실습 환경
OpenSearch 설치
- single mode
- 별도 권한 제어 없음
- tls 사용 안함 (https 사용 안함)
cd /home/ubuntu
sudo apt update
sudo apt install build-essential -y
wget https://artifacts.opensearch.org/releases/bundle/opensearch/2.4.0/opensearch-2.4.0-linux-x64.tar.gz
tar -xvf opensearch-2.4.0-linux-x64.tar.gz
echo 'export OPENSEARCH_HOME=/home/ubuntu/opensearch-2.4.0' >> ~/.bashrc
source ~/.bashrc
$ $OPENSEARCH_HOME/bin/opensearch -version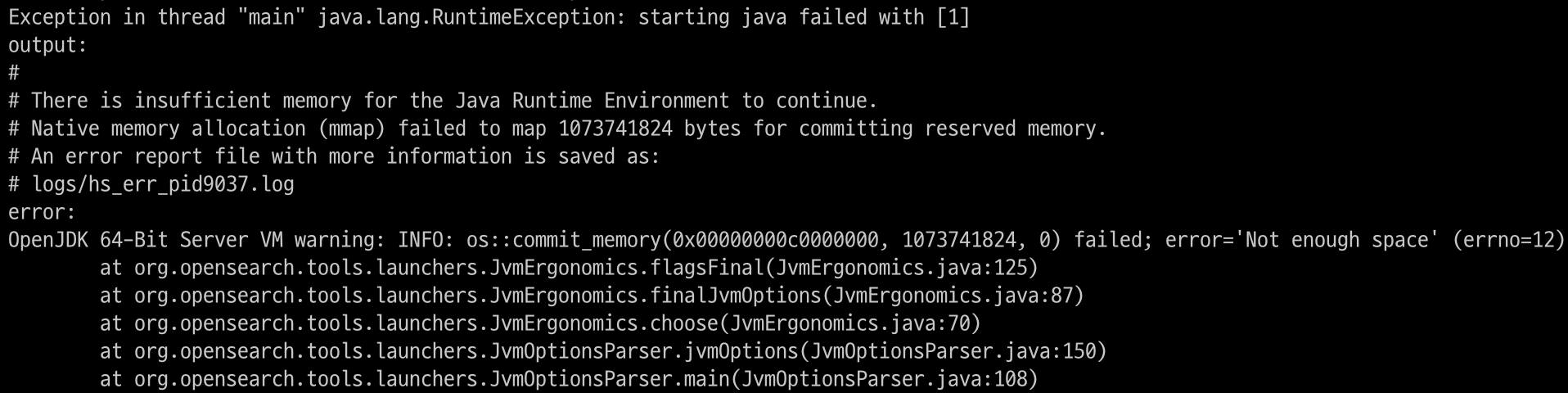
swap memory 할당
- swap memory를 할당하면 free tier에서도 opensearch 구동이 가능해짐
- 여기서는 2GB를 추가로 할당


sudo dd if=/dev/zero of=/swapfile bs=128M count=16
sudo chmod 600 /swapfile
sudo mkswap /swapfile
sudo swapon /swapfile
WARNING: A terminally deprecated method in java.lang.System has been called
WARNING: System::setSecurityManager has been called by org.opensearch.bootstrap.OpenSearch (file:/home/ubuntu/opensearch-2.4.0/lib/opensearch-2.4.0.jar)
WARNING: Please consider reporting this to the maintainers of org.opensearch.bootstrap.OpenSearch
WARNING: System::setSecurityManager will be removed in a future release
Version: 2.4.0, Build: tar/744ca260b892d119be8164f48d92b8810bd7801c/2022-11-15T04:42:29.671309257Z, JVM: 17.0.5- 실행이 되지만 여기서는 swap memory를 사용하지 않음
주요 디렉터리
- bin : 실행 파일 위치
- config : 설정 파일 위치. 부팅 전에 설정을 완료해야 함
- data : opensearch가 데이터를 저장하는 위치, 변경하고 싶으면 config에서 변경 가능
- jdk : 내장 JDK. Host에 JDK가 설치되어 있지 않으면 사용
- logs : log 디렉터리
- plugins : plugin 위치
Opensearch의 기본 포트
- 443
- AWS에서의 OpenSearch Dashboards
- https를 위한 포트 번호
- 5601
- OpenSearch 대쉬보드를 위한 포트 번호
- 9200
- OpenSearch의 API 포트 번호
- 9250
- Cross-cluster search
- 클러스터들 간에 연동할 때 사용하는 포트 번호
- 9300
- 같은 클러스터 안에 있는 노드들 간에 사용하는 포트 번호
- 9600
- Performance Analyzer
- 잘 사용되지 않음
설정
sudo swapoff -a$ vi $OPENSEARCH_HOME/config/opensearch.yml
network.host: 0.0.0.0
discovery.type: single-node # single node로 설정- 자기 자신의 IP를 등록하고, single-node이기 때문에 다른 것들은 클러스터가 아님을 알림
$ vi $OPENSEARCH_HOME/config/jvm.options
-Xms128m
-Xmx128m- JVM heap 사이즈의 초기값과, max값을 설정
- EC2 서버 메모리의 절반 추천
- 특별한 요구사항이 없을 때는 xms와 xmx는 같은 값을 가지는 것이 모니터링, 관리가 용이
plugin 설치
- Opensearch의 다양한 기능은 plugin 방식으로 개발됨
- 기본적으로 데이터 저장과 인덱싱 방법을 제공
- 활용하는 로직은 plugin에 구현됨
- maeven을 사용해 plugin을 설치 가능
bin/opensearch-plugin list // 설치된 plugin 확인
bin/opensearch-plugin remove opensearch-security // 인증이 오래 걸리기 때문에 security를 삭제실행
bin/opensearchopensearch를 실행한 후 로컬에서 public IP로 접근
curl -X GET http://$IP:9200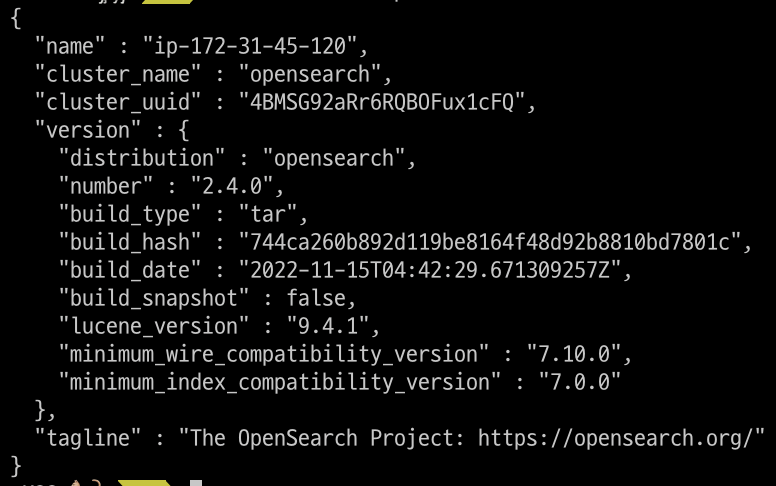
systemctl 등록
$ sudo vi /etc/systemd/system/opensearch.service
[Unit]
Description=OpenSearch
Wants=network-online.target
After=network-online.target
[Service]
Type=forking
RuntimeDirectory=data
WorkingDirectory=/home/ubuntu/opensearch-2.4.0
ExecStart=/home/ubuntu/opensearch-2.4.0/bin/opensearch -d
User=ubuntu
Group=ubuntu
StandardOutput=journal
StandardError=inherit
LimitNOFILE=65535
LimitNPROC=4096
LimitAS=infinity
LimitFSIZE=infinity
TimeoutStopSec=0
KillSignal=SIGTERM
KillMode=process
SendSIGKILL=no
SuccessExitStatus=143
TimeoutStartSec=75
[Install]
WantedBy=multi-user.targetsystemctl 파일을 생성
sudo systemctl daemon-reload
sudo systemctl enable opensearch.service
sudo systemctl start opensearch.service
ps -ef | grep opensearch
tail -f $OPENSEARCH_HOME/logs/opensearch.logs // log확인환경 변수 설정
export OPENSEARCH_REST_API=http://$IP:9200OpenSearch 구성 요소
- 클러스터: 여러 개의 노드로 구성되어 있으며 하나의 기능을 수행
- 노드: 하나 하나의 서버
- 샤드: 서버에 위치해 있는 데이터
- 인덱스: 데이터 묶음, 테이블에 해당
- 도큐먼트: 개별 레코드에 해당
- 필드: 데이터의 특성, 컬럼에 해당
- 매핑: 도큐먼트의 형식, 스키마에 해당
- 분석기
Opensearch는 데이터를 저장하고, 인덱싱하고, 쿼리 기반으로 데이터를 찾는다는 점에서 데이터베이스와 유사
인덱스
-
Opensearch에서 데이터를 검색하려면 데이터를 인덱싱해야 함
-
인덱싱
- opensearch는 자체적인 검색엔진을 갖는데, 검색 엔진에서 빠른 검색을 위해 데이터를 구조화하는 방법
- 도큐먼트를 검색에 최적화된 데이터 형태로 변환해, 인덱스 공간에 저장
-
인덱싱 결과로 생성된 결과를 인덱스로 칭함
-
도큐먼트가 저장되는 공간
-
형식
- 모든 문자는 소문자- 언더바, 하이픈으로 시작할 수 없음
- 공백, ",", ":", ", *, +, /, \, |, ?, #, >, <는 포함될 수 없음
매핑
- 도큐먼트를 인덱싱하기 위해서는 매핑을 거쳐야 함
- 도큐먼트의 필드와, 필드의 데이터 타입을 정의하여, 매핑 정의에 따라 Opensearch가 이해할 수 있는 데이터 구조로 변환
- 데이터 타입에 따라 인덱싱하는 방법이 다름
- Java는 정적 타입 언어이기 때문에 정렬을 위해서는 매핑이 필요
- 인덱싱 및 검색 성능을 높이기 위해서는 매핑을 잘 활용해야 함
- 인덱스 당 하나의 매핑 정의만 가질 수 있음
- 동일한 인덱스에 저장된 도큐먼트는 모두 동일한 방식으로 매핑(스키마)
명시적 매핑과 다이나믹 매핑
명시적 매핑
- 필드의 데이터 타입을 직접 정의
- 1) 처음부터 매핑이 정의된 인덱스를 생성하는 방법
- 2) 인덱스 생성 후 매핑 API를 활용해 별도 매핑을 정의하는 방법
다이나믹 매핑
- Opensearch가 자동으로 필드의 데이터 타입을 정의
- Opensearch는 도큐먼트의 원본 데이터에 맞춰 적절한 타입으로 매핑해줌
- 다이나믹 매핑은 일부 타입에 대해서만 지원
- 명시적 매핑은 IP 타입을 사용할 수 있지만, 다이나믹 매피
도큐먼트와 필드
- 도큐먼트는 기본적으로 JSON 형식
- 도큐먼트마다 고유한 아이디를 가짐
CRUD
- Opensearch REST API를 이용해 인덱스, 매핑, 도큐먼트를 직접 생성, 삭제하는 것이 목표
- JSON 응답을 사람이 읽기 쉽도록 하기 위해 "?pretty=true" 쿼리를 사용
인덱스 생성
- PUT을 사용
- PUT /:index
- 인덱스를 생성 가능
// movie 인덱스를 생성
$ curl -XPUT $OPENSEARCH_REST_API/movie
// {"acknowledged":true,"shards_acknowledged":true,"index":"movie"}% 인덱스 확인
- HEAD를 사용
- HEAD /:index
- 인덱스 존재 여부를 확인 가능
$ curl --head $OPENSEARCH_REST_API/movie
//HTTP/1.1 200 OK # 없는 경우 404를 반환
//content-type: application/json; charset=UTF-8
//content-length: 231인덱스 조회
- GET을 사용
- GET /:index
// 인덱스 조회
$ curl -XGET "$OPENSEARCH_REST_API/movie?pretty=true"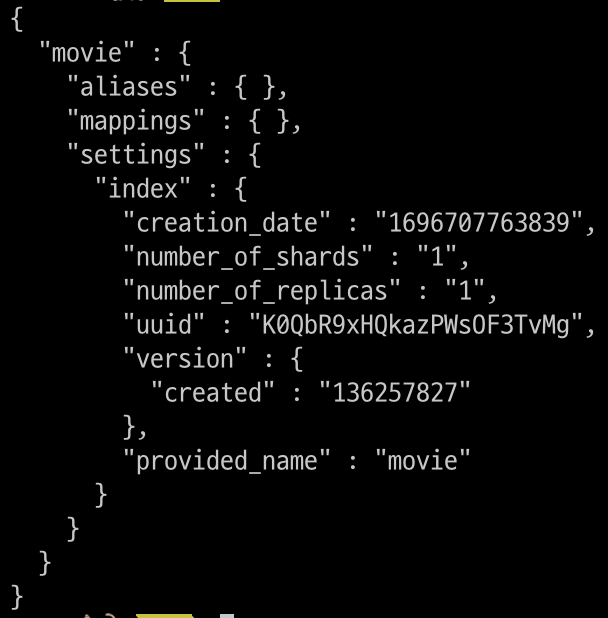
명시적 매핑
- PUT을 사용
- PUT /:index/_mapping
- -H는 header, -d는 data를 의미
$ curl -XPUT $OPENSEARCH_REST_API/movie/_mapping \
-H "Content-Type: application/json" \
-d '
{
"properties": {
"title": {
"type": "text"
}
}
}
}
// {"acknowledged":true}%
$ curl -XPUT $OPENSEARCH_REST_API/movie/_mapping \
-H "Content-Type: application/json" \
-d '
{
"properties": {
"genre": {
"type": "keyword" // 텍스트가 의미를 갖는 경우 text가 아닌 keyword 사용
}
}
}
}
'
// {"acknowledged":true}%
$ curl -XGET "$OPENSEARCH_REST_API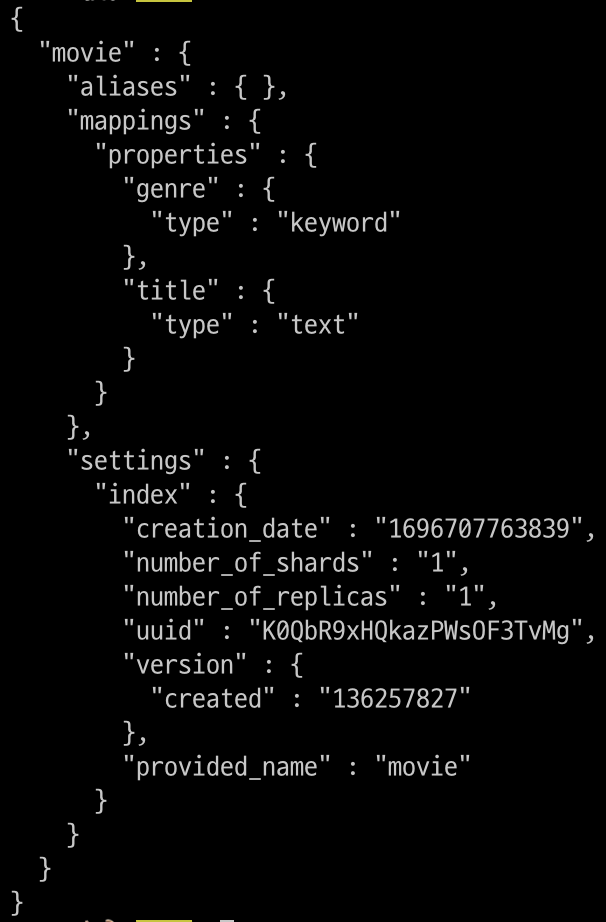 genre정보와 title 정보가 추가된 것을 확인할 수 있음
genre정보와 title 정보가 추가된 것을 확인할 수 있음
매핑 수정
- XPUT을 사용해 매핑을 바꾸려고 하는 경우 에러가 발생
- XPUT은 매핑이 안된 것을 추가하는 것만 자유로움
- 필드 이름을 변경하거나 데이터 타입을 변경하고 싶은 경우
- 새로운 인덱스를 만들어 데이터를 복사해서 넣거나
- reindex API를 사용
도큐먼트 생성과 다이나믹 매핑
도큐먼트 생성
- POST를 사용
- POST /:index/_doc
- POST를 사용해 인덱싱하는 경우 Opensearch가 도큐먼트의 ID를 자동으로 생성
- _id 필드를 통해 생성된 ID를 확인 가능
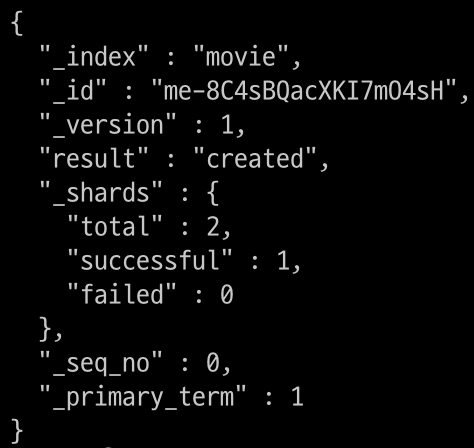
$ curl -XPOST "$OPENSEARCH_REST_API/movie/_doc?pretty=true" \
-H "Content-Type: application/json" \
-d '
{
"title": "Love Actually",
"genre": "Drama"
}
'
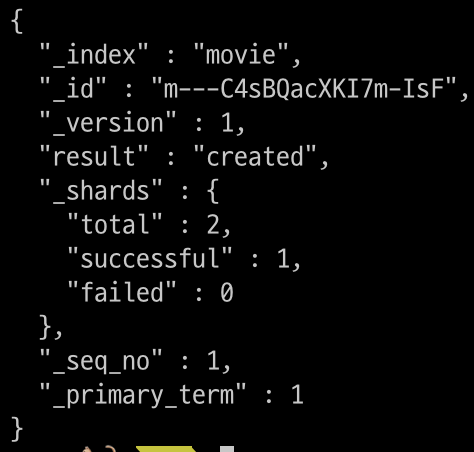
$ curl -XPOST "$OPENSEARCH_REST_API/movie/_doc?pretty=true" \
-H "Content-Type: application/json" \
-d '
{
"title": "Interstellar"
}
'
도큐먼트 조회
curl -XGET "$OPENSEARCH_REST_API/movie/_doc/m---C4sBQacXKI7m-IsF"
$ curl -XPOST "$OPENSEARCH_REST_API/movie/_doc?pretty=true" \
-H "Content-Type: application/json" \
-d '
{
"title": "Love Actually",
"genre": "Drame",
"directory": "Joseph Kosinski"
}
'
$ curl -XGET "$OPENSEARCH_REST_API/movie?pretty=true"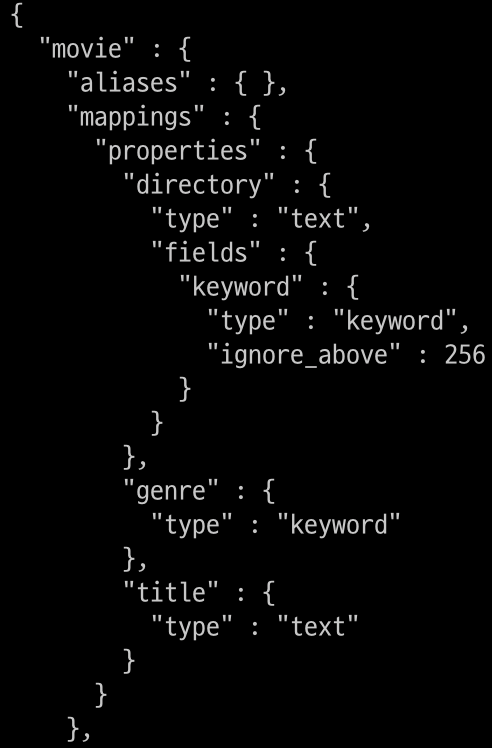
- 다이나믹 매핑을 사용한 후 XGET을 이용해 properties를 보면 director가 생성된 것을 확인할 수 있음
- text로 검색할 수 있고, keyword로도 검색이 가능
- fields를 사용하면 멀티 인덱싱이 가능
값을 잘못 넣는 경우
$ curl -XPOST "$OPENSEARCH_REST_API/movie/_doc?pretty=true" \
-H "Content-Type: application/json" \
-d '
{
"title": "Titanic",
"rate": "7.9" // rate는 text로 인식됨
}
'인덱싱은 text로 되어있지만 숫자로 값을 넣어도 매핑을 위해 tostring을 적용하여 값을 저장
→ 값을 조회하면 숫자로 저장된 값을 반환해줌
curl -XPOST "$OPENSEARCH_REST_API/movie/_doc?pretty=true" \
-H "Content-Type: application/json" \
-d '
{
"title": "Titanic2",
"rate": 7.9
}
'값을 자동으로 형변환할 수 없는 경우
$ curl -XPOST "$OPENSEARCH_REST_API/movies/_doc?pretty=true" \
-H "Content-Type: application/json" \
-d '
{
"title": "Titanic",
"rate2": 7.9
}
'rate2는 float으로 자동으로 설정됨
$ curl -XPOST "$OPENSEARCH_REST_API/movies/_doc?pretty=true" \
-H "Content-Type: application/json"
-d '
{
"title": "Titanic",
"rate2": "This is text"
}"This is text"는 float으로 형변환할 수 없기 때문에 에러가 발생함
도큐먼트 조회
- GET을 사용
- GET /:index/_doc/:id, GET /:index/_search
- _doc : 하나의 도큐먼트를 조회
- _search : 여러 개의 도큐먼트를 조회
- 인덱싱한 도큐먼트를 조회
ID로 조회
$ curl -XGET "$OPENSEARCH_REST_API/movie/_doc/$id?pretty=true"모든 도큐먼트를 조회
$ curl -XGET "$OPENSEARCH_REST_API/movie/_search?pretty=true"도큐먼트 조건부 조회
$ curl -XGET "$OPENSEARCH_REST_API/movie/_search?pretty=true&q=title:Titanic"- prefix나 key 등 여러 가지 조건을 이용해 조회할 수 있음
도큐먼트 수정
- PUT을 사용
- PUT /:index/_doc/:id, POST /:index/_update/:id
PUT
- PUT을 사용하면 기존에 있던 데이터 위에 새롭게 덮어쓰게 됨
- 데이터가 이미 있으면 값을 덮어쓰고 없으면 새로운 데이터를 생성함
$ curl -XPUT "$OPENSEARCH_REST_API/movie/_doc/$id?pretty=true" \
-H "Content-Type: application/json" \
-d '
{
"director": "Richard Curtis"
}
'update
- update는 기존에 있던 값에 새롭게 값을 더할 때 사용
$ curl -XPOST "$OPENSEARCH_REST_API/movie/_doc/$id?pretty=true" \
-H "Concent-Type: application/json" \
-d '
{
"doc": {
"rate2": "8.0",
"genre": "Drama",
"rank": 1
}
}
'도큐먼트 삭제
- DELETE 사용
- DELETE /:index/_doc/:id
- 삭제한 도큐먼트는 복구할 수 없음
$ curl -XDELETE "$OPENSEARCH_REST_API/movie/_doc/$id?pretty=true"인덱스 닫기
- POST 사용
- POST /:index/_close
- 사용하지 않는 인덱스는 힙 메모리, 검색 성능에 영향을 미칠 수 있음
- 오버헤드를 줄이기 위해 임시로 닫는 것이 좋음
- 닫힌 인덱스는 디스크에 저장되어 있지만, 힙 메모리에 로드되지 않음
- CRUD가 모두 불가능한 상태
$ curl -XPOST "$OPENSEARCH_REST_API/movie/_close?pretty=true"
$ curl -XGET "$OPENSEARCH_REST_API/movie/_search?pretty=true"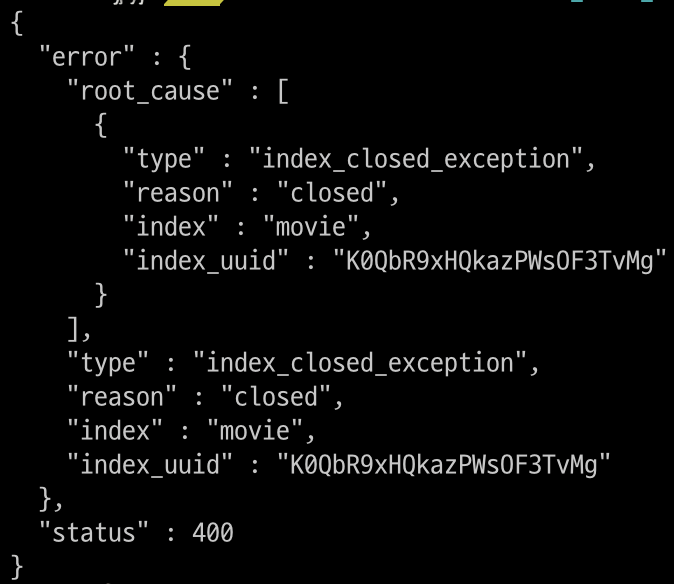
인덱스에 접근하려 하면 인덱스가 닫혀있는 것을 확인할 수 있음
인덱스 열기
- POST 사용
- POST /:index/_open
- 용량이 크다면 인덱스를 닫았다가 다시 열면 인덱싱을 하는 시간이 걸림
$ curl -XPOST "$OPENSEARCH_REST_API/movie/_open?pretty=true"인덱스 삭제
$ curl -XDELETE "$OPENSEARCH_REST_API/movie"도큐먼트 벌크 API
- 한 번에 여러개의 도큐먼트를 처리
- 한 번의 요청으로 많은 도큐먼트를 처리할 수 있기 때문에 네트워크 오버헤드가 줄어듬
- 프로그래밍을 할 때 일정 개수나 일정 주기로 도큐먼트를 한 번에 처리하는 것이 효율적
$ curl -XPOST "$OPENSEARCH_REST_API/_bulk?pretty=true" \
-H "Content-Type: application/json" \
-d '
{"index": {"_index": "test", "_id": "1"} }
{"field1": "value1"}
{"delete": {"_index": "test", "_id": "2"} }
{"create": {"_index": "test", "_id": "3"} }
{"field1": "value3"}
{"update": {"_id": "1", "_index": "test"} }
{"doc": {"field2": "value2"} }
'텍스트 인덱싱과 전문 검색(Full-text search)
- Opensearch는 필드의 매핑 타입에 따라 인덱싱하는 방법이 다름
- string 데이터는 keyword타입과 text타입으로 매핑
- text
- 도큐먼트가 추가되거나 업데이트 될 때마다 분석 수행
- 별도로 저장된 데이터 구조를 활용해 쿼리를 수행
- 좀 더 로드가 많음
- 메모리를 좀 더 많이 사용
- 역색인(Inverted index) 데이터 구조에 맞춰 데이터를 저장
- keyword
- 텍스트 그대로 인덱싱
- 도큐먼트의 텍스트를 그대로 사용
- cardinality에 취약
- text
Opensearch 텍스트 분석기의 구성 요소
텍스트 분석기는 3가지 요소로 구성
- 캐릭터 필터(Character filters)
- 분석기에 여러 개의 캐릭터 필터 추가 가능 (선택요소)
- 텍스트에서 약속받은 문자를 추가, 제거, 변경 가능
- ex) HTML 태그를 삭제하기 위해 사용 가능
- 토크나이저(Tokenizer)
- 분석기에는 하나의 토크나이저만 설정 가능 (필수요소)
- 텍스트를 개별 토큰으로 분리 (일반적으로 단어 단위)
- 각 토큰의 시작 위치와 끝나는 위치를 저장
- 토큰을 활용해 원본 텍스트에서 토큰과 매칭되는 단어를 찾을 수 있음
- 위치 정보 외에도 토큰 순서 등 다양한 메타데이터를 함께 저장
- 토크나이저의 종류는 다양한데, default는 standard tokenizer를 사용
- standard tokenizer는 유니코드 기준으로 텍스트를 분할
- 공백 기준으로 텍스트 분리
- 쉼표, 마침표, 세미콜론 등의 기호 제거
- whitespace tokenizer : standard와 달리 기호를 제거하지 않음
- 토큰 필터(Token filters)
- 분석기에 여러 개의 토큰 필터 설정 가능 (선택 요소)
- 분리된 토큰들에 대해 토큰을 추가, 삭제, 변경이 가능
- 텍스트를 입력으로 받는 캐릭터 필터와 다르게 토큰을 입력으로 받음
- ex)
- lowercase token filter : 모든 문자를 소문자로 변환
- stop filter : 불용어 제거
- lowercase token filter : 모든 문자를 소문자로 변환
Opensearch 텍스트 분석 과정
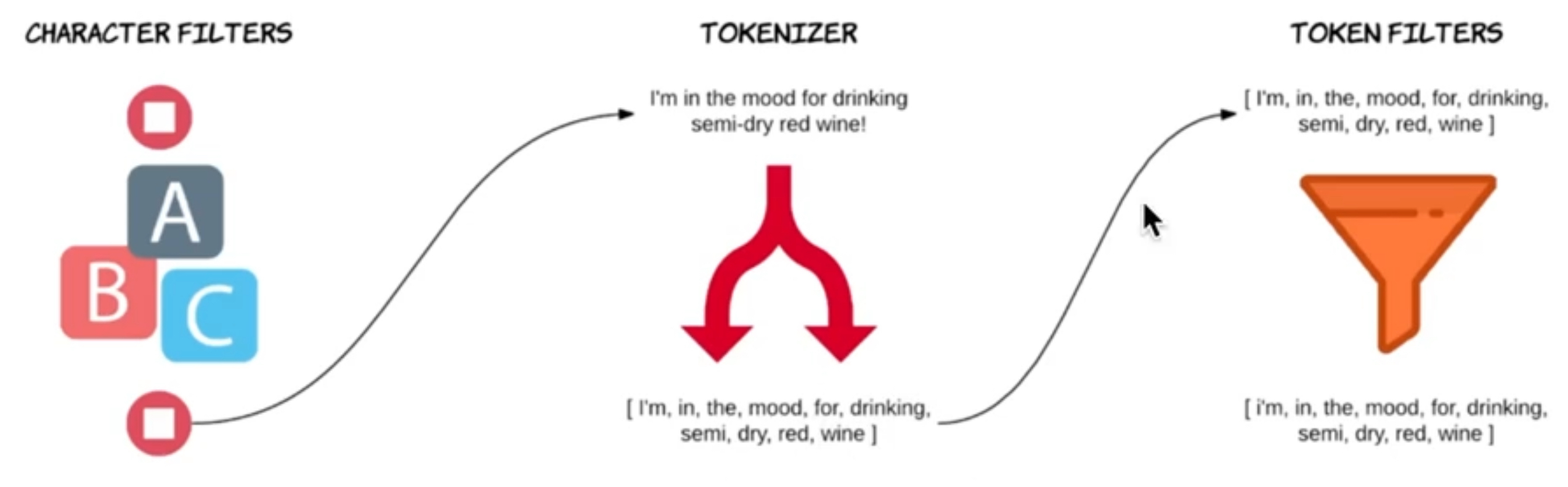
캐릭터 필터 → 토크나이저 → 토큰 필터
- standard 외의 다른 분석기를 사용하고 싶을 때는 명시적으로 분석기 타입을 지정
- 토크나이저와 필터를 조합해 커스텀 분석기를 만들 수도 있음
Opensearch 텍스트 분석
- GET /_analyze를 사용하면 데이터를 저장하지 않고 테스트를 수행할 수 있음
$ curl -XGET "$OPENSEARCH_REST_API/_analyze?pretty=true" \
-H "Content-Type: application/json" \
-d '
{
"analyzer": "standard",
"text": "Hello, World!"
}
'
$ curl -XGET "$OPENSEARCH_REST_API/_analyze?pretty=true" \
-H "Content-Type: application/json" \
-d '
{
"analyzer": "standard",
"text": ["first array element!", "second array element 2"]
}
'- 배열에 대해서도 동일하게 토크나이저를 적용할 수 있음
- 하나의 문자열로 합친 후 offset을 설정함
사용자 지정 analyzer
다음과 같이 사용자 지정 analyzer를 설정할 수 있음
- analyzer를 사용하지 않고 직접 tokenizer와 filter를 지정
$ curl -XGET "$OPENSEARCH_REST_API/_analyze?pretty=true" \
-H "Content-Type: application/json" \
-d '
{
"tokenizer": "standard",
"filter": ["uppercase"],
"text": "Opensearch Custom Analyzer"
}
'HTML 처리
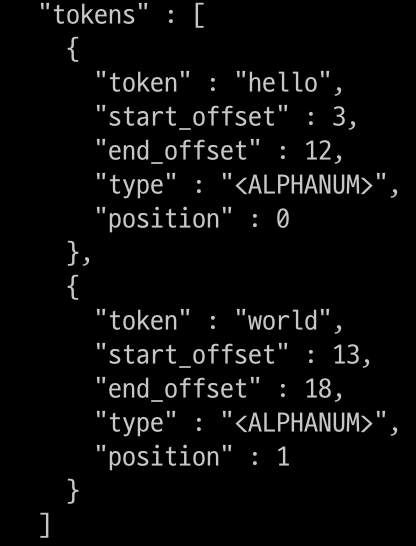
$ curl -XGET "$OPENSEARCH_REST_API/_analyze?pretty=true" \
-H "Content-Type: application/json" \
-d '
{
"tokenizer": "standard",
"filter": ["lowercase"],
"char_filter": ["html_strip"],
"text": "<b>Hello</b> world"
}
'
whitespace tokenizer
$ curl -XPUT "$OPENSEARCH_REST_API/book?pretty=true" \
-H "Content-Type: application/json" \
-d '
{
"mappings": {
"properties": {
"description": {
"type": "text",
"analyzer": "whitespace"
}
}
}
}
'
$ curl -XGET "$OPENSEARCH_REST_API/book/_analyze?pretty=true" \
-H "Content-Type: application/json" \
-d '
{
"field": "description",
"text": "Opensearch analyze test!!"
}
'$ curl -XPUT "$OPENSEARCH_REST_API/music" \
-H "Content-Type: application/json" \
-d '
{
"settings": {
"analysis": {
"analyzer": {
"default": {
"type": "whitespace"
}
}
}
}
}
'
$ curl -XGET "$OPENSEARCH_REST_API/music/_analyze?pretty=true" \
-H "Content-Type: application/json" \
-d '
{
"text": "Opensearch analyze test!!"
}
'Opensearch 역인덱스 (Inverted index)
역인덱스와 전문 검색
- 토크나이징하는 이유는 역인덱스를 사용하기 위함
- Full text search를 잘하기 위해 역인덱스에 구조화하여 저장
- 빠른 전문 검색이 가능해짐
- LIKE와 정규표현식은 인덱스를 사용하지 않고 모두 조회하기 때문에 속도가 느림
- 역인덱스 구조는 JSON 문서가 아닌, 토큰화된 역인덱스 데이터에 대해 쿼리를 수행
역인덱스 구조
- 텍스트 타입 필드 하나 당 하나의 역인덱스 생성
- 토큰이 어떤 텍스트(문서)에 포함되어 있는지를 저장함
- https://lucene.apache.org/core/3_0_3/fileformats.html
- analyzer에 따라 검색어가 올바르더라도 내용 조회가 안될 수도 있음
쿼리
- 전문 쿼리(Full-text query)
- 검색어와 도큐먼트가 일치하는 정도에 따라 관련성 점수 계산
- 내림차순 정렬
- 인덱싱에 사용된 분석기와 동일한 분석기로 분석 수행
- 검색어가 도큐먼트와 동일한 분석 프로세스를 가짐
- 용어 수준 쿼리(Term-level query)
- 검색어와 정확히 일치하는 용어를 찾기 위해 사용
- keyword 타입이 아닌 경우에도 용어 수준 쿼리를 사용 가능
실제 사용
$ curl -XPUT "$OPENSEARCH_REST_API/food?pretty=true" \
-H "Content-Type: application/json" \
-d '
{
"mappings": {
"properties": {
"category": {
"type": "keyword"
},
"review": {
"type": "text"
}
}
}
}
'데이터 삽입
$ curl -XPOST "$OPENSEARCH_REST_API/_bulk?pretty=true" \
-H "Content-Type: application/json" \
-d '
{"index": {"_index": "food", "_id": "1"}}
{"category": "Fruit", "review": "Fruits are the means by which flowering plants disseminate their seeds."}
{"index": {"_index": "food", "_id": "2"}}
{"category": "Meat", "review": "Meat is animal flesh that is eaten as food."}
{"index": {"_index": "food", "_id": "3"}}
{"category": "Vegetable", "review": "Vegetables are parts of plants that are consumed by humans or other animals as food."}
{"index": {"_index": "food", "_id": "4"}}
{"category": "Bread", "review": "Bread is a staple food prepared from a dough of flour and water, usually by baking."}
{"index": {"_index": "food", "_id": "2"}}
{"category": "Fish", "review": "Fish are aquatic, craniate, gill-bearing animals that lack limbs with digits."}
'전문 검색
전문 검색 쿼리를 사용하는 경우 검색어가 여러 도큐먼트에 포함된다면 연관성이 높은 순서대로 정렬해서 출력
$ curl -XGET "$OPENSEARCH_REST_API/food/_search?pretty=true" \
-H "Content-Type: application/json" \
-d '
{
"query": {
"match": {
"review": "flour, water"
}
}
}
'keyword 검색
- keyword 타입은 keyword 분석기가 적용됨
- 텍스트 전체를 단일 토큰으로 변환하는 분석기
curl -XGET "$OPENSEARCH_REST_API/food/_search?pretty=true" \
-H "Content-Type: application/json" \
-d '
{
"query": {
"match": {
"category": {"query": "Bread",
"analyzer": "standard"}
}
}
}
'용어 수준 검색
- insert할 때 어떻게 analyze되는지와 search할 때 analyze되는지를 고려해야 함
- 데이터가 없더라도 disk를 모두 조회하지 않음
curl -XGET "$OPENSEARCH_REST_API/food/_search?pretty=true" \
-H "Content-Type: application/json" \
-d '
{
"query": {
"term": {
"review": "Bread is a staple food prepared from a dough of flour and water, usually by baking."
}
}
}
'
스터디를 해보자
대단하시네요 ^__^