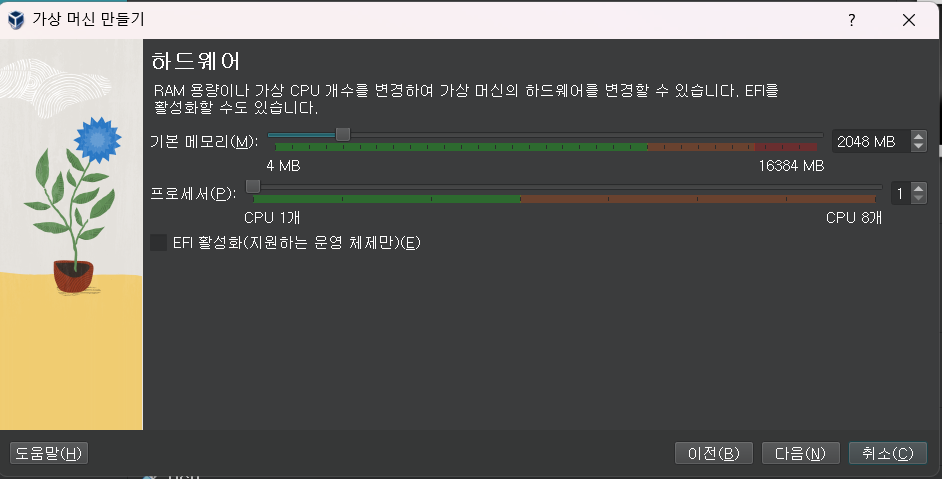
3 하드웨어
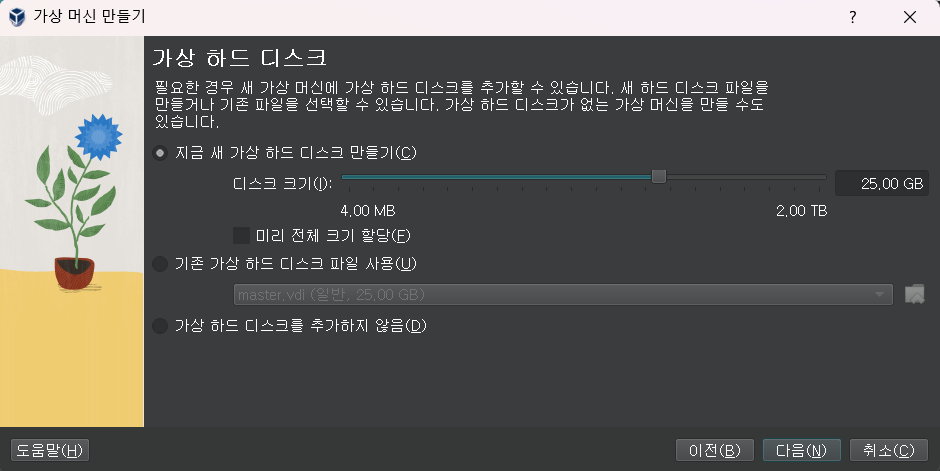
4 가상 하드 디스크
5 생성 완료
6 시작하기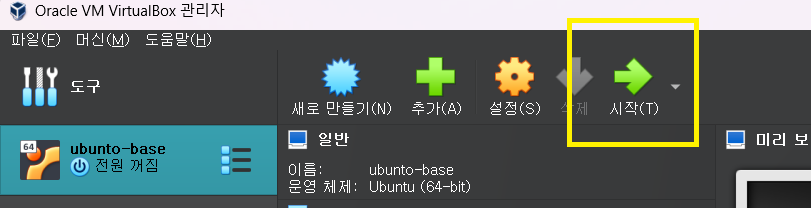
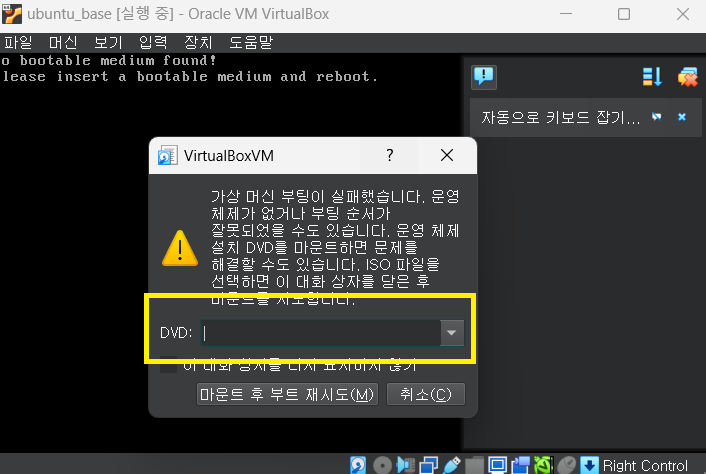
- 다운받은 ISO파일을 선택합니다.
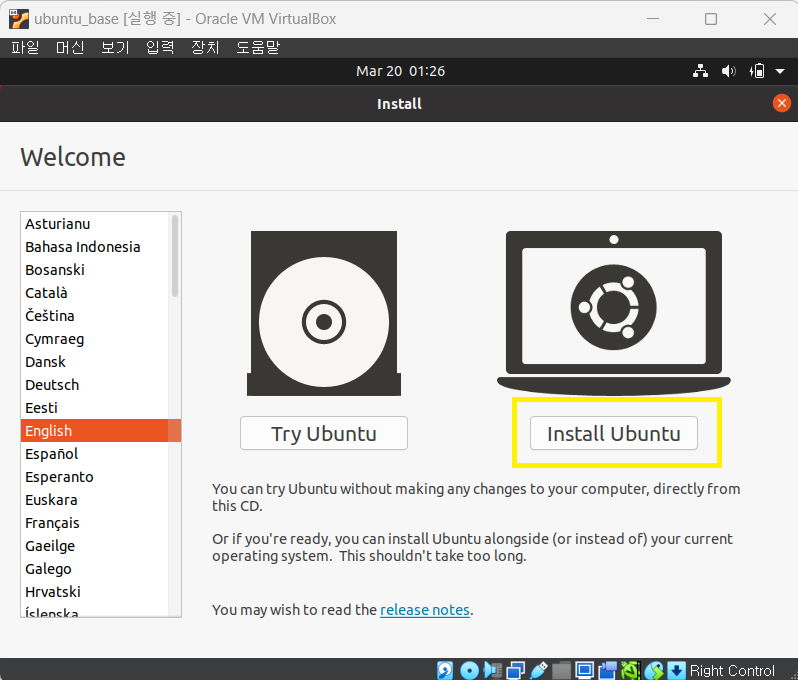
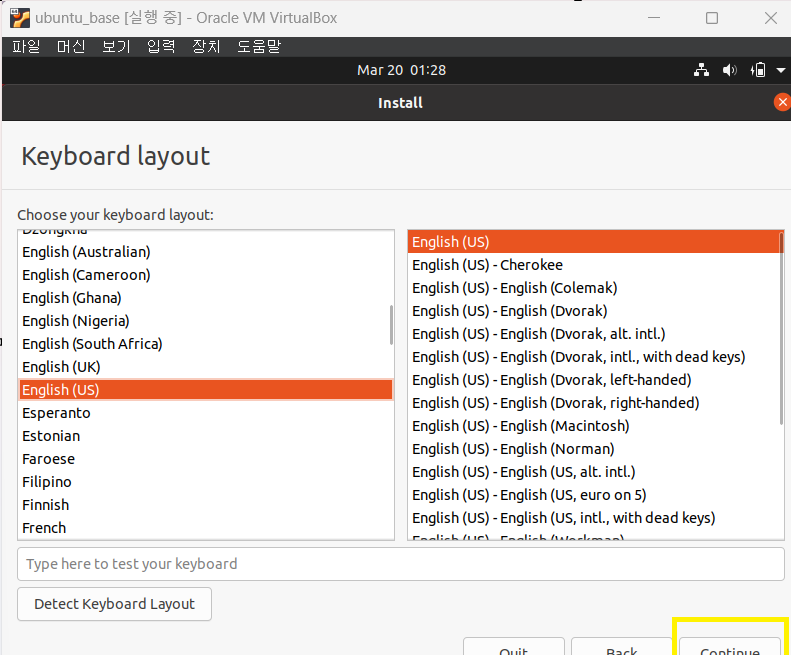
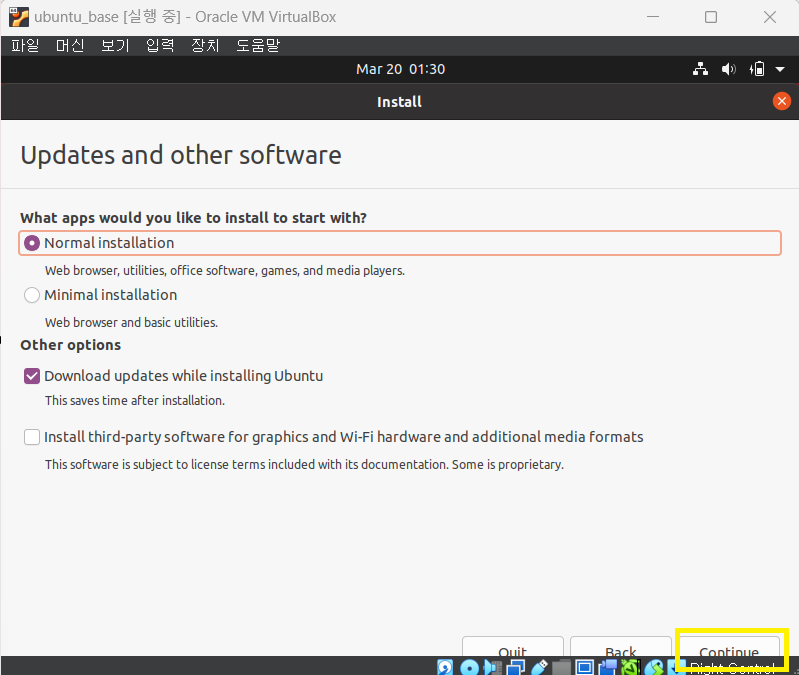
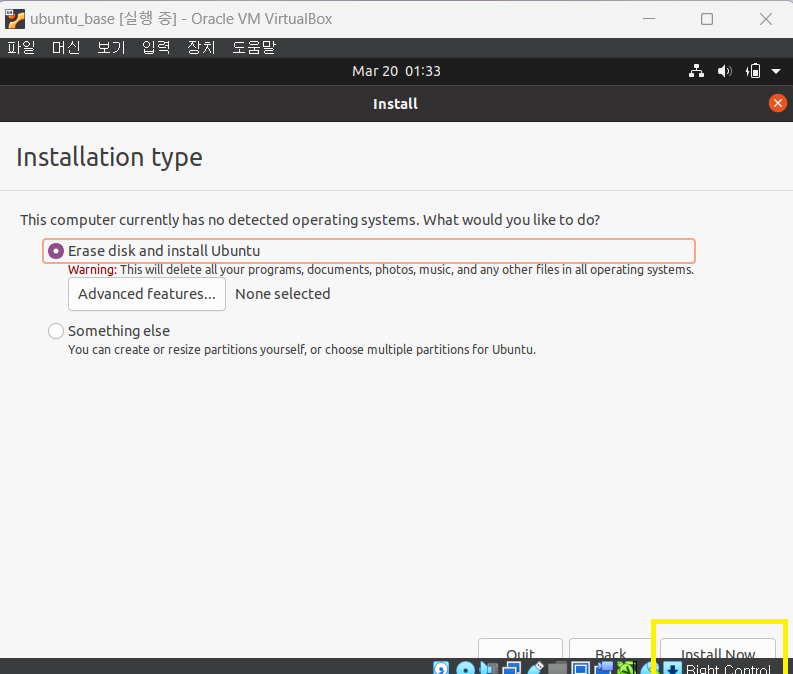
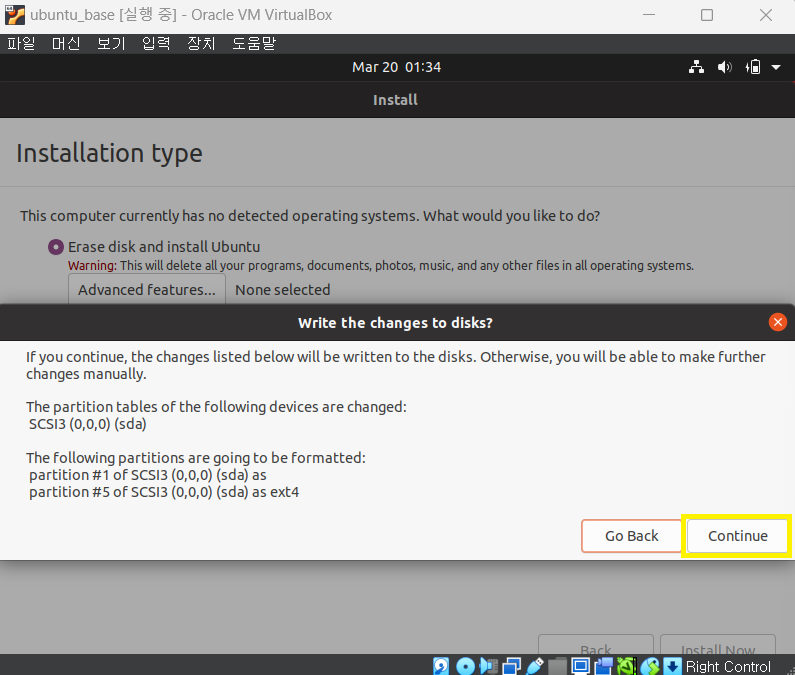
7 install ubuntu
![]0(https://velog.velcdn.com/images/rntjdwns1030/post/01743d7e-1d66-444c-8979-f20ba83518d6/image.png)
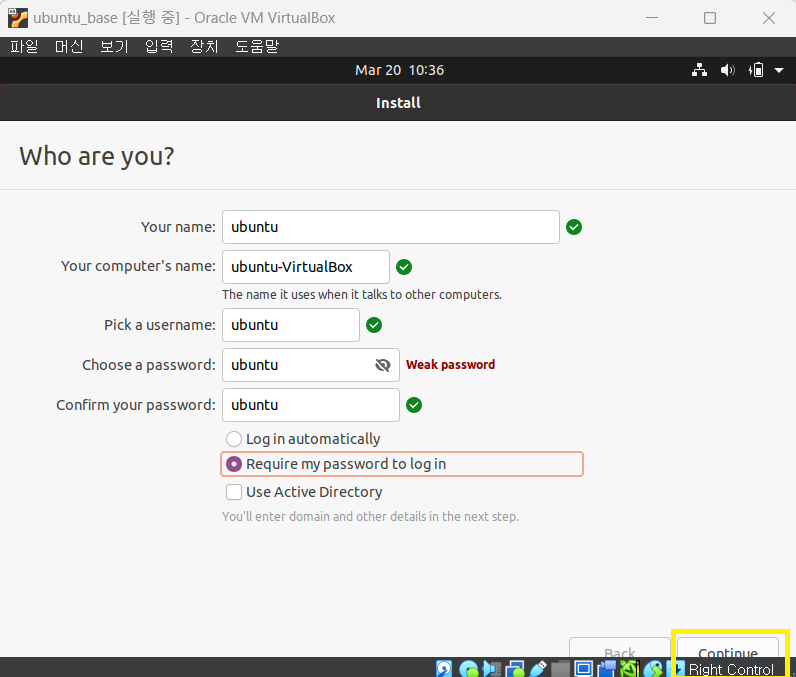
수정 Require my password to log in 이 아닌 Log in automatically를 선택하면 로그인시 자동으로 로그인이 가능합니다.
완료 후 재실행
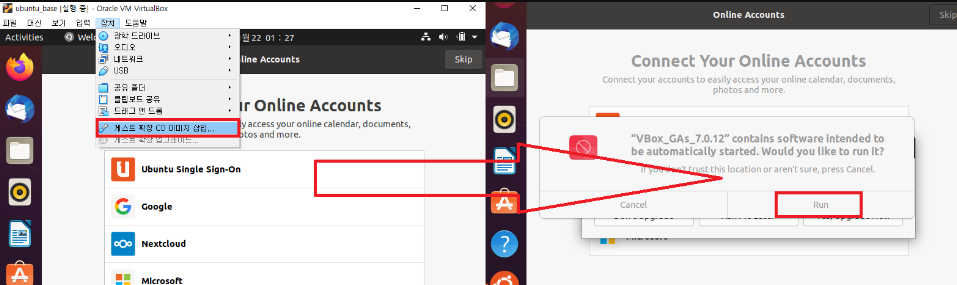
8 Virtural Box 게스트 확장 프로그램 설치하기
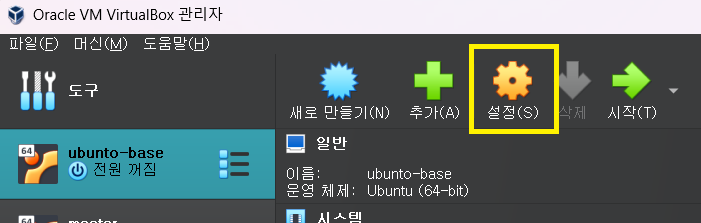
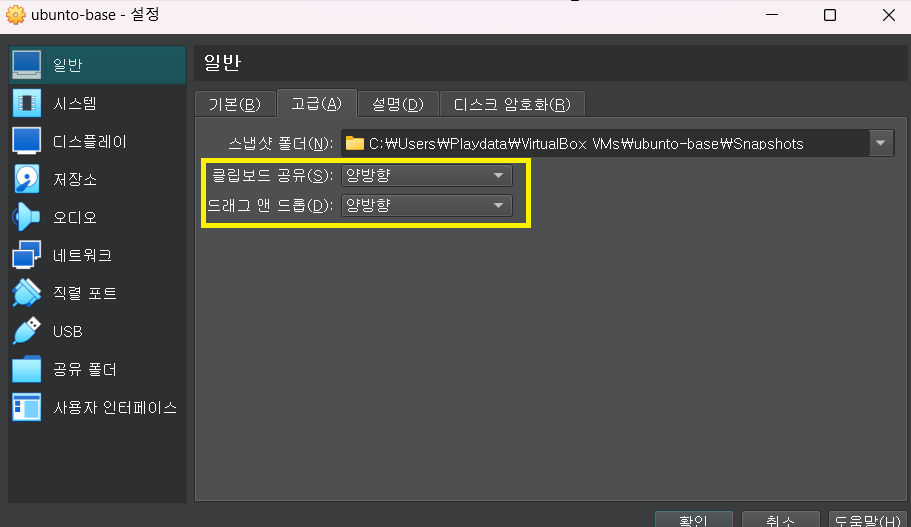
9 클립보드 설정
10 필수 라이브러리 설치
- vim : 텍스트 편집기
- wget : 웹 서버로부터 파일 다운로드
- unzip : 파일 압축 및 해제
- ssh / openssh-* : 리눅스 원격 접속
- net-tools : 네트워크 툴
# 업데이트 목록 갱신
sudo apt-get -y update
# 현재 패키지 업그레이드
sudo apt-get -y upgrade
# 신규 업데이트 설치
sudo apt-get -y dist-upgrade
# 필수 라이브러리 설치
sudo apt-get install -y vim wget unzip ssh openssh-* net-tools11 ssh install
sudo service ssh start
# ssh 실행 확인
systemctl status sshd12 Java 8 install
# Java 8 설치
sudo apt-get install -y openjdk-8-jdk
# Java version 확인
java -version
# Java 경로 확인
readlink -f $(which java) # /usr/lib/jvm/java-8-openjdk-amd6413 환경 설정
# 수정
sudo vim ~/.bashrc
# 아래내용 입력
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export PATH=$PATH:$JAVA_HOME/bin
# 적용
source ~/.bashrc
env | grep java # 확인 14 Apache Hadoop install
# 설치파일 관리용 디렉토리 생성
sudo mkdir /install_dir && cd /install_dir
# 다운로드
sudo wget https://archive.apache.org/dist/hadoop/core/hadoop-3.3.0/hadoop-3.3.0.tar.gz
# 확인
ls15 Python install
sudo apt-get install -y python3-pip16 Python 환경 설정
sudo vim ~/.bashrc
# python
export PYTHONPATH=/usr/bin/python3
export PYSPARK_PYTHON=/usr/bin/python3
export PATH=$PATH:/usr/bin/python3
# 수정된 .bashrc 파일 적용시키기
source ~/.bashrc
env | grep python317 Spark install
# 설치 관리용 디렉토리 이동
cd /install_dir
# Spark 3.2.1 설치
sudo wget https://archive.apache.org/dist/spark/spark-3.2.1/spark-3.2.1-bin-hadoop3.2.tgz
{kind=link}