playdata data engineering
1 hdfs-site.xml
HDFS에서 사용할 환경 정보 설정
-
dfs.replication : HDFS파일 블록 복제 개수 지정
-
dfs.namenode.name.dir : NameNode에서 관리할 dir지정
-
dfs.datanode.data.dir : DataNode에서 관리할 dir지정
-
dfs.journalnode.edits.dir : JournalNode는 NameNode의 동기화 상태 유지. 특정 시점에 구성된 fsimage snapshot이후 수정된 사항을 editlog, 저장 위치를 설정.
-
dfs.nameservices : Hadoop cluster의 네임서비스로 이름을 지정
-
dfs.ha.namenodes.my-hadoop-cluster : Hadoop cluster name service의 NameNode 이름을 지정(,(콤마)로 구분하여 기재)
- dfs.namenode.rpc-address.my-hadoop-cluster.namenode1 : NameNode간의 RPC 통신을 위해 통신 주소 지정. 8020포트 사용
- dfs.namenode.rpc-address.my-hadoop-cluster.namenode2 : NameNode간의 RPC 통신을 위해 통신 주소 지정. 8020포트 사용
- dfs.namenode.http-address.my-hadoop-cluster.namenode1 : NameNode1의 web ui 접속 url을 지정 50070포트
- dfs.namenode.http-address.my-hadoop-cluster.namenode2 : NameNode2의 web ui 접속 url을 지정 50070포트
- dfs.namenode.shared.edits.dir : editlog를 쓰고/읽을 JournalNode URL로 Zookeeper가 설치된 서버와 동일하게 설정하면 된다.
- dfs.client.failover.proxy.provider.my-hadoop-cluster : HDFS 클라이언트가 ActiveNameNode에 접근시 사용하는 Java class지정.
- dfs.ha.fencing.method : Failover 상황에서 기존 Active NameNode를 차단할 때 사용하는 방법을 기재.
- dfs.ha.fencing.ssh.private-key-files : ha.fencing.method를 sshfence로 지정할 경우, ssh를 경유하여 기존 Active NameNode를 죽이는데, 이때 passpharase(암호)를 통과하기위해서 SSH Private Key File를 지정
- dfs.ha.automatric-failover.enabled : 장애 복구를 자동으로 설정 여부 지정
vim $HADOOP_HOME/etc/hadoop/hdfs-site.xml
# 아래 내용으로 수정 후 저장
<configuration>
<!-- configuration hadoop -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop/data/nameNode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/data/dataNode</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/local/hadoop/data/dfs/journalnode</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>my-hadoop-cluster</value>
</property>
<property>
<name>dfs.ha.namenodes.my-hadoop-cluster</name>
<value>namenode1,namenode2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.my-hadoop-cluster.namenode1</name>
<value>master:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.my-hadoop-cluster.namenode2</name>
<value>worker1:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.my-hadoop-cluster.namenode1</name>
<value>master:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.my-hadoop-cluster.namenode2</name>
<value>worker1:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://master:8485;worker1:8485;worker2:8485/my-hadoop-cluster</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.my-hadoop-cluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>shell(/bin/true)</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/ubuntu/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/usr/local/hadoop/data/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/local/hadoop/data/data</value>
</property>
</configuration>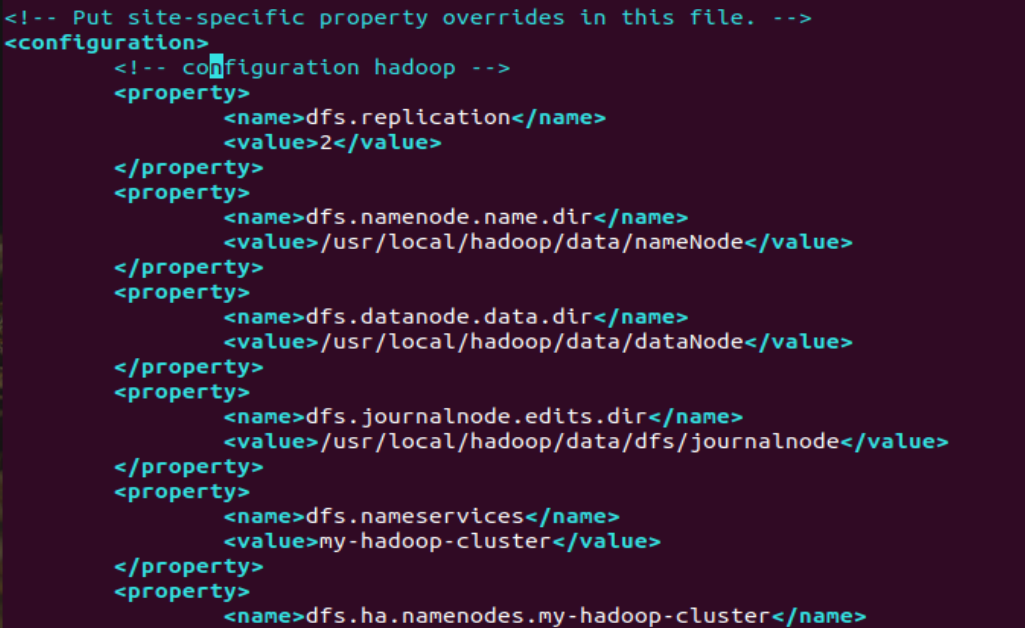
2 core-site.xml
Hadoop system 설정 파일
- fs.default.name : HDFS의 기본 통신 주소 지정
- fs.defaultFS : HDFS 기본 파일시스템 디렉토리 지정
- ha.zookeeper.quorum : Zookeeper가 설치되어 동작할 서버 주소 기재 포트 2181
vim $HADOOP_HOME/etc/hadoop/core-site.xml
# 아래 내용으로 수정 후 저장
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://my-hadoop-cluster</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>master:2181,worker1:2181,worker2:2181</value>
</property>
</configuration>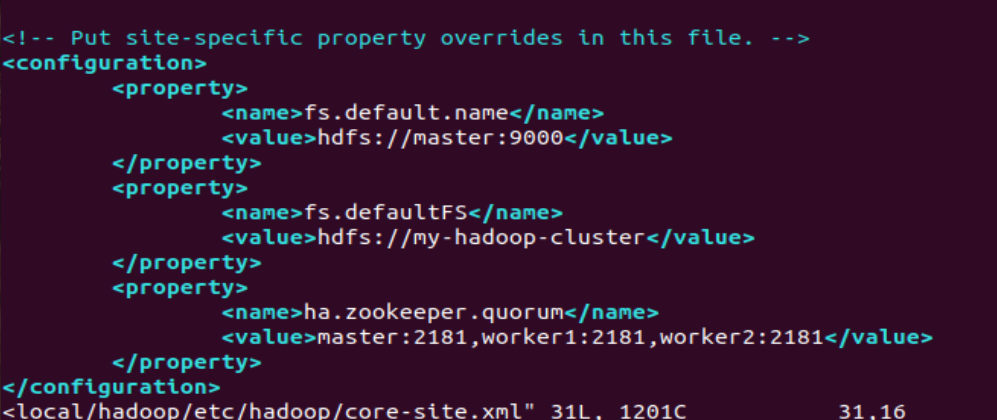
3 yarn-site.xml
Resource Manager 및 Node Manager에 대한 구성 정의
vim $HADOOP_HOME/etc/hadoop/yarn-site.xml
# 아래 내용으로 수정 후 저장
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>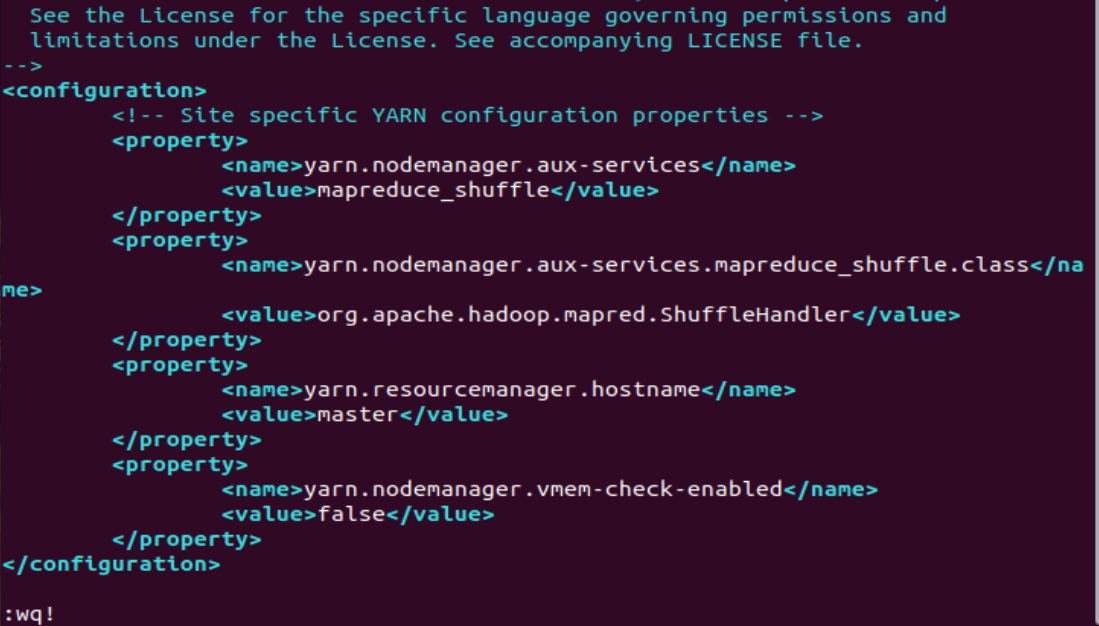
4 mapred-site.xml
MapReduce 어플리케이션 설정 파일
vim $HADOOP_HOME/etc/hadoop/mapred-site.xml
# 아래 내용으로 수정 후 저장
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>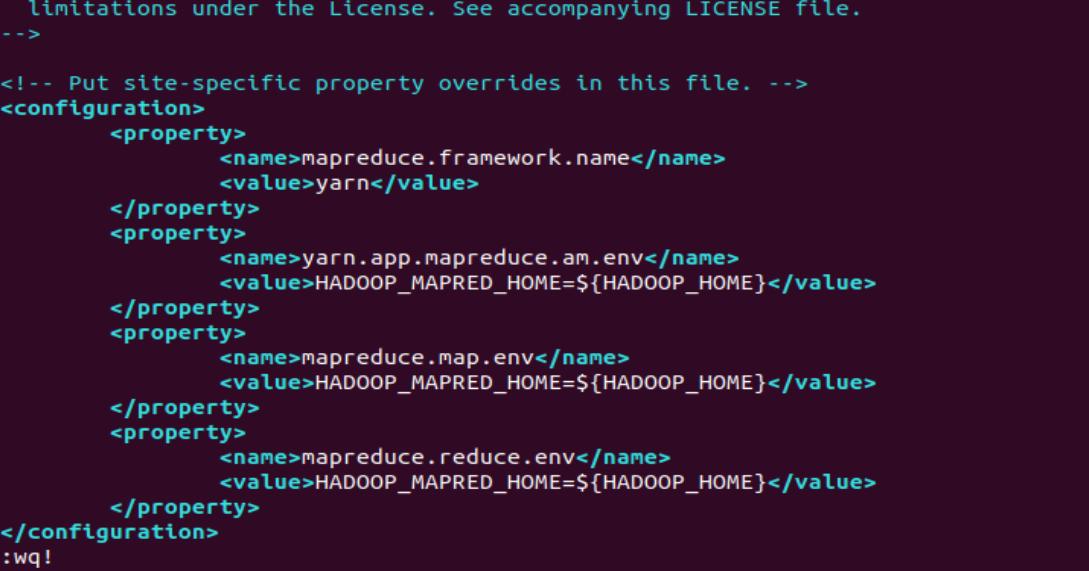
5 hadoop-env.sh
Hadoop 환경 설정
vim $HADOOP_HOME/etc/hadoop/hadoop-env.sh
# 아래 내용 수정 후 저장
# Java
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
# Hadoop
export HADOOP_HOME=/usr/local/hadoop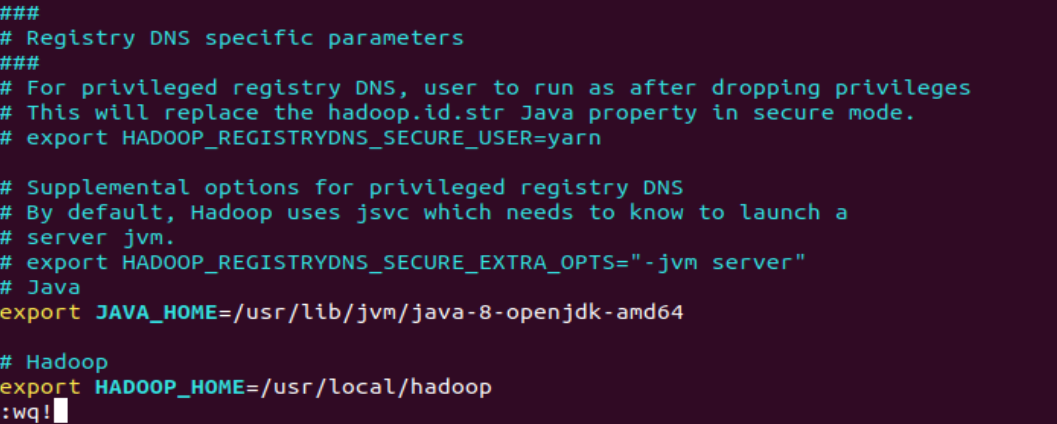
6 Hadoop worker
Hadoop의 worker로 동작한 서버 호스트 이름 설정
vim $HADOOP_HOME/etc/hadoop/workers
# 아래 내용 수정 후 저장
# localhost << 주석 처리 또는 제거
worker1
worker2
worker3
7 Hadoop masters
Hadoop의 master로 동작할 서버 호스트 이름 설정
# Hadoop masters 편집
vim $HADOOP_HOME/etc/hadoop/masters
# 아래 내용 수정 후 저장
master
worker1
